Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
¿Busca una manera fácil de mover datos? El trabajo de copia de Microsoft Fabric ofrece una manera sencilla y escalable de cargar datos sin crear una canalización. Obtenga información sobre cómo crear una.
En canalizaciones de Azure Data Factory y Synapse, puede usar la actividad de copia para copiar datos entre almacenes de datos locales y en la nube. Después de copiar los datos, puede usar otras actividades para luego transformarlos y analizarlos. La actividad de copia también puede usarse para publicar los resultados de transformación y análisis de inteligencia empresarial (BI) y el consumo de la aplicación.
La actividad de copia se ejecuta en un entorno de ejecución de integración. Puede usar diferentes tipos de entornos de ejecución de integración para diferentes escenarios de copia de datos:
- Al copiar datos entre dos almacenes de datos a los que se puede acceder públicamente mediante Internet desde cualquier dirección IP, puede usar el entorno de ejecución de integración de Azure para la actividad de copia. Este entorno de ejecución de integración es seguro, confiable, escalable y está globalmente disponible.
- Cuando vaya a copiar datos con almacenes de datos como origen o destino ubicados en el entorno local o en una red con control de acceso (por ejemplo, una red virtual de Azure), debe configurar un entorno de ejecución de integración autohospedado.
Un entorno de ejecución de integración debe estar asociado con todos los almacenes de datos receptores y de origen. Para información sobre cómo la actividad de copia determina qué entorno de ejecución de integración se va a usar, consulte Determinar qué entorno de ejecución de integración usar.
Nota:
No puede usar más de un entorno de ejecución de integración autohospedado en la misma actividad Copy. El origen y el receptor de la actividad deben estar conectados con el mismo entorno de ejecución de integración autohospedado.
Para copiar datos de un origen a un receptor, el servicio que ejecuta la actividad de copia realiza estos pasos:
- Lee datos desde un almacén de datos de origen.
- Realiza procesos de serialización y deserialización, compresión y descompresión, asignación de columnas, etc. Lleva a cabo estas operaciones según la configuración del conjunto de datos de entrada y salida, y la actividad de copia.
- Escribe datos en el almacén de datos de receptor o destino.

Nota:
Si usa un entorno de ejecución de integración autohospedado en un almacén de datos de origen o receptor en una actividad de copia, tanto el origen como el receptor deben ser accesibles desde el servidor que hospeda el entorno de ejecución de integración para que la actividad de copia se realice correctamente.
Almacenes de datos y formatos que se admiten
Nota:
Si un conector está marcado como versión preliminar, puede probarlo y enviarnos sus comentarios. Si quiere tener una dependencia de los conectores de versión preliminar de la solución, póngase en contacto con el servicio de soporte técnico de Azure.
Formatos de archivos admitidos
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato Iceberg (solo para Azure Data Lake Storage Gen2)
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
La actividad de copia se puede usar para copiar archivos tal cual entre dos almacenes de datos basados en archivos, en cuyo caso los datos se copian de manera eficaz sin serialización ni deserialización. Además, también puede analizar o generar archivos con un formato determinado; por ejemplo, puede realizar lo siguiente:
- Copiar datos de una base de datos de SQL Server y escribirlos en Azure Data Lake Storage Gen2 en formato Parquet.
- Copiar archivos en formato de texto (CSV) desde el sistema de archivos local y escribirlos en Azure Blob Storage en formato Avro
- Copiar archivos comprimidos del sistema de archivos local, descomprimirlos sobre la marcha y escribirlos en Azure Data Lake Storage Gen2.
- Copiar datos en formato de texto comprimido Gzip (CSV) de Azure Blob Storage y escribirlos en Azure SQL Database
- Muchas más actividades que requieren serialización y deserialización o compresión y descompresión.
Regiones admitidas
El servicio que permite la actividad de copia está disponible globalmente en las regiones y zonas geográficas enumeradas en Ubicaciones de Azure Integration Runtime. La topología disponible globalmente garantiza un movimiento de datos eficiente que, normalmente, evita saltos entre regiones. Consulte Productos por región para comprobar la disponibilidad de Data Factory, áreas de trabajo de Synapse y movimiento de datos en una región específica.
Configuración
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- Herramienta Copiar datos
- Azure Portal
- SDK de .NET
- SDK de Python
- Azure PowerShell
- REST API
- Plantilla de Azure Resource Manager
En general, para usar la actividad de copia en canalizaciones de Azure Data Factory o Synapse, debe hacer lo siguiente:
- Crear servicios vinculados para el almacén de datos de origen y el almacén de datos receptor. Puede encontrar la lista de conectores admitidos en la sección Almacenes de datos y formatos que se admiten de este artículo. Consulte la sección "Propiedades del servicio vinculado" del artículo sobre conectores para información sobre la configuración y las propiedades admitidas.
- Crear conjuntos de datos para el origen y el receptor. Consulte las secciones "Propiedades del conjunto de datos" de los artículos sobre los conectores de origen y receptor para información sobre la configuración y las propiedades admitidas.
- Crear una canalización con la actividad de copia. Se proporciona un ejemplo en la sección siguiente.
Sintaxis
La plantilla siguiente de una actividad de copia contiene una lista completa de todas las propiedades admitidas. Especifique las que se adapten a su escenario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Detalles de la sintaxis
| Propiedad | Descripción | ¿Necesario? |
|---|---|---|
| tipo | Para una actividad de copia, establezca esta propiedad en Copy. |
Sí |
| entradas | Especifique el conjunto de datos que creó y que señala a los datos de origen. La actividad de copia admite solo una entrada. | Sí |
| outputs | Especifique el conjunto de datos que creó y que señala a los datos del receptor. La actividad de copia admite solo una salida. | Sí |
| typeProperties | Especifique las propiedades para configurar la actividad de copia. | Sí |
| fuente | Especifique el tipo de origen de copia y las propiedades correspondientes para la recuperación de datos. Para más información, consulte la sección "Propiedades de la actividad de copia" del artículo sobre conectores que aparece en Almacenes de datos y formatos que se admiten. |
Sí |
| receptor | Especifique el tipo de receptor de copia y las propiedades correspondientes para escribir datos. Para más información, consulte la sección "Propiedades de la actividad de copia" del artículo sobre conectores que aparece en Almacenes de datos y formatos que se admiten. |
Sí |
| translator | Especifique asignaciones de columna explícitas de origen a receptor. Esta propiedad se aplica cuando el comportamiento de copia predeterminado no satisface sus necesidades. Para más información, consulte Asignación de esquemas en la actividad de copia. |
No |
| dataIntegrationUnits | Especifique una medida que represente la cantidad de potencia que emplea el entorno de ejecución de integración de Azure para la copia de datos. Estas unidades se conocían anteriormente como unidades de movimiento de datos de nube (DMU). Para más información, consulte Unidades de integración de datos. |
No |
| parallelCopies | Especifique el paralelismo que quiere que use la actividad de copia al leer datos del origen y escribirlos en el receptor. Para obtener más información, consulte Copia paralela. |
No |
| preservar | Especifique si desea conservar los metadatos o las ACL durante la copia de datos. Para obtener más información, vea Conservación de metadatos. |
No |
| enableStaging stagingSettings |
Especifique si quiere almacenar provisionalmente los datos en una instancia de Blob Storage en lugar de copiarlos directamente del origen al receptor. Para información sobre escenarios útiles y detalles de configuración, consulte Copia almacenada provisionalmente. |
No |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Elija cómo controlar las filas incompatibles al copiar datos del origen al receptor. Para más información, consulte Tolerancia a errores. |
No |
Supervisión
Puede supervisar la ejecución de la actividad de copia en canalizaciones de Azure Data Factory y Synapse visualmente o mediante programación. Para obtener más detalles, consulte Supervisión de la actividad de copia.
Copia incremental
Las canalizaciones de Data Factory y Synapse le permiten copiar de forma incremental datos diferenciales de un almacén de datos de origen a otro receptor. Para más información, consulte Tutorial: Copia de datos de forma incremental.
Rendimiento y optimización
La experiencia de supervisión de la actividad de copia muestra las estadísticas de rendimiento de copia de cada una de las ejecuciones de actividad. En el artículo Guía de escalabilidad y rendimiento de la actividad de copia se describen los factores claves que afectan al rendimiento del movimiento de datos mediante la actividad de copia. También se muestran los valores de rendimiento observados durante las pruebas y se describe cómo optimizar el rendimiento de la actividad de copia.
Reanudación desde el último error de ejecución
La actividad de copia admite la reanudación de la última ejecución fallida al copiar archivos de gran tamaño tal cual con formato binario entre almacenes basados en archivos y elegir conservar la jerarquía de carpetas o archivos del origen al destino, por ejemplo, para migrar datos de Amazon S3 a Azure Data Lake Storage Gen2. Se aplica a los siguientes conectores basados en archivos: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage y SFTP.
Puede usar la reanudación de la actividad de copia de las dos maneras siguientes:
Reintento de nivel de actividad: Puede establecer el número de reintentos en la actividad de copia. Durante la ejecución de la canalización, si se produce un error en la ejecución de la actividad de copia, el siguiente reintento automático se inicia desde el punto de error de la última prueba.
Volver a ejecutar desde la actividad con errores: Una vez finalizada la ejecución de la canalización, también puede desencadenar una nueva ejecución desde la actividad con errores en la vista de supervisión de la interfaz de usuario de ADF o mediante programación. Si la actividad con errores es una actividad de copia, la canalización no solo se vuelve a ejecutar desde esta actividad, sino que también se reanuda desde el punto de error de la ejecución anterior.
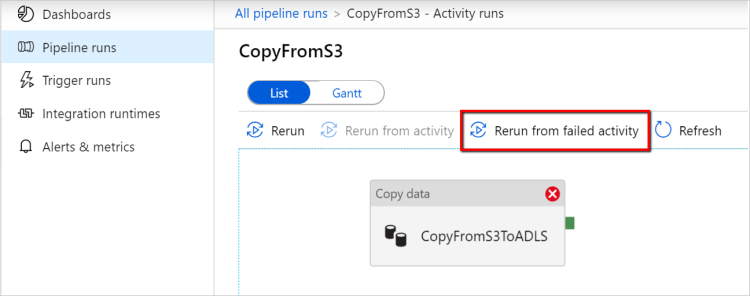
Algunos puntos que se deben tener en cuenta:
- La reanudación se produce en el nivel de archivo. Si se produce un error en la actividad de copia al copiar un archivo, en la siguiente ejecución, se volverá a copiar este archivo específico.
- Para que la reanudación funcione correctamente, no cambie la configuración de la actividad de copia entre las reactivaciones.
- Al copiar datos de Amazon S3, Azure Blob, Azure Data Lake Storage Gen2 y Google Cloud Storage, la actividad de copia puede reanudarse desde un número arbitrario de archivos copiados. Por su parte, cuando los orígenes son el resto de conectores basados en archivos, la actividad de copia actualmente admite la reanudación desde un número limitado de archivos, normalmente en el intervalo de decenas de miles y varía en función de la longitud de las rutas de acceso de archivo. Los archivos que superen este número se volverán a copiar durante la nueva ejecución.
En el caso de otros escenarios de copia de archivos binarios, la ejecución de la actividad de copia comienza desde el principio.
Nota:
La reanudación de la última ejecución con errores a través del entorno de ejecución de integración autohospedado ahora solo se admite en la versión 5.43.8935.2 o posterior del entorno de ejecución de integración autohospedado.
Conservación de los metadatos junto con los datos
Al copiar datos desde el origen al receptor, en escenarios como la migración de Data Lake, también puede optar por conservar los metadatos y las ACL junto con los datos mediante la actividad de copia. Consulte Conservación de metadatos para obtener más información.
Adición de etiquetas de metadatos a un receptor basado en archivos
Cuando el receptor está basado en Azure Storage (Azure Data Lake Storage o Azure Blob Storage), podemos optar por agregar metadatos a los archivos. Estos metadatos aparecerán como parte de las propiedades del archivo como pares clave-valor. Para todos los tipos de sumideros basados en archivos, puede agregar metadatos que incluyan contenido dinámico mediante los parámetros de canalización, las variables del sistema, las funciones y las variables. Además de esto, para un receptor basado en archivos binarios, tiene la opción de agregar la fecha y hora de la última modificación (del archivo de origen) mediante la palabra clave $$LASTMODIFIED y valores personalizados como metadatos en el archivo receptor.
Asignación de tipo de datos y esquema
Para información sobre cómo la actividad de copia asigna los datos de origen al receptor, consulte Asignación de tipo de datos y esquema.
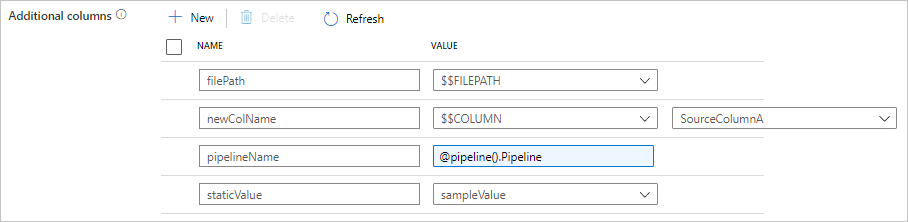
Adición de columnas adicionales durante la copia
Además de copiar datos desde el almacén de datos de origen al receptor, también puede configurar la adición de columnas de datos adicionales para copiar junto con el receptor. Por ejemplo:
- Al copiar desde un origen basado en archivos, almacene la ruta de acceso del archivo relativa como una columna adicional de tipo String para realizar un seguimiento del archivo del que proceden los datos.
- Duplique la columna de origen especificada como otra columna.
- Agregue una columna con la expresión de ADF para asociar variables del sistema ADF, como el nombre de la canalización o el identificador de la canalización, o bien almacene otros valores dinámicos de la salida de la actividad ascendente.
- Agregue una columna con un valor estático para satisfacer sus necesidades de consumo descendente.
Puede encontrar la siguiente configuración en la pestaña de origen de la actividad de copia. También puede asignar esas columnas adicionales en la actividad de copia asignación de esquemas como de costumbre con los nombres de columna definidos.
Sugerencia
Esta característica funciona con el modelo de conjunto de datos más reciente. Si no ve esta opción desde la interfaz de usuario, intente crear un nuevo conjunto de datos.
Para configurarlo mediante programación, agregue la propiedad additionalColumns al origen de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| columnas adicionales | Agregue columnas de datos adicionales para copiarlas en el receptor. Cada objeto de la matriz additionalColumns representa una columna adicional.
name define el nombre de la columna y value indica el valor de los datos de esa columna.Los valores permitidos de los datos son: - $$FILEPATH: una variable reservada indica almacenar la ruta de acceso relativa de los archivos de origen en la ruta de acceso de la carpeta especificada en el conjunto de datos. Se aplica en un origen basado en archivos.- $$COLUMN:<source_column_name>: un patrón de variable reservada indica que se duplique la columna de origen especificada como otra columna- Expresión - Valor estático |
No |
Ejemplo:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Sugerencia
Después de configurar columnas adicionales, recuerde asignarlas al receptor de destino, en la pestaña Asignación.
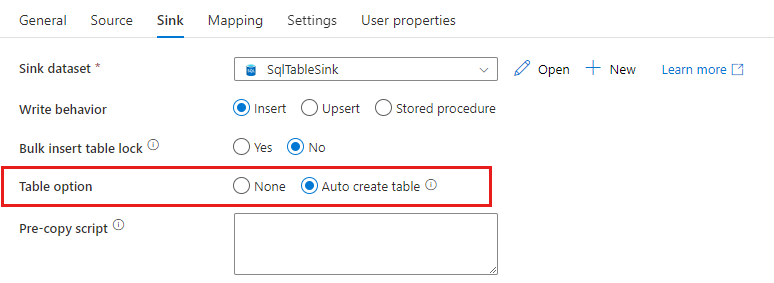
Creación automática de tablas de receptores
Al copiar datos en SQL Database o Azure Synapse Analytics, si la tabla de destino no existe, la actividad de copia admite la creación automática en función de los datos de origen. Esto pretende ayudarle a empezar rápidamente a cargar los datos y evaluar SQL Database o Azure Synapse Analytics. Después de la ingesta de datos, puede revisar y ajustar el esquema de la tabla de receptores según sus necesidades.
Esta característica se acepta cuando se copian datos desde cualquier origen en los siguientes almacenes de datos de receptor. Puede encontrar la opción en interfaz de usuario de creación de ADF ->Receptor de actividad de copia ->Opción Tabla ->Crear tabla automáticamente, o mediante la propiedad tableOption en la carga de trabajo del receptor de actividad de copia.
Tolerancia a errores
De forma predeterminada, la actividad de copia detiene la copia de datos y devuelve un error cuando las filas de datos de origen no son compatibles con las filas de datos del receptor. Para que la copia se realice correctamente, puede configurar la actividad de copia para omitir y registrar las filas incompatibles y copiar solo los datos compatibles. Para más información, consulte Tolerancia a errores de la actividad de copia en Azure Data Factory.
Comprobación de la coherencia de los datos
Al mover datos de origen a almacén de destino, la actividad de copia proporciona una opción para que realice una comprobación adicional de la coherencia de datos para asegurarse de que los datos no solo se copian correctamente del almacén de origen al de destino, sino que también se comprueba que son coherentes entre el almacén de origen y de destino. Si se encuentran archivos incoherentes durante el movimiento de datos, puede anular la actividad de copia o habilitar la opción de configuración de tolerancia a errores para seguir copiando el resto y omitir los archivos incoherentes. Para obtener los nombres de los archivos omitidos, habilite la configuración del registro de sesión en la actividad de copia. Consulte Comprobación de la coherencia de los datos en la actividad de copia para más información.
Registro de la sesión
Puede registrar los nombres de archivo copiados, lo que puede ayudarle a asegurarse de que los datos no solo se copian correctamente del almacén de origen al de destino, sino que también son coherentes entre el almacén de origen y de destino revisando los registros de sesión de la actividad de copia. Consulte Actividad de copia de inicios de sesión para más información.
Contenido relacionado
Consulte las guías de inicio rápido, los tutoriales y los ejemplos siguientes: