Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se detalla cómo puede prepararse para una interrupción regional de Azure mediante la replicación de los recursos de Azure Data Explorer, la administración y la ingesta en otras regiones de Azure. Se proporciona un ejemplo de ingesta de datos con Azure Event Hubs. También se describe la optimización de costos para las distintas configuraciones de la arquitectura. Para obtener una visión más detallada de las consideraciones de arquitectura y las soluciones de recuperación, consulte Introducción a la continuidad empresarial y recuperación ante desastres.
Preparación de la protección de los datos ante una interrupción regional de Azure
Azure Data Explorer no proporciona protección automática frente a la interrupción de toda una región de Azure. Este tipo de interrupción se puede producir durante un desastre natural, como un terremoto. Si necesita una solución para una situación de recuperación ante desastres, realice los pasos siguientes para garantizar la continuidad empresarial. En estos pasos, replicará los clústeres, la administración y la ingesta de datos en dos regiones de Azure emparejadas.
- Cree dos o más clústeres independientes en dos regiones emparejadas de Azure.
- Replique todas las actividades de administración en cada clúster, como la creación de nuevas tablas o la administración de roles de usuario.
- Realice la ingesta de datos en paralelo en cada clúster.
Creación de varios clústeres independientes
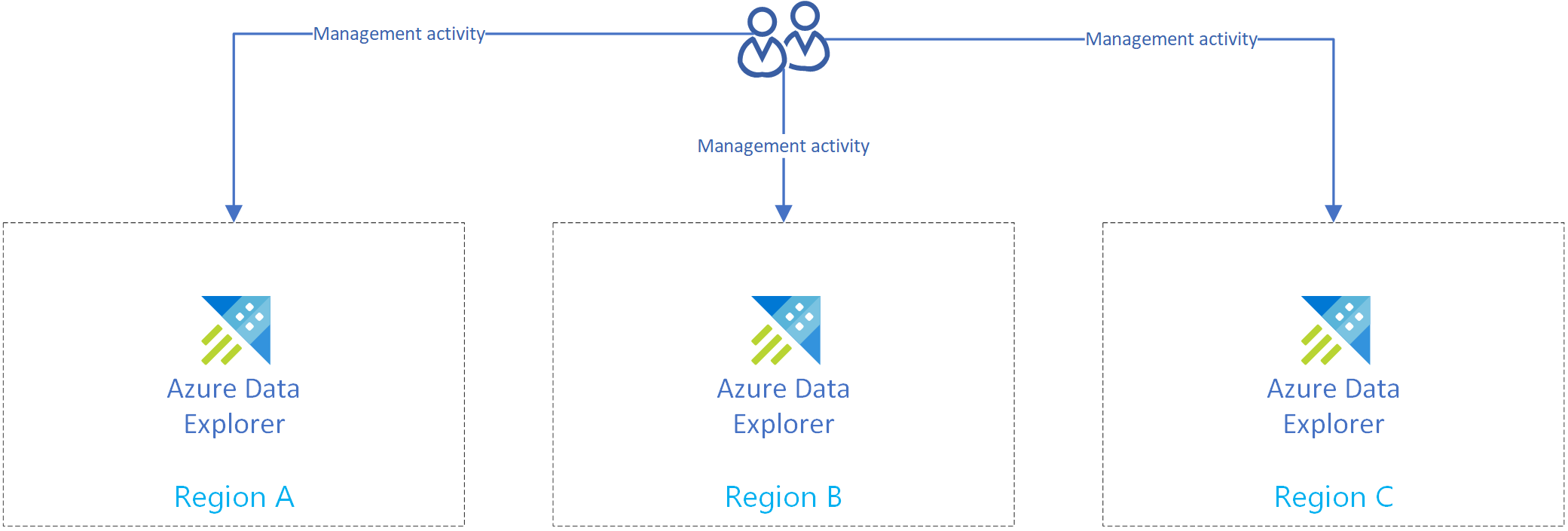
Cree más de un clúster de Azure Data Explorer en más de una región. Asegúrese de que al menos dos de estos clústeres se creen en regiones de Azure emparejadas.
En la imagen siguiente se muestran las réplicas, tres clústeres en tres regiones diferentes.

Replicación de las actividades de administración
Replique las actividades de administración para tener la misma configuración de clúster en todas las réplicas.
Cree los mismos elementos en cada réplica:
- Bases de datos: puede usar Azure Portal o uno de los SDK para crear una base de datos.
- Tablas
- Asignaciones
- Directivas
Administre la autenticación y autorización en cada réplica.
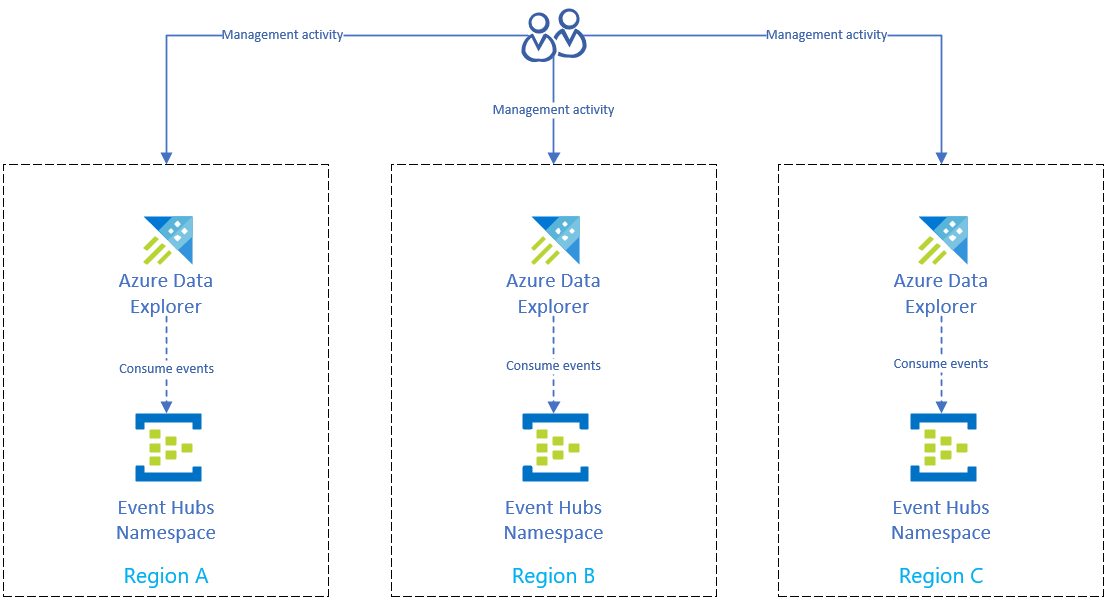
Solución de recuperación ante desastres mediante la ingesta de Event Hubs
Una vez que haya completado los pasos que se describen en Preparación de la protección de los datos ante una interrupción regional de Azure, los datos y la administración se distribuyen entre varias regiones. Si se produce una interrupción en una región, Azure Data Explorer podrá usar las otras réplicas.
Configuración de la ingesta mediante un centro de eventos
Para ingerir datos de Azure Event Hubs en el clúster de Azure Data Explorer de cada región, primero replique la configuración de Azure Event Hubs en cada región. A continuación, configure la réplica de Azure Data Explorer de cada región para ingerir datos de su correspondiente Event Hubs.
Nota:
La ingesta mediante Azure Event Hubs, IoT Hub y Azure Storage es sólida. Si un clúster no está disponible durante un período de tiempo, se detectará más adelante y se insertarán los mensajes y blobs pendientes. Este proceso se basa en la creación de puntos de comprobación.
Como se muestra en el diagrama siguiente, los orígenes de datos producen eventos en la instancia de Event Hubs de todas las regiones y cada réplica de Azure Data Explorer consume los eventos. Los componentes de visualización de datos como Power BI, Grafana o las aplicaciones web desarrolladas con los SDK pueden consultar una de las réplicas.
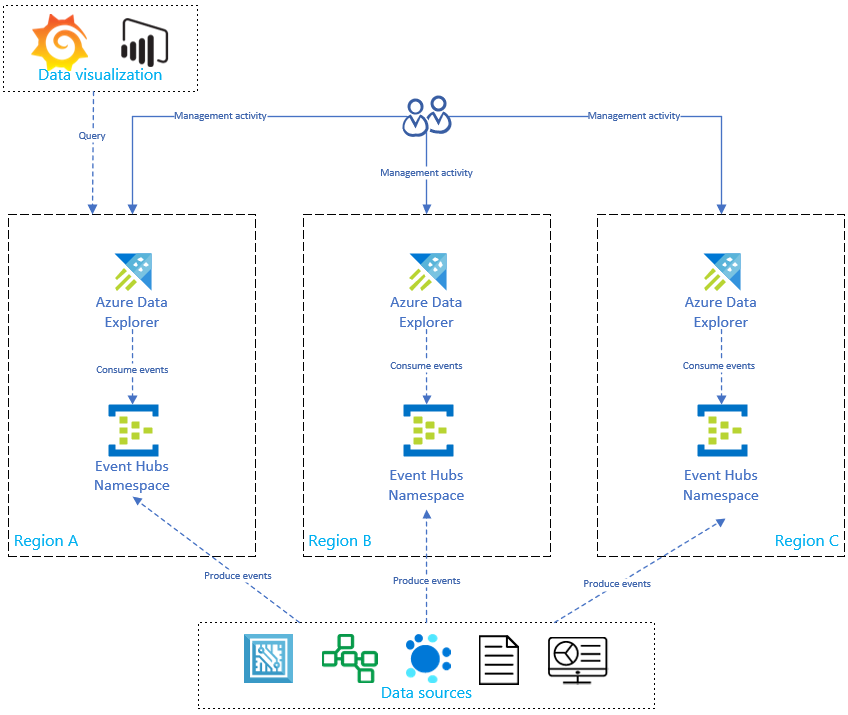
Optimización de costos
Ahora está listo para optimizar las réplicas con algunos de los siguientes métodos:
- Creación de una configuración de recuperación de datos a petición
- Inicio y detención de las réplicas
- Implementación de un servicio de aplicación de alta disponibilidad
- Optimización del costo en una configuración activo-activo
Creación de una configuración de recuperación de datos a petición
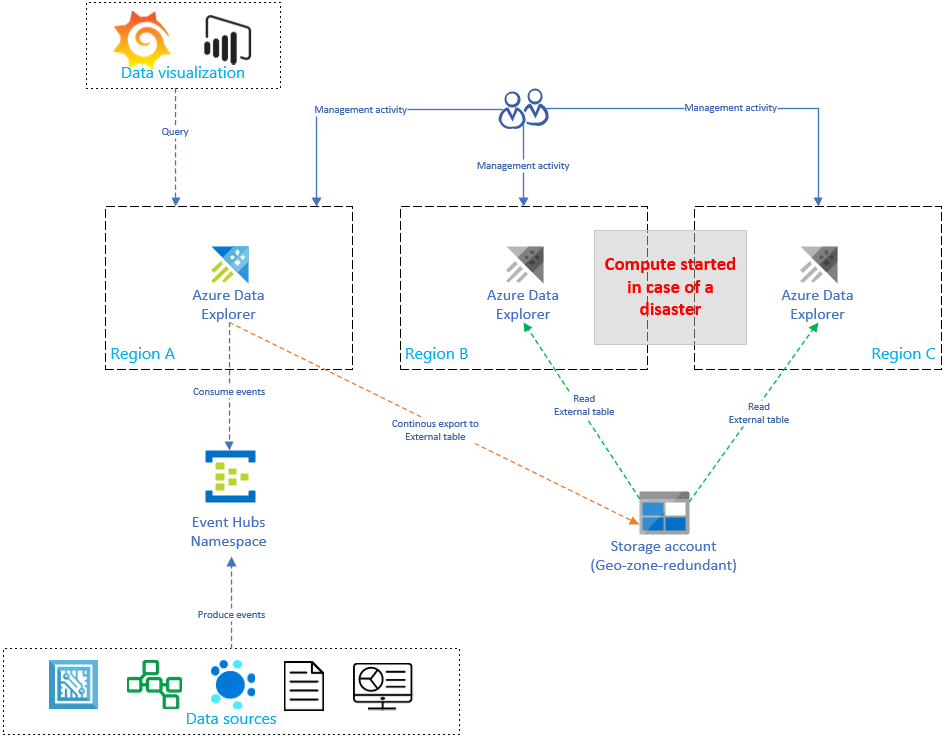
Al replicar y actualizar la configuración de Azure Data Explorer, el costo se incrementará linealmente con el número de réplicas. Para optimizar el costo, puede implementar una variante arquitectónica para equilibrar el tiempo, la conmutación por error y el costo. En una configuración de recuperación de datos a petición, se ha implementado la optimización de costos mediante la introducción de réplicas pasivas de Azure Data Explorer. Estas réplicas solo se activan si hay un desastre en la región primaria (por ejemplo, la región A). No es necesario que las réplicas de las regiones B y C estén activas ininterrumpidamente, lo que reduce significativamente el costo. Sin embargo, en la mayoría de los casos, el rendimiento de estas réplicas no será tan bueno como el del clúster principal. Para más información, consulte Configuración de recuperación de datos a petición.
En la imagen siguiente, solo un clúster realiza la ingesta de datos desde Event Hubs. El clúster principal de la región A realiza la exportación de datos continua de todos los datos a una cuenta de almacenamiento. Las réplicas secundarias tienen acceso a los datos mediante tablas externas.
Inicio y detención de las réplicas
Puede iniciar y detener las réplicas secundarias mediante uno de los métodos siguientes:
Conector de Azure Data Explorer para Power Automate (versión preliminar)
El botón Detener de la pestaña Información general de Azure Portal. Para más información, consulte Detención y reinicio del clúster.
CLI de Azure:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
Implementación de un servicio de aplicación de alta disponibilidad
Creación del cliente de BCDR de Azure App Service
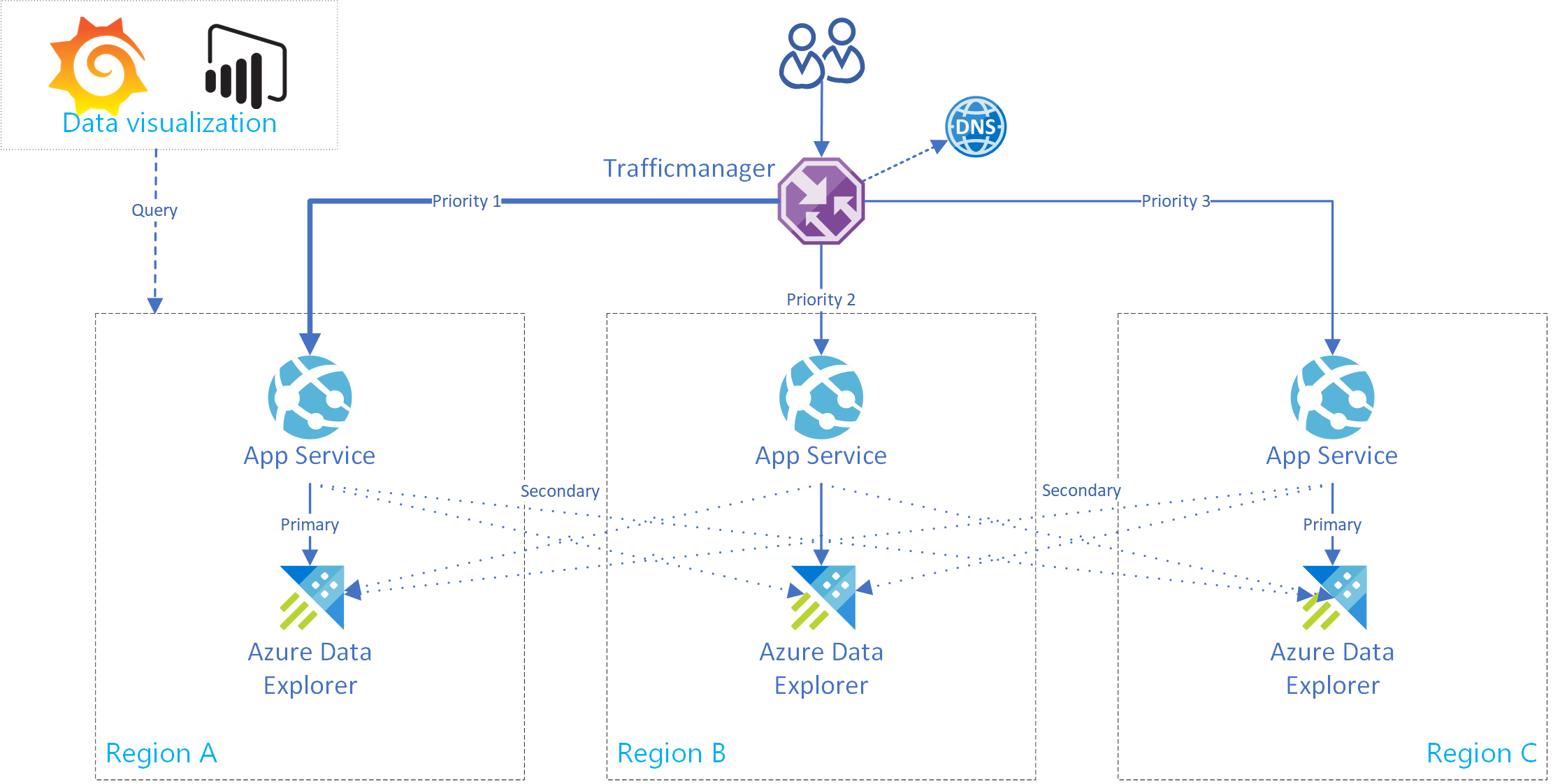
En esta sección se muestra cómo crear una instancia de Azure App Service que admite una conexión a un único clúster principal y a varios clústeres secundarios de Azure Data Explorer. En la imagen siguiente se ilustra la configuración de Azure App Service.
Sugerencia
Tener varias conexiones entre réplicas en el mismo servicio proporciona mayor disponibilidad. Esta configuración no solo es útil en casos de interrupciones regionales.
Utilice este código reutilizable para una instancia de App Service. Se ha creado la clase AdxBcdrClient para implementar un cliente con varios clústeres. Cada consulta que se ejecute mediante este cliente se enviará primero al clúster principal. Si se produce un error, la consulta se enviará a las réplicas secundarias.
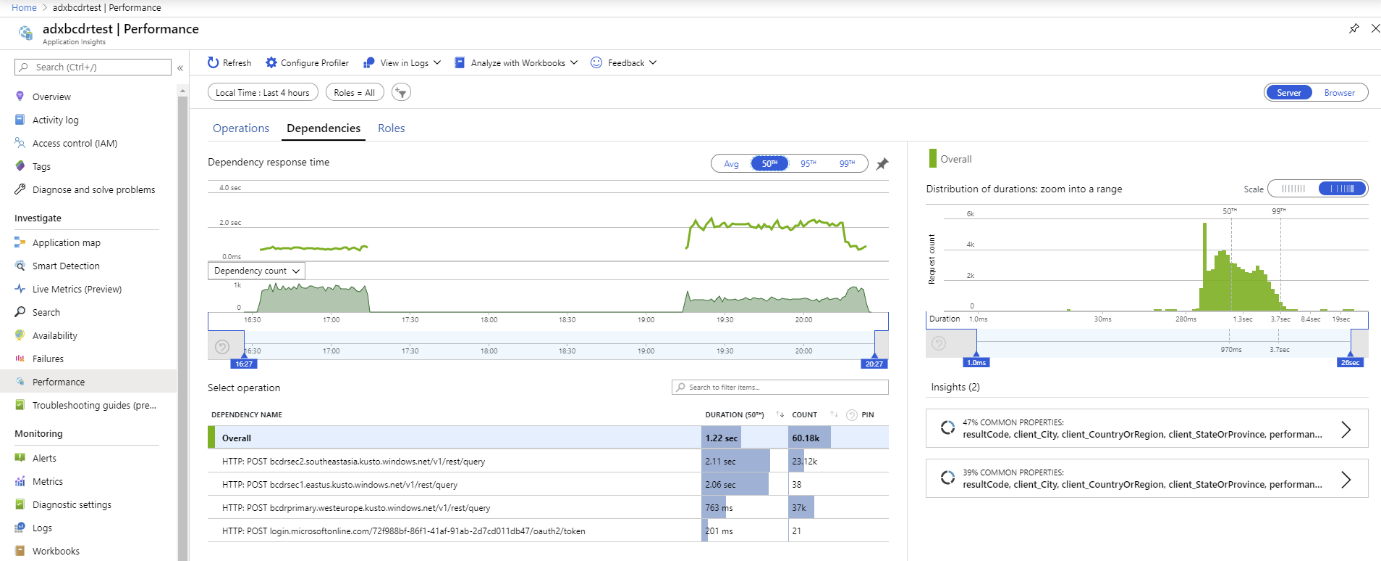
Use métricas personalizadas de Application Insights para medir el rendimiento y la distribución de las solicitudes a los clústeres principal y secundarios.
Prueba del cliente de BCDR de Azure App Service
Hemos ejecutado una prueba con varias réplicas de Azure Data Explorer. Después de una interrupción simulada de los clústeres principal y secundarios, puede ver que el cliente de BCDR de App Service se comporta según lo previsto.
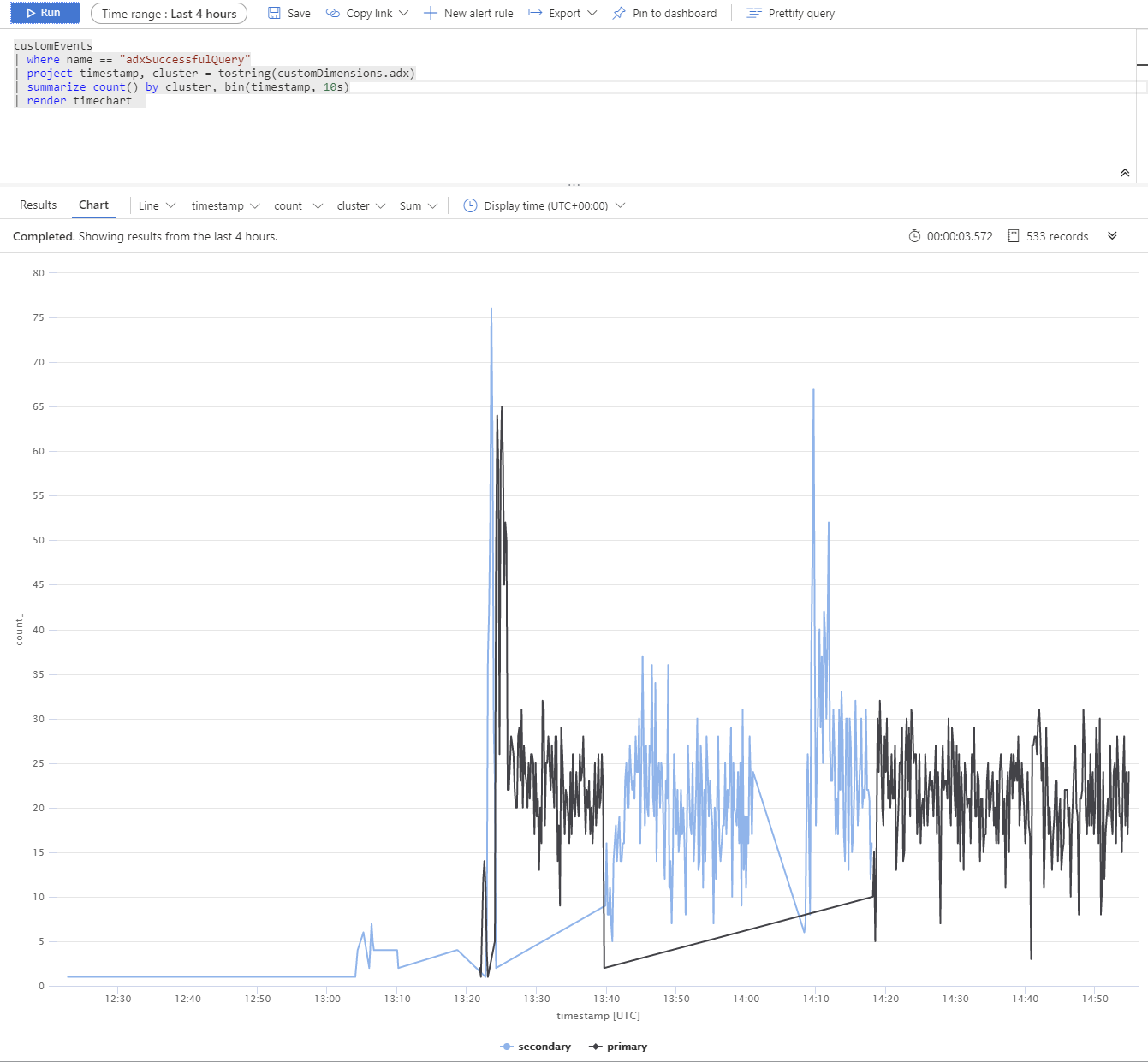
Los clústeres de Azure Data Explorer se distribuyen en Oeste de Europa (2xD14v2 principal), Sudeste Asiático y Este de EE. UU. (2xD11v2).
Nota:
Los tiempos de respuesta más lentos se deben a las diferentes SKU y las consultas globales.
Enrutamiento dinámico o estático
Use los métodos de enrutamiento de Azure Traffic Manager para el enrutamiento dinámico o estático de las solicitudes. Azure Traffic Manager es un equilibrador de carga de tráfico basado en DNS que permite distribuir el tráfico de App Service. Este tráfico está optimizado para los servicios en las regiones globales de Azure, a la vez que proporciona alta disponibilidad y capacidad de respuesta.
También puede usar el enrutamiento basado en Azure Front Door. Para obtener una comparación de estos dos métodos, vea Equilibrio de carga con el conjunto de entrega de aplicaciones de Azure.
Optimización del costo en una configuración activo-activo
El uso de una configuración activo-activo para la recuperación ante desastres aumenta el costo linealmente. El costo incluye los nodos, el almacenamiento, el marcado y un mayor costo de red para el ancho de banda.
Uso de la escalabilidad automática optimizada para optimizar los costos
Use la característica escalabilidad automática optimizada para configurar el escalado horizontal de los clústeres secundarios. Se deben dimensionar para que puedan controlar la carga de la ingesta. Cuando no se pueda acceder al clúster principal, los clústeres secundarios tendrán más tráfico y se escalarán según la configuración.
El uso de la escalabilidad automática optimizada en este ejemplo ahorró aproximadamente un 50 % del costo en comparación con la misma escala horizontal y vertical en todas las réplicas.