Migración a La Cumbre de innovación:
Obtenga información sobre cómo migrar y modernizar a Azure puede aumentar el rendimiento, la resistencia y la seguridad de su empresa, lo que le permite adoptar completamente la inteligencia artificial.Regístrese ahora
Este explorador ya no se admite.
Actualice a Microsoft Edge para aprovechar las características y actualizaciones de seguridad más recientes, y disponer de soporte técnico.
Los grupos de disponibilidad AlwaysOn en Azure Virtual Machines son similares a los grupos de disponibilidad AlwaysOn en el entorno local, y se basan en el clúster de conmutación por error de Windows Server subyacente. Sin embargo, dado que las máquinas virtuales se hospedan en Azure, existen algunas consideraciones adicionales, como la redundancia de máquinas virtuales y el enrutamiento del tráfico en la red de Azure.
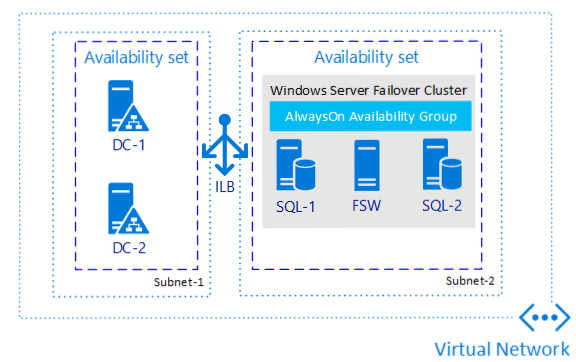
En el diagrama siguiente se muestra un grupo de disponibilidad para SQL Server en Azure Virtual Machines:
Nota
Ahora es posible migrar mediante lift and shift la solución de grupo de disponibilidad a SQL Server en máquinas virtuales de Azure mediante Azure Migrate. Para más información, consulte Migración del grupo de disponibilidad.
La colocación de un conjunto de máquinas virtuales en el mismo conjunto de disponibilidad protege frente a interrupciones en un centro de datos provocadas por un error del equipo (las máquinas virtuales dentro de un conjunto de disponibilidad no comparten recursos) o actualizaciones (las máquinas virtuales de un conjunto de disponibilidad no se actualizan al mismo tiempo).
Las zonas de disponibilidad protegen contra el error de un centro de datos completo, y cada zona representa un conjunto de centros de datos dentro de una región. Al asegurarse de que los recursos se colocan en diferentes zonas de disponibilidad, ninguna interrupción a nivel de centro de datos podrá desconectar todas las VM.
Al crear máquinas virtuales de Azure, debe elegir entre configurar conjuntos de disponibilidad y zonas de disponibilidad. Una máquina virtual de Azure no puede participar en ambos.
Aunque las zonas de disponibilidad pueden brindar una mejor disponibilidad que los conjuntos de disponibilidad (un 99,99 % frente al 99,95 %), el rendimiento también se debe tener en cuenta. Las máquinas virtuales dentro de un conjunto de disponibilidad se pueden colocar en un grupo de ubicación por proximidad que garantice que están próximas unas de otras, lo que minimiza la latencia de red entre ellas. Las máquinas virtuales ubicadas en distintas zonas de disponibilidad tienen una mayor latencia de red entre ellas, lo que puede aumentar el tiempo que se tarda en sincronizar los datos entre la réplica principal y las secundarias. Esto puede provocar retrasos en la réplica principal, así como aumentar la probabilidad de pérdida de datos en caso de una conmutación por error no planeada. Es importante probar la solución propuesta con carga y asegurarse de que cumpla con los Acuerdos de Nivel de Servicio tanto en lo relativo al rendimiento como a la disponibilidad.
Conectividad
Para que coincida con la experiencia local para conectarse al cliente de escucha del grupo de disponibilidad, implemente las máquinas virtuales de SQL Server en varias subredes dentro de la misma red virtual. Tener varias subredes elimina la necesidad de la dependencia adicional de una instancia de Azure Load Balancer o un nombre de red distribuida (DNN) para enrutar el tráfico al cliente de escucha.
Si implementa las máquinas virtuales de SQL Server en una sola subred, puede configurar un nombre de red virtual (VNN) y una instancia de Azure Load Balancer, o un nombre de red distribuida (DNN) para enrutar el tráfico al cliente de escucha del grupo de disponibilidad. Revise las diferencias entre los dos y, a continuación, implemente un nombre de red distribuida (DNN) o un nombre de red virtual (VNN) para el grupo de disponibilidad.
La mayoría de las características de SQL Server funcionan de manera transparente con los grupos de disponibilidad cuando se usa el DNN, pero hay determinadas características que pueden exigir una consideración especial. Para más información, consulte Interoperabilidad de grupos de disponibilidad con DNN.
Además, hay algunas diferencias de comportamiento entre la funcionalidad del agente de escucha de VNN y el agente de escucha de DNN que son importantes tener en cuenta:
Tiempo de conmutación por error: el tiempo de conmutación por error es más rápido cuando se usa un cliente de escucha de DNN, ya que no es necesario esperar a que el equilibrador de carga de red detecte el evento de error y cambie su enrutamiento.
Conexiones existentes: Las conexiones establecidas con una base de datos específica dentro de un grupo de disponibilidad de conmutación por error se cerrarán, pero otras conexiones a la réplica principal permanecerán abiertas, ya que el DNN permanece en línea durante el proceso de conmutación por error. Esto es diferente de un entorno VNN tradicional en el que todas las conexiones a la réplica principal normalmente se cierran cuando se conmuta por error el grupo de disponibilidad, el agente de escucha se queda sin conexión y la réplica principal cambia al rol secundario. Al usar un agente de escucha de DNN, es posible que tenga que ajustar las cadenas de conexión de la aplicación para asegurarse de que las conexiones se redirijan a la nueva réplica principal tras la conmutación por error.
Transacciones abiertas: Las transacciones abiertas en una base de datos de un grupo de disponibilidad con conmutación por error se cerrarán y revertirán, y tendrá que volver a conectarse manualmente. Por ejemplo, en SQL Server Management Studio, cierre la ventana de consulta y abra otra nueva.
Nota
Si tiene varios grupos de disponibilidad o FCI en el mismo clúster y utiliza una escucha de DNN o VNN, cada grupo de disponibilidad o FCI necesita su propio punto de conexión independiente.
La configuración de un agente de escucha de VNN en Azure requiere un equilibrador de carga. Hay dos opciones principales para los equilibradores de carga en Azure: externa (pública) o interna. El equilibrador de carga externo (público) es un equilibrador de carga accesible desde Internet y está asociado a una IP virtual pública que es accesible a través de Internet. Un equilibrador de carga interno solo admite clientes dentro de la misma red virtual. Para cualquiera de los tipos de equilibrador de carga, tiene que habilitar Direct Server Return.
Puede seguir conectándose a cada réplica de disponibilidad por separado conectándose directamente a la instancia del servicio. Además, como los grupos de disponibilidad son compatibles con las versiones anteriores de los clientes de creación de reflejo de la base de datos, puede conectarse a las réplicas de disponibilidad como asociados de creación de reflejo de la base de datos siempre y cuando las réplicas estén configuradas de forma similar a la creación de reflejo de la base de datos:
Hay una réplica principal y una réplica secundaria.
La réplica secundaria está configurada como no legible (la opción Secundaria legible está establecida en No).
A continuación, se muestra una cadena de conexión de cliente de ejemplo correspondiente a esta configuración similar a la creación de reflejo de la base de datos que usa ADO.NET o SQL Server Native Client:
Consola
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Para obtener más información sobre la conectividad del cliente, consulte:
Al crear un cliente de escucha de grupo de disponibilidad en un clúster de conmutación por error de Windows Server (WSFC) tradicional local, se crea un registro DNS para el cliente de escucha con la dirección IP que se proporcione y esta dirección IP se asigna a la dirección MAC de la réplica principal actual en las tablas de ARP de conmutadores y enrutadores de la red local. Para ello, el clúster usa Gratuitous ARP (GARP), que difunde a la red la última asignación de direcciones IP a MAC cada vez que se selecciona una nueva réplica principal tras la conmutación por error. En este caso, la dirección IP es del cliente de escucha y la dirección MAC es de la réplica principal actual. GARP fuerza una actualización a las entradas de la tabla de ARP de los conmutadores y enrutadores, y los usuarios que se conectan a la dirección IP del cliente de escucha se enrutan sin problemas a la réplica principal actual.
Por motivos de seguridad, no se permite la difusión en ninguna nube pública (Azure, Google, AWS), por lo que no se admiten los usos de ARP y GARP en Azure. Para superar esta diferencia en los entornos de red, las máquinas virtuales con SQL Server de un único grupo de disponibilidad de subred dependen de equilibradores de carga para enrutar el tráfico a las direcciones IP adecuadas. Los equilibradores de carga se configuran con una dirección IP de front-end que corresponde al cliente de escucha y se asigna un puerto de sondeo para que Azure Load Balancer sondee periódicamente el estado de las réplicas del grupo de disponibilidad. Puesto que solo la réplica principal de VM con SQL Server responde al sondeo TCP, el tráfico entrante se enruta a la máquina virtual que responde correctamente al sondeo. Además, el puerto de sondeo correspondiente se configura como la dirección IP del clúster de WSFC, lo que garantiza que la réplica principal responda al sondeo TCP.
Los grupos de disponibilidad configurados en una sola subred deben usar un equilibrador de carga o un nombre de red distribuido (DNN) para enrutar el tráfico a la réplica adecuada. Para evitar estas dependencias, configure el grupo de disponibilidad en varias subredes para que el cliente de escucha del grupo de disponibilidad esté configurado con una dirección IP de una réplica en cada subred y pueda enrutar el tráfico correctamente.
Para SQL Server, la DLL de recursos del grupo de disponibilidad determina el estado del grupo de disponibilidad según el mecanismo de concesión del grupo de disponibilidad y la detección de estado de Always On. La DLL de recursos del grupo de disponibilidad expone el estado de los recursos a través de la operación IsAlive. El monitor de recursos sondea IsAlive en el intervalo de latidos del clúster, que se establece mediante los valores CrossSubnetDelay y SameSubnetDelay para todo el clúster. En un nodo principal, el servicio de clúster inicia la conmutación por error cada vez que la llamada de IsAlive a la DLL de recursos indica que el grupo de disponibilidad no tiene un estado correcto.
La DLL de recursos del grupo de disponibilidad supervisa el estado de los componentes internos de SQL Server. Sp_server_diagnostics notifica el estado de estos componentes a SQL Server en un intervalo controlado por HealthCheckTimeout.
A diferencia de otros mecanismos de conmutación por error, la instancia de SQL Server desempeña un rol activo en el mecanismo de concesión. El mecanismo de concesión se usa como validación Looks-Alive entre el host del recurso de clúster y el proceso de SQL Server. El mecanismo se usa para garantizar que los dos lados (el Servicio de clúster y el servicio de SQL Server) están en contacto con frecuencia, comprobando el estado del otro y evitando en última instancia un escenario de cerebro dividido.
Al configurar un grupo de disponibilidad en máquinas virtuales de Azure, a menudo es necesario configurar estos umbrales de manera diferente a como se configurarían en un entorno local. Para configurar los valores de umbral según los procedimientos recomendados para VM de Azure, consulte los procedimientos recomendados del clúster.
Configuración de red
Implemente las máquinas virtuales de SQL Server en varias subredes siempre que sea posible para evitar la dependencia de un nombre de red distribuida (DNN) o una instancia de Azure Load Balancer para enrutar el tráfico al cliente de escucha del grupo de disponibilidad.
En un clúster de conmutación por error de máquinas virtuales de Azure, se recomienda una sola NIC por servidor (nodo de clúster). Las redes de Azure tienen redundancia física, lo que hace que las NIC adicionales sean innecesarias en un clúster de conmutación por error de máquinas virtuales de Azure. Aunque el informe de validación del clúster emite una advertencia acerca de que los nodos solo son accesibles en una única red, esta advertencia puede omitirse de forma segura en los clústeres de conmutación por error de máquinas virtuales de Azure.
Grupo de disponibilidad básico
Como el grupo de disponibilidad básico no permite más de una réplica secundaria y no hay acceso de lectura a la réplica secundaria, puede usar las cadenas de conexión de creación de reflejo de la base de datos para los grupos de disponibilidad básicos. El uso de la cadena de conexión elimina la necesidad de tener agentes de escucha. La eliminación de la dependencia del agente de escucha es útil para los grupos de disponibilidad en VM de Azure, ya que elimina la necesidad de un equilibrador de carga o de tener que agregar direcciones IP adicionales al equilibrador de carga cuando se tienen varios agentes de escucha para bases de datos adicionales.
Por ejemplo, para conectarse explícitamente mediante TCP/IP a la base de datos AdventureWorks del grupo de disponibilidad en Replica_A o Replica_B de un grupo de disponibilidad básico (o cualquier grupo de disponibilidad que tenga solo una réplica secundaria y no se permita el acceso de lectura en la réplica secundaria), una aplicación cliente podría proporcionar la siguiente cadena de conexión de creación de reflejo de la base de datos para conectarse correctamente al grupo de disponibilidad.
Elimine la necesidad de una instancia de Azure Load Balancer o un nombre de red distribuida (DNN) para el grupo de disponibilidad Always On mediante la creación de las máquinas virtuales de SQL Server en varias subredes dentro de la misma red virtual de Azure.
Hay varias opciones para implementar un grupo de disponibilidad en SQL Server en Azure Virtual Machines, algunas con más automatización que otras.
En la tabla siguiente se proporciona una comparación de las opciones disponibles:
Administre una infraestructura de base de datos de SQL Server para bases de datos relacionales locales e híbridas en la nube mediante las ofertas de bases de datos relacionales PaaS de Microsoft.
En este tutorial se explica cómo configurar un grupo de disponibilidad Always On para SQL Server en máquinas virtuales de Azure con una réplica en una región distinta con respecto a la réplica principal.
Use Azure Portal para crear VM con SQL Server en varias subredes, un clúster de conmutación por error de Windows, un grupo de disponibilidad y un agente de escucha de grupo de disponibilidad para SQL Server en máquinas virtuales de Azure.
Obtenga información sobre las diferencias con la tecnología de Clúster de conmutación por error de Windows Server cuando se usa con SQL Server en VM de Azure, como grupos de disponibilidad e instancias de clúster de conmutación por error.
Use las plantillas de inicio rápido de Azure para crear el clúster de conmutación por error de Windows, unir las máquinas virtuales con SQL Server al clúster, crear la escucha y configurar el equilibrador de carga interno en Azure.
Aprenda a configurar una instancia de Azure Load Balancer para enrutar el tráfico al cliente de escucha del nombre de red virtual (VNN) para un grupo de disponibilidad con SQL Server en VM de Azure para lograr una alta disponibilidad y recuperación ante desastres (HADR).