¿Qué es Speech Service?
El servicio de Voz proporciona funcionalidades de conversión de voz en texto y texto a voz con un recurso de Voz. Puede transcribir voz en texto con alta precisión, producir voces de texto a voz de sonido natural, traducir audio hablado y usar el reconocimiento del hablante durante las conversaciones.

Cree voces personalizadas, agregue palabras específicas al vocabulario base o cree sus propios modelos. Ejecute el servicio de Voz en cualquier lugar, en la nube o en el perímetro en contenedores. Es fácil habilitar aplicaciones, herramientas y dispositivos mediante la CLI de Voz, el SDK de voz y las API REST.
El servicio de Voz está disponible para muchos idiomas, regiones y puntos de precio.
Escenarios de voz
Entre los escenarios comunes de voz, se incluyen:
- Subtítulos: obtenga información sobre la sincronización de los subtítulos con el audio de entrada, la aplicación de filtros de palabras soeces, la obtención de resultados parciales, la aplicación de personalizaciones y la identificación de los idiomas hablados en escenarios multilingües.
- Creación de contenido de audio: puede usar voces neuronales para que las interacciones con los bots de chat y los asistentes para voz sean más naturales y atractivas, para convertir textos digitales (por ejemplo, los libros electrónicos) en audiolibros y para mejorar los sistemas de navegación de los automóviles.
- Centro de llamadas: transcriba llamadas en tiempo real o procese las llamadas en lote, censure la información de identificación personal y extraiga información como opiniones para ayudar con el caso de uso del centro de llamadas.
- Aprendizaje de idiomas: proporcione comentarios de evaluación de la pronunciación a los aprendices de idiomas, admita la transcripción en tiempo real para conversaciones de aprendizaje remoto y lea materiales de enseñanza en voz alta con voces neuronales.
- Asistentes de voz: creen interfaces de conversación naturales, similares a las humanas, para sus aplicaciones y experiencias. La característica de asistente para voz proporciona una interacción rápida y confiable entre un dispositivo y la implementación de un asistente.
Microsoft usa el servicio de Voz para muchos escenarios, como los subtítulos en Teams, el dictado en Office 365 y la lectura en voz alta en el explorador Microsoft Edge.
Las funcionalidades de voz
En estas secciones se resumen las características de Voz con vínculos para más información.
Conversión de voz en texto
Use la conversión de voz en texto para transcribir audio en texto, ya sea en tiempo real o de forma asincrónica con la transcripción por lotes.
Sugerencia
Puede probar la conversión de voz en texto en tiempo real en Speech Studio sin registrarse ni escribir código.
Convierta audio en texto a partir de una variedad de orígenes, incluidos micrófonos, archivos de audio y almacenamiento de blobs. Utiliza la creación de diarios de los hablantes para determinar quién ha dicho qué y cuándo. Obtenga transcripciones legibles con formato y puntuación automáticos.
Es posible que el modelo base no sea suficiente si el audio contiene ruido ambiental o incluye una gran cantidad de jerga específica del sector y del dominio. En estos casos, puede crear y entrenar modelos de voz personalizados con datos acústicos, de lenguaje y pronunciación. Los modelos de voz personalizados son privados y pueden ofrecer una ventaja competitiva.
Conversión de voz en texto en tiempo real
Con la conversión de voz en texto en tiempo real, el audio se transcribe mientras la voz se reconoce desde un micrófono o archivo. Usa la conversión de voz en texto en tiempo real para las aplicaciones que necesiten transcribir audio en tiempo real, como:
- Transcripciones, títulos o subtítulos para reuniones en directo
- Diarización
- Evaluación de la pronunciación
- Asistencia del agente del centro de contactos
- Dictado
- Agentes de voz
API de Transcripción rápida
La API de Transcripción rápida se usa para transcribir archivos de audio con resultados de forma sincrónica y mucho más rápidos que en el audio en tiempo real. Use la transcripción rápida en los escenarios en los que necesite la transcripción de una grabación de audio lo más rápido posible con una latencia predecible, como los siguientes:
- Transcripción rápida de audio o vídeo, subtítulos y edición.
- Traducción de vídeo
Para empezar a trabajar con la transcripción rápida, vea Uso de la API de transcripción rápida.
Transcripción de Azure Batch
La transcripción por lotes se usa para transcribir una gran cantidad de audio en el almacenamiento. Puede apuntar a archivos de audio con un identificador URI de firma de acceso compartido (SAS) y recibir los resultados de las transcripciones de forma asincrónica. Usa la transcripción por lotes para aplicaciones que necesiten transcribir audio de forma masiva, como:
- Transcripciones, títulos o subtítulos para audio grabado previamente
- Análisis de llamadas posteriores al centro de contactos
- Diarización
Texto a voz
Con texto a voz, puede convertir el texto de entrada en una voz sintetizada similar a la humana. Use voces neuronales, que son voces similares a las humanas con tecnología de redes neuronales profundas. Use el Lenguaje de marcado de síntesis de voz (SSML) para un ajuste preciso del tono, la pronunciación, la velocidad del habla, el volumen y mucho más.
- Voz neuronal creada previamente: voces predefinidas muy naturales. Consulte los ejemplos de voz neuronal pregenerados en la Galería de voces y determine la voz adecuada para sus necesidades empresariales.
- Voz neuronal personalizada: además de las voces neuronales creadas previamente que vienen listas para usar, también puede crear una voz neuronal personalizada que sea reconocible y única para su marca o producto. Las voces neuronales personalizadas son privadas y pueden ofrecer una ventaja competitiva. Consulte los ejemplos de voz neuronal personalizada aquí.
Traducción de voz
La traducción de voz habilita la traducción de voz en varios idiomas en tiempo real en sus aplicaciones, herramientas y dispositivos. Use esta característica para la traducción de voz a voz y la conversión de voz en texto.
Identificación del idioma
La identificación del idioma se usa para identificar los idiomas que se hablan en el audio mediante la comparación con una lista de idiomas admitidos. Use la identificación del idioma por sí mismo, con el reconocimiento de voz en texto o con la traducción de voz.
Reconocimiento del hablante
El reconocimiento del hablante proporciona algoritmos que comprueban e identifican a los hablantes por sus características de voz únicas. El reconocimiento del hablante se usa para responder a la pregunta "¿quién está hablando?".
Evaluación de la pronunciación
La evaluación de la pronunciación evalúa la pronunciación de la voz y ofrece a los oradores comentarios sobre la precisión y la fluidez del audio hablado. Con la evaluación de la pronunciación, los estudiantes de idiomas pueden practicar, obtener comentarios instantáneos y mejorar su pronunciación para poder hablar y realizar presentaciones con confianza.
Reconocimiento de la intención
Reconocimiento de intenciones: use la conversión de voz en texto con reconocimiento del lenguaje conversacional para deducir las intenciones del usuario a partir de la voz transcrita y actuar en los comandos de voz.
Entrega y presencia
Puede implementar las características de Voz de los servicios de Azure AI en la nube o en el entorno local.
Con los contenedores, puede acercar el servicio a los datos por motivos de cumplimiento, seguridad u otras razones operativas.
La implementación del servicio de Voz en nubes soberanas está disponible para algunas entidades gubernamentales y sus asociados. Por ejemplo, la nube de Azure Government está disponible para las entidades de la Administración Pública de Estados Unidos y sus asociados. Microsoft Azure, operado por la nube 21Vianet, está disponible para organizaciones con presencia empresarial en China. Para más información, consulte Nubes soberanas.
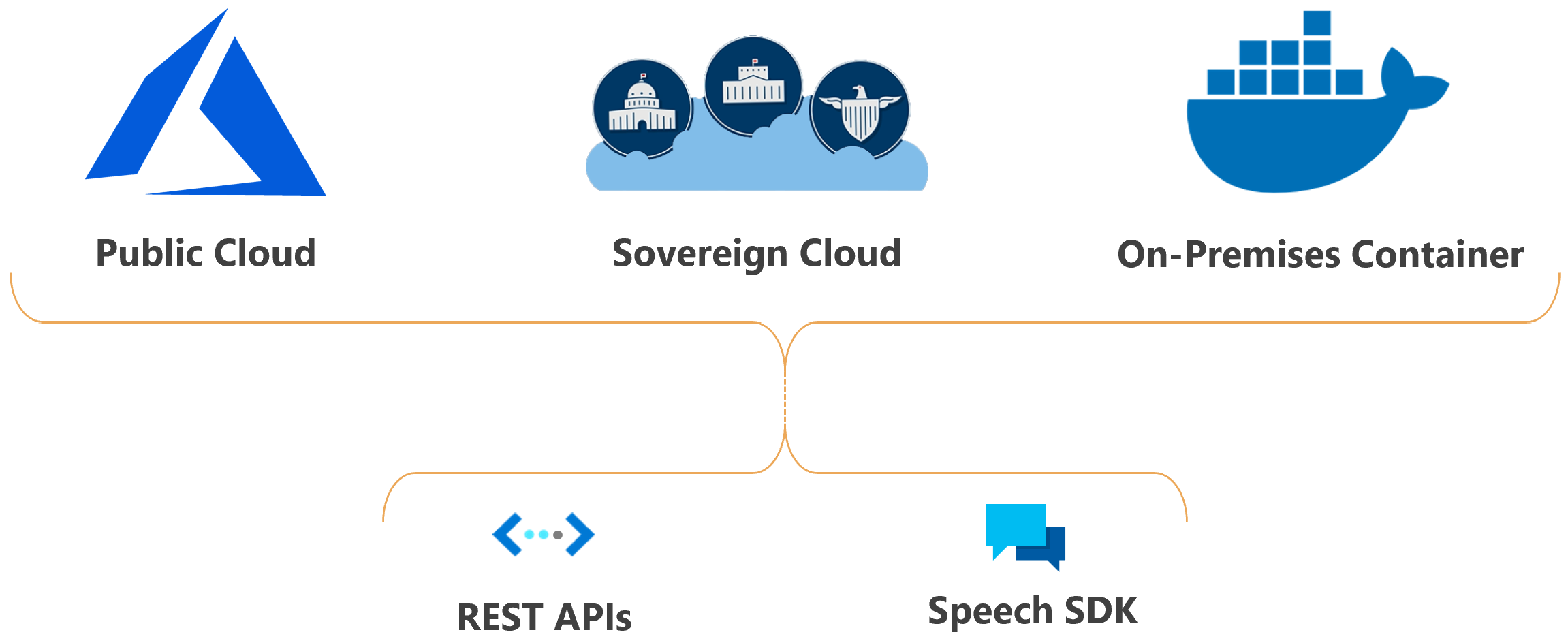
Uso del servicio de Voz en la aplicación
Speech Studio es un conjunto de herramientas basadas en interfaz de usuario para compilar e integrar características del servicio Voz de Azure en las aplicaciones. Debe crear proyectos en Speech Studio mediante un enfoque sin código y, a continuación, hacer referencia a esos recursos en las aplicaciones mediante el SDK de Voz, la CLI de Voz o las API de REST.
La CLI del servicio de Voz es una herramienta de la línea de comandos para usar el servicio de Voz sin necesidad de escribir código. La mayoría de las características principales del SDK de voz están disponibles en la CLI de voz, y algunas características y personalizaciones avanzadas se han simplificado en esta última.
El SDK de Voz expone muchas de las funcionalidades del servicio de Voz que se pueden usar para desarrollar aplicaciones habilitadas para voz. El SDK de voz está disponible en muchos lenguajes de programación y en todas las plataformas.
En algunos casos, no puede o no debe usar el SDK de Voz. En esos casos, puede usar las API REST para acceder al servicio de Voz. Por ejemplo, use las API REST para transcripción por lotes y las API REST de reconocimiento del hablante.
Primeros pasos
Ofrecemos inicios rápidos en los lenguajes de programación más conocidos. El diseño de cada inicio rápido le permite ejecutar el código en menos de 10 minutos. Consulte la siguiente lista para obtener la guía de inicio rápido de cada característica:
- Inicio rápido de voz a texto
- Inicio rápido para la conversión de texto a voz
- Inicio rápido sobre la traducción de voz
Ejemplos de código
Hay disponible código de ejemplo para el servicio de Voz en GitHub. En estos ejemplos se tratan escenarios comunes como la lectura de audio de un archivo o flujo, el reconocimiento continuo y de una sola emisión, y el trabajo con modelos personalizados. Use estos vínculos para ver ejemplos de SDK y REST:
- Ejemplos de conversión de voz a texto, texto a voz y traducción de voz (SDK)
- Ejemplos de transcripción de Azure Batch (REST)
- Ejemplos de conversión de texto a voz (REST)
- Ejemplos del asistente de voz (SDK)
IA responsable
Los sistemas de inteligencia artificial no solo incluyen la tecnología, sino también las personas que la usan, las que se ven afectadas por ella y el entorno en el que se implementan. Lea las notas sobre transparencia para obtener información sobre el uso responsable de la inteligencia artificial y la implementación en los sistemas.
Conversión de voz en texto
- Nota de transparencia y casos de uso
- Características y limitaciones
- Integración y uso responsable
- Datos, privacidad y seguridad
Valoración de la pronunciación
Voz neuronal personalizada
- Nota de transparencia y casos de uso
- Características y limitaciones
- Acceso limitado
- Implementación responsable de la voz sintética
- Divulgación de talento de voz
- Divulgación de directrices de diseño
- Divulgación de patrones de diseño
- Código de conducta
- Datos, privacidad y seguridad
Speaker Recognition
- Nota de transparencia y casos de uso
- Características y limitaciones
- Acceso limitado
- Instrucciones generales
- Datos, privacidad y seguridad