Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: ![]() MongoDB
MongoDB
Esta guía de migración forma parte de la serie sobre migración de bases de datos de MongoDB a la API de Azure CosmosDB para MongoDB. Los pasos críticos de la migración son la migración previa, la migración y la migración posterior, como se muestra a continuación.

Migración de datos con Azure Databricks
Azure Databricks es una oferta de plataforma como servicio (PaaS) para Apache Spark. Ofrece una manera de realizar migraciones sin conexión en un conjunto de datos a gran escala. Puede usar Azure Databricks para realizar una migración sin conexión desde MongoDB a Azure Cosmos DB for MongoDB.
En este tutorial, aprenderá a:
Aprovisionar un clúster de Azure Databricks
Adición de dependencias
Crear y ejecutar un cuaderno de Scala o Python
Optimizar el rendimiento de la migración
Solucionar problemas de errores de limitación de velocidad que se pueden observar durante la migración
Requisitos previos
Para completar este tutorial, necesita:
- Completar los pasos previos a la migración, como calcular el rendimiento y elegir una clave compartida.
- Crear una cuenta de Azure Cosmos DB for MongoDB.
Aprovisionar un clúster de Azure Databricks
Puede seguir las instrucciones para aprovisionar un clúster de Azure Databricks. Se recomienda seleccionar el entorno de ejecución de Databricks versión 7.6, que admite Spark 3.0.
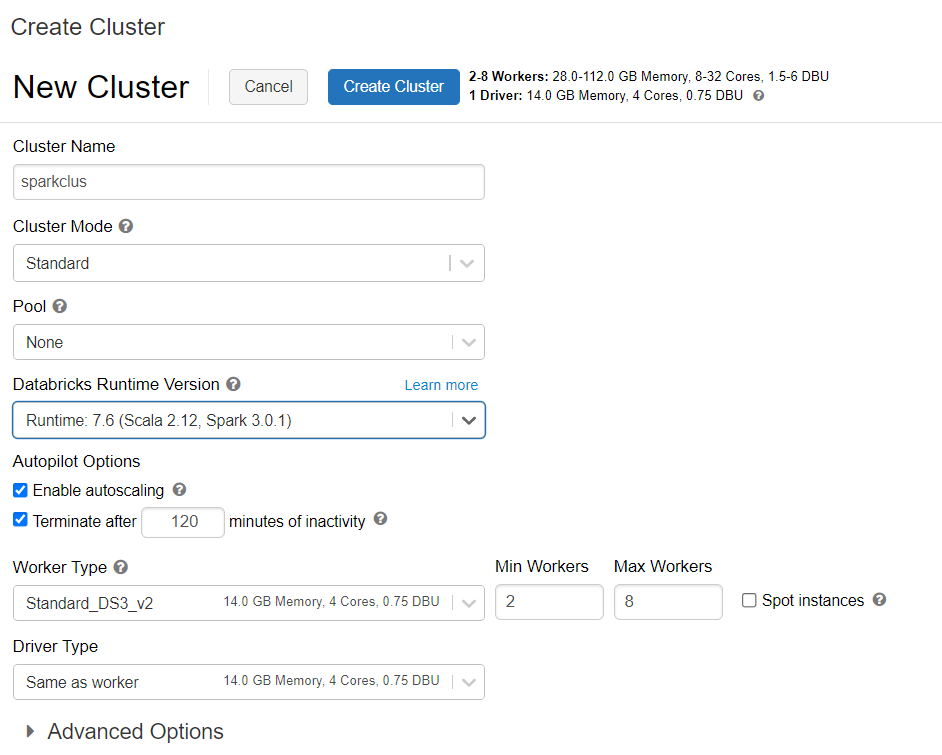
Adición de dependencias
Agregue la biblioteca MongoDB Connector for Spark al clúster para realizar la conexión a puntos de conexión nativos de MongoDB y Azure Cosmos DB for MongoDB. En el clúster, seleccione Libraries>Install New>Maven (Bibliotecas > Instalar nueva > Maven) y, después, agregue las coordenadas de Maven org.mongodb.spark:mongo-spark-connector_2.12:3.0.1.
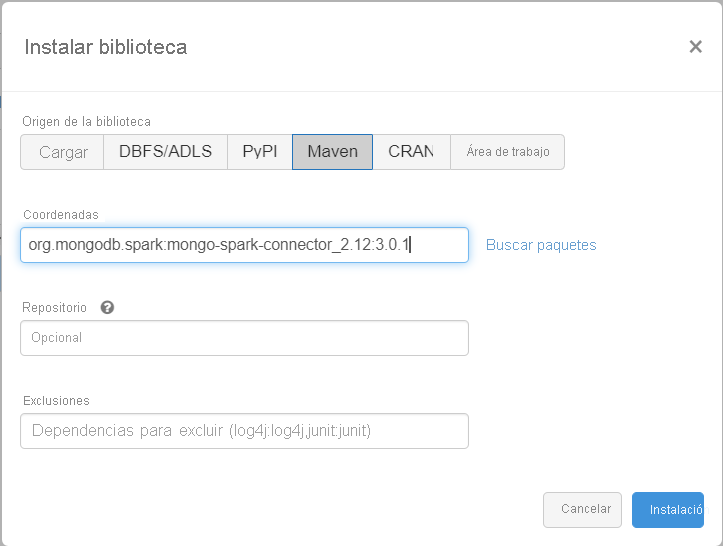
Seleccione Install (Instalar) y asegúrese de reiniciar el clúster cuando se complete la instalación.
Nota
Asegúrese de reiniciar el clúster de Databricks después de que se haya instalado la biblioteca MongoDB Connector for Spark.
Luego, puede crear un cuaderno de Scala o Python para la migración.
Creación de un cuaderno de Scala para la migración
Cree un cuaderno de Scala en Databricks. Asegúrese de escribir los valores correctos para las variables antes de ejecutar el código siguiente:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Creación de un cuaderno de Python para la migración
Cree un cuaderno de Python en Databricks. Asegúrese de escribir los valores correctos para las variables antes de ejecutar el código siguiente:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimizar el rendimiento de la migración
El rendimiento de la migración se puede ajustar mediante estas configuraciones:
Número de trabajos y núcleos en el clúster de Spark: más trabajos significan más particiones de proceso para ejecutar tareas.
maxBatchSize: el valor
maxBatchSizecontrola la velocidad a la que se guardan los datos en la colección de Azure Cosmos DB de destino. Pero si maxBatchSize es demasiado alto para el rendimiento de la colección, puede provocar errores de limitación de velocidad.Tendría que ajustar el número de trabajadores y maxBatchSize, en función del número de ejecutores en el clúster de Spark, posiblemente el tamaño (y por eso el costo de RU) de cada documento que se escribe y los límites de rendimiento de la colección de destino.
Sugerencia
maxBatchSize = Rendimiento de la colección / (coste de RU para 1 documento * número de trabajadores de Spark * número de núcleos de CPU por trabajo)
Partitioner y partitionKey de Spark de MongoDB: el particionador predeterminado que se usa es MongoDefaultPartitioner y el valor partitionKey predeterminado es _id. El particionador se puede cambiar si se asigna el valor
MongoSamplePartitionera la propiedad de configuración de entradaspark.mongodb.input.partitioner. De forma similar, partitionKey se puede cambiar si se asigna el nombre de campo adecuado a la propiedad de configuración de entradaspark.mongodb.input.partitioner.partitionKey. partitionKey puede ayudar a evitar la asimetría de datos (se escribe un gran número de registros para el mismo valor de clave de partición).Deshabilitar índices durante la transferencia de datos: para la migración de grandes cantidades de datos, considere la posibilidad de deshabilitar los índices, especialmente los que tienen caracteres comodín en la colección de destino. Los índices aumentan el costo de RU para escribir cada documento. La liberación de estas RU puede ayudar a mejorar la velocidad de transferencia de datos. Puede habilitar los índices una vez que se hayan migrado los datos.
Solucionar problemas
Error de tiempo de espera (código de error 50)
Es posible que vea un código de error 50 para las operaciones en la base de datos de Azure Cosmos DB for MongoDB. Los siguientes escenarios pueden provocar errores de tiempo de espera:
- El rendimiento asignado a la base de datos es bajo: asegúrese de que la colección de destino tiene asignado un rendimiento suficiente.
- Asimetría de datos excesiva con grandes volúmenes de datos. Si tiene una gran cantidad de datos para migrar a una tabla concreta, pero tiene una asimetría significativa en los datos, es posible que experimente una limitación de velocidad aunque tenga varias unidades de solicitud aprovisionadas en la tabla. Las unidades de solicitud se dividen equitativamente entre las particiones físicas y, una asimetría de datos intensiva puede provocar un cuello de botella de las solicitudes en una única partición. La asimetría de datos significa un gran número de registros para el mismo valor de clave de partición.
Limitación de velocidad (código de error 16500)
Es posible que vea un código de error 16500 para las operaciones en la base de datos de Azure Cosmos DB for MongoDB. Se trata de errores de limitación de velocidad y se pueden observar en cuentas antiguas o cuentas en las que la característica de reintento del lado servidor está deshabilitada.
- Habilitar reintento del lado servidor: habilite la característica Reintento del lado servidor (SSR) y permita que el servidor vuelva a intentar de forma automática las operaciones con limitación de frecuencia.
Optimización posterior a la migración
Después de migrar los datos, puede conectarse a Azure Cosmos DB y administrarlos. También puede seguir otros pasos posteriores a la migración, como optimizar la directiva de indexación, actualizar el nivel de coherencia predeterminado o configurar la distribución global de la cuenta de Azure Cosmos DB. Para más información, consulte el artículo Optimización posterior a la migración.
Recursos adicionales
- ¿Intenta planear la capacidad de una migración a Azure Cosmos DB?
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, lea sobre el cálculo de unidades de solicitud mediante núcleos o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.