Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Un escenario común en Data Factory al usar flujos de datos de mapeo consiste en escribir los datos transformados en una base de datos de Azure SQL Database. En este escenario, una condición de error común que se debe evitar es un posible truncamiento de columna.
Hay dos métodos principales para controlar correctamente los errores cuando se escriben datos en el receptor de la base de datos en flujos de datos de ADF:
- Establezca el control de filas de errores del receptor en "Continuar con el error" al procesar los datos de la base de datos. Se trata de un método catch-all automatizado que no requiere una lógica personalizada en el flujo de datos.
- Como alternativa, realice los siguientes pasos para proporcionar el registro de columnas que no quepan en una columna de cadena de destino, lo que permite que el flujo de datos continúe.
Nota:
Al habilitar el control de filas de errores automático, en contraposición al método siguiente de escribir su propia lógica de control de errores, se producirá una pequeña reducción del rendimiento provocado por un paso adicional realizado por la factoría de datos para llevar a cabo una operación de dos fases para interceptar los errores.
Escenario
Tenemos una tabla de base de datos de destino que tiene una columna
nvarchar(5)denominada "Name" (Nombre).Dentro de nuestro flujo de datos, queremos asignar títulos de películas de nuestro receptor a esa columna de "Name" de destino.

El problema es que el título de la película no cabe en una columna de receptor que solo pueda contener cinco caracteres. Al ejecutar este flujo de datos, recibirá un error similar al siguiente:
"Job failed due to reason: DF-SYS-01 at Sink 'WriteToDatabase': java.sql.BatchUpdateException: String or binary data would be truncated. java.sql.BatchUpdateException: String or binary data would be truncated."
Este vídeo le guía a través de un ejemplo de configuración de la lógica de control de filas de errores en el flujo de datos:
Cómo diseñar en torno a esta condición
En este escenario, la longitud máxima de la columna "Name" es de cinco caracteres. Por lo tanto, vamos a agregar una transformación de división condicional que nos permita registrar filas con "títulos" con más de cinco caracteres, al tiempo que permite que el resto de las filas que caben en ese espacio escriban en la base de datos.
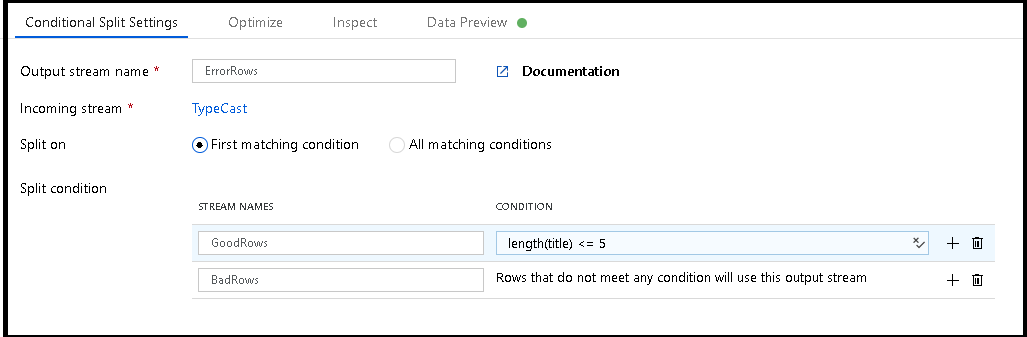
Esta transformación de división condicional define la longitud máxima de "title" (título) como cinco. Cualquier fila que sea menor o igual que cinco va al flujo
GoodRows. Cualquier fila que sea mayor a cinco va al flujoBadRows.Ahora es necesario registrar las filas en las que se produjo un error. Agregue una transformación de receptor al flujo
BadRowspara el registro. Aquí hacemos un mapeo automático de todos los campos para que tengamos el registro completo de la transacción. Se trata de un archivo CSV delimitado por texto que se envía a un solo archivo en Blob Storage. Llamamos al archivo de registro "badrows.csv".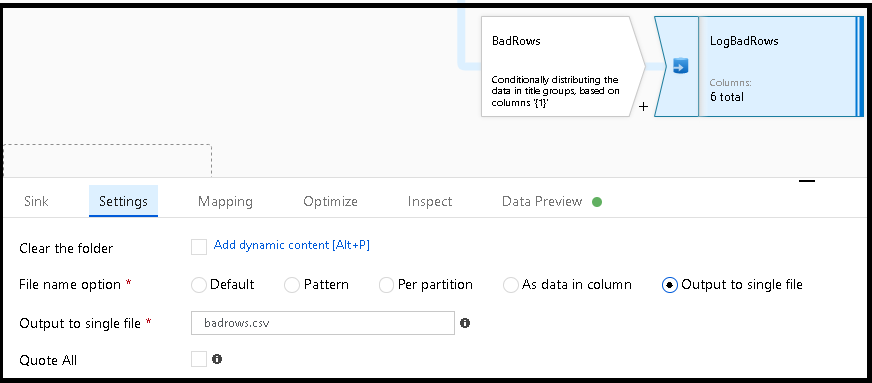
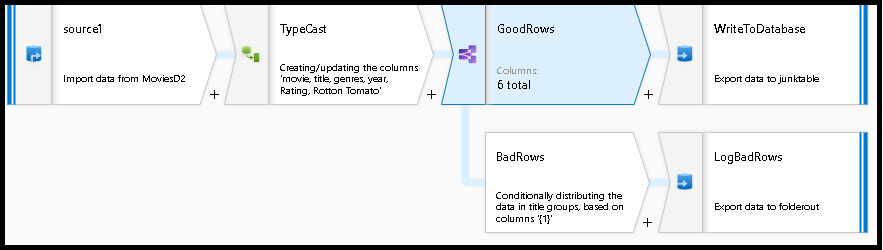
Aquí se muestra el flujo de datos completado. Ahora podemos dividir las filas de error para evitar los errores de truncamiento de SQL y colocar dichas entradas en un archivo de registro. Mientras tanto, las filas correctas pueden continuar escribiendo en nuestra base de datos de destino.
Si elige la opción de control de filas de errores en la transformación del receptor y establece "Filas de errores de salida", Azure Data Factory genera automáticamente una salida de archivo CSV de los datos de la fila junto con los mensajes de error notificados por el controlador. No es necesario agregar esa lógica manualmente al flujo de datos con esa opción alternativa. Se produce una pequeña reducción del rendimiento con esta opción para que ADF pueda implementar una metodología de dos fases para interceptar los errores y registrarlos.

Contenido relacionado
- Compile el resto de la lógica del flujo de datos mediante transformaciones de flujos de datos de asignación.