En este artículo se describen los procedimientos recomendados para supervisar una aplicación de microservicios que se ejecuta en Azure Kubernetes Service (AKS). Los temas específicos incluyen la recopilación de telemetría, la supervisión del estado del clúster, las métricas, el registro, el registro estructurado y el seguimiento distribuido. Este último se ilustra en este diagrama:

Descargue un archivo Visio de esta arquitectura.
Recopilación de telemetría
En las aplicaciones complejas, en algún momento algo puede salir mal. En una aplicación de microservicios, necesita realizar un seguimiento de lo que está sucediendo en docenas o incluso centenares de servicios. Para comprender lo que está pasando, tiene que recopilar la telemetría de la aplicación. Los datos de telemetría se pueden dividir en estas categorías: registros, seguimientos y métricas.
Los registros son registros de eventos basados en texto que tienen lugar mientras la aplicación está en ejecución. Incluyen elementos como registros de aplicación (instrucciones de seguimiento) y registros de servidor web. Los registros son sobre todo útiles para analizar la causa raíz y los análisis forenses.
Los seguimientos, también llamados operaciones, conectan los pasos de una solicitud con las distintas llamadas dentro de los microservicios y entre ellos. Pueden proporcionar observabilidad estructurada en las interacciones de los componentes del sistema. Los seguimientos pueden comenzar al principio del proceso de solicitud, como dentro de la interfaz de usuario de una aplicación, y se pueden propagar por los servicios de red, a través de una red de microservicios que controlan la solicitud.
- Los intervalos son unidades de trabajo dentro de un seguimiento. Cada intervalo está conectado a un único seguimiento y se puede anidar con otros intervalos. Suelen corresponderse con solicitudes individuales en una operación multiservicio, pero también pueden definir el trabajo en componentes individuales dentro de un servicio. Los intervalos también hacen un seguimiento de las llamadas salientes de un servicio a otro. (A veces, los intervalos se denominan registros de dependencia).
Las métricas son valores numéricos que se pueden analizar. Puede usarlas para observar un sistema en tiempo real (o casi en tiempo real) o para analizar las tendencias de rendimiento a lo largo del tiempo. Para comprender un sistema de forma holística, tiene que recopilar métricas en distintos niveles de la arquitectura, desde la infraestructura física hasta la aplicación, entre las que se incluyen:
Métricas de nivel de nodo, lo que incluye uso de CPU, memoria, red, disco y sistema de archivos. Las métricas del sistema le ayudan a comprender la asignación de recursos para cada nodo del clúster y solucionar problemas de valores atípicos.
Métricas de contenedor. En el caso de las aplicaciones en contenedores, debe recopilar métricas en el nivel de contenedor, no solo en el nivel de máquina virtual.
Métricas de aplicación. Estas métricas son pertinentes para conocer el comportamiento de un servicio. Algunos ejemplos son el número de solicitudes HTTP entrantes en cola, la latencia de solicitud y la longitud de cola de mensajes. Las aplicaciones también pueden usar métricas personalizadas que son específicas del dominio, como el número de transacciones de negocio procesadas por minuto.
Métricas de servicios dependientes. Los servicios a veces llaman a servicios o puntos de conexión externos, como servicios PaaS o SaaS administrados. Los servicios de terceros pueden no proporcionar las métricas. Si no es así, tendrá que depender de sus propias métricas de aplicación para realizar el seguimiento de estadísticas de latencia y tasa de errores.
Supervisión del estado del clúster
Use Azure Monitor para supervisar el estado general de los clústeres. En la captura de pantalla siguiente se muestra un clúster con errores críticos en pods implementados por el usuario:

Desde aquí, puede profundizar más para encontrar el problema. Por ejemplo, si el estado del pod es ImagePullBackoff, Kubernetes no pudo extraer la imagen de contenedor del registro. Este problema se puede deber a una etiqueta de contenedor no válida o a un error de autenticación al intentar la extracción del registro.
Si un contenedor se bloquea, el contenedor State se convierte en Waiting, con un Reason de CrashLoopBackOff. En un escenario típico en el que un pod forma parte de un conjunto de réplicas y la directiva de reintentos es Always, este problema no se mostrará como un error en el estado del clúster. Sin embargo, puede ejecutar consultas o configurar alertas para esta condición. Para más información, consulte Supervisión del rendimiento del clúster de AKS con Azure Monitor Container Insights.
Hay varios libros específicos del contenedor disponibles en el panel libros de un recurso de AKS. Puede usar estos libros para obtener información general rápida, solución de problemas, administración e información. En la captura de pantalla siguiente se muestra una lista de libros que están disponibles de forma predeterminada para las cargas de trabajo de AKS.

Métricas
Se recomienda usar Azure Monitor para recopilar y ver las métricas de los clústeres de AKS y cualquier otro servicio de Azure dependiente.
Para las métricas del clúster y del contenedor, habilite Azure Monitor Container Insights. Cuando esta característica está habilitada, Monitor recopila las métricas de memoria y de procesador de los controladores, los nodos y los contenedores mediante la API de métricas de Kubernetes. Para más información sobre las métricas que están disponibles mediante Container Insights, consulte Supervisión del rendimiento del clúster de AKS con Azure Monitor Container Insights.
Use Application Insights para recopilar las métricas de la aplicación. Application Insights es un servicio de Application Performance Management (APM) extensible. Para utilizarlo, instale un paquete de instrumentación en la aplicación. Este paquete supervisa la aplicación y envía los datos de telemetría a Application Insights. También puede extraer datos de telemetría desde el entorno de host. A continuación, los datos se envían a Monitor. Application Insights también proporciona una correlación y un seguimiento de dependencias integrados. (Consulte Seguimiento distribuido, más adelante en este artículo).
Application Insights tiene un rendimiento máximo medido en eventos por segundo y limita la telemetría si la velocidad de los datos supera el límite. Para más información, consulte Límites de Application Insights. Cree instancias diferentes de Application Insights para cada entorno, de modo que los entornos de desarrollo y pruebas no compitan con los datos de telemetría de producción por la cuota.
Una única operación puede generar varios eventos de telemetría, por lo que si la aplicación experimenta un gran volumen de tráfico, es probable que se vea limitada. Para mitigar este problema, puede realizar un muestreo para reducir el tráfico de telemetría. La contrapartida es que sus métricas serán menos precisas, a menos que la instrumentación admita la agregación previa. En ese caso, habrá menos ejemplos de seguimiento para solucionar problemas, pero las métricas mantendrán la precisión. Para más información, consulte Muestreo en Application Insights. También puede reducir el volumen de datos mediante la agregación previa de métricas. Es decir, puede calcular valores estadísticos, como la desviación media y estándar, y enviar esos valores en lugar de la telemetría sin procesar. En esta entrada de blog se describe un enfoque sobre el uso de Application Insights a escala: Supervisión de Azure y análisis a escala.
Si la velocidad de los datos es lo suficientemente alta como para desencadenar la limitación y el muestreo o la agregación no son aceptables, considere la posibilidad de exportar las métricas a una base de datos de series temporales, como Azure Data Explorer, Prometheus o InfluxDB, que se ejecuten en el clúster.
Azure Data Explorer es un servicio de exploración de datos nativo de Azure altamente escalable para datos de telemetría y de registro. Admite varios formatos de datos, un lenguaje de consulta enriquecido y conexiones para consumir datos en herramientas populares como Jupyter Notebooks y Grafana. Azure Data Explorer incluye conectores integrados para ingerir datos de registro y métricas a través de Azure Event Hubs. Para obtener más información, consulte Ingesta y consulta de datos de supervisión en Azure Data Explorer.
InfluxDB es un sistema basado en la inserción. Un agente tiene que insertar las métricas. Puede usar la pila TICK para configurar la supervisión de Kubernetes. Después, puede insertarla en InfluxDB mediante Telegraf, que es un agente para recopilar y notificar métricas. Puede usar InfluxDB para eventos irregulares y tipos de datos de cadena.
Prometheus es un sistema basado en la extracción. Periódicamente extrae métricas de ubicaciones configuradas. Prometheus puede extraer métricas generadas por Azure Monitor o kube-state-metrics. kube-state-metrics es un servicio que recopila métricas del servidor de API de Kubernetes y las pone a disposición de Prometheus (o un extractor que sea compatible con un punto de conexión de cliente de Prometheus). Para las métricas del sistema, use node-exporter, que es un exportador de Prometheus para las métricas del sistema. Prometheus admite datos de punto flotante pero no datos de cadena, por lo que es adecuado para las métricas del sistema pero no para los registros. El servidor de métricas de Kubernetes es un agregador de los datos de uso de los recursos en todo el clúster.
Registro
Estos son algunos de los desafíos generales del registro en una aplicación de microservicios:
- Comprender el procesamiento de un extremo a otro de una solicitud de cliente, en la que se pueden invocar varios servicios para controlar una única solicitud.
- Consolidar los registros de varios servicios en una única vista agregada.
- Analizar los registros que proceden de varios orígenes, que usan sus propios esquemas de registro o que no tienen un esquema determinado. Los registros pueden haber sido generados por componentes de terceros sobre los que no tiene control.
- Las arquitecturas de microservicios suelen generar un volumen mayor de registros que las arquitecturas monolíticas tradicionales, ya que hay más servicios, llamadas de red y pasos en una transacción. Esto significa que el propio registro puede ser un cuello de botella de rendimiento o de recursos para la aplicación.
Hay algunos desafíos adicionales para una arquitectura basada en Kubernetes:
- Los contenedores se pueden trasladar y volver a programar.
- Kubernetes tiene una abstracción de red que usa direcciones IP virtuales y asignaciones de puertos.
En Kubernetes, el enfoque estándar para el registro es que un contenedor escriba los registros en stdout y stderr. El motor de contenedores redirige estos flujos a un controlador de registro. Para facilitar la consulta y evitar la posible pérdida de datos de registro si se bloquea un nodo, el enfoque habitual es recopilar los registros de cada nodo y enviarlos a una ubicación de almacenamiento central.
Azure Monitor se integra con AKS para posibilitar este enfoque. Monitor recopila los registros de contenedor y los envía a un área de trabajo de Log Analytics. Desde allí, puede usar el Lenguaje de consulta Kusto para escribir consultas sobre los registros agregados. Por ejemplo, esta es una consulta de Kusto para mostrar los registros de contenedor de un pod especificado:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure Monitor es un servicio administrado y la configuración de un clúster de AKS para que utilice Monitor es un simple cambio en la configuración en la CLI o una plantilla de Azure Resource Manager. (Para más información, consulte Habilitación de la información de contenedores de Azure Monitor). Otra ventaja de utilizar Azure Monitor es que consolida los registros de AKS con otros registros de la plataforma de Azure, lo que proporciona una experiencia de supervisión unificada.
Azure Monitor se factura por gigabyte (GB) de datos ingeridos en el servicio. (Consulte Precios de Azure Monitor). En grandes volúmenes, es posible que el costo se convierta en una consideración. Hay muchas alternativas de código abierto disponibles para el ecosistema de Kubernetes. Por ejemplo, muchas organizaciones usan Fluentd con Elasticsearch. Fluentd es un recopilador de datos de código abierto y Elasticsearch es una base de datos de documentos que se usa para las búsquedas. Un desafío con estas opciones es que requieren configuración y administración adicionales del clúster. En el caso de una carga de trabajo de producción, puede que tenga que experimentar con las opciones de configuración. También necesitará supervisar el rendimiento de la infraestructura de registro.
OpenTelemetry
OpenTelemetry es una iniciativa multisectorial para mejorar el seguimiento mediante la normalización de la interfaz de las distintas aplicaciones, bibliotecas, telemetría y recopiladores de datos. Cuando usa un marco de trabajo y una biblioteca que se instrumenta con OpenTelemetry, la mayor parte del trabajo del seguimiento de operaciones, que son tradicionalmente operaciones del sistema, se controla con las bibliotecas subyacentes, incluidos los siguientes escenarios comunes:
- Registro de operaciones de solicitud básicas, como la hora de inicio, la hora de salida y la duración
- Excepciones lanzadas
- Propagación del contexto (por ejemplo, enviar un identificador de correlación por los límites de las llamadas HTTP)
En su lugar, las bibliotecas base y los marcos de trabajo que controlan estas operaciones crean estructuras interrelacionadas de datos de seguimiento e intervalos enriquecidos, y las propagan por los contextos. Antes de OpenTelemetry, normalmente solo se insertaban como mensajes de registro especiales o como estructuras de datos propietarias específicas del proveedor que creó las herramientas de supervisión. OpenTelemetry también fomenta un modelo de datos de instrumentación más completo que un enfoque tradicional de inicio de sesión previo, y los registros son más útiles, ya que los mensajes de registro están vinculados a los seguimientos e intervalos donde se generaron. Con frecuencia, esto facilita la búsqueda de registros asociados a una operación o solicitud concretas.
Muchos de los SDK de Azure se han instrumentado con OpenTelemetry o están en proceso de implementación.
Un desarrollador de aplicaciones puede agregar instrumentación manual mediante los SDK de OpenTelemetry para hacer las siguientes actividades:
- Agregar instrumentación allí donde una biblioteca subyacente no la proporcione.
- Enriquezca el contexto de seguimiento agregando intervalos para exponer unidades de trabajo específicas de la aplicación (por ejemplo, un bucle de pedido que crea un intervalo para el procesamiento de cada línea de pedido).
- Enriquezca los intervalos existentes con claves de entidad para facilitar el seguimiento. (Por ejemplo, agregue un valor/clave de OrderID a la solicitud que procesa dicha orden). Estas claves las exponen como valores estructurados que se pueden consultar, filtrar y agregar (sin analizar cadenas de mensajes de registro ni buscar combinaciones de secuencias de mensajes de registro, como es habitual en el enfoque de inicio de sesión).
- Propagar el contexto de seguimiento mediante el acceso a los atributos trace y span, insertando traceIds en respuestas y cargas o leyendo traceIds de los mensajes entrantes, con el fin de crear solicitudes e intervalos.
Obtenga más información sobre la instrumentación y los SDK de OpenTelemetry, en la documentación de OpenTelemetry.
Application Insights
Application Insights recopila datos enriquecidos de OpenTelemetry y sus bibliotecas de instrumentación, y los captura en un almacén de datos eficaz para proporcionar una visualización enriquecida y compatibilidad con consultas. Las bibliotecas de instrumentación basadas en OpenTelemetry de Application Insights, para lenguajes como .NET, Java, Node.js o Python, facilitan el envío de datos de telemetría a Application Insights.
Si usa .NET Core, se recomienda usar también la biblioteca Application Insights para Kubernetes. Esta biblioteca enriquece los seguimientos de Application Insights con información adicional, como el contenedor, el nodo, el pod, las etiquetas y el conjunto de réplicas.
Application Insights asigna el contexto de OpenTelemetry a su modelo de datos interno:
- Seguimiento -> operación
- ID de seguimiento -> identificador de operación
- Intervalo -> solicitud o dependencia
Tome en cuenta las siguientes consideraciones:
- Application Insights limita los datos de telemetría si la velocidad de los datos supera un límite máximo. Para más información, consulte Límites de Application Insights. Una única operación puede generar varios eventos de telemetría, por lo que si la aplicación experimenta un gran volumen de tráfico, es probable que se vea limitada.
- Dado que Application Insights procesa los datos por lotes, puede perder un lote si un proceso produce un error con una excepción no controlada.
- Application Insights se factura en función del volumen de datos. Para más información, consulte Administración de precios y volúmenes de datos de Application Insights.
Registro estructurado
Use el registro estructurado siempre que pueda para facilitar el análisis de los registros. Cuando usa el registro estructurado, la aplicación escribe los registros en un formato estructurado, como JSON, en lugar de generar cadenas de texto no estructuradas. Hay muchas bibliotecas de registro estructurado disponibles. Por ejemplo, a continuación se muestra una instrucción de registro que usa la biblioteca Serilog para .NET Core:
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
En este caso, la llamada a LogInformation incluye el parámetro Id y el parámetro DeliveryInfo. Cuando usa el registro estructurado, estos valores no se interpolan en la cadena del mensaje. En su lugar, la salida del registro tendrá un aspecto similar al siguiente:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Se trata de una cadena JSON, en la que el campo @t es una marca de tiempo, el campo @mt es la cadena del mensaje y los pares de clave-valor restantes son los parámetros. La salida en formato JSON facilita la consulta de los datos de una manera estructurada. Por ejemplo, la consulta de Log Analytics siguiente, escrita en el lenguaje de consulta Kusto, busca instancias de este mensaje determinado en todos los contenedores llamados fabrikam-delivery:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Si ve el resultado en Azure Portal, puede ver que DeliveryInfo es un registro estructurado que contiene la representación serializada del modelo DeliveryInfo:

Este es el código JSON de este ejemplo:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Muchos mensajes de registro marcan el inicio o el final de una unidad de trabajo, o conectan una entidad empresarial con un conjunto de mensajes y operaciones con fines de trazabilidad. En muchos casos, enriquecer los objetos de intervalo y solicitud de OpenTelemetry es mejor que registrar solo el inicio y el final de esa operación. De esta manera, se agrega ese contexto a todos los seguimientos conectados y operaciones secundarias, y coloca esa información en el ámbito de la operación completa. Los SDK de OpenTelemetry para varios lenguajes admiten la creación de intervalos o la adición de atributos personalizados en intervalos. Por ejemplo, el código siguiente usa el SDK de OpenTelemetry de Java, que es compatible con Application Insights. Un intervalo principal existente (por ejemplo, un intervalo de solicitud asociado a una llamada del controlador REST y creado por el marco de trabajo web que se esté utilizando) se puede enriquecer con un identificador de entidad asociado a él, como se muestra aquí:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Este código establece una clave o un valor en el intervalo actual, que está conectado a las operaciones y los mensajes de registro que se producen en ese intervalo. El valor aparece en el objeto de solicitud de Application Insights, como se muestra aquí:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Esta técnica es más eficaz cuando se usa con registros, filtros y anotación de seguimientos de registro con contexto de intervalo, como se muestra aquí:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Si usa una biblioteca o un marco de trabajo que ya está instrumentado con OpenTelemetry, permite controlar la creación de intervalos y solicitudes, pero el código de la aplicación también puede crear unidades de trabajo. Por ejemplo, un método que recorre en bucle una matriz de entidades y que realiza trabajo en cada una de ellas puede crear un intervalo para cada iteración del bucle de procesamiento. Para obtener información sobre cómo agregar instrumentación a código de aplicación y biblioteca, consulte la documentación de instrumentación de OpenTelemery.
Seguimiento distribuido
Uno de los desafíos al usar microservicios es entender el flujo de eventos entre servicios. Una única transacción puede implicar llamadas a varios servicios.
Ejemplo de seguimiento distribuido
Este ejemplo describe la ruta de acceso de una transacción distribuida a través de un conjunto de microservicios. El ejemplo se basa en una aplicación de entrega de drones.
En este escenario, la transacción distribuida incluye estos pasos:
- El servicio de ingesta coloca un mensaje en una cola de Azure Service Bus.
- El servicio de flujos de trabajo extrae el mensaje de la cola.
- El servicio de flujos de trabajo llama a tres servicios de back-end para procesar la solicitud (Dron Scheduler, Package y Delivery).
En la captura de pantalla siguiente se muestra el mapa de aplicación correspondiente a la aplicación de entrega de drones. Este mapa muestra que las llamadas al punto de conexión de API público producen un flujo de trabajo que implica a cinco microservicios.
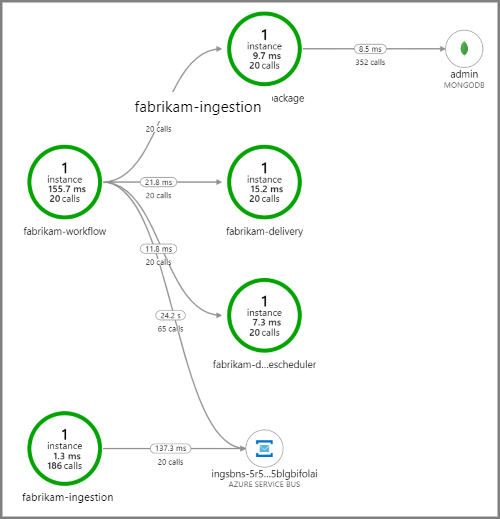
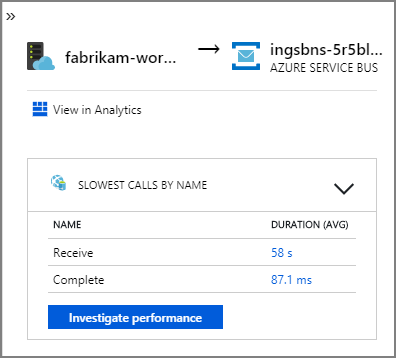
Las flechas que van desde fabrikam-workflow y fabrikam-ingestion a una cola de Service Bus muestran dónde se envían y reciben los mensajes. No se puede indicar en el diagrama qué servicio está enviando mensajes y cuál está recibiéndolos. Las flechas solo muestran que ambos servicios llaman a Service Bus. Sin embargo, la información sobre qué servicio está enviando y cuál está recibiendo está disponible en los detalles:
Dado que cada llamada incluye un identificador de operación, también puede ver los pasos de un extremo a otro de una única transacción, incluidas la información de tiempos y las llamadas HTTP de cada paso. Esta es la visualización de una transacción de este tipo:

Esta visualización muestra los pasos desde el servicio de ingesta hasta la cola, desde la cola hasta el servicio de flujos de trabajo y desde el servicio de flujos de trabajo hasta los otros servicios de back-end. El último paso es el servicio de flujos de trabajo que marca el mensaje de Service Bus como completado.
En este ejemplo se muestran las llamadas a un servicio back-end con errores:
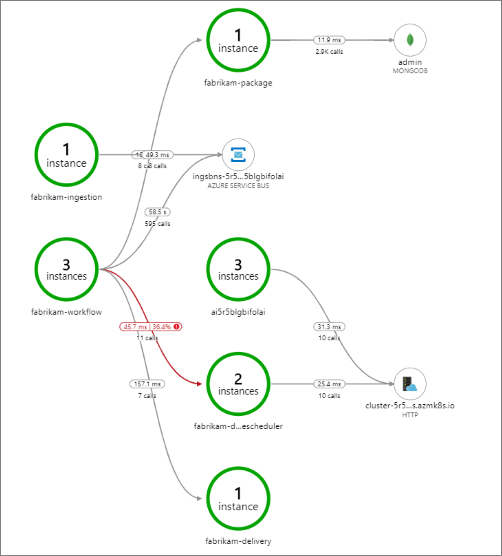
Este mapa muestra que un alto porcentaje (36 %) de las llamadas al servicio Drone Scheduler durante el período de consulta tuvieron errores. La vista de transacción de un extremo a otro revela que se produce una excepción cuando se envía una solicitud HTTP PUT al servicio:

Si profundiza más, puede ver que la excepción es una excepción de socket: "No existe tal dispositivo o dirección".
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Esta excepción sugiere que el servicio back-end no es accesible. En este momento, puede usar kubectl para ver la configuración de implementación. En este ejemplo, el nombre de host del servicio no se resuelve debido a un error en los archivos de configuración de Kubernetes. En el artículo Depuración de servicios de la documentación de Kubernetes se ofrecen sugerencias para diagnosticar este tipo de error.
Estas son algunas causas comunes de los errores:
- Errores de código. Estos errores pueden aparecer como:
- Excepciones. Consulte los registros de Application Insights para ver los detalles de la excepción.
- Error en un proceso. Consulte el estado del contenedor y el pod y consulte los registros de contenedor o los seguimientos de Application Insights.
- Errores HTTP 5xx.
- Agotamiento de recursos:
- Busque limitaciones (HTTP 429) o errores de tiempos de espera de las solicitudes.
- Examine las métricas de contenedor para la CPU, la memoria y el disco.
- Consulte las configuraciones de los límites de recursos del contenedor y el pod.
- Detección de servicios. Examine la configuración del servicio Kubernetes y las asignaciones de puertos.
- API no coincidente. Busque errores HTTP 400. Si las API tienen versiones, observe a qué versión se está llamando.
- Error al extraer una imagen de contenedor. Consulte la especificación del pod. Asegúrese también de que el clúster esté autorizado para realizar extracciones del registro de contenedor.
- Problemas de RBAC.
Pasos siguientes
Más información sobre las características de Azure Monitor que hacen posible la supervisión de aplicaciones en AKS:
- Introducción a Azure Monitor Container Insights
- Supervisión del rendimiento del clúster de AKS con Azure Monitor Container Insights