Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Data Explorer (ADX) es una plataforma de análisis totalmente administrada para el análisis en tiempo real de datos de registro y telemetría a gran escala. En este artículo se explica cómo se calcula el costo por GB ingerido en Azure Data Explorer, qué factores lo impulsan y cómo puede optimizar el clúster para la eficiencia de los costos. Las plataformas de análisis de macrodatos usan diferentes modelos de precios. Muchas plataformas basan los precios en factores como el volumen de consulta, la ingesta de datos, la duración del almacenamiento y los recursos de proceso. Esta complejidad dificulta la comparación de precios entre productos.
Para ayudar a comprender el costo del uso de Azure Data Explorer, en este artículo se usa el costo de métrica por GB ingerido. Esta métrica es el costo total del clúster (proceso, almacenamiento, redes y marcado de servicio) dividido por los datos totales de tamaño original ingeridos durante ese período.
Se utiliza una instantánea representativa de los clústeres de ADX en junio de 2025 para fundamentar el análisis de ejemplo. En las secciones siguientes se muestran los resultados principales del análisis, se explica lo que impulsa las variaciones de costos y cómo los usuarios pueden optimizar el costo por GB ingeridos sin poner en peligro el rendimiento.
Nota:
- Todas las cifras de costos de este artículo muestran los precios de la lista y no incluyen descuentos ni ahorros basados en compromisos.
- Para este análisis de ejemplo, el costo por GB se expresa en Unidades de costo de ejemplo (SCU), donde cada SCU representa una unidad de costo genérica, por ejemplo, un centavo de EE. UU.
- Para obtener información sobre los precios de la lista y cómo calcularlos, consulte Calculadora de precios de Azure Data Explorer.
Análisis del costo por GB ingerido
En el gráfico siguiente se muestran los GB diarios medios ingeridos en tamaño original (eje Y) frente al costo medio por GB ingeridos (eje X) para cada grupo de costos. El tamaño de la burbuja representa la participación del grupo en los datos totales ingeridos en el servicio.
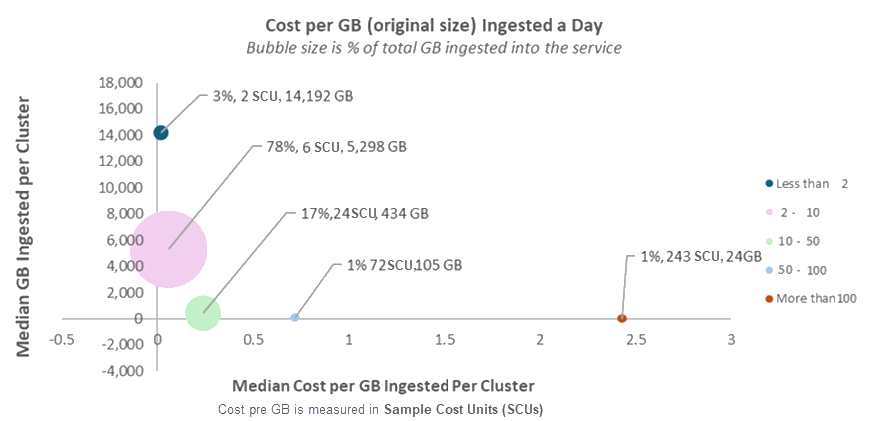
El costo por GB ingerido varía entre clústeres, pero se destacan varios patrones:
La mayoría de los datos (>75%) se ingieren a un costo entre 2 y 10 SCUs por GB (antes de descuentos).
Menos del 5 % de los datos se ingieren a menos de 2 SCU por GB.
Incluso dentro de la misma categoría de uso (o "burbuja"), verá una variación significativa. Por ejemplo, en la burbuja más grande, un clúster ingiere 2 SCUs por GB, mientras que otro alcanza 10 SCUs por GB. Esa es una diferencia de 5X. En las secciones siguientes se explican los motivos clave de esta variación.
Los clústeres con un mayor costo por GB son menos comunes y suelen tener volúmenes de ingesta más bajos. En general, los volúmenes de datos más pequeños significan un mayor costo por GB.
Importante
El gráfico de burbujas muestra que el costo por GB ingerido varía entre clústeres. Esta variación no indica buenas prácticas o incorrectas. Refleja diferentes escenarios, configuraciones y patrones de uso para el servicio.
Por ejemplo, un clúster podría conservar los datos durante más tiempo para cumplir con las normativas, lo que aumenta los costos de almacenamiento. Otro podría usar directivas de actualización que procesan los datos durante la ingestión, lo que incrementa el uso de recursos de computación. Estos escenarios son opciones de diseño intencionadas alineadas con objetivos específicos y afectan naturalmente al costo por GB.
Factores que influyen en el costo por GB ingerido
Estos factores clave están detrás de las variaciones en el costo por GB ingeridos por clúster:
Duración del almacenamiento: cuanto más tiempo almacene los datos, mayor será el costo. Consulte la directiva de retención.
Uso elevado de CPU: acciones como consultas intensivas, procesamiento de datos o transformaciones provocan un uso elevado de la CPU.
Configuración de caché: el almacenamiento en caché aumenta el rendimiento de los datos, pero puede aumentar los costos. Consulte la directiva de caché.
Uso de datos inactivos: Las consultas que acceden a datos inactivos desencadenan transacciones de lectura y aumentan el costo. Consulte caché de nivel de acceso frecuente y de nivel de acceso esporádico.
Transformación y optimización de datos: características como directivas de actualización, vistas materializadas y creación de particiones consumen recursos de CPU y pueden aumentar el costo. Consulte Políticas de actualización, vistas materializadas y particiones.
Volumen de ingesta: los clústeres funcionan de forma más rentable a volúmenes de ingesta más altos.
Ingestión en streaming frente a ingestión en cola: Cada uno tiene un perfil de costes diferente en función del caso de uso. Consulte streaming y en cola.
Diseño de esquema: las tablas anchas con muchas columnas necesitan más recursos de proceso y almacenamiento, lo que aumenta los costos.
Características avanzadas: opciones como seguidores, puntos de conexión privados y espacios aislados de Python consumen más recursos y pueden agregar al costo.
Opción de canalización de datos: algunas vías de ingesta cuestan menos. Por ejemplo, la ingesta de Event Grid suele ser más barata que Event Hubs.
Escalado automático: los clústeres sin escalabilidad automática suelen costar más porque no ajustan su tamaño en función de la demanda.
Puede configurar la mayoría de estos factores para optimizar tanto el rendimiento como el costo.
Un vistazo más detallado a los impulsores clave de los costos
En esta sección se exploran los factores clave que influyen en el costo por GB ingeridos en Azure Data Explorer, lo que proporciona información sobre cómo administrar y optimizar estos costos.
Impacto en la retención de datos en el costo
En ADX, todos los datos ingeridos se almacenan en el almacenamiento persistente. Cada tabla y vista materializada tiene una directiva de retención que define cuánto tiempo se conservan los datos. Cuanto más tiempo se conserven los datos, mayor será el costo, en función de los precios de Azure Storage. Cuando necesita almacenamiento a largo plazo, como para el cumplimiento, el costo por GB ingerido aumenta porque incluye gastos de almacenamiento continuos.
Además del tamaño de extensión notificado por el clúster, hay dos controladores de costos adicionales:
- Búfer de retención: de forma predeterminada, se almacenan 7 días adicionales de datos para protegerse contra la pérdida accidental de datos.
- Sobrecarga de capacidad de recuperación: en las tablas en las que la configuración de capacidad de recuperación está habilitada (valor predeterminado), los datos se conservan durante 14 días adicionales. Esto incluye blobs intermedios generados durante las operaciones de combinación y recompilación.
Tamaño del clúster
El tamaño del clúster es el número de máquinas (nodos) del clúster. Cada máquina agrega costo, en función de su tipo (SKU). El escalado automático ajusta el tamaño del clúster en función del uso de la CPU, por lo que el sistema puede optimizar el costo y el rendimiento evitando los recursos inactivos o redundantes.
El escalado automático ajusta el tamaño del clúster para garantizar que los datos almacenados en caché se ajusten al espacio SSD disponible. Como resultado, una caché grande puede aumentar el tamaño del clúster y, si el uso de CPU es bajo, esto puede provocar un costo mayor por GB. Consulte la herramienta Información de clústeresde la pestaña Caché para obtener más información sobre cómo optimizar el tamaño de la memoria caché.
Los clústeres que ejecutan muchas consultas o realizan tareas intensivas de CPU, como vistas materializadas, directivas de actualización o creación de particiones, pueden escalar el clúster, lo que aumenta el costo por GB. Tenga en cuenta que estas características pueden aumentar significativamente el rendimiento de las consultas y reducir el uso de la CPU de las consultas y, por tanto, mejorar la eficacia general.
Volumen de datos ingeridos
A medida que crece un clúster, se agregan más nodos, lo que aumenta el costo total. Ese costo se distribuye entre todos los datos ingeridos, por lo que cuantos más datos ingiere, menor será el costo por GB.
Uso de datos fríos
Cuando las consultas acceden con frecuencia a datos inactivos almacenados en el disco, provocan transacciones de lectura que usan más recursos y pueden aumentar el costo general del clúster.
Streaming frente a ingesta por lotes
Cada método de ingesta tiene diferentes características de costo, latencia y funcionalidad, por lo que cada uno es mejor para diferentes escenarios. En cuanto a los costes, la ingesta en streaming es más barata cuando se ingestan muchas tablas pequeñas con datos de seguimiento, mientras que la ingesta en cola es más rentable para tablas grandes.
Sugerencia
Optimización del costo por GB ingerido
Compruebe las configuraciones de los principales controladores de costos para asegurarse de que se ajusten a las necesidades del clúster y los requisitos de servicio para lograr una eficacia. En particular:
- Minimice las consultas sobre datos de acceso esporádico para reducir las transacciones de lectura.
- Habilite la escalabilidad automática para que coincida dinámicamente con el tamaño del clúster a petición.