Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La actividad de Spark en canalizaciones de Data Factory y Synapse ejecuta un programa de Spark en su propio clúster de HDInsight o a petición. Este artículo se basa en el artículo sobre actividades de transformación de datos , que presenta información general de la transformación de datos y las actividades de transformación admitidas. Cuando usas un servicio vinculado a Spark bajo demanda, el servicio crea automáticamente un clúster justo a tiempo para procesar los datos y luego lo elimina una vez finalizado el procesamiento.
Añade una actividad de Spark a un flujo de trabajo utilizando la interfaz de usuario.
Para usar una actividad de Spark en una canalización, complete los pasos siguientes:
Busque Spark en el panel Actividades de canalización y arrastre una actividad de Spark al lienzo de canalización.
Seleccione la nueva actividad de Spark en el lienzo si aún no lo ha hecho.
Seleccione la pestaña HDI Cluster (Clúster de HDI) para elegir o crear un servicio vinculado a un clúster de HDInsight que se usará para ejecutar la actividad de Spark.
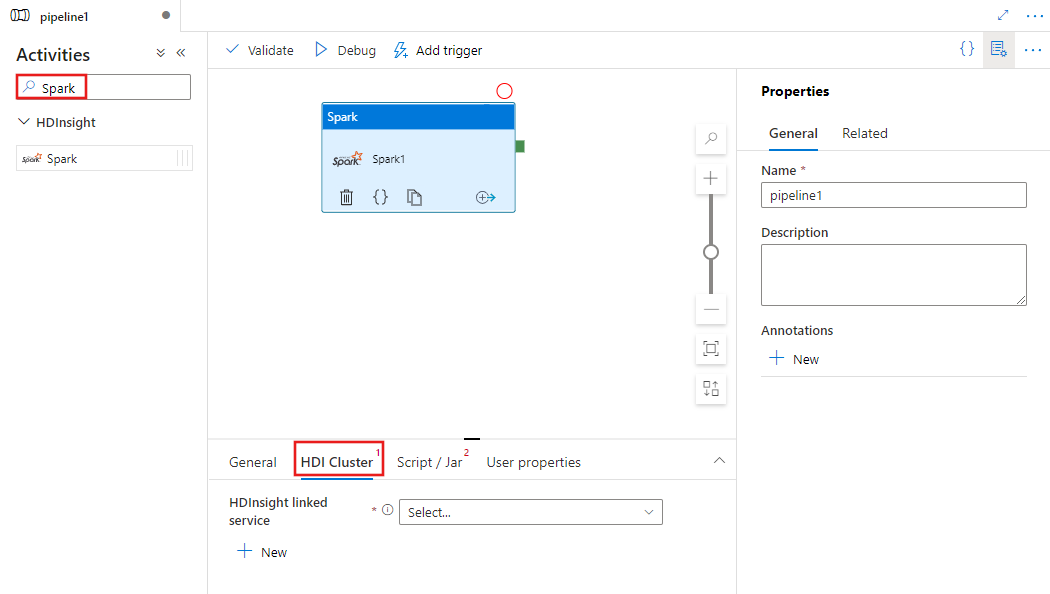
Seleccione la pestaña Script/ Jar para seleccionar o crear un nuevo servicio vinculado de trabajo en una cuenta de Azure Storage que hospedará el script. Especifique una ruta de acceso al archivo que se va a ejecutar allí. También puede configurar detalles avanzados, como un usuario de proxy, la configuración de depuración y los argumentos y parámetros de configuración de Spark que se pasarán al script.
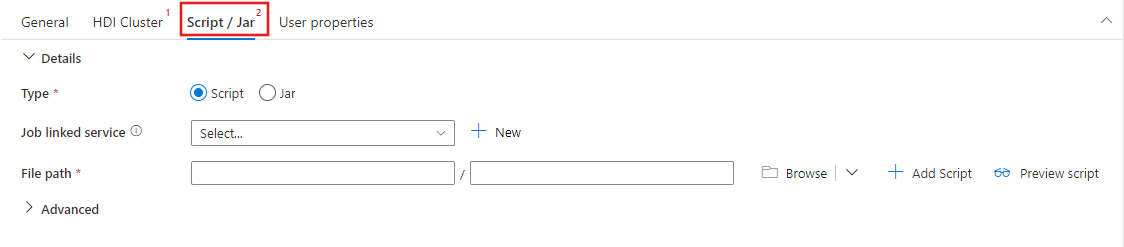
Propiedades de la actividad de Spark
Esta es la definición de JSON de ejemplo de una actividad de Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
En la siguiente tabla se describen las propiedades JSON que se usan en la definición de JSON:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| nombre | Nombre de la actividad en la canalización. | Sí |
| descripción | Texto que describe para qué se usa la actividad. | No |
| tipo | Para la Spark Activity, el tipo de actividad es HDInsightSpark. | Sí |
| nombreDelServicioVinculado | Nombre del servicio vinculado de HDInsight Spark en el que se ejecuta el programa de Spark. Para obtener más información sobre este servicio vinculado, consulte el artículo Compute linked services (Servicios vinculados de cálculo). | Sí |
| SparkJobLinkedService | El servicio vinculado de Azure Storage que contiene el archivo de trabajo de Spark, las dependencias y los registros. Aquí solo se admiten los servicios vinculados Azure Blob Storage y ADLS Gen2. Si no especifica un valor para esta propiedad, se usa el almacenamiento asociado con el clúster de HDInsight. El valor de esta propiedad solo puede ser un servicio vinculado de Azure Storage. | No |
| ruta raíz | El contenedor de Blobs de Azure y la carpeta que contiene el archivo Spark. El nombre del archivo distingue mayúsculas de minúsculas. Vea la sección sobre la estructura de carpetas (sección siguiente) para obtener más información sobre la estructura de esta carpeta. | Sí |
| entryFilePath | Ruta de acceso relativa a la carpeta raíz del código o el paquete de Spark. El archivo de entrada debe ser un archivo Python o un archivo .jar. | Sí |
| className | Clase principal Java/Spark de la aplicación | No |
| argumentos | Lista de argumentos de línea de comandos del programa de Spark. | No |
| proxyUser | La cuenta de usuario a suplantar para ejecutar el programa de Spark. | No |
| sparkConfig | Especifique valores para las propiedades de configuración de Spark indicadas en el tema: Spark Configuration - Application properties (Configuración de Spark: Propiedades de aplicación). | No |
| getDebugInfo | Especifica cuándo se copian los archivos de registro de Spark en el almacenamiento de Azure usado por el clúster de HDInsight (o) especificado por sparkJobLinkedService. Valores permitidos: Ninguno, Siempre o Error. Valor predeterminado: Ninguno. | No |
Estructura de carpetas
Los trabajos de Spark son más extensibles que los de Pig y Hive. En el caso de los trabajos de Spark, puede proporcionar varias dependencias, como paquetes jar (colocados en Java CLASSPATH), Python archivos (colocados en PYTHONPATH) y cualquier otro archivo.
Cree la siguiente estructura de carpetas en el Azure Blob Storage al que hace referencia el servicio vinculado de HDInsight. Luego, cargue los archivos dependientes en las subcarpetas adecuadas de la carpeta raíz que representa entryFilePath. Por ejemplo, cargue archivos Python en la subcarpeta pyFiles y los archivos jar en la subcarpeta jars de la carpeta raíz. En tiempo de ejecución, el servicio espera la siguiente estructura de carpetas en el Azure Blob Storage:
| Ruta | Descripción | Obligatorio | Tipo |
|---|---|---|---|
. (raíz) |
Ruta raíz del trabajo de Spark en el servicio enlazado de almacenamiento. | Sí | Carpeta |
| <Definida por el usuario> | Ruta de acceso que apunta al archivo de entrada del trabajo de Spark. | Sí | Archivo |
| ./jars | Todos los archivos de esta carpeta se cargan y colocan en la ruta de clases Java del clúster. | No | Carpeta |
| ./pyFiles | Todos los archivos de esta carpeta se cargan y se colocan en el PYTHONPATH del clúster. | No | Carpeta |
| ./files | Todos los archivos de esta carpeta se cargan y se colocan en el directorio de trabajo del ejecutor. | No | Carpeta |
| ./archives | Todos los archivos de esta carpeta están sin comprimir. | No | Carpeta |
| ./logs | Carpeta que contiene los registros del clúster de Spark. | No | Carpeta |
Este es un ejemplo de un almacenamiento que contiene dos archivos de trabajo de Spark en el Azure Blob Storage al que hace referencia el servicio vinculado de HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Contenido relacionado
Vea los siguientes artículos, en los que se explica cómo transformar datos de otras maneras: