Generación de anuncios mejorada con IA mediante el núcleo virtual de Azure Cosmos DB for MongoDB
En esta guía, mostramos cómo crear contenido publicitario dinámico que conecte con su público, usando nuestro asistente personalizado de IA, Heelie. Con el núcleo virtual de Azure Cosmos DB for MongoDB, aprovechamos la funcionalidad de búsqueda de similitud de vectores para analizar semánticamente y combinar descripciones de inventario con los temas de anuncios. El proceso es posible mediante la generación de vectores para descripciones de inventario mediante inserciones de OpenAI, lo que mejora significativamente su profundidad semántica. Estos vectores se almacenan e indexan en el recurso de núcleo virtual de Cosmos DB for MongoDB. Al generar contenido para anuncios, vectorizamos el tema del anuncio para encontrar los elementos del inventario más adecuados. Esto va seguido de un proceso de generación aumentada de recuperación (RAG), donde las coincidencias principales se envían a OpenAI para crear un anuncio atractivo. El código base completo de la aplicación está disponible en un repositorio de GitHub para su consulta.
Características
- Búsqueda de similitud de vectores: usa la potente búsqueda por similitud vectorial del núcleo virtual de Azure Cosmos DB for MongoDB para mejorar las capacidades de búsqueda semántica, lo que facilita la búsqueda de elementos de inventario relevantes basándose en el contenido de los anuncios.
- Inserciones de OpenAI: usa las inserciones de vanguardia de OpenAI para generar vectores para descripciones de inventario. Este enfoque permite coincidencias más matizadas y semánticamente enriquecidas entre el inventario y el contenido del anuncio.
- Generación de contenido: emplea modelos de lenguaje avanzados de OpenAI para generar anuncios atractivos centrados en tendencias. Este método garantiza que el contenido no solo sea relevante, sino también cautivador para el público objetivo.
Requisitos previos
Azure OpenAI: vamos a configurar el recurso de Azure OpenAI. El acceso a este servicio solo está disponible en la aplicación. Para solicitar acceso a Azure OpenAI, rellene el formulario de https://aka.ms/oai/access. Una vez que tenga acceso, complete los pasos siguientes:
- Cree un recurso de Azure OpenAI siguiendo este inicio rápido.
- Implemente un modelo
completionsyembeddings - Anote los nombres de su punto de conexión, clave e implementación.
Recurso de núcleo virtual de Cosmos DB for MongoDB: empecemos por crear un recurso de núcleo virtual de Azure Cosmos DB for MongoDB de forma gratuita siguiendo esta guía de inicio rápido.
- Anote los detalles de conexión (cadena de conexión).
Entorno de Python (>= versión 3.9) con paquetes como
numpy,openai,pymongo,python-dotenv,azure-core,azure-cosmos,tenacityygradio.Descargue el archivo de datos y guárdelo en una carpeta de datos designada.
Ejecutar el script
Antes de profundizar en la parte emocionante de la generación de anuncios mejorados con IA, es necesario configurar nuestro entorno. Esta configuración implica la instalación de los paquetes necesarios para garantizar que el script se ejecute sin problemas. Aquí tiene una guía paso a paso para prepararlo todo.
1.1 Instalar paquetes necesarios
En primer lugar, es necesario instalar algunos paquetes de Python. Abra el terminal y ejecute los siguientes comandos:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 Configurar el cliente de OpenAI y Azure
Después de instalar los paquetes necesarios, el siguiente paso consiste en configurar nuestros clientes OpenAI y Azure para el script, que es crucial para autenticar nuestras solicitudes a la API de OpenAI y los servicios de Azure.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Arquitectura de la solución
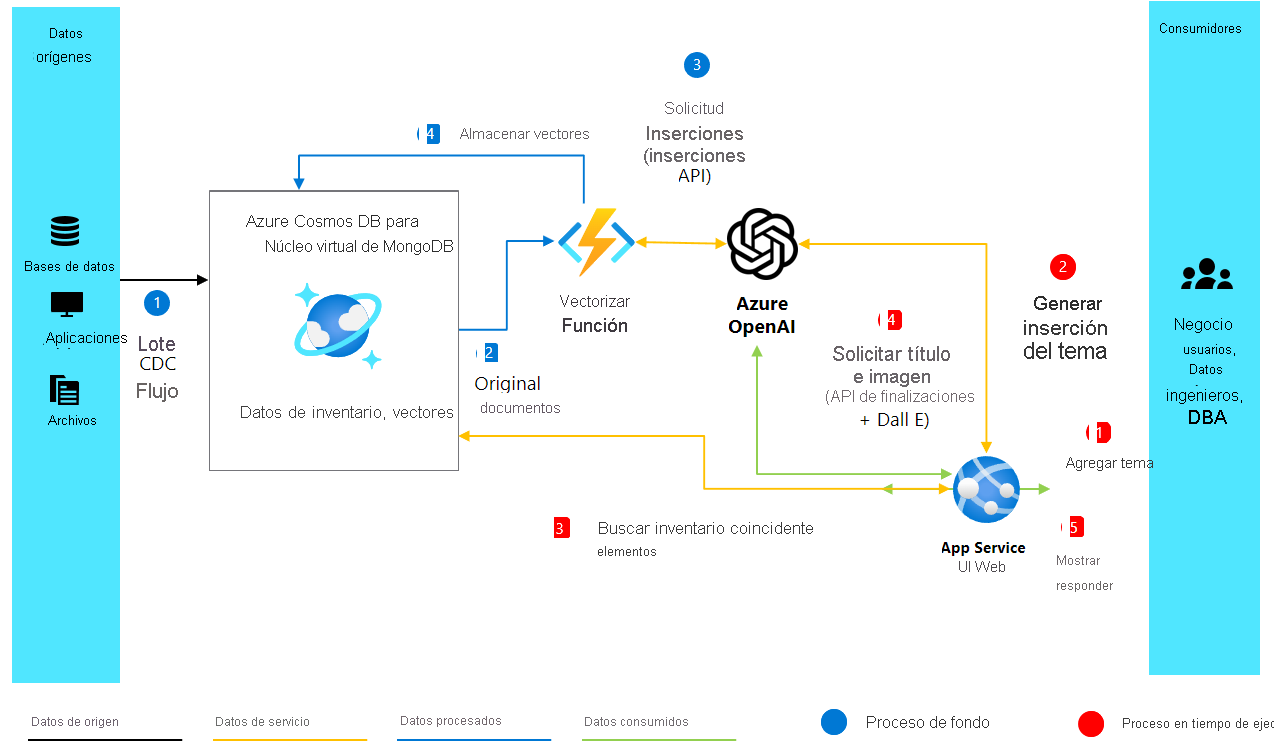
2. Crear inserciones y configurar Cosmos DB
Después de configurar nuestro entorno y el cliente de OpenAI, pasamos a la parte principal de nuestro proyecto de generación de anuncios mejorado con IA. El código siguiente crea inserciones vectoriales a partir de descripciones de texto de productos y configura nuestra base de datos en el núcleo virtual de Azure Cosmos DB for MongoDB para almacenar y buscar estas inserciones.
2.1 Crear inserciones
Para generar anuncios atractivos, primero necesitamos comprender los elementos de nuestro inventario. Para ello, creamos inserciones vectoriales a partir de descripciones de nuestros elementos, lo que nos permite capturar su significado semántico de forma que las máquinas puedan entenderlo y procesarlo. Aquí se explica cómo crear inserciones de vectores para una descripción de un elemento mediante Azure OpenAI:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
La función toma una entrada de texto, como la descripción de un producto, y usa el método client.embeddings.create de la API OpenAI para generar un vector insertado para ese texto. Aquí se usa el modelo text-embedding-ada-002, pero puede elegir otros modelos en función de sus requisitos. Si el proceso se realiza correctamente, imprime las inserciones generadas; en caso contrario, controla las excepciones imprimiendo un mensaje de error.
3. Conectar y configurar el núcleo virtual de Cosmos DB for MongoDB
Con nuestras inserciones listas, el siguiente paso es almacenarlas e indexarlas en una base de datos que admita la búsqueda de similitud vectorial. El núcleo virtual de Azure Cosmos DB for MongoDB es ideal para esta tarea, ya que está diseñado para almacenar datos transaccionales y realizar búsquedas de vectores en un solo lugar.
3.1 Configurar la conexión
Para conectarse a Cosmos DB, usamos la biblioteca pymongo, que nos permite interactuar fácilmente con MongoDB. El siguiente fragmento de código establece una conexión con nuestra instancia de núcleo virtual de Cosmos DB for MongoDB:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Reemplace <USERNAME>, <PASSWORD> y <VCORE_CLUSTER_NAME> por el nombre de usuario, la contraseña y el nombre de clúster de núcleo virtual de MongoDB, respectivamente.
4. Configurar la base de datos y el índice vectorial en Cosmos DB
Una vez establecida la conexión con Azure Cosmos DB, los siguientes pasos consisten en configurar la base de datos y la colección y, a continuación, crear un índice vectorial que permita realizar búsquedas eficientes de similitudes vectoriales. Vamos a seguir estos pasos.
4.1 Configurar la base de datos y la colección
En primer lugar, creamos una base de datos y una colección dentro de nuestra instancia de Cosmos DB. Este es el procedimiento:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 Crear el índice vectorial
Para realizar búsquedas eficaces de similitud vectorial dentro de nuestra colección, es necesario crear un índice vectorial. Cosmos DB admite diferentes tipos de índices vectoriales y aquí se describen dos: IVF y HNSW.
IVF
IVF (índice de archivos invertido) es el algoritmo de indexación vectorial predeterminado, que funciona en todos los niveles de clúster. Se trata de un enfoque de vecinos más próximos aproximados (ANN) que usa la agrupación para acelerar la búsqueda de vectores similares en un conjunto de datos. Para crear un índice de IVF, use el siguiente comando:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Importante
Solo puede crear un índice por propiedad vectorial. Es decir, no se puede crear más de un índice que apunte a la misma propiedad vectorial. Si desea cambiar el tipo de índice (por ejemplo, de IVF a HNSW), primero debe quitar el índice antes de crear uno nuevo.
HNSW
HNSW son las siglas de "Hierarchical Navigable Small Worlds", una estructura de datos basada en grafos que divide vectores en clústeres y subclústeres. Con HNSW puede hacer una búsqueda rápida de vecino más próximo a velocidades más altas con mayor precisión. HNSW es un método aproximado (ANN). Así es como se configura:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Nota:
La indexación de HNSW solo está disponible en los niveles de clúster M40 y versiones posteriores.
5. Insertar datos en la colección
Ahora inserte los datos del inventario, que incluyen descripciones y sus inserciones vectoriales correspondientes, en la colección recién creada. Para insertar datos en nuestra colección, usamos el método insert_many() proporcionado por la biblioteca pymongo. El método nos permite insertar varios documentos en la colección a la vez. Nuestros datos se almacenan en un archivo JSON, que cargaremos y luego insertaremos en la base de datos.
Descargue el archivo shoes_with_vectors.json del repositorio de GitHub y almacénelo en un directorio data dentro de la carpeta del proyecto.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Búsqueda de vectores en el núcleo virtual de Cosmos DB for MongoDB
Con nuestros datos cargados correctamente, ahora podemos aplicar la potencia de la búsqueda de vectores para encontrar los elementos más relevantes en función de una consulta. El índice vectorial que hemos creado anteriormente nos permite realizar búsquedas semánticas dentro de nuestro conjunto de datos.
6.1 Realizar una búsqueda de vectores
Para realizar una búsqueda de vectores, definimos una función vector_search que toma una consulta y el número de resultados que se van a devolver. La función genera un vector para la consulta mediante la función generate_embeddings que definimos anteriormente y, a continuación, usa la funcionalidad de $search de Cosmos DB para buscar los elementos coincidentes más cercanos en función de sus inserciones vectoriales.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Realizar consulta de búsqueda de vectores
Por último, ejecutamos nuestra función de búsqueda de vectores con una consulta específica y procesamos los resultados para mostrarlos:
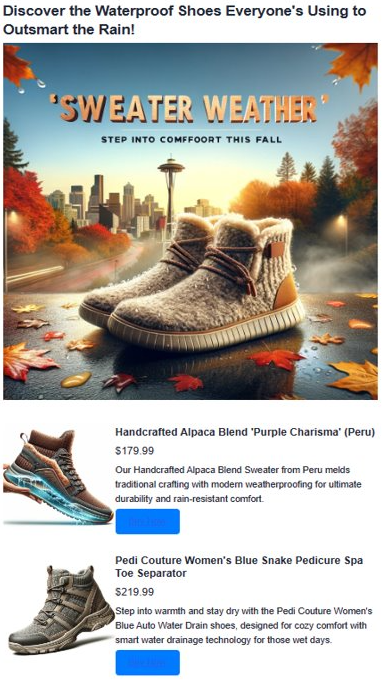
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
7. Generar contenido de anuncios con GPT-4 y DALL.E
Combinamos todos los componentes desarrollados para crear anuncios atractivos, empleando GPT-4 de OpenAI para el texto y DALL-E 3 para las imágenes. Junto con los resultados de la búsqueda de vectores, forman un anuncio completo. También presentamos a Heelie, nuestro asistente inteligente, encargado de crear eslóganes publicitarios atractivos. A través del próximo código, verá a Heelie en acción, mejorando nuestro proceso de creación de anuncios.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Resumen
Para que nuestra generación de anuncios sea interactiva, usamos Gradio, una biblioteca de Python para crear interfaces de usuario web sencillas. Definimos una interfaz de usuario que permite a los usuarios introducir temas publicitarios y, a continuación, genera y muestra dinámicamente el anuncio resultante.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
Output