Introducción a la continuidad empresarial y recuperación ante desastres
La continuidad empresarial y recuperación ante desastres en Azure Data Explorer permite que la empresa continúe en funcionamiento en caso de que se produzca una interrupción. En este artículo se describe la disponibilidad (dentro de la región) y la recuperación ante desastres. Se detallan las funcionalidades nativas y las consideraciones de arquitectura para una implementación resistente de Azure Data Explorer. Se detallan las recuperaciones frente a errores humanos, la alta disponibilidad y varias configuraciones de recuperación ante desastres. Estas configuraciones dependen de requisitos de resistencia como el objetivo de punto de recuperación (RPO) o el objetivo de tiempo de recuperación (RTO), el esfuerzo necesario y el costo.
Mitigación de eventos que causan interrupciones
- Error humano
- Alta disponibilidad de Azure Data Explorer
- Interrupción de una zona de disponibilidad de Azure
- Interrupción de un centro de datos de Azure
- Interrupción de una región de Azure
Error humano
Los errores humanos son inevitables. Los usuarios pueden eliminar accidentalmente un clúster, una base de datos o una tabla.
Eliminación accidental de clústeres o de bases de datos
La eliminación accidental de clústeres o de bases de datos es una acción irrecuperable. Como propietario del recurso de Azure Data Explorer, puede evitar la pérdida de datos; para ello, habilite la funcionalidad de bloqueo de eliminación, disponible en el nivel de recurso de Azure.
Eliminación accidental de tablas
Los usuarios con permisos de administrador de tabla o superiores pueden eliminar tablas. Si uno de esos usuarios elimina accidentalmente una tabla, puede recuperarla mediante el comando .undo drop table. Para que este comando se ejecute correctamente, primero debe habilitar la propiedad recoverability (capacidad de recuperación) en la directiva de retención.
Eliminación accidental de tablas externas
Las tablas externas son entidades del esquema de la consulta de Kusto que hacen referencia a datos almacenados fuera de la base de datos. La eliminación de una tabla externa solo elimina los metadatos de la tabla. Para recuperarlos, vuelva a ejecutar el comando de creación de la tabla. Use la funcionalidad de eliminación temporal para proteger contra la eliminación accidental o la sobrescritura de un archivo o blob durante un tiempo configurado por el usuario.
Alta disponibilidad de Azure Data Explorer
La alta disponibilidad se refiere a la tolerancia a errores de Azure Data Explorer, sus componentes y las dependencias subyacentes en una región de Azure. Esta tolerancia a errores evita los únicos puntos de error (SPOF) en la implementación. En Azure Data Explorer, la alta disponibilidad incluye la capa de persistencia, la capa de proceso y una configuración líder-seguidor.
Capa de persistencia
Azure Data Explorer utiliza Azure Storage como su capa de persistencia duradera. Azure Storage proporciona automáticamente tolerancia a errores, con la opción predeterminada de almacenamiento con redundancia local (LRS) dentro de un centro de datos. Se conservan tres réplicas. Si se pierde una réplica mientras está en uso, se implementa otra sin interrupción. Es posible una mayor resistencia con el almacenamiento con redundancia de zona (ZRS), que coloca las réplicas de forma inteligente entre las zonas de disponibilidad regional de Azure para lograr una tolerancia a errores máxima con un costo adicional. El almacenamiento habilitado para ZRS se configura automáticamente cuando el clúster de Azure Data Explorer se implementa en Availability Zones.
Capa de proceso
Azure Data Explorer es una plataforma de computación distribuida y puede tener de dos a muchos nodos según la escala y el tipo de rol del nodo. En el momento del aprovisionamiento, seleccione las zonas de disponibilidad para distribuir la implementación del nodo, entre zonas para lograr la máxima resistencia dentro de la región. Un error en la zona de disponibilidad no producirá una interrupción completa, sino una degradación del rendimiento hasta la recuperación de la zona.
Configuración de clúster líder-seguidor
Azure Data Explorer proporciona una funcionalidad de seguidor opcional para que un clúster líder sea seguido por otros clústeres seguidores para el acceso de solo lectura a los datos y metadatos del líder. Los cambios en el líder, como create, append y drop, se sincronizan automáticamente con el seguidor. Aunque los clústeres líderes pueden extenderse en varias regiones de Azure, los clústeres seguidores se deben hospedar en las mismas regiones que el líder. Si el clúster líder está inactivo o se eliminan accidentalmente las bases de datos o las tablas, los clústeres seguidores perderán el acceso hasta que se recupere el acceso en el líder.
Interrupción de una zona de disponibilidad de Azure
Las zonas de disponibilidad de Azure son ubicaciones físicas únicas dentro de la misma región de Azure. Pueden proteger el proceso y los datos de un clúster de Azure Data Explorer de un error parcial en la región. Un error en la zona es un escenario de disponibilidad, ya que se produce dentro de la región.
Puede anclar un clúster de Azure Data Explorer a la misma zona que los otros recursos de Azure conectados. Para más información sobre cómo habilitar las zonas de disponibilidad, consulte Creación de un clúster.
Nota:
La implementación en zonas de disponibilidad es posible al crear un clúster o se puede migrar más adelante.
Interrupción de un centro de datos de Azure
Las zonas de disponibilidad de Azure tienen un costo y algunos clientes deciden implementar sin redundancia de zona. Con una implementación de este tipo de Azure Data Explorer, una interrupción del centro de datos de Azure producirá una interrupción del clúster. La administración de una interrupción del centro de datos de Azure es, por lo tanto, idéntica a la de una interrupción de la región de Azure.
Interrupción de una región de Azure
Azure Data Explorer no proporciona protección automática frente a la interrupción de toda una región de Azure. Para minimizar el impacto para la empresa si se produce una interrupción, implemente varios clústeres de Azure Data Explorer en regiones emparejadas de Azure. En función del objetivo de tiempo de recuperación (RTO), el objetivo de punto de recuperación (RPO), así como las consideraciones de esfuerzo y costo, existen varias configuraciones de recuperación ante desastres. Es posible realizar optimizaciones de costos y rendimiento con las recomendaciones de Azure Advisor y la configuración de la escalabilidad automática.
Configuraciones de recuperación ante desastres
En esta sección se detallan varias configuraciones de recuperación ante desastres en función de los requisitos de resistencia (RPO y RTO), el esfuerzo necesario y el costo.
El objetivo de tiempo de recuperación (RTO) hace referencia al tiempo que se tarda en recuperarse de una interrupción. Por ejemplo, un RTO de 2 horas significa que la aplicación tiene que estar activa y en funcionamiento en un plazo de dos horas tras una interrupción. El objetivo de punto de recuperación (RPO) hace referencia al intervalo de tiempo que puede transcurrir durante una interrupción antes de que la cantidad de datos perdidos durante ese período sea mayor que el umbral permitido. Por ejemplo, si el RPO es de 24 horas y una aplicación tiene datos que comienzan hace 15 años, todavía están dentro de los parámetros del RPO acordado.
Los procesos de ingesta, procesamiento y protección necesitan un diseño diligente por adelantado al planear la recuperación ante desastres. La ingesta hace referencia a los datos integrados en Azure Data Explorer desde diversos orígenes; el procesamiento hace referencia a las transformaciones y actividades similares; la protección hace referencia a las vistas materializadas, a las exportaciones al lago de datos, etc.
A continuación se muestran las configuraciones de recuperación ante desastres más populares y se describe cada una con detalle.
- Configuración activo-activo-activo (siempre activado)
- Configuración activo-activo
- Configuración activo-espera activa
- Configuración de clúster con recuperación de datos a petición
Configuración activo-activo-activo
Esta configuración también se llama "siempre activado". En el caso de las implementaciones de aplicaciones críticas sin tolerancia a interrupciones, debe usar varios clústeres de Azure Data Explorer en regiones emparejadas de Azure. Configure la ingesta, el procesamiento y la protección en paralelo en todos los clústeres. La SKU del clúster debe ser la misma en todas las regiones. Azure se asegurará de que las actualizaciones se implementan y se escalonan en las regiones emparejadas de Azure. Una interrupción de la región de Azure no provocará una interrupción de la aplicación. Puede experimentar una degradación del rendimiento o de la latencia.
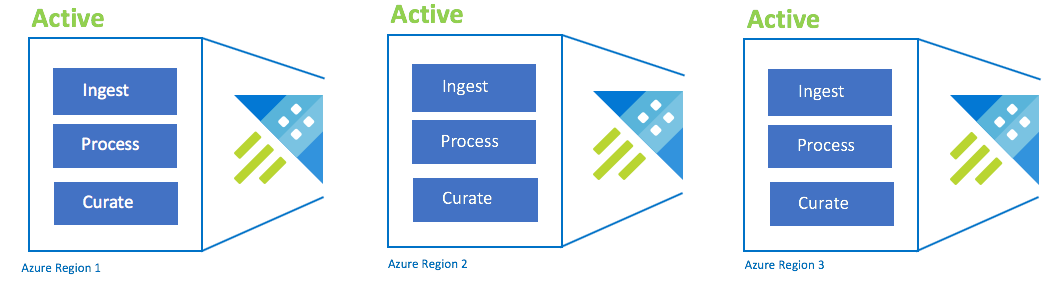
| Configuración | RPO | RTO | Esfuerzo | Costee |
|---|---|---|---|---|
| Activo-activo-activo-n | 0 horas | 0 horas | Inferior | Highest (el más alto) |
Configuración activo-activo
Esta configuración es idéntica a la configuración activo-activo-activo, pero solo implica dos regiones emparejadas de Azure. Configure la ingesta, el procesamiento y la protección duales. Los usuarios se enrutan a la región más cercana. La SKU del clúster debe ser la misma en todas las regiones.
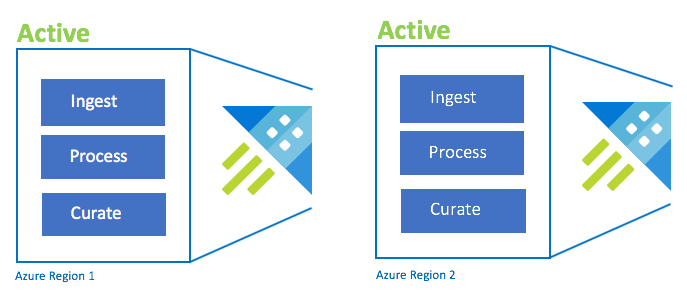
| Configuración | RPO | RTO | Esfuerzo | Costee |
|---|---|---|---|---|
| Activo-activo | 0 horas | 0 horas | Inferior | Alto |
Configuración activo-espera activa
La configuración activo-espera activa es similar a la configuración activo-activo en la ingesta, el procesamiento y la protección duales. Aunque el clúster en espera está en línea para la ingesta, el proceso y la curación, no está disponible para realizar consultas. El clúster en espera no necesita estar en la misma SKU que el clúster principal. Puede ser de una SKU y una escala más pequeñas, lo que puede dar lugar a que sea menos eficaz. En un escenario de desastre, los usuarios se redirigen al clúster en espera, que, opcionalmente, se puede escalar verticalmente para aumentar el rendimiento.
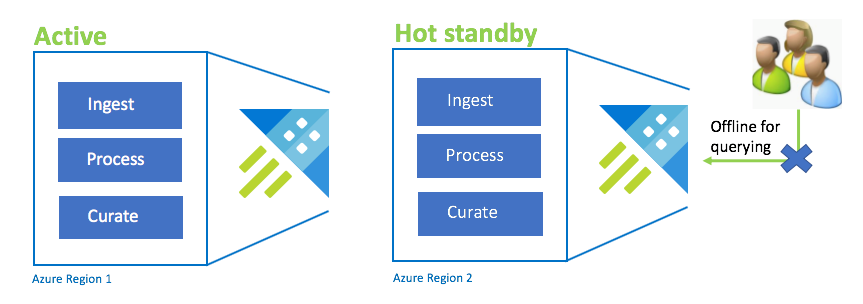
| Configuración | RPO | RTO | Esfuerzo | Costee |
|---|---|---|---|---|
| Activo-espera activa | 0 horas | Bajo | Media | Media |
Configuración de recuperación de datos a petición
Esta solución ofrece la menor resistencia (RPO y RTO más altos), con el costo más bajo y el esfuerzo más alto. En esta configuración, no hay ningún clúster de recuperación de datos. Configure la exportación continua de los datos protegidos (a menos que también se requieran datos sin procesar e intermedios) a una cuenta de almacenamiento configurada con GRS (almacenamiento con redundancia geográfica). Se pondrá en marcha un clúster de recuperación de datos si se produce un escenario de recuperación ante desastres. En ese momento, se aplican los DDL, la configuración, las directivas y los procesos. Los datos se ingieren desde el almacenamiento con la propiedad de ingesta kustoCreationTime para invalidar el tiempo de ingesta, que tiene como valor predeterminado la hora del sistema.
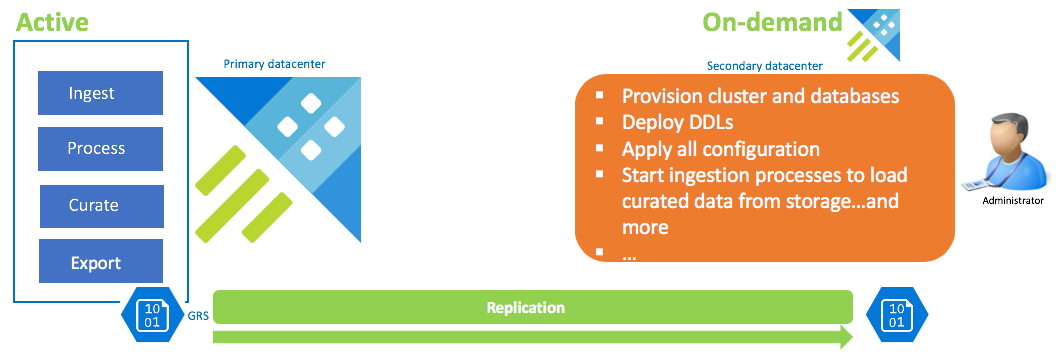
| Configuración | RPO | RTO | Esfuerzo | Costee |
|---|---|---|---|---|
| Clúster con recuperación de datos a petición | Highest (el más alto) | Highest (el más alto) | Highest (el más alto) | Mínima |
Resumen de las opciones de configuración de la recuperación ante desastres
| Configuración | Resistencia | RPO | RTO | Esfuerzo | Costee |
|---|---|---|---|---|---|
| Activo-activo-activo-n | Highest (el más alto) | 0 horas | 0 horas | Inferior | Highest (el más alto) |
| Activo-activo | Alto | 0 horas | 0 horas | Inferior | Alto |
| Activo-espera activa | Media | 0 horas | Bajo | Media | Media |
| Clúster con recuperación de datos a petición | Mínima | Highest (el más alto) | Highest (el más alto) | Highest (el más alto) | Mínima |
Procedimientos recomendados
Independientemente de la configuración de recuperación ante desastres elegida, siga estos procedimientos recomendados:
- Todos los objetos, las directivas y las configuraciones de la base de datos se deben conservar en el control de código fuente para que se puedan publicar en el clúster desde la herramienta de automatización de versiones. Para más información, consulte Compatibilidad de Azure DevOps con Azure Data Explorer.
- Diseñe, desarrolle e implemente rutinas de validación para asegurarse de que todos los clústeres estén sincronizados desde la perspectiva de los datos. Azure Data Explorer admite combinaciones de consultas entre clústeres. Un simple recuento de las filas en las tablas puede ayudar a validar.
- Los procedimientos de versión deben incluir comprobaciones y saldos de gobernanza que garanticen la creación de reflejo de los clústeres.
- Conozca todo lo que se necesita para crear un clúster desde cero.
- Cree una lista de comprobación de las unidades de implementación. La lista será exclusiva según sus necesidades, pero debe incluir: scripts de implementación, conexiones de ingesta, herramientas de BI y otras configuraciones importantes.