Integración y entrega continuas en Azure Databricks con Azure DevOps
Nota:
En este artículo se describe Azure DevOps, que no se proporciona ni es compatible con Databricks. Para ponerse en contacto con el proveedor, consulte Soporte técnico de Azure DevOps Services.
Este artículo le guiará a través de la configuración de la automatización de Azure DevOps para el código y los artefactos que funcionan con Azure Databricks. En concreto, configurará un flujo de trabajo de integración continua y entrega continua (CI/CD) para conectarse a un repositorio de Git, ejecutar trabajos mediante Azure Pipelines para compilar y realizar pruebas unitarias de una rueda de Python (*.whl) e implementarla para su uso en cuadernos de Databricks.
Flujo de trabajo de desarrollo CI/CD
Databricks sugiere el siguiente flujo de trabajo para el desarrollo de CI/CD con Azure DevOps:
- Cree un repositorio o use un repositorio existente con el proveedor de Git de terceros.
- Conecte la máquina de desarrollo local al mismo repositorio de terceros. Para obtener instrucciones, consulte la documentación del proveedor de Git de terceros.
- Extraiga los artefactos actualizados existentes (como cuadernos, archivos de código y scripts de compilación) al equipo de desarrollo local desde el repositorio de terceros.
- Según sea necesario, cree, actualice y pruebe artefactos en la máquina de desarrollo local. A continuación, envíe cualquier artefacto nuevo o modificado desde su máquina de desarrollo local al repositorio de terceros. Para obtener instrucciones, consulte la documentación del proveedor de Git de terceros.
- Repita los pasos 3 y 4 según sea necesario.
- Use Azure DevOps periódicamente como enfoque integrado para extraer automáticamente artefactos del repositorio de terceros, compilar, probar y ejecutar código en el área de trabajo de Azure Databricks; y generar informes y ejecutar resultados. Aunque se puede ejecutar Azure DevOps manualmente, en el mundo real se le indicaría al proveedor de Git que ejecute Azure DevOps cada vez que ocurra un evento específico, como una solicitud de PR de un repositorio.
Hay numerosas herramientas de CI/CD que puede usar para administrar y ejecutar la canalización. En este artículo se muestra cómo usar Azure DevOps. CI/CD es un patrón de diseño, por lo que los pasos y las fases descritos en el ejemplo de este artículo deberían transferirse con algunos cambios al lenguaje de definición de la canalización en cada herramienta. Además, gran parte del código de esta canalización de ejemplo es código de Python estándar que se puede invocar en otras herramientas.
Sugerencia
Para más información sobre el uso de Jenkins con Azure Databricks en lugar de Azure DevOps, consulte CI/CD con Jenkins en Azure Databricks.
En el resto de este artículo se describe un par de canalizaciones de ejemplo en Azure DevOps que puede adaptar a sus propias necesidades en Azure Databricks.
Acerca del ejemplo
En el ejemplo de este artículo, se usan dos canalizaciones para recopilar, implementar y ejecutar ejemplos de código de Python y cuadernos de Python almacenados en un repositorio de Git remoto.
La primera canalización, conocida como canalización de compilación, prepara los artefactos de compilación para la segunda canalización, conocida como canalización de versión. La separación de la canalización de compilación de la canalización de versión le permite crear un artefacto de compilación sin implementarlo ni implementar artefactos simultáneamente desde varias compilaciones. Para construir las canalizaciones de versión y compilación:
- Cree una máquina virtual de Azure para la canalización de compilación.
- Copie los archivos del repositorio de Git en la máquina virtual.
- Cree un archivo tar comprimido mediante gzip que contenga el código de Python, los cuadernos de Python y los archivos de compilación e implementación, así como los parámetros de ejecución relacionados.
- Copie el archivo .tar comprimido con gzip como un archivo ZIP en una ubicación para su acceso por la canalización de versión.
- Cree otra máquina virtual de Azure para la canalización de versión.
- Obtenga el archivo ZIP de la ubicación de la canalización de compilación y, a continuación, desempaquete el archivo ZIP para obtener el código de Python, los cuadernos de Python y los archivos de compilación, implementación y parámetros de ejecución relacionados.
- Implemente el código de Python, los cuadernos de Python y los archivos de compilación, implementación y parámetros de configuración relacionados en el área de trabajo remota de Azure Databricks.
- Compile los archivos de código del componente de la biblioteca wheel de Python en un archivo wheel de Python.
- Ejecute pruebas unitarias en el código de componente para comprobar la lógica en el archivo wheel de Python.
- Ejecute los cuadernos de Python, uno de los cuales llama a la funcionalidad del archivo wheel de Python.
Acerca de la CLI de Databricks
En este ejemplo de este artículo se muestra cómo usar la CLI de Databricks en un modo no interactivo dentro de una canalización. En este artículo, la canalización de ejemplo implementa código, compila una biblioteca y ejecuta cuadernos en el área de trabajo de Azure Databricks.
Si usa la CLI de Databricks en la canalización sin implementar el código de ejemplo, la biblioteca y los cuadernos de este artículo, siga estos pasos:
Prepare el área de trabajo de Azure Databricks para usar la autenticación de máquina a máquina (M2M) de OAuth para autenticar una entidad de servicio. Antes de empezar, confirme que tiene una entidad de servicio de Microsoft Entra ID (anteriormente Azure Active Directory) con un secreto de OAuth de Azure Databricks. Consulte autenticación de máquina a máquina (M2M) de OAuth.
Instale la CLI de Databricks en la canalización. Para ello, agregue una tarea Script de Bash a la canalización que ejecute el siguiente script:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shPara agregar una tarea de Script de Bash a la canalización, vea Paso 3.6. Instale la CLI de Databricks y las herramientas de compilación del paquete wheel de Python.
Configure la canalización para habilitar la CLI de Databricks instalada para autenticar la entidad de servicio con el área de trabajo. Para ello, vea Paso 3.1: Definir variables de entorno para la canalización de versión.
Agregue más Script de Bash tareas a la canalización según sea necesario para ejecutar los comandos de la CLI de Databricks. Vea comandos de la CLI de Databricks.
Antes de empezar
Para usar el ejemplo de este artículo, debe tener:
- Un proyecto de Azure DevOps existente. Si aún no tiene un proyecto, cree un proyecto en Azure DevOps.
- Un repositorio existente con un proveedor de Git compatible con Azure DevOps. Agregará a este repositorio el código de ejemplo de Python, el cuaderno de Python de ejemplo y los archivos de configuración de versión relacionados. Si aún no tiene un repositorio, cree uno siguiendo las instrucciones del proveedor de Git. A continuación, conecte el proyecto de Azure DevOps a este repositorio si aún no lo ha hecho. Para obtener instrucciones, siga los vínculos de Repositorios de origen admitidos.
- El ejemplo de este artículo utiliza la autenticación de máquina a máquina (M2M) de OAuth para autenticar una entidad de servicio de Microsoft Entra ID (anteriormente Azure Active Directory) en un área de trabajo de Azure Databricks. Debe tener una entidad de servicio de Microsoft Entra ID con un secreto de OAuth de Azure Databricks para esa entidad de servicio. Consulte autenticación de máquina a máquina (M2M) de OAuth.
Paso 1: Agregar los archivos del ejemplo al repositorio
En este paso, en el repositorio con el proveedor de Git de terceros, agregará todos los archivos de ejemplo de este artículo que las canalizaciones de Azure DevOps compilan, implementan y ejecutan en el área de trabajo remota de Azure Databricks.
Paso 1.1: Agregar los archivos de componentes de paquete wheel de Python
En el ejemplo de este artículo, las canalizaciones de Azure DevOps compilan y hacen una prueba unitaria de un archivo wheel de Python. A continuación, un cuaderno de Azure Databricks llama a la funcionalidad del archivo wheel de Python compilado.
Para definir la lógica y las pruebas unitarias para el archivo wheel de Python contra el que se ejecutan los cuadernos, en la raíz del repositorio, cree dos archivos denominados addcol.py y test_addcol.py, y agréguelos a una estructura de carpetas denominada python/dabdemo/dabdemo en una carpeta Libraries, como se muestra a continuación:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
El archivo addcol.py contiene una función de biblioteca que se integra más adelante en un archivo wheel de Python y luego se instala en clústeres de Azure Databricks. Es una función sencilla que agrega una nueva columna, rellenada por un literal, a un DataFrame de Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
El archivo test_addcol.py contiene pruebas para pasar un objeto DataFrame ficticio a la función with_status, definida en addcol.py. A continuación, el resultado se compara con un objeto DataFrame que contiene los valores esperados. Si los valores coinciden, se supera la prueba:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Para permitir que la CLI de Databricks empaquete correctamente este código de biblioteca en un archivo de wheel de Python, cree dos archivos denominados __init__.py y __main__.py en la misma carpeta que los dos archivos anteriores. Además, cree un archivo denominado setup.py en la carpeta python/dabdemo, como se muestra a continuación:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
El archivo __init__.py contiene el número de versión y el autor de la biblioteca. Reemplace <my-author-name> por su nombre:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
El archivo __main__.py contiene el punto de entrada de la biblioteca:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
El archivo setup.py contiene configuraciones adicionales para compilar la biblioteca en un archivo wheel de Python. Reemplace <my-url>, <my-author-name>@<my-organization> y <my-package-description> por valores válidos:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Paso 1.2: Agregar un cuaderno de prueba unitaria para el archivo wheel de Python
Más adelante, la CLI de Databricks ejecuta un trabajo de cuaderno. Este trabajo ejecuta un cuaderno de Python con el nombre de archivo de run_unit_tests.py. Este cuaderno ejecuta pytest en la lógica de la biblioteca de paquete wheel de Python.
Para ejecutar las pruebas unitarias del ejemplo de este artículo, agregue a la raíz del repositorio un archivo de cuaderno denominado run_unit_tests.py con el siguiente contenido:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Paso 1.3: Agregar un cuaderno que llame al archivo wheel de Python
Más adelante, la CLI de Databricks ejecuta otro trabajo de cuaderno. Este cuaderno crea un objeto DataFrame, lo pasa a la función with_status de la biblioteca de paquete wheel, imprime el resultado e informa de los resultados de ejecución del trabajo. Cree la raíz del repositorio un archivo de cuaderno denominado dabdemo_notebook.py con el siguiente contenido:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Paso 1.4: Crear la configuración en conjunto
En este artículo se usan los Conjuntos de recursos de Databricks para definir la configuración y los comportamientos para compilar, implementar y ejecutar los archivos wheel de Python, los dos cuadernos y el archivo de código de Python. Los conjuntos de recursos de Databricks, conocidos simplemente como conjuntos de , permiten expresar datos completos, análisis y ML como una colección de archivos de origen. Consulte ¿Qué son las agrupaciones de recursos de Databricks?
Para configurar la agrupación para el ejemplo de este artículo, cree en la raíz del repositorio un archivo denominado databricks.yml. En este ejemplo del archivo databricks.yml, reemplace los siguientes marcadores de posición:
- Reemplace
<bundle-name>por un nombre de programación único para la agrupación. Por ejemplo,azure-devops-demo. - Reemplace
<job-prefix-name>con alguna cadena para ayudar a identificar de forma única los trabajos que se crean en el área de trabajo de Azure Databricks para este ejemplo. Por ejemplo,azure-devops-demo. - Reemplace
<spark-version-id>por el id. de versión de Databricks Runtime para los clústeres de trabajos, por ejemplo13.3.x-scala2.12. - Reemplace
<cluster-node-type-id>con el id. del tipo de nodo de clúster para sus clústeres de trabajo, por ejemploStandard_DS3_v2. - Tenga en cuenta que
deven la asignación detargetsespecifica el host y los comportamientos de implementación relacionados. En las implementaciones del mundo real, puede asignar a este destino un nombre diferente en sus propias agrupaciones.
Este es el contenido del archivo databricks.yml de este ejemplo:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Para obtener más información sobre la sintaxis del archivo databricks.yml, vea configuraciones de Asset Bundle de Databricks.
Paso 2: Definir la canalización de compilación
Azure DevOps proporciona una interfaz de usuario hospedada en la nube para definir las etapas de su canalización de CI/CD utilizando YAML. Para más información sobre Azure DevOps y las canalizaciones, consulte Documentación de Azure DevOps.
En este paso, usará el marcado YAML para definir la canalización de compilación, que compila un artefacto de implementación. Para implementar el código en un área de trabajo de Azure Databricks, especifique el artefacto de compilación de esta canalización como entrada en una canalización de versión. Esta canalización de versión se definirá más adelante.
Para ejecutar canalizaciones de compilación, Azure DevOps proporciona agentes de ejecución a petición hospedados en la nube que admiten implementaciones en Kubernetes, máquinas virtuales, Azure Functions, Azure Web Apps y muchos más destinos. En este ejemplo, se usa un agente a petición para automatizar la creación del artefacto de implementación.
Defina la canalización de compilación de ejemplo de este artículo de la siguiente manera:
Inicie sesión en Azure DevOps y, a continuación, haga clic en el vínculo Inicio de sesión para abrir el proyecto de Azure DevOps.
Nota:
Si Azure Portal se muestra en lugar del proyecto de Azure DevOps, haga clic en Más servicios > Organizaciones de Azure DevOps > Mis organizaciones de Azure DevOps y, a continuación, abra el proyecto de Azure DevOps.
Haga clic en Pipelines en la barra lateral y, luego, haga clic en Pipelines en el menú Pipelines.
Haga clic en el botón Nueva canalización y siga las instrucciones en pantalla. (Si ya tiene canalizaciones, haga clic en Crear canalización en su lugar). Al final de estas instrucciones, se abre el editor de canalización. Aquí se define el script de canalización de compilación en el archivo
azure-pipelines.ymlque aparece. Si el editor de canalización no está visible al final de las instrucciones, seleccione el nombre de la canalización de compilación y, a continuación, haga clic en Editar.Puede usar el selector de ramas de Git
 para personalizar el proceso de compilación para cada rama de su repositorio Git. Se trata de un procedimiento recomendado de CI/CD para no realizar el trabajo de producción directamente en la rama
para personalizar el proceso de compilación para cada rama de su repositorio Git. Se trata de un procedimiento recomendado de CI/CD para no realizar el trabajo de producción directamente en la rama maindel repositorio. En este ejemplo se supone que existe una rama denominadareleaseen el repositorio que se va a usar en lugar demain.
El script de canalización de compilación
azure-pipelines.ymlse almacena de forma predeterminada en la raíz del repositorio de Git remoto asociado a la canalización.Sobrescriba el contenido de entrada del archivo
azure-pipelines.ymlde la canalización con la siguiente definición y, luego, haga clic en Save.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Paso 3: Definir la canalización de versión
La canalización de versión implementa los artefactos de compilación de la canalización de compilación en un entorno de Azure Databricks. Separar la canalización de versión de este paso de la canalización de compilación de los pasos anteriores permite crear una compilación sin implementarla o implementar artefactos de varias compilaciones simultáneamente.
En el proyecto de Azure DevOps, en el menú Pipelines de la barra lateral, haga clic en Releases.
Haga clic en Nueva > Nueva canalización de versión. (Si ya tiene canalizaciones, haga clic en Nueva canalización en su lugar).
En el lado derecho de la pantalla hay una lista de plantillas destacadas para patrones de implementación comunes. Para esta canalización de versión de ejemplo, haga clic en
 .
.
En el cuadro Artefactos del lado de la pantalla, haga clic en
 . En el panel Add an artifact, en Source (build pipeline), seleccione la canalización de compilación que creó anteriormente. A continuación, haga clic en Agregar.
. En el panel Add an artifact, en Source (build pipeline), seleccione la canalización de compilación que creó anteriormente. A continuación, haga clic en Agregar.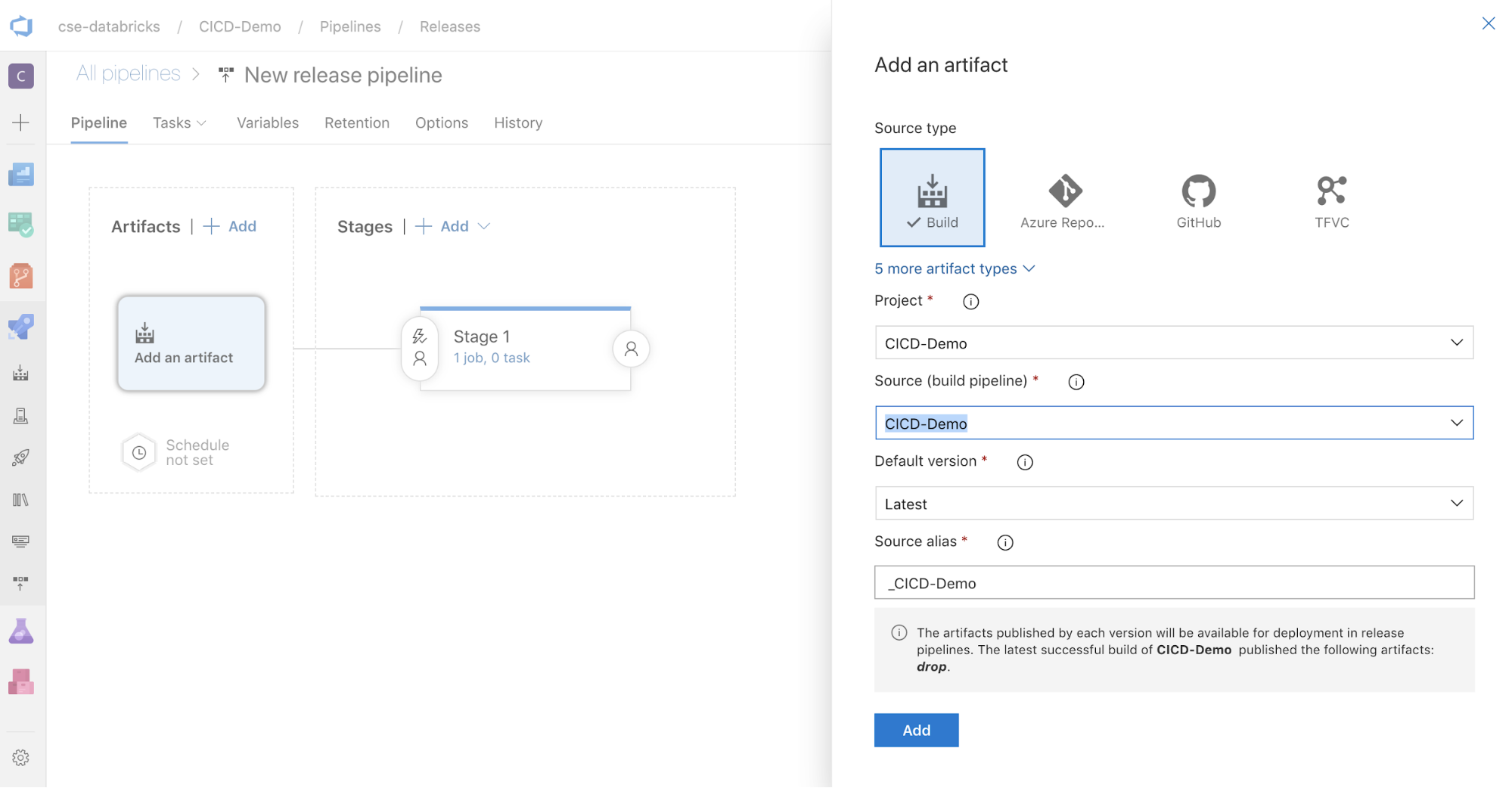
Para configurar cómo se desencadena la canalización, haga clic en
 para mostrar las opciones de desencadenamiento en el lado de la pantalla. Si desea que una versión se inicie automáticamente en función de la disponibilidad del artefacto de compilación o después de un flujo de trabajo de solicitud de incorporación de cambios, habilite el desencadenador adecuado. Por ahora, en este ejemplo, en el último paso de este artículo se desencadena manualmente la canalización de compilación y, luego, la canalización de versión.
para mostrar las opciones de desencadenamiento en el lado de la pantalla. Si desea que una versión se inicie automáticamente en función de la disponibilidad del artefacto de compilación o después de un flujo de trabajo de solicitud de incorporación de cambios, habilite el desencadenador adecuado. Por ahora, en este ejemplo, en el último paso de este artículo se desencadena manualmente la canalización de compilación y, luego, la canalización de versión.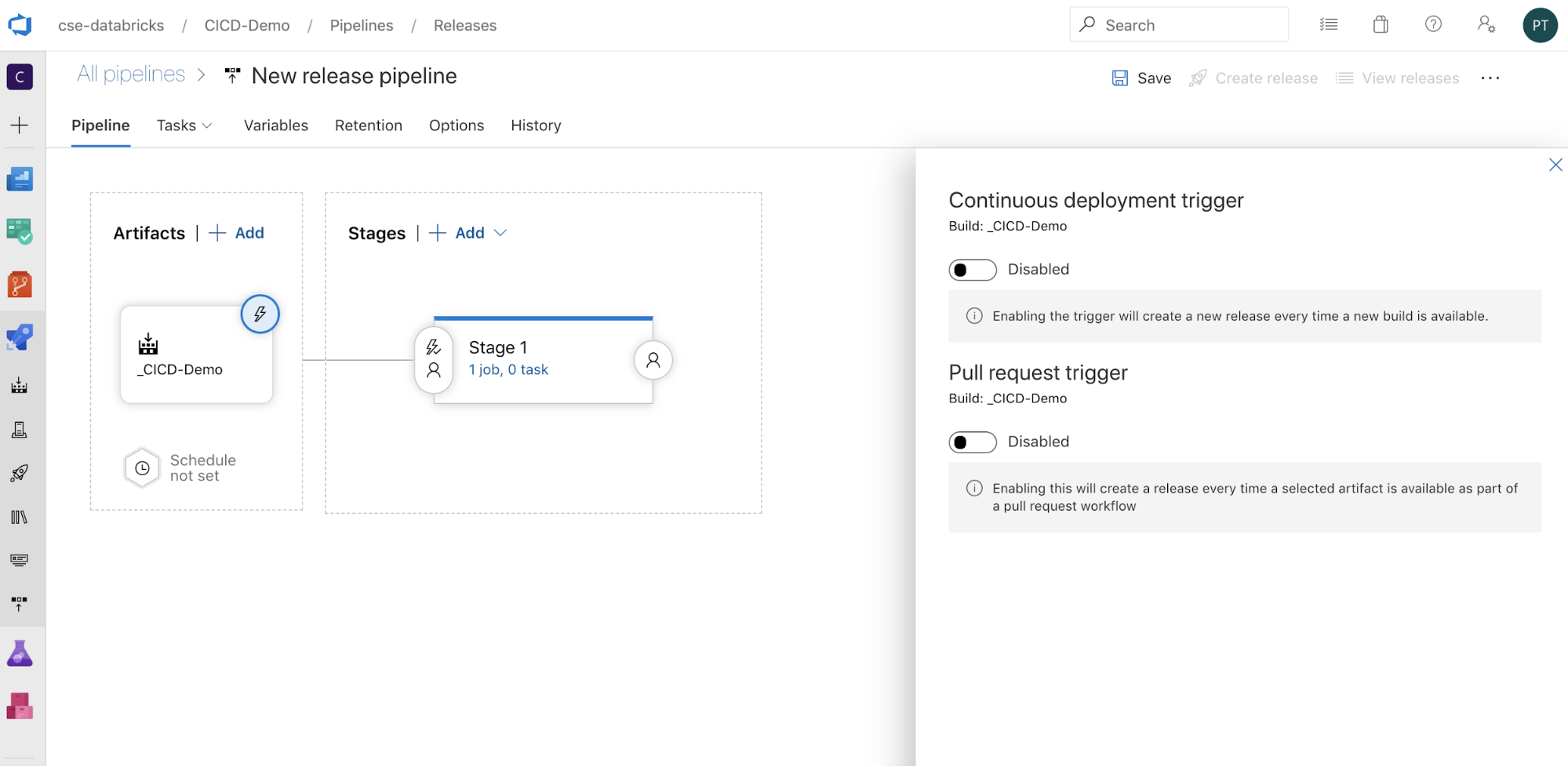
Haga clic en Save > OK.
Paso 3.1: Definir variables de entorno para la canalización de versión
Esta canalización de versión de ejemplo depende de las variables de entorno siguientes, que puede agregar haciendo clic en Agregar en la sección Variables de pipeline de la pestaña Variables, con un valor de Ámbito de Fase 1:
BUNDLE_TARGET, que debe coincidir con el nombretargetdel archivodatabricks.yml. En el ejemplo de este artículo, esdev.DATABRICKS_HOST, que representa la dirección URL por área de trabajo del área de trabajo de Azure Databricks, que comienza porhttps://, por ejemplo,https://adb-<workspace-id>.<random-number>.azuredatabricks.net. No incluya el carácter final/después de.net.DATABRICKS_CLIENT_ID, que representa el ID de la aplicación de la entidad principal del servicio de Microsoft Entra ID.DATABRICKS_CLIENT_SECRET, que representa un secreto de OAuth de Azure Databricks para la entidad de servicio de Microsoft Entra ID.
Paso 3.2: Configuración del agente de versión para la canalización de versión
Haga clic en el vínculo 1 job, 0 task dentro del objeto Stage 1.
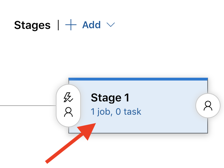
En la pestaña Tasks, haga clic en Agent job.
En la sección Agent selection, en Agent pool, seleccione Azure Pipelines.
En Agent Specification, seleccione el mismo agente que especificó anteriormente para el agente de compilación, en este ejemplo ubuntu-22.04.
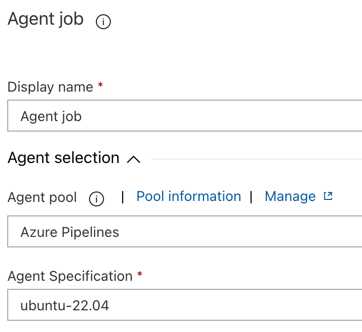
Haga clic en Save > OK.
Paso 3.3: Establecimiento de la versión de Python para el agente de versión
Haga clic en el complemento de la sección Agent job, que viene indicado por la flecha roja de la siguiente ilustración. Aparece una lista donde puede buscar tareas disponibles. También hay una pestaña Marketplace para complementos de terceros que se puede usar para complementar las tareas Azure DevOps estándar. Agregará varias tareas al agente de versión durante los pasos siguientes.
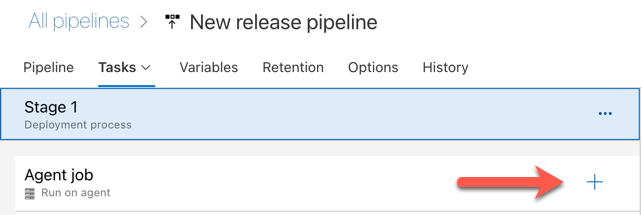
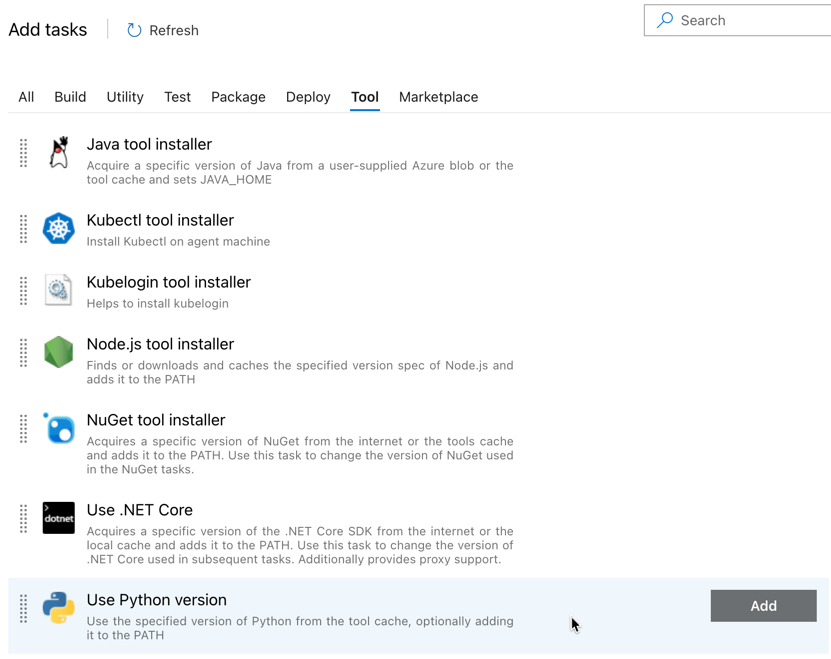
La primera tarea que agrega es Use Python version, que se encuentra en la pestaña Tool. Si no encuentra esta tarea, use el cuadro Search para buscarla. Cuando la encuentre, selecciónela y, luego, haga clic en el botón Add situado junto a la tarea Use Python version.
Al igual que con la canalización de compilación, quiere asegurarse de que la versión de Python es compatible con los scripts a los que se llama en las tareas posteriores. En este caso, haga clic en la tarea Use Python 3.x junto a Agent job y establezca Version spec en
3.10. Establezca también Display name enUse Python 3.10. Esta canalización supone que usa Databricks Runtime 13.3 LTS en los clústeres, que tienen instalado Python 3.10.12.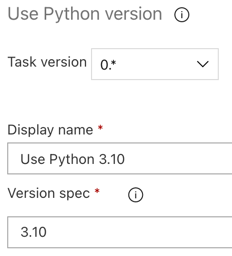
Haga clic en Save > OK.
Paso 3.4: Desempaquetado del artefacto de compilación de la canalización de compilación
A continuación, indique al agente de versión que extraiga el archivo wheel de Python, los archivos de configuración de versión relacionados, los cuadernos y el archivo de código de Python del archivo ZIP mediante la tarea Extraer archivos: haga clic en el signo más en la sección Trabajo de agente, seleccione la tarea Extraer archivos en la pestaña Utilidad y, luego, haga clic en Agregar.
Haga clic en la tarea Extract files junto a Agent job, establezca Archive file patterns en
**/*.zipy establezca la carpeta Destination en la variable del sistema$(Release.PrimaryArtifactSourceAlias)/Databricks. Establezca también Display name enExtract build pipeline artifact.Nota:
$(Release.PrimaryArtifactSourceAlias)representa un alias generado por Azure DevOps para identificar la ubicación de origen del artefacto principal en el agente de versión, por ejemplo,_<your-github-alias>.<your-github-repo-name>. La canalización de versión establece este valor como la variable de entornoRELEASE_PRIMARYARTIFACTSOURCEALIASen la fase de inicialización del trabajo para el agente de versión. Consulte Variables de versión y artefactos clásicos.Establezca Display name en
Extract build pipeline artifact.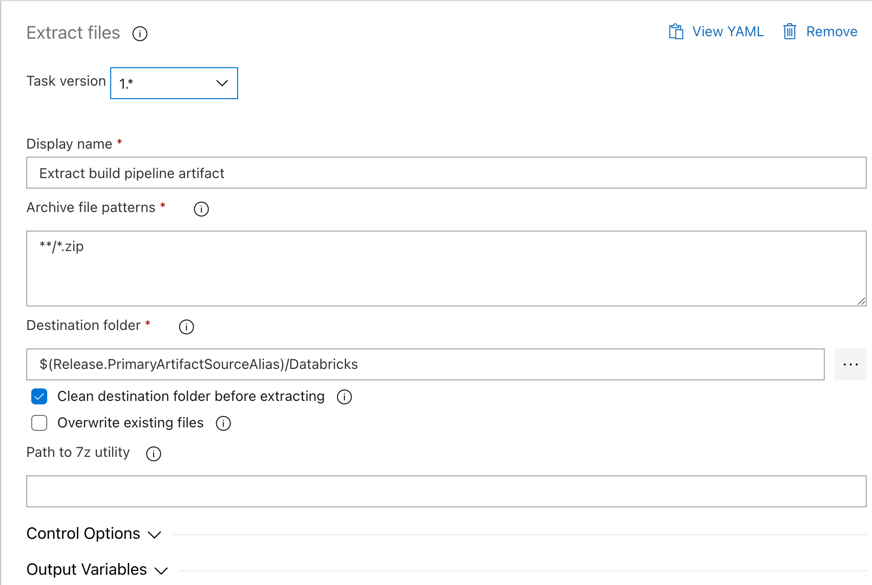
Haga clic en Save > OK.
Paso 3.5: Establecer la variable de entorno BUNDLE_ROOT
Para que el ejemplo de este artículo funcione según lo previsto, debe establecer una variable de entorno denominada BUNDLE_ROOT en la canalización de versión. Las agrupaciones de recursos de Databricks usan esta variable de entorno para determinar dónde se encuentra el archivo databricks.yml. Para establecer esta variable de entorno:
Use la tarea Variables de entorno: haga clic en el signo más de nuevo en la sección Agente de trabajo, seleccione la tarea Variables de entorno en la pestaña Utilidad y, a continuación, haga clic en Agregar.
Nota:
Si la tarea Variables de entorno no está visible en la pestaña Utilidad, escriba
Environment Variablesen el cuadro Buscar y siga las instrucciones que aparecen en pantalla para agregar la tarea a la pestaña Utilidad. Esto puede requerir que salga de Azure DevOps y, a continuación, vuelva a esta ubicación donde lo dejó.En Variables de entorno (separadas por comas), escriba la siguiente definición:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Nota:
$(Agent.ReleaseDirectory)representa un alias generado por Azure DevOps para identificar la ubicación del directorio de versión en el agente de versión, por ejemplo,/home/vsts/work/r1/a. La canalización de versión establece este valor como la variable de entornoAGENT_RELEASEDIRECTORYen la fase de inicialización del trabajo para el agente de versión. Consulte Variables de versión y artefactos clásicos. Para obtener información sobre$(Release.PrimaryArtifactSourceAlias), vea la nota del paso anterior.Establezca Display name en
Set BUNDLE_ROOT environment variable.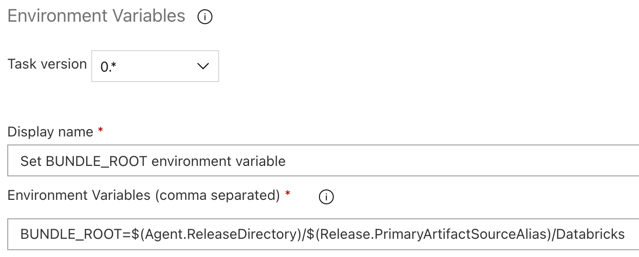
Haga clic en Save > OK.
Paso 3.6. Instalación de la CLI de Databricks y las herramientas de compilación del paquete wheel de Python
A continuación, instale las herramientas de compilación del paquete wheel de Python y la CLI de Databricks en el agente de versión. El agente de versión llamará a la CLI de Databricks y a las herramientas de compilación del paquete wheel de Python en las siguientes tareas. Para ello, use la tarea Bash: haga clic en el signo más de nuevo en la sección Agent job, seleccione la tarea Bash en la pestaña Utility y, luego, haga clic en Add.
Haga clic en la tarea Bash Script junto a Agent job.
En Type, seleccione Inline.
Reemplace el contenido de Script por el siguiente comando, que instala la CLI de Databricks y las herramientas de compilación del paquete wheel de Python:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelEstablezca Display name en
Install Databricks CLI and Python wheel build tools.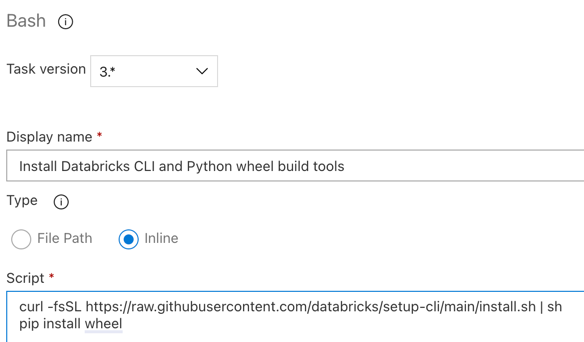
Haga clic en Save > OK.
Paso 3.7: Validación del conjunto de recursos de Databricks
En este paso, se asegura de que el archivo databricks.yml sea sintácticamente correcto.
Use la tarea Bash: haga clic en el signo más de nuevo en la sección Agent job, seleccione la tarea Bash en la pestaña Utility y, luego, haga clic en Add.
Haga clic en la tarea Bash Script junto a Agent job.
En Type, seleccione Inline.
Reemplace el contenido de Script por el comando siguiente, que usa la CLI de Databricks para comprobar si el archivo
databricks.ymles sintácticamente correcto:databricks bundle validate -t $(BUNDLE_TARGET)Establezca Display name en
Validate bundle.Haga clic en Save > OK.
Paso 3.8: Implementar la agrupación
En este paso, compilará el archivo wheel de Python y lo implementará junto a los dos cuadernos de Python y el archivo de Python de la canalización de versión en el área de trabajo de Azure Databricks.
Use la tarea Bash: haga clic en el signo más de nuevo en la sección Agent job, seleccione la tarea Bash en la pestaña Utility y, luego, haga clic en Add.
Haga clic en la tarea Bash Script junto a Agent job.
En Type, seleccione Inline.
Reemplace el contenido de Script por el siguiente comando, que usa la CLI de Databricks para compilar el paquete wheel de Python e implementar los archivos de ejemplo de este artículo desde la canalización de versión en el área de trabajo de Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)Establezca Display name en
Deploy bundle.Haga clic en Save > OK.
Paso 3.9: Ejecutar el cuaderno de prueba unitaria para el paquete wheel de Python
En este paso, ejecutará un trabajo que ejecuta el cuaderno de prueba unitaria en el área de trabajo de Azure Databricks. Este cuaderno ejecuta pruebas unitarias en la lógica de la biblioteca de paquete wheel de Python.
Use la tarea Bash: haga clic en el signo más de nuevo en la sección Agent job, seleccione la tarea Bash en la pestaña Utility y, luego, haga clic en Add.
Haga clic en la tarea Bash Script junto a Agent job.
En Type, seleccione Inline.
Reemplace el contenido de script por el comando siguiente, que usa la CLI de Databricks para ejecutar el trabajo en el área de trabajo de Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsEstablezca Display name en
Run unit tests.Haga clic en Save > OK.
Paso 3.10: Ejecutar el cuaderno que llama al paquete wheel de Python
En este paso, ejecutará un trabajo que ejecuta otro cuaderno en el área de trabajo de Azure Databricks. Este cuaderno llama a la biblioteca de paquete wheel de Python.
Use la tarea Bash: haga clic en el signo más de nuevo en la sección Agent job, seleccione la tarea Bash en la pestaña Utility y, luego, haga clic en Add.
Haga clic en la tarea Bash Script junto a Agent job.
En Type, seleccione Inline.
Reemplace el contenido de script por el comando siguiente, que usa la CLI de Databricks para ejecutar el trabajo en el área de trabajo de Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookEstablezca Display name en
Run notebook.Haga clic en Save > OK.
Ya ha completado la configuración de la canalización de versión. Debería tener el siguiente aspecto:
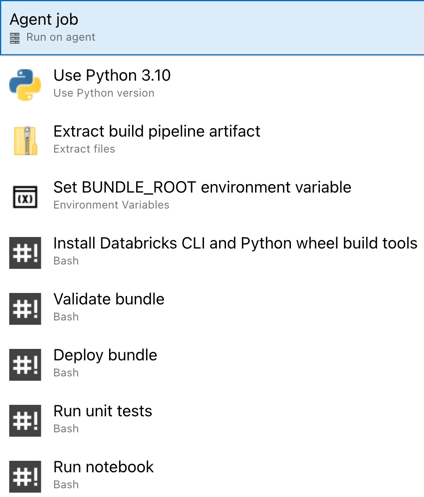
Paso 4: Crear canalizaciones de compilación y versión
En este paso, ejecutará las canalizaciones manualmente. Para obtener información sobre cómo ejecutar automáticamente las canalizaciones, consulte Especificar eventos que desencadenan canalizaciones y Desencadenadores de versión.
Para ejecutar manualmente la canalización de compilación:
- En el menú Pipelines de la barra lateral, haga clic en Pipelines.
- Haga clic en el nombre de la canalización de compilación y, a continuación, haga clic en Ejecutar canalización.
- En Branch/tag, seleccione el nombre de la rama en el repositorio de Git que contiene todo el código fuente que agregó. En este ejemplo se supone que está en la rama
release. - Haga clic en Ejecutar. Aparece la página de ejecución de la canalización de compilación.
- Para ver el progreso de la canalización de compilación y ver los registros relacionados, haga clic en el icono giratorio junto a Job.
- Después de que el icono de trabajo cambie a una marca de verificación verde, continúe para ejecutar la canalización de versión.
Para ejecutar manualmente la canalización de versión:
- Una vez que la canalización de compilación se haya ejecutado correctamente, en el menú Canalizaciones de la barra lateral, haga clic en Versiones.
- Haga clic en el nombre de la canalización de versión y, luego, haga clic en Create release.
- Haga clic en Crear.
- Para ver el progreso de la canalización de versión, en la lista de versiones, haga clic en el nombre de la versión más reciente.
- En el cuadro Fases, haga clic en Fase 1 y en Registros.