Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Mapeo de flujos de datos en las canalizaciones de Azure Data Factory y Synapse proporciona una interfaz sin necesidad de código para diseñar y ejecutar transformaciones de datos a gran escala. Si no está familiarizado con los flujos de datos de mapeo, consulte la Descripción general del flujo de datos de mapeo. En este artículo se destacan varias maneras de ajustar y optimizar los flujos de datos para que cumplan con los parámetros deseados de rendimiento.
En el siguiente vídeo se muestran algunos intervalos de ejemplo que transforman datos con flujos de datos.
Supervisión del rendimiento de flujo de datos
Después de comprobar la lógica de transformación mediante el modo de depuración, puede ejecutar el flujo de datos de un extremo a otro como una actividad en una canalización. Los flujos de datos se operativizan en una canalización mediante la actividad de ejecución de flujo de datos. La actividad de flujo de datos tiene una experiencia de supervisión única en comparación con otras actividades que muestra un plan de ejecución detallado y un perfil de rendimiento de la lógica de transformación. Para ver información detallada de la supervisión de un flujo de datos, seleccione el icono de las gafas en la salida de la ejecución de actividad de una canalización. Para obtener más información, consulte Supervisión de los mapas de flujo de datos.

Cuando se supervisa el rendimiento del flujo de datos, hay cuatro posibles cuellos de botella que se deben considerar:
- Tiempo para el inicio de actividad del clúster
- Lectura desde una fuente
- Tiempo de transformación
- Escritura en un sumidero
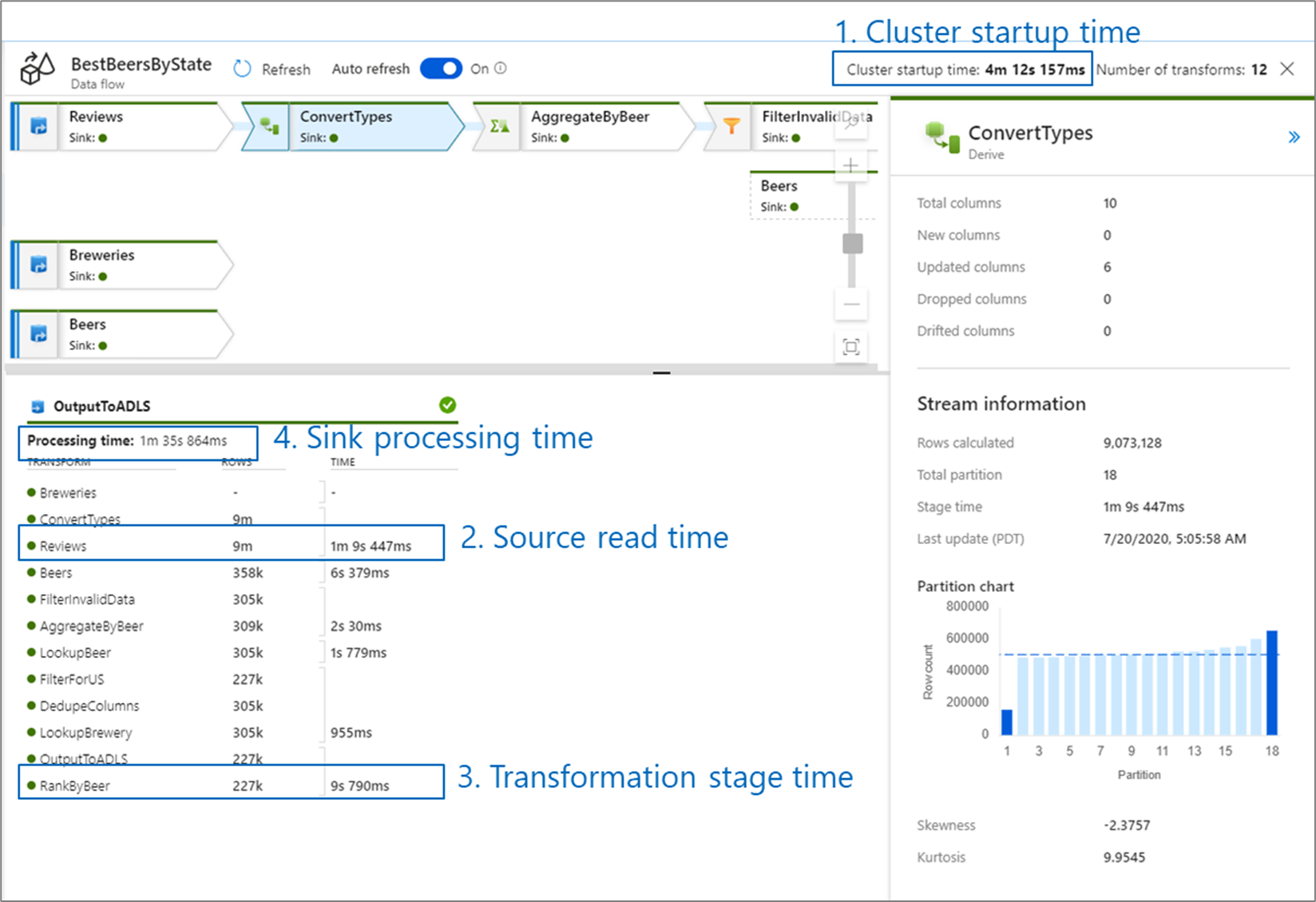
El tiempo para el inicio de actividad del clúster es el tiempo que se tarda en poner en marcha un clúster de Apache Spark. Este valor se encuentra en la esquina superior derecha de la pantalla de supervisión. Los flujos de datos se ejecutan en un modelo Just-in-Time donde cada trabajo utiliza un clúster aislado. Por lo general, el inicio de actividad tarda de tres a cinco minutos. En el caso de los trabajos secuenciales, el tiempo de inicio se puede reducir si se habilita un valor de período de vida. Para obtener más información, consulte la sección Time to live en Integration Runtime performance.
Los flujos de datos usan un optimizador de Spark que reordena y ejecuta la lógica de negocios en "fases" para actuar lo más rápido posible. La salida de la supervisión muestra la duración de cada fase de transformación de cada uno de los receptores en los que escribe el flujo de datos, junto con el tiempo que se tarda en escribir los datos en el receptor. El mayor valor de tiempo es probablemente el cuello de botella del flujo de datos. Si la fase de transformación que más tarda contiene un origen, puede que le interese estudiar cómo mejorar la optimización del tiempo de lectura. Si una transformación tarda mucho tiempo, puede que tenga que volver a crear particiones o aumentar el tamaño del entorno de ejecución de integración. Si el tiempo de procesamiento del receptor es elevado, puede que necesite escalar verticalmente la base de datos o comprobar que no se está generando la salida en un único archivo.
Cuando haya identificado el cuello de botella del flujo de datos, use las siguientes estrategias de optimización para mejorar el rendimiento.
Prueba de la lógica de flujo de datos
Al diseñar y probar flujos de datos desde la interfaz de usuario, el modo de depuración permite probar interactivamente en un clúster de Spark activo, lo que a su vez permite obtener una vista previa de los datos y ejecutar los flujos de datos sin esperar a que un clúster se caliente. Para más información, consulte Modo de depuración.
Pestaña Optimizar
La pestaña Optimize (Optimizar) contiene valores para configurar el esquema de partición del clúster de Spark. Esta pestaña existe en cada transformación de flujo de datos y especifica si se desea volver a crear particiones de los datos después de que se haya completado la transformación. Ajustar las particiones permite controlar la distribución de los datos entre los nodos de proceso y las optimizaciones de la localidad de los datos, lo que puede tener efectos tanto positivos como negativos en el rendimiento general de los flujos de datos.
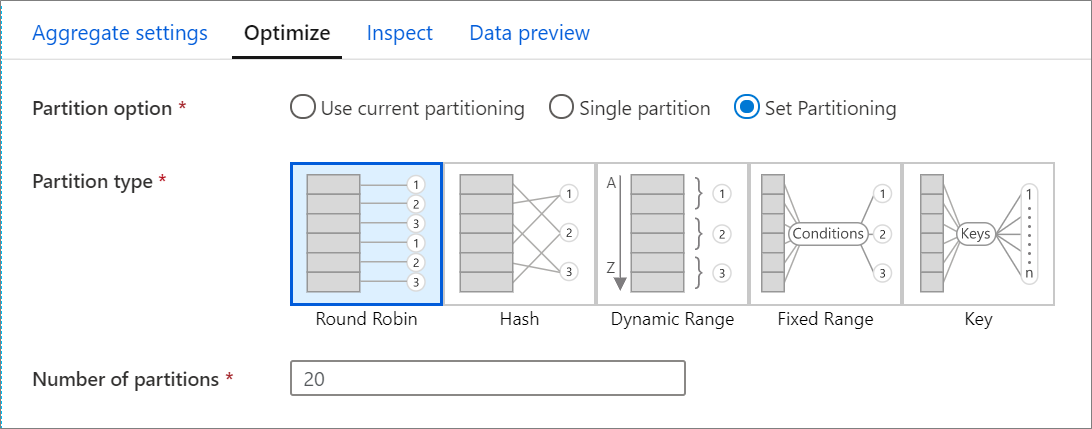
De manera predeterminada, se selecciona Use current partitioning (Usar particiones actuales), que indica al servicio que mantenga las particiones de salida actuales de la transformación. Dado que una nueva partición de datos lleva su tiempo, en la mayoría de los escenarios se recomienda la opción Use current partitioning (Usar particiones actuales). Entre los escenarios en los que es posible que desee volver a crear particiones de los datos se incluyen los que surgen tras agregados y combinaciones que sesgan significativamente los datos o cuando se usa la creación de particiones de origen en una base de datos SQL.
Para cambiar las particiones de cualquier transformación, seleccione la pestaña Optimizar y elija el botón de radio Set Partitioning (Establecer particiones). Aparecen una serie de opciones relacionadas con la creación de particiones. El mejor método para crear particiones depende de los volúmenes de datos, las claves candidatas, los valores nulos y la cardinalidad.
Importante
La opción Single partition (Partición única) combina todos los datos distribuidos en una sola partición. Se trata de una operación muy lenta que también afecta significativamente a todas las operaciones de transformación y escritura de nivel inferior. No es nada recomendable usar esta opción, a menos que haya una razón empresarial explícita para ello.
Las siguientes opciones de creación de particiones están disponibles en todas las transformaciones:
Sistema de turnos
Round robin distribuye los datos equitativamente entre las particiones. Use round robin cuando los candidatos principales no sean lo suficientemente buenos como para implementar una estrategia de creación de particiones sólida e inteligente. Puede establecer el número de particiones físicas.
Hash
El servicio genera un hash de columnas a fin de crear particiones uniformes de tal modo que, por ejemplo, las filas con valores similares estén en la misma partición. Si usa la opción Hash, pruebe si hay una posible distorsión de las particiones. Puede establecer el número de particiones físicas.
Intervalo dinámico
El intervalo dinámico usa los intervalos dinámicos de Spark en función de las columnas o expresiones que proporcione. Puede establecer el número de particiones físicas.
Intervalo fijo
Cree una expresión que proporcione un intervalo de valores fijo en las columnas de datos con particiones. Para evitar la distorsión de la partición, es preciso que conozca perfectamente los datos antes de usar esta opción. Los valores que especifique para la expresión se usan como parte de una función de partición. Puede establecer el número de particiones físicas.
Clave
Si conoce bien la cardinalidad de los datos, la creación de particiones clave puede ser una buena estrategia. La creación de particiones clave crea particiones para cada valor único de la columna. No puede establecer el número de particiones porque dicho número depende de valores únicos de los datos.
Sugerencia
Al establecer manualmente el esquema de partición, los datos se reordenan y se pueden perder las ventajas del optimizador de Spark. Como procedimiento recomendado, conviene no establecer manualmente las particiones a menos que sea necesario hacerlo.
Nivel de registro
Si no es necesario que cada ejecución de canalización de las actividades de flujo de datos anote completamente todos los registros de telemetría detallados, tiene la opción de establecer el nivel de registro en "Básico" o "Ninguno". Al ejecutar los flujos de datos en "modo Verbose" (por defecto), está solicitando al servicio que registre completamente la actividad a nivel de cada partición durante la transformación de los datos. Esta puede ser una operación costosa; por tanto, habilitar solo el modo detallado al solucionar problemas puede mejorar el flujo de datos y el rendimiento de la canalización en general. El modo "básico" solo registra las duraciones de las transformaciones, mientras que "ninguno" solo proporciona un resumen de las duraciones.

Contenido relacionado
- Optimización de orígenes
- Optimización de sumideros
- Optimización de transformaciones
- Uso de flujos de datos en canalizaciones
Consulte otros artículos de Data Flow relacionados con el rendimiento: