Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Data Explorer es un servicio rápido, totalmente administrado y de análisis de datos. Ofrece análisis en tiempo real en grandes volúmenes de datos que transmiten desde muchos orígenes, como aplicaciones, sitios web y dispositivos IoT.
Para copiar datos de una base de datos en Oracle Server, Netezza, Teradata o SQL Server en Azure Data Explorer, debe cargar grandes cantidades de datos de varias tablas. Normalmente, los datos se tienen que dividir aún más en cada tabla para poder cargar filas con varios subprocesos en paralelo desde una única tabla. En este artículo se describe una plantilla para utilizarla en estos escenarios.
Las plantillas de Azure Data Factory son canalizaciones de Data Factory predefinidas. Estas plantillas pueden ayudarle a empezar a trabajar rápidamente con Data Factory y reducir el tiempo de desarrollo en proyectos de integración de datos.
Cree la plantilla de Copia masiva de la base de datos en Azure Data Explorer mediante las actividades de Búsqueda y ForEach. Para una copia de datos más rápida, puede usar la plantilla para crear muchas canalizaciones por base de datos o por tabla.
Importante
Asegúrese de usar la herramienta adecuada para la cantidad de datos que desea copiar.
- Use la plantilla Copia masiva de base de datos en Azure Data Explorer para copiar grandes cantidades de datos de bases de datos como SQL Server y Google BigQuery en Azure Data Explorer.
- Use la herramienta Copia de datos de Data Factory para copiar algunas tablas con pequeñas o moderadas cantidades de datos en Azure Data Explorer.
Prerrequisitos
- Una suscripción de Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Una factoría de datos. Cree una factoría de datos.
- Origen de datos.
Creación de ControlTableDataset
ControlTableDataset indica qué datos se copiarán del origen al destino de la canalización. El número de filas indica el número total de canalizaciones necesarias para copiar los datos. Debe definir ControlTableDataset como parte de la base de datos de origen.
En el código siguiente se muestra un ejemplo del formato de tabla de origen de SQL Server:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Los elementos de código se describen en la tabla siguiente:
| Propiedad | Descripción | Ejemplo |
|---|---|---|
| Id de partición | Orden de copia | 1 |
| SourceQuery | Consulta que indica qué datos se copiarán durante el tiempo de ejecución de la canalización. | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | Nombre de la tabla de destino | MyAdxTable |
Si su ControlTableDataset tiene un formato diferente, cree un ControlTableDataset comparable para su formato.
Uso de la plantilla de copia masiva de la base de datos a Azure Data Explorer
En el panel Introducción , seleccione Crear canalización desde la plantilla para abrir el panel Galería de plantillas .
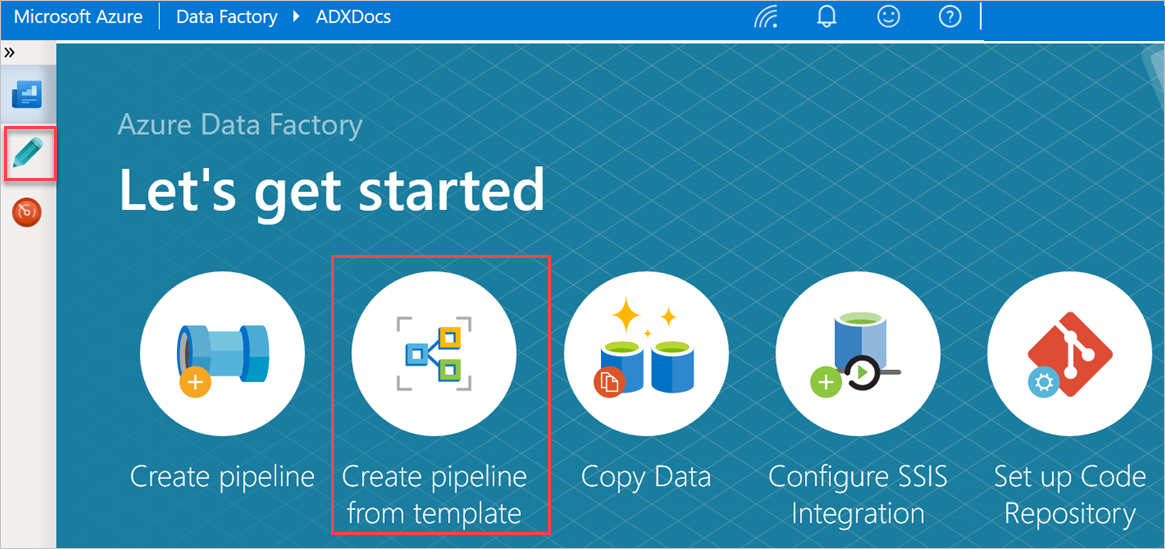
Seleccione la plantilla Copia masiva de la base de datos en Azure Data Explorer .
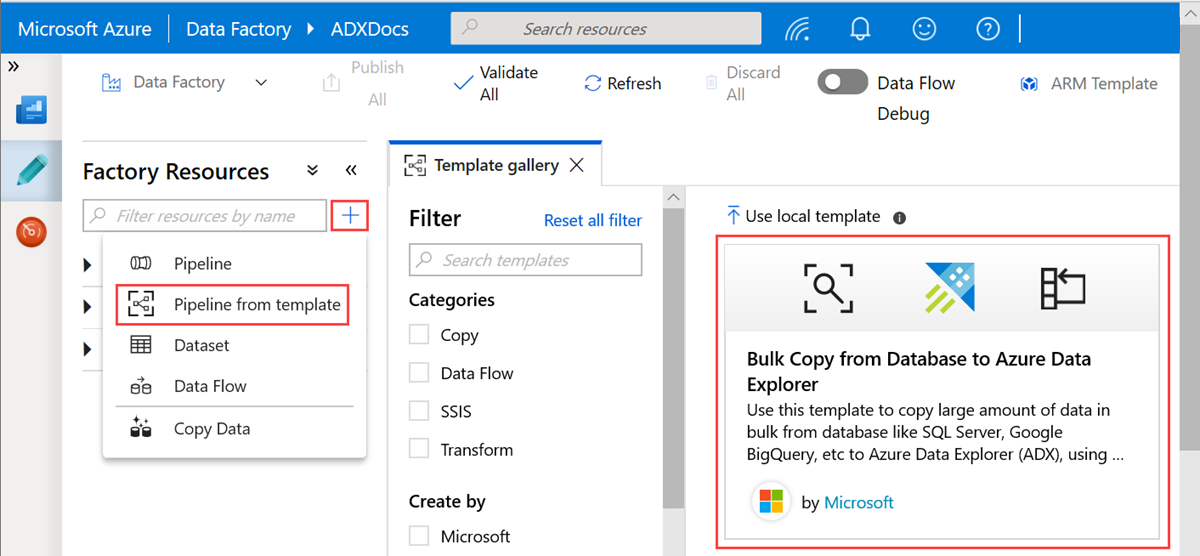
En el panel Copia masiva de la base de datos en Azure Data Explorer , en Entradas de usuario, especifique los conjuntos de datos haciendo lo siguiente:
a) En la lista desplegable ControlTableDataset , seleccione el servicio vinculado a la tabla de control que indica qué datos se copian del origen al destino y dónde se colocará en el destino.
b. En la lista desplegable SourceDataset , seleccione el servicio vinculado a la base de datos de origen.
c. En la lista desplegable AzureDataExplorerTable , seleccione la tabla azure Data Explorer. Si el conjunto de datos no existe, cree el servicio vinculado de Azure Data Explorer para agregar el conjunto de datos.
d. Seleccione Usar esta plantilla.
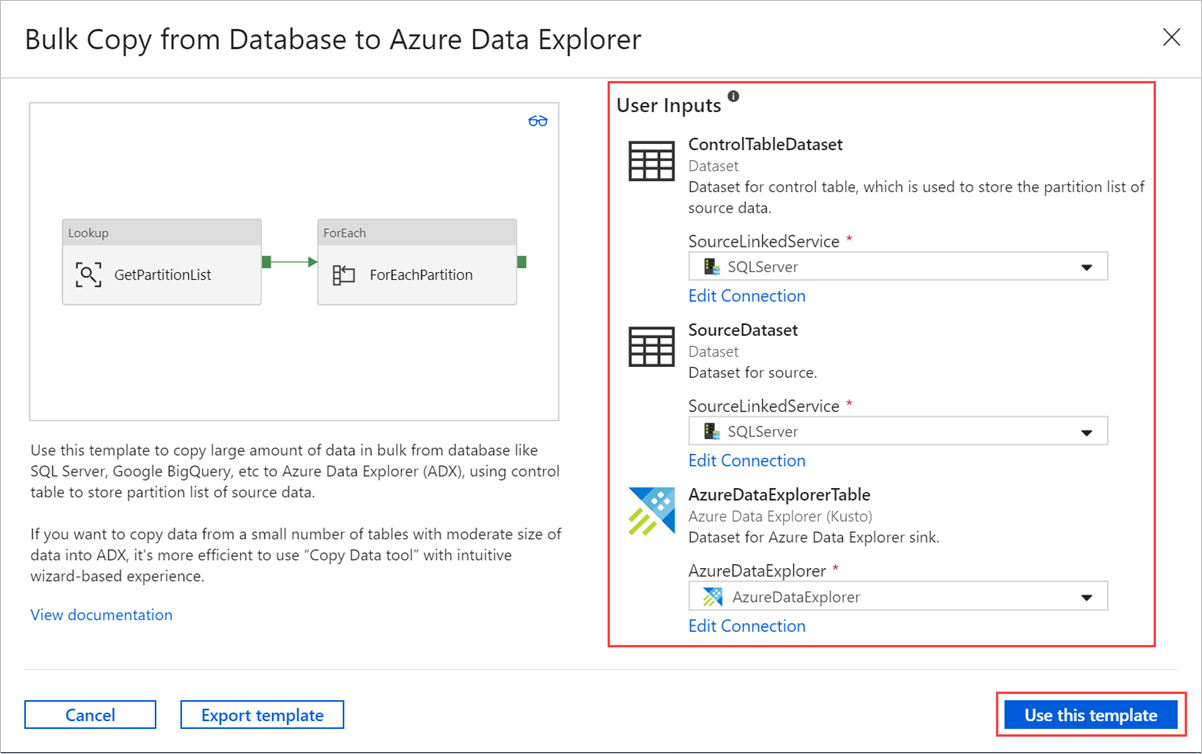
Seleccione un área del lienzo fuera de las actividades para acceder a la canalización de la plantilla. Seleccione la pestaña Parámetros para escribir los parámetros de la tabla, incluido Nombre (nombre de tabla de control) y Valor predeterminado (nombres de columna).
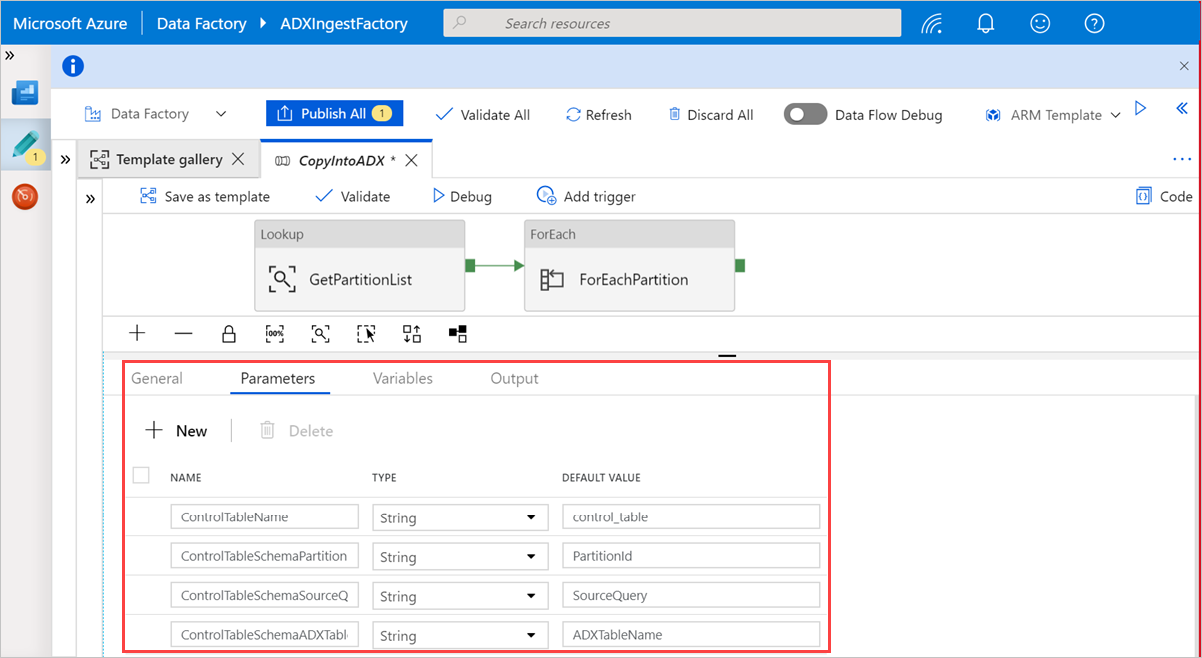
En Búsqueda, seleccione GetPartitionList para ver la configuración predeterminada. La consulta se crea automáticamente.
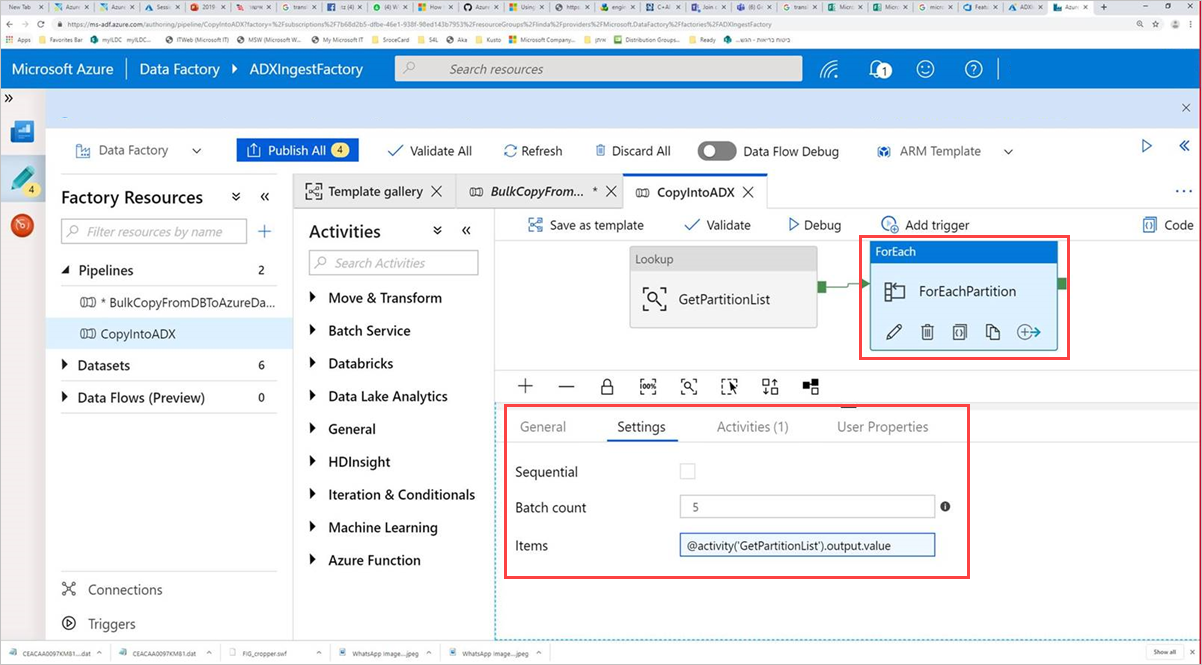
Seleccione la actividad Comando , ForEachPartition, seleccione la pestaña Configuración y haga lo siguiente:
a) En el cuadro Recuento de lotes , escriba un número de 1 a 50. Esta selección determina el número de canalizaciones que se ejecutan en paralelo hasta que se alcanza el número de las filas de ControlTableDataset.
b. Para asegurarse de que los lotes de canalización se ejecutan en paralelo, no active la casilla Secuencial.
Sugerencia
El procedimiento recomendado es ejecutar muchas canalizaciones en paralelo para que los datos se puedan copiar más rápidamente. Para aumentar la eficacia, particione los datos de la tabla de origen y asigne una partición por canalización, según la fecha y la tabla.
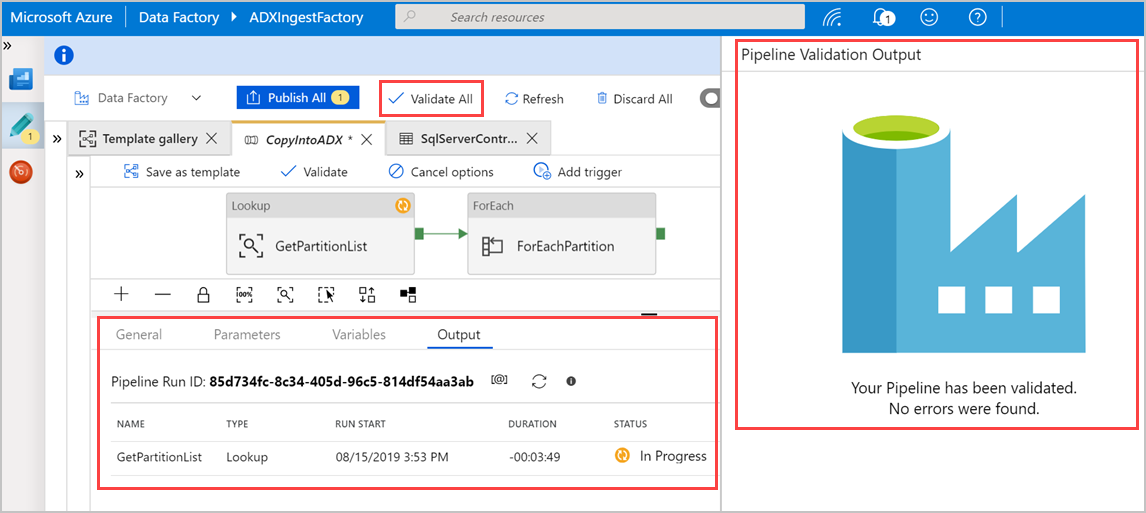
Seleccione Validar todo para validar la canalización de Azure Data Factory y, a continuación, vea el resultado en el panel Salida de validación de canalización .
Si es necesario, seleccione Depurar y, a continuación, seleccione Agregar desencadenador para ejecutar la canalización.
Ahora puede usar la plantilla para copiar de forma eficaz grandes cantidades de datos de las bases de datos y tablas.
Contenido relacionado
- Obtenga información sobre el conector de Azure Data Explorer para Azure Data Factory.
- Edite servicios vinculados, conjuntos de datos y canalizaciones en la interfaz de usuario de Data Factory.
- Consulta de datos en la interfaz de usuario web de Azure Data Explorer.