Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
A veces, quiere realizar una migración de datos a gran escala desde data lake o almacenamiento de datos empresarial (EDW) para Azure. Otras veces quieres ingerir grandes cantidades de datos de diferentes fuentes en Azure, para el análisis de macrodatos. En cada caso, es fundamental lograr un rendimiento y una escalabilidad óptimos.
Azure Data Factory y canalizaciones de Azure Synapse Analytics proporcionan un mecanismo para ingerir datos, con las siguientes ventajas:
- Administra grandes cantidades de datos
- Tiene un alto rendimiento
- Es rentable
Estas ventajas hacen representan una excelente opción para aquellos ingenieros de datos que desean crear canalizaciones de ingesta de datos escalables con un alto rendimiento.
Después de leer este artículo, podrá responder a las preguntas siguientes:
- ¿Qué nivel de rendimiento y escalabilidad puedo lograr mediante la actividad de copia para escenarios de migración de datos e ingesta de datos?
- ¿Qué pasos debo seguir para optimizar el rendimiento de la actividad de copia?
- ¿Qué optimizaciones de rendimiento puedo usar para una única ejecución de actividad de copia?
- ¿Qué otros factores externos se deben tener en cuenta al optimizar el rendimiento de las copia?
Note
Si no está familiarizado con la actividad de copia en general, consulte la información general de la actividad de copia antes de leer este artículo.
Rendimiento y escalabilidad de copia factibles mediante canalizaciones de Azure Data Factory y Synapse
Azure Data Factory y las canalizaciones de Synapse ofrecen una arquitectura sin servidor que permite paralelismo en distintos niveles.
Esta arquitectura hace posible el desarrollo de canalizaciones que maximizan el rendimiento del movimiento de datos para su entorno. Estas canalizaciones hacen un uso completo de los siguientes recursos:
- Ancho de banda de red entre los almacenes de datos de origen y destino
- Operaciones de entrada/salida por segundo (IOPS) y ancho de banda del almacén de datos de origen o destino
Este uso completo significa que puede calcular el rendimiento general midiendo el rendimiento mínimo disponible con los siguientes recursos:
- Almacén de datos de origen
- Almacén de datos de destino
- Ancho de banda de red entre los almacenes de datos de origen y de destino
En la siguiente tabla se muestra el cálculo de la duración del movimiento de datos. La duración de cada celda se calcula en función de un determinado ancho de banda de red y almacén de datos y de un determinado tamaño de carga de datos.
Note
La duración proporcionada a continuación está pensada para representar un rendimiento factible en una solución de integración de datos de un extremo a otro, usando una o varias de las técnicas de optimización del rendimiento descritas en Características de optimización del rendimiento de la actividad de copia. Entre estas técnicas se incluye el uso de ForEach para crear particiones y generar varias actividades de copia simultáneas. Se recomienda seguir el procedimiento descrito en Pasos de optimización del rendimiento con el fin de optimizar el rendimiento de la actividad de copia para su conjunto de datos y su configuración del sistema en particular. Debe usar los números obtenidos en las pruebas de optimización del rendimiento con relación al planeamiento de la implementación de producción, el planeamiento de la capacidad y la proyección de facturación.
| Tamaño de los datos / bandwidth |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 minutos | 1,4 minutos | 0,3 minutos | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 GB | 27,3 minutos | 13,7 minutos | 2,7 minutos | 1,3 minutos | 0,3 minutos | 0,1 min | 0,03 min |
| 100 GB | 4,6 horas | 2,3 horas | 0,5 horas | 0,2 horas | 0,05 horas | 0,02 horas | 0,0 horas |
| 1 TB | 46,6 horas | 23.3 horas | 4,7 horas | 2,3 horas | 0,5 horas | 0,2 horas | 0,05 horas |
| 10 TB | 19,4 días | 9,7 días | 1,9 días | 0,9 días | 0,2 días | 0,1 días | 0,02 días |
| 100 TB | 194.2 días | 97.1 días | 19,4 días | 9,7 días | 1,9 días | 1 día | 0,2 días |
| 1 PB | 64.7 mo | 32,4 mo | 6.5 mo | 3.2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647.3 mo | 323.6 mo | 64.7 mo | 31.6 mo | 6.5 mo | 3.2 mo | 0,6 mo |
La copia puede escalarse en diferentes niveles:
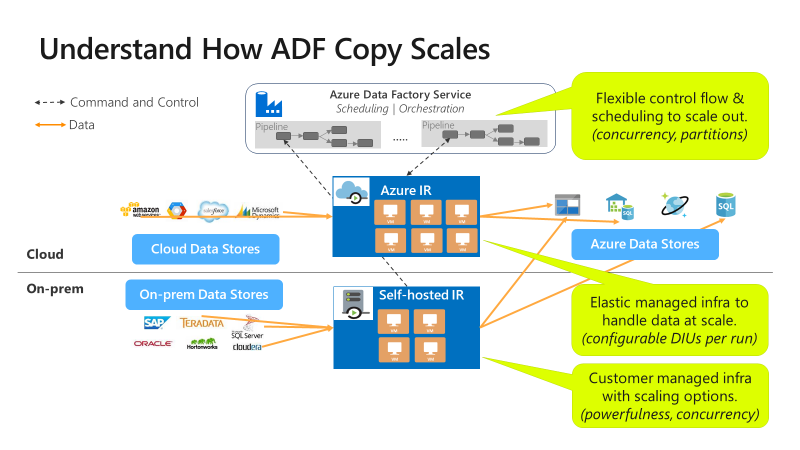
El flujo de control puede iniciar varias actividades de copia en paralelo, por ejemplo, mediante un bucle ForEach.
Una sola actividad de copia puede aprovechar los recursos de proceso escalables.
- Al usar el entorno de ejecución de integración de Azure, puede especificar hasta 256 unidades de integración de datos (DIU) para cada actividad de copia sin servidor.
- Al usar IR autohospedado, puede utilizar uno de los métodos siguientes:
- Escalar verticalmente la máquina de forma manual.
- Escalar horizontalmente a varias máquinas (hasta 4 nodos), y una única actividad de copia dividirá su conjunto de archivos en todos los nodos.
Una única actividad de copia lee y escribe en el almacén de datos mediante varios subprocesos en paralelo.
Pasos de optimización del rendimiento
Para optimizar el rendimiento del servicio con la actividad de copia, siga estos pasos:
Seleccione un conjunto de datos de prueba y establezca una línea de base.
Durante el desarrollo, pruebe la canalización, para lo que debe usar la actividad de copia con unos datos de ejemplo representativos. El conjunto de datos que elija debe representar los patrones de datos típicos a lo largo de los siguientes atributos:
- Estructura de carpetas
- Patrón de archivo
- Esquema de datos
Y el conjunto de datos debe ser lo suficientemente grande como para evaluar el rendimiento de la copia. Para un buen tamaño, la actividad de copia tarda al menos 10 minutos en completarse. Recopile los detalles de la ejecución y las características del rendimiento después de la supervisión de la actividad de copia.
Cómo maximizar el rendimiento de una única actividad de copia:
Se recomienda maximizar primero el rendimiento mediante una única actividad de copia.
Si se ejecuta la actividad de copia en un Azure integration runtime:
Comience con los valores predeterminados de las unidades de integración de datos (DIU) y la configuración de copia paralela.
Si la actividad de copia se va a ejecutar en un entorno de ejecución de integración autohospedado:
Se recomienda usar una máquina dedicada para hospedar el entorno de ejecución de integración. La máquina debe ser independiente del servidor que hospeda el almacén de datos. Comience con los valores predeterminados para la configuración de copia en paralelo y use un solo nodo para el IR autohospedado.
Realice una serie de pruebas de rendimiento. Tome nota del rendimiento conseguido. Incluya los valores reales usados, como las DIU y las copias paralelas. Consulte la supervisión de la actividad de copia para obtener información sobre cómo recopilar los resultados de las pruebas y la configuración de rendimiento. Obtenga información acerca de cómo solucionar problemas de rendimiento de la actividad de copia para identificar y resolver el cuello de botella.
Iteración para realizar más ejecuciones de pruebas de rendimiento siguiendo las instrucciones de solución de problemas y optimización. Una vez que ejecutar una sola actividad de copia ya no mejora el rendimiento, considere maximizar el rendimiento agregado ejecutando varias copias simultáneamente. Esta opción se describe en la siguiente viñeta numerada.
Cómo maximizar el rendimiento agregado mediante la ejecución de varias copias simultáneamente:
Ahora ha maximizado el rendimiento de una única actividad de copia. Si aún no ha alcanzado los límites superiores de rendimiento de su entorno, puede ejecutar varias actividades de copia en paralelo. Puede ejecutar en paralelo mediante construcciones de flujo de control. Una de estas construcciones el bucle For Each. Para obtener más información, consulte los siguientes artículos sobre las plantillas de solución:
Expanda la configuración a todo el conjunto de datos.
Cuando esté satisfecho con los resultados y el rendimiento de la ejecución, puede expandir la definición y la canalización para cubrir todo el conjunto de datos.
Solución de problemas de rendimiento de la actividad de copia
Siga los pasos de optimización del rendimiento para planear y realizar la prueba de rendimiento de su escenario. Y aprenda a solucionar los problemas de rendimiento de la ejecución de la actividad de copia desde Solución de problemas de rendimiento de la actividad de copia.
Características de optimización del rendimiento
El servicio proporciona las siguientes características de optimización del rendimiento:
- Unidades de integración de datos
- Escalabilidad de Integration Runtime autohospedado
- Copia en paralelo
- Copia almacenada provisionalmente
Unidades de integración de datos
Una unidad de integración de datos (DIU) es una medida que representa la potencia de una sola unidad en Azure Data Factory y canalizaciones de Synapse. La potencia es una combinación de CPU, memoria y asignación de recursos de red. La DIU solo se aplica a Azure integration Runtime. La DIU no se aplica al entorno de ejecución de integración autohospedado. Obtenga más información aquí.
Escalabilidad del entorno de ejecución de integración autohospedado
Es posible que desee hospedar una carga de trabajo simultánea creciente. O bien, puede que desee conseguir un mayor rendimiento en el nivel de carga de trabajo actual. Puede mejorar la escala del procesamiento mediante los siguientes métodos:
- Puede escalar verticalmente el entorno de ejecución de integración autohospedado aumentando el número de trabajos simultáneos que se pueden ejecutar en un nodo.
El escalado vertical solo funciona si el procesador y la memoria del nodo son inferiores al uso completo. - Puede escalar horizontalmente el entorno de ejecución de integración autohospedado agregando más nodos (máquinas).
Para más información, consulte:
- Características de optimización del rendimiento de la actividad de copia: escalabilidad del entorno de ejecución de integración autohospedado
- Creación y configuración de un entorno de ejecución de integración autohospedado: consideraciones de escala
Copia en paralelo
Puede establecer la propiedad parallelCopies para indicar el paralelismo que desea que utilice la actividad de copia. Considere esta propiedad como el número máximo de subprocesos dentro de la actividad de copia. Los subprocesos operan en paralelo. Los subprocesos leen desde el origen o escriben en los almacenes de datos receptores.
Obtenga más información.
copia almacenada provisionalmente
Una operación de copia de datos puede enviar los datos directamente al almacén de datos receptor. Como alternativa, puede usar el almacenamiento de blobs como almacenamiento provisional. Obtenga más información.
Contenido relacionado
Consulte los restantes artículos acerca de la actividad de copia:
- Información general de la actividad de copia
- Solución de problemas de rendimiento de la actividad de copia
- Funciones de optimización del rendimiento de la actividad de copia
- Utiliza Azure Data Factory para migrar datos desde tu data lake o almacén de datos a Azure
- Migrar datos de Amazon S3 a Azure Storage