Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Important
Esta característica se encuentra en su versión beta. Los administradores de cuentas pueden controlar el acceso a esta característica desde la página Vistas previas .
En esta página se describe cómo supervisar el uso de puntos de conexión de AI Gateway (Beta) mediante la tabla del sistema de seguimiento de uso.
La tabla de seguimiento de uso captura automáticamente los detalles de solicitud y respuesta de un punto de conexión, registrando métricas esenciales, como el uso de tokens y la latencia. Puede usar los datos de esta tabla para supervisar el uso, realizar un seguimiento de los costos y obtener información sobre el rendimiento y el consumo del punto de conexión.
Requisitos
- Versión preliminar de AI Gateway (beta) habilitada para su cuenta.
- Un área de trabajo de Azure Databricks en una región compatible con AI Gateway (beta).
- Unity Catalog habilitado para su área de trabajo. Consulte Habilitar un área de trabajo para Unity Catalog.
Consultar la tabla de uso
AI Gateway registra los datos de uso en la tabla del sistema system.ai_gateway.usage. Puede ver la tabla en la interfaz de usuario o consultar la tabla desde Databricks SQL o un cuaderno.
Nota:
Solo los administradores de cuentas tienen permiso para ver o consultar la system.ai_gateway.usage tabla.
Para ver la tabla en la interfaz de usuario, haga clic en el enlace de la tabla de seguimiento del uso en la página del endpoint para abrir la tabla en el Explorador de Catálogos.
Para consultar la tabla desde Databricks SQL o un cuaderno:
SELECT * FROM system.ai_gateway.usage;
Panel de uso integrado
Importar panel de uso integrado
Los administradores de cuentas pueden importar un panel de uso integrado de AI Gateway haciendo clic en Crear panel en la página de AI Gateway para supervisar el uso, realizar un seguimiento de los costos y obtener información sobre el rendimiento y el consumo de los puntos de conexión. El panel se publica con los permisos del administrador de la cuenta, lo que permite a los visores ejecutar consultas mediante los permisos del publicador. Consulte Publicar un panel para obtener más detalles. Los administradores de cuentas también pueden actualizar el almacenamiento que se usa para ejecutar consultas de panel, que se aplican a todas las consultas posteriores.

Nota:
La importación del panel está restringida a los administradores de cuentas porque requiere SELECT permisos en la system.ai_gateway.usage tabla. Los datos del panel están sujetos a las directivas de retención de la usage tabla. Vea ¿Qué tablas del sistema están disponibles?.
Para volver a cargar el panel desde la plantilla más reciente, los administradores de cuentas pueden hacer clic en Volver a importar panel en la página puerta de enlace de AI. Esto actualiza el panel con las nuevas visualizaciones o mejoras de la plantilla al tiempo que conserva la configuración del almacenamiento.
Visualización del panel de uso
Para ver el tablero, haga clic en Ver tablero en la página del AI Gateway. El panel integrado proporciona visibilidad completa del uso y el rendimiento de los puntos de conexión de AI Gateway. Incluye varias solicitudes de seguimiento de páginas, consumo de tokens, métricas de latencia, tasas de error y actividad del agente de codificación.

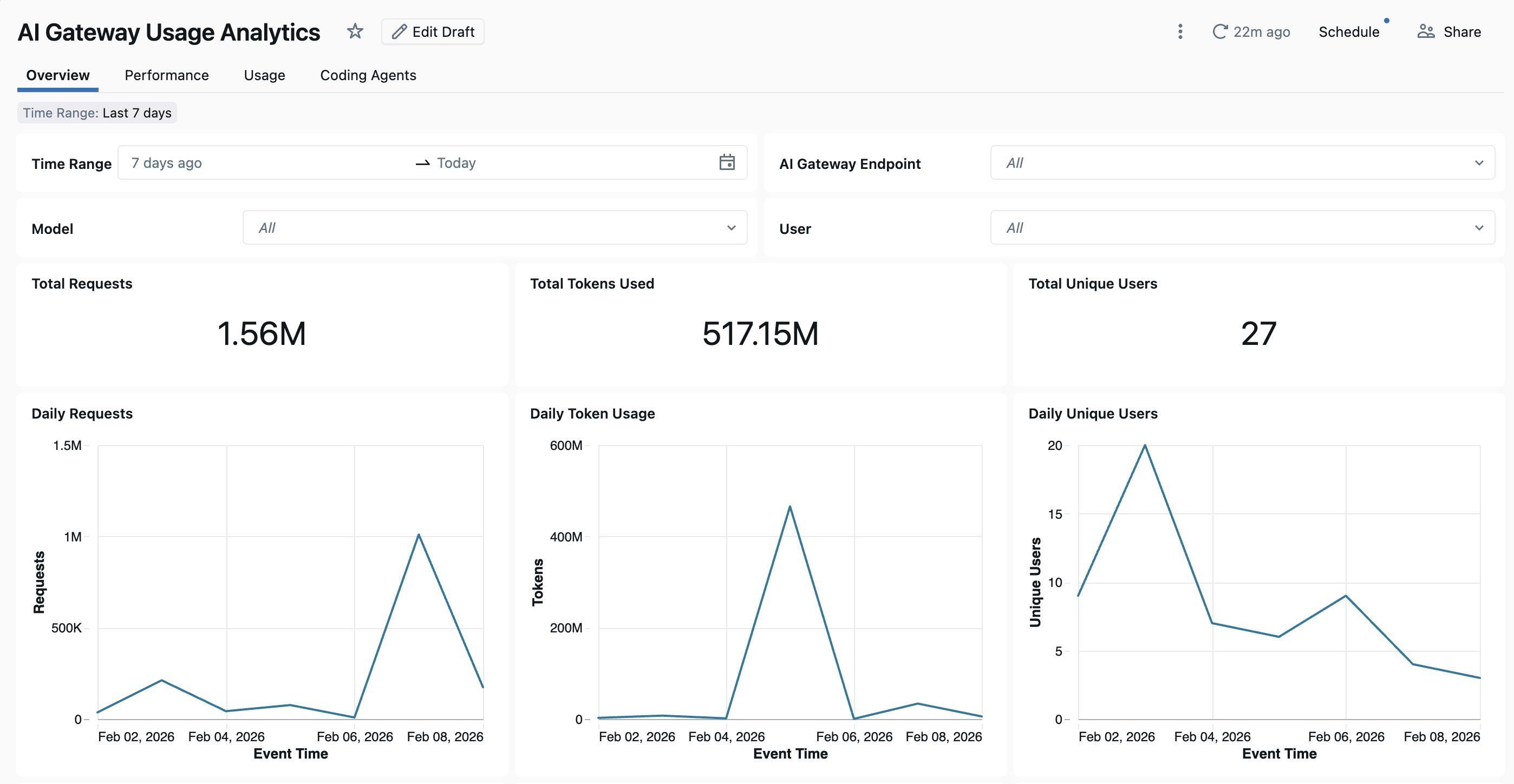
El panel proporciona análisis entre áreas de trabajo de forma predeterminada. Todas las páginas del panel se pueden filtrar por intervalo de fechas e identificador de área de trabajo.
- Pestaña Información general: muestra métricas de uso de alto nivel, como el volumen diario de solicitudes, las tendencias de uso de tokens a lo largo del tiempo, los principales usuarios por consumo de tokens y el total de recuentos de usuarios únicos. Use esta pestaña para obtener una instantánea rápida de la actividad general de AI Gateway e identificar los usuarios y modelos más activos.
- Pestaña Rendimiento: realiza un seguimiento de las métricas clave de rendimiento, incluidos los percentiles de latencia (P50, P90, P95, P99), el tiempo hasta el primer byte, las tasas de error y las distribuciones de código de estado HTTP. Utiliza esta pestaña para supervisar la salud del endpoint e identificar cuellos de botella de rendimiento o problemas de fiabilidad.
- Pestaña Uso: muestra desgloses detallados del consumo por punto de conexión, área de trabajo y solicitante. En esta pestaña se muestran los patrones de uso de tokens, las distribuciones de solicitudes y las relaciones de aciertos de caché para ayudar a analizar y optimizar los costos.
- Pestaña Agentes de codificación: supervisa la actividad de los agentes de codificación integrados, como Cursor, Claude Code, Gemini CLI y Codex CLI. En esta pestaña se muestran métricas como días activos, sesiones de codificación, confirmaciones y líneas de código agregadas o eliminadas para supervisar el uso de las herramientas para desarrolladores. Consulte El panel del agente de codificación para obtener más detalles.
Esquema de tabla de uso
La system.ai_gateway.usage tabla tiene el esquema siguiente:
| Nombre de la columna | Tipo | Description | Example |
|---|---|---|---|
account_id |
STRING | El identificador de cuenta. | 11d77e21-5e05-4196-af72-423257f74974 |
workspace_id |
STRING | El identificador del área de trabajo. | 1653573648247579 |
request_id |
STRING | Identificador único de la solicitud. | b4a47a30-0e18-4ae3-9a7f-29bcb07e0f00 |
schema_version |
INTEGER | Versión del esquema del registro de uso. | 1 |
endpoint_id |
STRING | Identificador único del punto de conexión de AI Gateway. | 43addf89-d802-3ca2-bd54-fe4d2a60d58a |
endpoint_name |
STRING | Nombre del punto de conexión de AI Gateway. | databricks-gpt-5-2 |
endpoint_tags |
MAP | Etiquetas asociadas al punto de conexión. | {"team": "engineering"} |
endpoint_metadata |
ESTRUCTURA | Metadatos del punto de conexión, incluidos creator, creation_timelast_updated_time, destinations, , inference_tabley fallbacks. |
{"creator": "user.name@email.com", "creation_time": "2026-01-06T12:00:00.000Z", ...} |
event_time |
TIMESTAMP | Marca de tiempo cuando se recibió la solicitud. | 2026-01-20T19:48:08.000+00:00 |
latency_ms |
LONG | Latencia total en milisegundos. | 300 |
time_to_first_byte_ms |
LONG | El tiempo de primer byte en milisegundos. | 300 |
destination_type |
STRING | Tipo de destino (por ejemplo, modelo externo o modelo de base). | PAY_PER_TOKEN_FOUNDATION_MODEL |
destination_name |
STRING | Nombre del modelo o proveedor de destino. | databricks-gpt-5-2 |
destination_id |
STRING | Identificador único del destino. | 507e7456151b3cc89e05ff48161efb87 |
destination_model |
STRING | Modelo específico que se usa para la solicitud. | GPT-5.2 |
requester |
STRING | Identificador del usuario o la entidad de servicio que realizó la solicitud. | user.name@email.com |
requester_type |
STRING | Tipo de solicitante (usuario, entidad de servicio o grupo de usuarios). | USER |
ip_address |
STRING | Dirección IP del solicitante. | 1.2.3.4 |
url |
STRING | Dirección URL de la solicitud. | https://<ai-gateway-url>/mlflow/v1/chat/completions |
user_agent |
STRING | Agente de usuario del solicitante. | OpenAI/Python 2.13.0 |
api_type |
STRING | Tipo de llamada API (por ejemplo, chat, finalizaciones o incrustaciones). | mlflow/v1/chat/completions |
request_tags |
MAP | Etiquetas asociadas a la solicitud. | {"team": "engineering"} |
input_tokens |
LONG | Número de tokens de entrada. | 100 |
output_tokens |
LONG | Número de tokens de salida. | 100 |
total_tokens |
LONG | Número total de tokens (entrada y salida). | 200 |
token_details |
ESTRUCTURA | Desglose detallado del token, incluidos cache_read_input_tokens, cache_creation_input_tokensy output_reasoning_tokens. |
{"cache_read_input_tokens": 100, ...} |
response_content_type |
STRING | Tipo de contenido de la respuesta. | application/json |
status_code |
INT | Código de estado HTTP de la respuesta. | 200 |
routing_information |
ESTRUCTURA | Detalles de enrutamiento de los intentos de contingencia. Contiene una attempts matriz con priority, , actiondestinationdestination_idstatus_codeerror_codelatency_ms, , , start_timey end_time para cada modelo probado durante la solicitud. |
{"attempts": [{"priority": "1", ...}]} |