Uso de MirrorMaker para replicar temas de Apache Kafka con Kafka en HDInsight
Obtenga información sobre cómo usar la característica de creación de reflejo de Apache Kafka para replicar temas a un clúster secundario. Puede ejecutar la creación de reflejo como un proceso continuo, o de forma intermitente, para migrar datos de un clúster a otro.
En este artículo, usará la creación de reflejo para replicar temas entre dos clústeres de HDInsight. Estos clústeres están en redes virtuales diferentes de distintos centros de datos.
Advertencia
No use la creación de reflejo como medio para lograr la tolerancia a errores. El desplazamiento a los elementos de un tema es diferente entre los clústeres principales y secundarios, por lo que los clientes no pueden usarlos indistintamente. Si le preocupa la tolerancia a errores, establezca la replicación para los temas en el clúster. Para obtener más información, vea Introducción a Apache Kafka en HDInsight.
Funcionamiento de la creación de reflejo de Apache Kafka
La creación de reflejo funciona mediante la herramienta MirrorMaker, que forma parte de Apache Kafka. MirrorMaker consume registros de los temas del clúster principal y, a continuación, crea una copia local en el clúster secundario. MirrorMaker usa uno o varios consumidores que leen los datos del clúster principal y un productor que escribe los datos en el clúster local (secundario).
La configuración de la creación de reflejo que resulta más útil para la recuperación ante desastres consiste en usar clústeres de Kafka en diferentes regiones de Azure. Para ello, se emparejan las redes virtuales en las que residen los clústeres.
En el siguiente diagrama, se ilustra el proceso de creación de reflejo y cómo fluye la comunicación entre los clústeres:
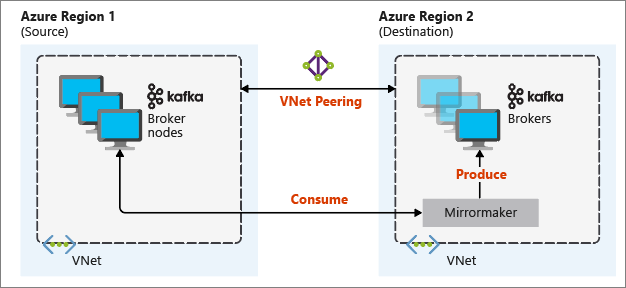
Los clústeres principales y secundarios pueden tener un número diferente de nodos y de particiones. Además, los desplazamientos dentro de los temas también son diferentes. La creación de reflejos conserva el valor de la clave que se utiliza para crear particiones, por lo que se mantiene el orden de los registros en una base por claves.
Creación de reflejo en los límites de red
Si tiene que crear un reflejo entre los clústeres Kafka en distintas redes, existen las siguientes consideraciones adicionales:
Puertas de enlace: las redes deben poder comunicarse en el nivel TCP/IP.
Direccionamiento del servidor: si quiere, puede direccionar los nodos del clúster mediante sus direcciones IP o nombres de dominio completo.
Direcciones IP: si configura los clústeres de Kafka para que usen publicidad basada en direcciones IP, puede configurar la creación de reflejo con las direcciones IP de los nodos de agentes y los nodos de ZooKeeper.
Nombres de dominio: si no configura los clústeres de Kafka para que usen publicidad basada en direcciones IP, es necesario que los clústeres puedan conectarse entre sí mediante nombres de dominio completo (FQDN). Para ello, debe haber un servidor de sistema de nombres de dominio (DNS) en cada red que esté configurado para reenviar solicitudes a las demás redes. Al crear una instancia de Azure Virtual Network, en lugar de usar el DNS automático que se proporciona con la red, debe especificar un servidor DNS personalizado y la dirección IP para el servidor. Una vez que haya creado la red virtual, debe crear una máquina virtual de Azure que use esa dirección IP. Después, instale y configure en ella el software DNS.
Importante
Cree y configure el servidor DNS personalizado antes de instalar HDInsight en la red virtual. No es necesaria ninguna configuración adicional para que HDInsight use el servidor DNS configurado para la red virtual.
Para obtener más información sobre cómo conectar dos redes virtuales de Azure, consulte el documento sobre configuración de una conexión de red virtual a red virtual.
Arquitectura de creación de reflejo
Esta arquitectura contiene dos clústeres en diferentes grupos de recursos y redes virtuales: uno principal y otro secundario.
Pasos de creación
Cree dos nuevos grupos de recursos:
Resource group Location kafka-primary-rg Centro de EE. UU. kafka-secondary-rg Centro-Norte de EE. UU Cree una nueva red virtual, kafka-primary-vnet, en kafka-primary-rg. Deje los valores predeterminados.
Cree una nueva red virtual, kafka-secondary-vnet, en kafka-secondary-rg también con la configuración predeterminada.
Cree dos nuevos clústeres de Kafka:
Nombre del clúster Resource group Virtual network Cuenta de almacenamiento kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Cree los emparejamientos de las redes virtuales. Este paso creará dos emparejamientos: uno de kafka-primary-vnet a kafka-secondary-vnet y otro de vuelta de kafka-secondary-vnet a kafka-primary-vnet.
Seleccione la red virtual kafka-primary-vnet.
En Configuración, seleccione Emparejamientos.
Seleccione Agregar.
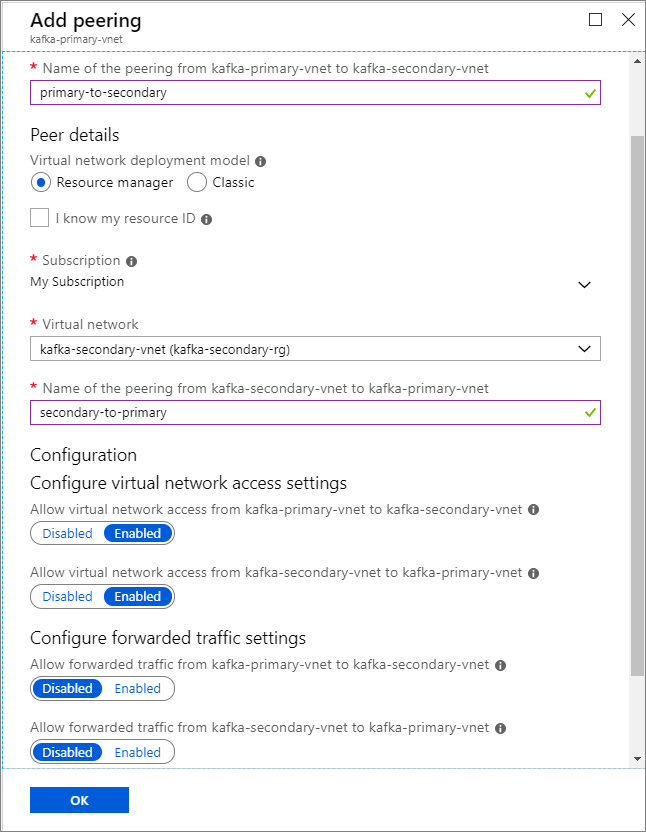
En la pantalla Agregar emparejamiento, escriba los detalles tal y como aparecen en la captura de pantalla siguiente.
Configuración del anuncio de direcciones IP
La configuración de la publicidad de direcciones IP permite al cliente conectarse mediante direcciones IP de agente, en lugar de nombres de dominio.
Vaya al panel de Ambari del clúster principal:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Seleccione Services> (Servicios) Kafka. Seleccione la pestaña Configs (Configuraciones).
Agregue las siguientes líneas de configuración en la sección kafka-env template que encontrará en la parte inferior. Seleccione Guardar.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesEscriba una nota en la pantalla Guardar configuración y seleccione Guardar.
Si recibe una advertencia de configuración, seleccione Proceed Anyway (Continuar de todos modos).
En Save Configuration Changes (Guardar cambios de configuración), seleccione Ok (Aceptar).
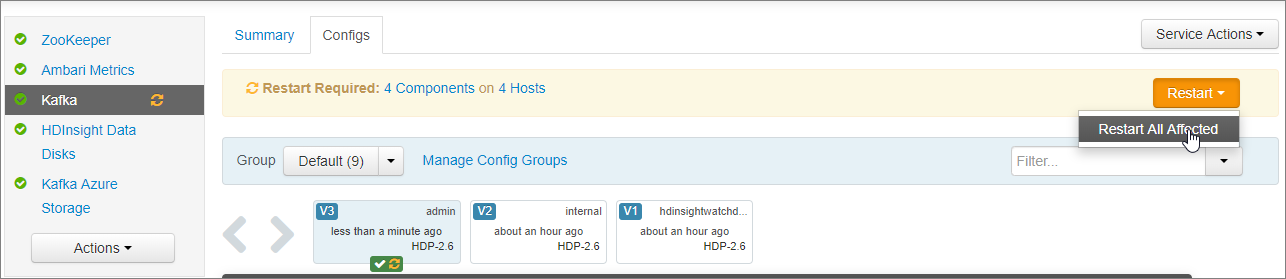
En la notificación Restart Required (Es necesario reiniciar), seleccione Restart (Reiniciar)>Restart All Affected (Reiniciar todos los elementos afectados). Seleccione Confirm Restart All (Confirmar reinicio de todo).
Configuración de Kafka para que escuche en todas las interfaces de red
- Permanezca en la pestaña Configs (Configuraciones) de Services (Servicios)>Kafka. En la sección Kafka Broker (Agente de Kafka), establezca la propiedad listeners en
PLAINTEXT://0.0.0.0:9092. - Seleccione Guardar.
- Seleccione Restart (Reiniciar) >Confirm Restart All (Confirmar reinicio de todo).
Registro de las direcciones IP de los agentes y las direcciones ZooKeeper del clúster principal
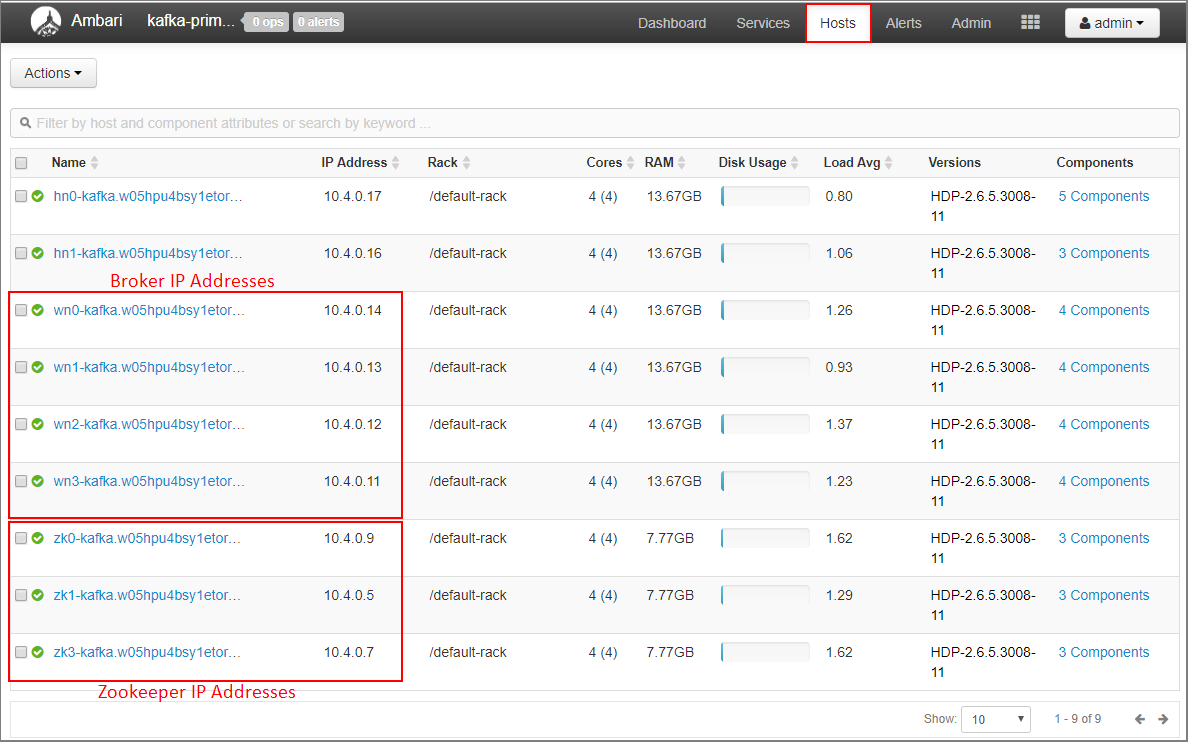
Seleccione Hosts en el panel de Ambari.
Tome nota de las direcciones IP de los agentes y las instancias de ZooKeeper. El nombre del host de los nodos de los agentes comienza por wn, mientras que el nombre del host de los nodos de ZooKeeper comienza por zk.
Repita los tres pasos anteriores con el segundo clúster, kafka-secondary-cluster: configure la publicidad basada en IP, establezca los agentes de escucha y tome nota de las direcciones IP de ZooKeeper y el agente.
Creación de temas
Conéctese al clúster principal con SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netReemplace
sshuserpor el nombre de usuario SSH que usó al crear el clúster. ReemplacePRIMARYCLUSTERpor el nombre base que usó al crear el clúster.Para más información, consulte Uso SSH con HDInsight.
Use el comando siguiente para crear dos variables de entorno con los hosts de Apache ZooKeeper y los hosts de agente para el clúster principal. Reemplace las cadenas como
ZOOKEEPER_IP_ADDRESS1por las direcciones IP reales que anotó anteriormente; por ejemplo,10.23.0.11y10.23.0.7. Ocurre lo mismo conBROKER_IP_ADDRESS1. Si usa la resolución FQDN con un servidor DNS personalizado, siga estos pasos para obtener los nombres de agente y de ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Para crear un tema llamado
testtopic, use el comando siguiente:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSUse el siguiente comando para comprobar que se creó el tema:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSLa respuesta contiene
testtopic.Use lo siguiente para ver la información del host del agente de este clúster (el principal):
echo $PRIMARY_BROKERHOSTSEsto devuelve información similar al texto siguiente:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Guarde esta información. Se usa en la siguiente sección.
Configuración del reflejo
Conéctese al clúster secundario mediante otra sesión SSH:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netReemplace
sshuserpor el nombre de usuario SSH que usó al crear el clúster. ReemplaceSECONDARYCLUSTERpor el nombre que usó al crear el clúster.Para más información, consulte Uso SSH con HDInsight.
Use un archivo
consumer.propertiespara configurar la comunicación con el clúster principal. Para crear el archivo, use el comando siguiente:nano consumer.propertiesUse el texto siguiente como contenido del archivo
consumer.properties:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupReemplace
PRIMARY_BROKERHOSTSpor las direcciones IP del host de agente del clúster principal.Este archivo contiene la información del consumidor que se va a usar cuando se lea desde el clúster Kafka principal. Para obtener más información, consulte las configuraciones de consumidor en
kafka.apache.org.Para guardar el archivo, presione Ctrl+X y después Y; a continuación, presione Entrar.
Antes de configurar el productor que se comunica con el clúster secundario, configure una variable para las direcciones IP del agente del clúster secundario. Utilice los comandos siguientes para crear esta variable:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'La información devuelta por el comando
echo $SECONDARY_BROKERHOSTSdebe ser similar a la siguiente:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Use un archivo
producer.propertiespara comunicarse con el clúster secundario. Para crear el archivo, use el comando siguiente:nano producer.propertiesUse el texto siguiente como contenido del archivo
producer.properties:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneSustituya
SECONDARY_BROKERHOSTSpor las direcciones IP de los agentes que usó en el paso anterior.Para obtener más información, consulte las configuraciones de productor en
kafka.apache.org.Use los comandos siguientes para crear una variable de entorno con las direcciones IP de los hosts de ZooKeeper del clúster secundario:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'La configuración predeterminada para Kafka en HDInsight no permite la creación automática de temas. Debe usar una de las opciones siguientes antes de iniciar el proceso de creación de reflejo:
Create the topics on the destination cluster (Crear los temas en el clúster de destino): esta opción también le permite establecer el número de particiones y el factor de replicación.
Puede crear temas con antelación mediante el comando siguiente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSReemplace
testtopicpor el nombre del tema que se va a crear.Configurar el clúster para la creación automática de temas: esta opción permite a MirrorMaker crear temas de forma automática. Tenga en cuenta que puede crearlos con un número distinto de particiones o un factor de replicación diferente al del tema principal.
Para configurar el clúster secundario de forma que cree automáticamente los temas, siga estos pasos:
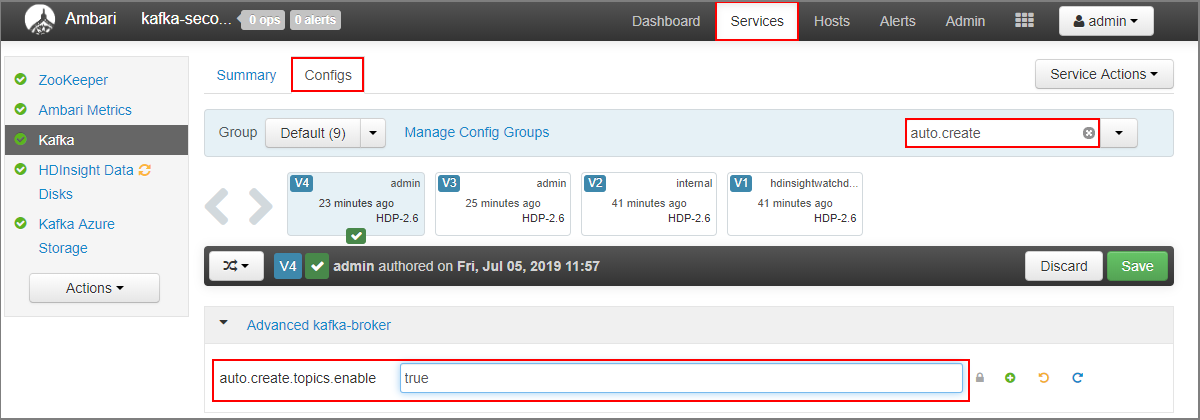
- Vaya al panel de Ambari del clúster secundario:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Seleccione Services> (Servicios) Kafka. A continuación, seleccione la pestaña Configs (Configuraciones).
- En el campo Filtro, escriba un valor de
auto.create. La lista de propiedades se filtra y se muestra el valorauto.create.topics.enable. - Cambie el valor de
auto.create.topics.enableatruey, luego, seleccione Guardar. Agregue una nota y, a continuación, seleccione de nuevo Guardar. - Seleccione el servicio Kafka, seleccione Reiniciar y luego seleccione Restart all affected (Reiniciar todos los afectados). Cuando se le solicite, seleccione Confirm Restart All (Confirmar reiniciar todo).
- Vaya al panel de Ambari del clúster secundario:
Inicio de MirrorMaker
Nota
Este artículo contiene referencias a un término que Microsoft ya no utiliza. Cuando se quite el término del software, se quitará también del artículo.
En la conexión SSH con el clúster secundario, use el siguiente comando para iniciar el proceso de MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Parámetros que se utilizan en este ejemplo:
Parámetro Descripción --consumer.configespecifica el archivo que contiene las propiedades de consumidor. Estas propiedades se usan para crear un consumidor que lea los datos desde el clúster de Kafka principal. --producer.configespecifica el archivo que contiene las propiedades de productor. Estas propiedades se usan para crear un productor que escriba en el clúster de Kafka secundario. --whitelistlista de temas del clúster principal que MirrorMaker replica en el secundario. --num.streamsnúmero de subprocesos de consumidor para crear. Ahora, el consumidor del nodo secundario espera a recibir mensajes.
En la conexión SSH con el clúster principal, use el siguiente comando para iniciar un productor y enviar mensajes al tema:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicCuando llegue a una línea en blanco con un cursor, escriba algunos mensajes de texto. Los mensajes se envían al tema del clúster principal. Cuando haya terminado, presione Ctrl + C para finalizar el proceso de productor.
En la conexión SSH con el clúster secundario, use Ctrl + C para iniciar el proceso de MirrorMaker. El proceso puede tardar varios segundos en finalizar. Para comprobar que los mensajes se han replicado en el clúster secundario, use el siguiente comando:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningLa lista de temas ahora incluye
testtopic, que se crea cuando MirrorMaster refleja el tema del clúster principal en el secundario. Los mensajes recuperados del tema son los mismos que los que se especificaron en el clúster principal.
Eliminación del clúster
Advertencia
La facturación de los clústeres de HDInsight se prorratea por minuto, tanto si se usan como si no. Por consiguiente, asegúrese de eliminar el clúster cuando termine de usarlo. Consulte Eliminación de un clúster de HDInsight.
Al seguir los pasos de este artículo, se crearon clústeres en diferentes grupos de recursos de Azure. Para eliminar todos los recursos que se han creado, puede eliminar los dos grupos de recursos: kafka-primary-rg y kafka-secondary_rg. Al eliminar los grupos de recursos, se eliminan todos los recursos que se crearon al seguir el procedimiento descrito en este artículo, incluidos los clústeres, las redes virtuales y las cuentas de almacenamiento.
Pasos siguientes
En este artículo, ha aprendido a usar MirrorMaker para crear una réplica de un clúster de Apache Kafka. Utilice los vínculos siguientes para conocer otras formas de trabajar con Kafka:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de