Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: ![]() NoSQL
NoSQL
Importante
Las sugerencias de rendimiento de este artículo son solo para el SDK de Python de Azure Cosmos DB. Consulte las notas de la versión del SDK de Python de Azure Cosmos DB LéameNotas de la versión, Paquete (PyPI), Paquete (Conda)y guía de solución de problemas para obtener más información.
Azure Cosmos DB es una base de datos distribuida rápida y flexible que se escala sin problemas con una latencia y un rendimiento garantizados. No es necesario realizar cambios de arquitectura importantes ni escribir código complejo para escalar la base de datos con Azure Cosmos DB. Escalar y reducir verticalmente es tan sencillo como realizar una única llamada API o una llamada al método SDK. Sin embargo, dado que se accede a Azure Cosmos DB a través de llamadas de red, hay optimizaciones del lado cliente que puede realizar para lograr un rendimiento máximo al usar el SDK de Python de Azure Cosmos DB.
Por lo tanto, si se pregunta "¿Cómo puedo mejorar el rendimiento de mi base de datos?", considere las siguientes opciones:
Redes
- Colocación de los clientes en la misma región de Azure para aumentar el rendimiento
Cuando sea posible, coloque las aplicaciones que llaman a Azure Cosmos DB en la misma región que la base de datos de Azure Cosmos DB. Para obtener una comparación aproximada, las llamadas a Azure Cosmos DB en la misma región se realizan en menos de 1 o 2 ms, pero la latencia entre las costas este y oeste de Estados Unidos es >50 ms. Esta latencia podría variar de una solicitud a otra, según la ruta tomada por la solicitud cuando pasa del cliente al límite del centro de datos de Azure. Para conseguir la menor latencia posible, asegúrese de que la aplicación que llama se encuentra en la misma región de Azure que el punto de conexión de Azure Cosmos DB aprovisionado. Para obtener una lista de regiones disponibles, consulte Regiones de Azure.
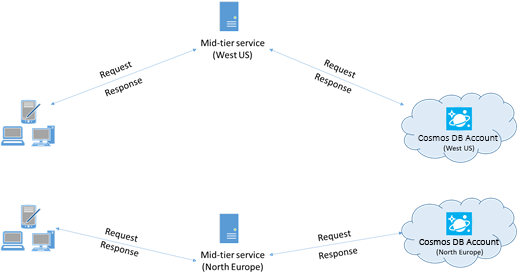
Una aplicación que interactúa con una cuenta de Azure Cosmos DB de varias regiones debe configurar ubicaciones preferidas para asegurarse de que las solicitudes vayan a una región colocalizada.
Habilitación de redes aceleradas para reducir la latencia y la vibración de la CPU
Se recomienda seguir las instrucciones para habilitar Redes Aceleradas en su VM Azure Windows (seleccione para obtener instrucciones) o Linux (seleccione para obtener instrucciones), con el fin de maximizar el rendimiento (reducir la latencia y la fluctuación de la CPU).
Sin las redes aceleradas, la E/S que pasa entre su máquina virtual de Azure y otros recursos de Azure puede enrutarse innecesariamente a través de un host y un conmutador virtual situado entre la máquina virtual y su tarjeta de red. Si el host y el conmutador virtual están alineados en la ruta de datos no solo se aumenta la latencia y la vibración en el canal de comunicación, sino que también se roban ciclos de la CPU de la máquina virtual. Con las redes aceleradas, la máquina virtual interactúa directamente con la NIC sin intermediarios; los detalles de la directiva de red que se administraban mediante el host y el conmutador virtual se administran ahora en hardware en la NIC; se omiten el host y el conmutador virtual. Por lo general, al habilitar las redes aceleradas puede esperar una menor latencia y un mayor rendimiento, así como una latencia más uniforme y una disminución del uso de la CPU.
Limitaciones: las redes aceleradas deben ser compatibles con el sistema operativo de la máquina virtual y solo se pueden habilitar cuando la máquina virtual se ha detenido y se ha desasignado. No se puede implementar la máquina virtual con Azure Resource Manager. App Service no tiene habilitada la red acelerada.
Consulte las instrucciones de Windows y Linux para obtener más detalles.
Alta disponibilidad
Para obtener instrucciones generales sobre cómo configurar la alta disponibilidad en Azure Cosmos DB, consulte Alta disponibilidad en Azure Cosmos DB.
Además de una buena configuración básica en la plataforma de base de datos, el disyuntor de nivel de partición se puede implementar en el SDK de Python, lo que puede ayudar en escenarios de interrupción. Esta característica proporciona desafíos de disponibilidad de mecanismos avanzados, pasando por encima y más allá de las funcionalidades de reintento entre regiones integradas en el SDK de forma predeterminada. Esto puede mejorar significativamente la resistencia y el rendimiento de la aplicación, especialmente en condiciones de alta carga o degradadas.
Disyuntor de nivel de partición
El disyuntor de nivel de partición (PPCB) en el SDK de Python mejora la disponibilidad y la resistencia al rastrear la salud de las particiones físicas individuales y redirigir las solicitudes lejos de las problemáticas. Esta característica es especialmente útil para controlar problemas transitorios y de terminal, como problemas de red, actualizaciones de particiones o migraciones.
EL PPCB es aplicable en los escenarios siguientes:
- Cualquier nivel de coherencia
- Operaciones con clave de partición (lecturas y escrituras puntuales)
- Cuentas de región de escritura única con varias regiones de lectura
- Varias cuentas de región de escritura
Cómo funciona
Las particiones pasan a través de cuatro estados: Saludable, No Saludable Tentativo, No Saludable, y Saludable Tentativo, en función del éxito o error de las solicitudes.
- Seguimiento de errores: El SDK supervisa las tasas de error (por ejemplo, 5xx, 408) por partición en un período de un minuto. El SDK realiza un seguimiento de los errores consecutivos por partición indefinidamente.
- Marcado como no disponible: Si una partición supera los umbrales configurados, se marca como Tentativa de estado no saludable y se excluye del enrutamiento durante 1 minuto.
- Promoción a Incorrecto o Recuperación: Si se produce un error en los intentos de recuperación, la partición pasa a Incorrecto. Después de un intervalo de retroceso, se realiza un sondeo Provisional correcto con una solicitud de tiempo limitado para determinar la recuperación.
- Restablecimiento: Si el sondeo provisional se realiza correctamente, la partición vuelve a Correcto. En caso contrario, permanece insalubre hasta el siguiente sondeo.
El SDK administra internamente esta conmutación por error y garantiza que las solicitudes eviten particiones problemáticas conocidas hasta que se confirme que están en buen estado de nuevo.
Configuración a través de variables de entorno
Puede controlar el comportamiento de PPCB mediante estas variables de entorno:
| Variable | Descripción | Predeterminado |
|---|---|---|
AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER |
Habilita o deshabilita PPCB | false |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_READ |
Número máximo de errores de lectura consecutivos hasta que una partición se marque como no disponible | 10 |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_WRITE |
Errores de escritura consecutivos máximos antes de marcar una partición como no disponible | 5 |
AZURE_COSMOS_FAILURE_PERCENTAGE_TOLERATED |
Umbral de porcentaje de error antes de marcar una partición no disponible | 90 |
Sugerencia
En futuras versiones se podrían ofrecer opcionales adicionales de configuración para ajustar con mayor precisión las duraciones de los tiempos de espera y el comportamiento de retroceso durante la recuperación.
Regiones excluidas
La característica regiones excluidas permite un control específico sobre el enrutamiento de solicitudes, ya que permite excluir regiones específicas de las ubicaciones preferidas por solicitud. Esta característica está disponible en la versión 4.14.0 del SDK de Python de Azure Cosmos DB y versiones posteriores.
Ventajas clave:
- Controlar la limitación de velocidad: al encontrar respuestas 429 (demasiadas solicitudes), enruta automáticamente las solicitudes a regiones alternativas con rendimiento disponible.
- Enrutamiento dirigido: asegúrese de que las solicitudes se atienden desde regiones específicas excluyendo a todos los demás.
- Omitir orden preferido: invalide la lista de regiones preferidas predeterminada para solicitudes individuales sin crear clientes independientes.
Configuración:
Las regiones excluidas se pueden configurar en el nivel de cliente y en el nivel de solicitud:
from azure.cosmos import CosmosClient
from azure.cosmos.partition_key import PartitionKey
# Configure preferred locations and excluded locations at client level
preferred_locations = ['West US 3', 'West US', 'East US 2']
excluded_locations_on_client = ['West US 3', 'West US']
client = CosmosClient(
url=HOST,
credential=MASTER_KEY,
preferred_locations=preferred_locations,
excluded_locations=excluded_locations_on_client
)
database = client.create_database('TestDB')
container = database.create_container(
id='TestContainer',
partition_key=PartitionKey(path="/pk")
)
# Create an item (writes ignore excluded_locations in single-region write accounts)
test_item = {
'id': 'Item_1',
'pk': 'PartitionKey_1',
'test_object': True,
'lastName': 'Smith'
}
created_item = container.create_item(test_item)
# Read operations will use preferred_locations minus excluded_locations
# In this example: ['West US 3', 'West US', 'East US 2'] - ['West US 3', 'West US'] = ['East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk']
)
Regiones excluidas de nivel de solicitud:
Las regiones excluidas de nivel de solicitud tienen prioridad más alta e invalidan la configuración de nivel de cliente:
# Excluded locations can be specified per request, overriding client settings
excluded_locations_on_request = ['West US 3']
# Create item with request-level excluded regions
created_item = container.create_item(
test_item,
excluded_locations=excluded_locations_on_request
)
# Read with request-level excluded regions
# This will use: ['West US 3', 'West US', 'East US 2'] - ['West US 3'] = ['West US', 'East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk'],
excluded_locations=excluded_locations_on_request
)
Ajuste de la coherencia frente a disponibilidad
La característica regiones excluidas proporciona un mecanismo adicional para equilibrar la coherencia y las ventajas de disponibilidad en la aplicación. Esta funcionalidad es especialmente valiosa en escenarios dinámicos en los que los requisitos pueden cambiar en función de las condiciones operativas:
Control de interrupciones dinámicas: cuando una región primaria experimenta una interrupción y los umbrales de disyuntor de nivel de partición resultan insuficientes, las regiones excluidas permiten la conmutación por error inmediata sin cambios de código ni reinicios de la aplicación. Esto proporciona una respuesta más rápida a los problemas regionales en comparación con la espera de activación automática del interruptor.
Preferencias de coherencia condicional: las aplicaciones pueden implementar diferentes estrategias de coherencia basadas en el estado operativo:
- Estado estable: priorice las lecturas coherentes excluyendo todas las regiones excepto la principal, lo que garantiza la coherencia de los datos con el costo potencial de disponibilidad.
- Escenarios de interrupción: favorece la disponibilidad sobre la coherencia estricta al permitir el enrutamiento entre regiones, aceptando posibles retrasos en los datos a cambio de la disponibilidad continua del servicio.
Este enfoque permite que los mecanismos externos (como administradores de tráfico o equilibradores de carga) organicen las decisiones de conmutación por error mientras la aplicación mantiene el control sobre los requisitos de coherencia a través de patrones de exclusión de regiones.
Cuando se excluyen todas las regiones, las solicitudes se enrutarán a la región principal o central. Esta característica funciona con todos los tipos de solicitud, incluidas las consultas, y es especialmente útil para mantener las instancias de cliente singleton al lograr un comportamiento de enrutamiento flexible.
Uso del SDK
- Instalación del SDK más reciente
Los SDK de Azure Cosmos DB se mejoran constantemente para proporcionar el mejor rendimiento. Consulte las notas de la versión del SDK de Azure Cosmos DB para determinar las mejoras más recientes del SDK y la revisión.
- Uso de un cliente de Azure Cosmos DB singleton para aumentar la duración de la aplicación
Cada instancia de Azure Cosmos DB está protegida frente a amenazas y realiza de manera eficiente la administración de las conexiones y el almacenamiento en caché de las direcciones. Para permitir una administración de conexiones eficaz y un mejor rendimiento por parte del cliente de Azure Cosmos DB, se recomienda usar una única instancia del cliente de Azure Cosmos DB durante la vigencia de la aplicación.
- Ajuste del tiempo de espera y las configuraciones de reintento
Las configuraciones de tiempo de espera y las directivas de reintento se pueden personalizar en función de las necesidades de la aplicación. Consulte tiempo de espera y vuelva a intentar la configuración documento para obtener una lista completa de las configuraciones que se pueden personalizar.
- Uso del nivel de coherencia más bajo necesario para la aplicación
Cuando se crea un CosmosClient, se usa la coherencia del nivel de cuenta si no se especifica ninguna en la creación del cliente. Para obtener más información sobre los niveles de coherencia, consulte el documento niveles de coherencia.
- Escalado horizontal de la carga de trabajo de cliente
Si va a realizar pruebas en niveles de alto rendimiento, la aplicación cliente puede crear cuellos de botella, debido a que la máquina limita el uso de CPU o de la red. Si llega a este punto, puede seguir insertando la cuenta de Azure Cosmos DB mediante la escala horizontal de las aplicaciones cliente en varios servidores.
Una buena regla general es no superar un uso de la CPU >50 % en cualquier servidor para mantener baja la latencia.
- Límite de recursos de archivos abiertos del sistema operativo
Algunos sistemas Linux (como Red Hat) tienen un límite superior sobre el número de archivos abiertos y, por tanto, sobre el número total de conexiones. Ejecute el siguiente código para ver los límites actuales:
ulimit -a
El número de archivos abiertos (nofile) debe ofrecer el espacio suficiente para el tamaño configurado del grupo de conexiones y otros archivos abiertos por el sistema operativo. Se puede modificar para permitir un tamaño mayor del grupo de conexiones.
Abra el archivo limits.conf:
vim /etc/security/limits.conf
Agregue o modifique las siguientes líneas:
* - nofile 100000
Operaciones de consulta
Para las operaciones de consulta, consulte las sugerencias de rendimiento para las consultas.
Directiva de indexación
- Exclusión de rutas de acceso sin utilizar de la indexación para acelerar las escrituras
La directiva de indexación de Azure Cosmos DB le permite especificar las rutas de acceso de documentos que se incluirán en la indexación o se excluirán de esta mediante el aprovechamiento de las rutas de acceso de indexación (setIncludedPaths y setExcludedPaths). El uso de rutas de acceso de indexación puede ofrecer un rendimiento de escritura mejorado y un almacenamiento de índices reducido en escenarios en los que los patrones de consulta se conocen de antemano, dado que los costos de indexación están directamente correlacionados con el número de rutas de acceso únicas indexadas. Por ejemplo, en el código siguiente se muestra cómo incluir y excluir secciones completas de los documentos (que también se conocen como subárbol) de la indexación mediante el comodín "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Para más información, consulte Directivas de indexación de Azure Cosmos DB.
Capacidad de procesamiento
- Medición y optimización del uso menor de unidades de solicitud por segundo
Azure Cosmos DB ofrece un amplio conjunto de operaciones de base de datos, incluidas consultas relacionales y jerárquicas con funciones definidas por el usuario, procedimientos almacenados y desencadenadores. Todo funciona con los documentos dentro de una colección de base de datos. El costo asociado a cada una de estas operaciones variará en función de la CPU, la E/S y la memoria necesarias para completar la operación. En lugar de administrar y pensar sobre los recursos de hardware, puede pensar en una unidad de solicitud (RU) como una medida única para los recursos necesarios para realizar varias operaciones de la base de datos y dar servicio a una solicitud de la aplicación.
El rendimiento se aprovisiona en función del número de unidades de solicitud establecido para cada contenedor. El consumo de la unidad de solicitud se evalúa como frecuencia por segundo. Las aplicaciones que superan la frecuencia de unidad de solicitud aprovisionada para su contenedor están limitadas hasta que la frecuencia cae por debajo del nivel aprovisionado del contenedor. Si la aplicación requiere un mayor nivel de rendimiento, puede aumentar el rendimiento mediante el aprovisionamiento de unidades de solicitud adicionales.
La complejidad de una consulta afecta a la cantidad de unidades de solicitud consumidas para una operación. El número de predicados, la naturaleza de los predicados, el número de UDF y el tamaño del conjunto de datos de origen influyen en el costo de operaciones de consulta.
Para medir la sobrecarga de cualquier operación (crear, actualizar o eliminar), inspeccione el encabezado x-ms-request-charge para medir el número de unidades de solicitud usadas por estas operaciones.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
El cargo de solicitud devuelto en este encabezado es una fracción de la capacidad de proceso aprovisionada. Por ejemplo, si tiene 2000 RU/segundo aprovisionadas, y si la consulta anterior devuelve 1000 documentos de 1 KB, el costo de la operación será 1000. Por lo tanto, al cabo de un segundo, el servidor atenderá solo dos de estas solicitudes antes de limitar la velocidad de las solicitudes posteriores. Para más información, consulte Unidades de solicitud y la calculadora de unidades de solicitud.
- Administración de la limitación de velocidad y la tasa de solicitudes demasiado grande
Cuando un cliente intenta superar la capacidad de proceso reservada para una cuenta, no habrá ninguna degradación del rendimiento en el servidor y no se utilizará ninguna capacidad de proceso más allá del nivel reservado. El servidor finalizará de forma preventiva la solicitud con RequestRateTooLarge (código de estado HTTP 429) y devolverá el encabezado x-ms-retry-after-ms para indicar la cantidad de tiempo, en milisegundos, que el usuario debe esperar antes de volver a intentar realizar la solicitud.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Los SDK capturan implícitamente esta respuesta, respetan el encabezado retry-after especificado por el servidor y reintentan la solicitud. A menos que varios clientes obtengan acceso a la cuenta al mismo tiempo, el siguiente reintento se realizará correctamente.
Si tiene más de un cliente que funciona de forma acumulativa de forma coherente por encima de la tasa de solicitudes, es posible que el número de reintentos predeterminado establecido actualmente en 9 internamente por el cliente no sea suficiente; en este caso, el cliente inicia una CosmosHttpResponseError con el código de estado 429 a la aplicación. El recuento de reintentos predeterminado se puede cambiar pasando retry_total configuración al cliente. De forma predeterminada, el cosmosHttpResponseError con el código de estado 429 se devuelve después de un tiempo de espera acumulado de 30 segundos si la solicitud sigue funcionando por encima de la tasa de solicitudes. Esto sucede incluso cuando el número de reintentos actual es inferior al número de reintentos máximo de 9, el valor predeterminado, o un valor definido por el usuario.
Aunque el comportamiento de reintento automático ayuda a mejorar la resistencia y la usabilidad en la mayoría de las aplicaciones, podría no resultar ventajoso al realizar comparativas de rendimiento, en especial al medir la latencia. La latencia observada del cliente aumentará si el experimento llega a la limitación del servidor y hace que el SDK del cliente realice reintentos de forma silenciosa. Para evitar aumentos de latencia durante los experimentos de rendimiento, mida el gasto devuelto por cada operación y asegúrese de que las solicitudes funcionan por debajo de la tasa de solicitudes observada. Para más información, consulte Unidades de solicitud.
- Diseño de documentos más pequeños para un mayor rendimiento
El gasto de solicitud (es decir, el costo de procesamiento de solicitudes) de una operación dada está directamente correlacionado con el tamaño del documento. Las operaciones con documentos grandes cuestan más que las operaciones con documentos pequeños. Idealmente, diseñe la aplicación y los flujos de trabajo para que el tamaño del elemento sea ~1 KB, o un orden o una magnitud similares. En el caso de las aplicaciones dependientes de la latencia, deben evitarse los elementos de gran tamaño; los documentos de varios MB ralentizarán la aplicación.
Pasos siguientes
Para más información sobre cómo diseñar la aplicación para escalarla y obtener un alto rendimiento, consulte Partición y escalado en Azure Cosmos DB.
¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Puede usar la información sobre el clúster de bases de datos existente para el planeamiento de capacidad.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, consulte la información sobre el cálculo de unidades de solicitud mediante núcleos virtuales o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.