Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Cree un agente de INTELIGENCIA ARTIFICIAL e impleméntelo mediante Aplicaciones de Databricks. Databricks Apps proporciona control total sobre el código del agente, la configuración del servidor y el flujo de trabajo de implementación. Este enfoque es ideal cuando se necesita el comportamiento del servidor personalizado, el control de versiones basado en Git o el desarrollo del IDE local.
Tip
Si el agente solo usa herramientas hospedadas Azure Databricks y no necesita lógica personalizada entre llamadas a herramientas, puede usar la API Supervisor (Beta) para permitir que Azure Databricks administre el bucle del agente automáticamente.
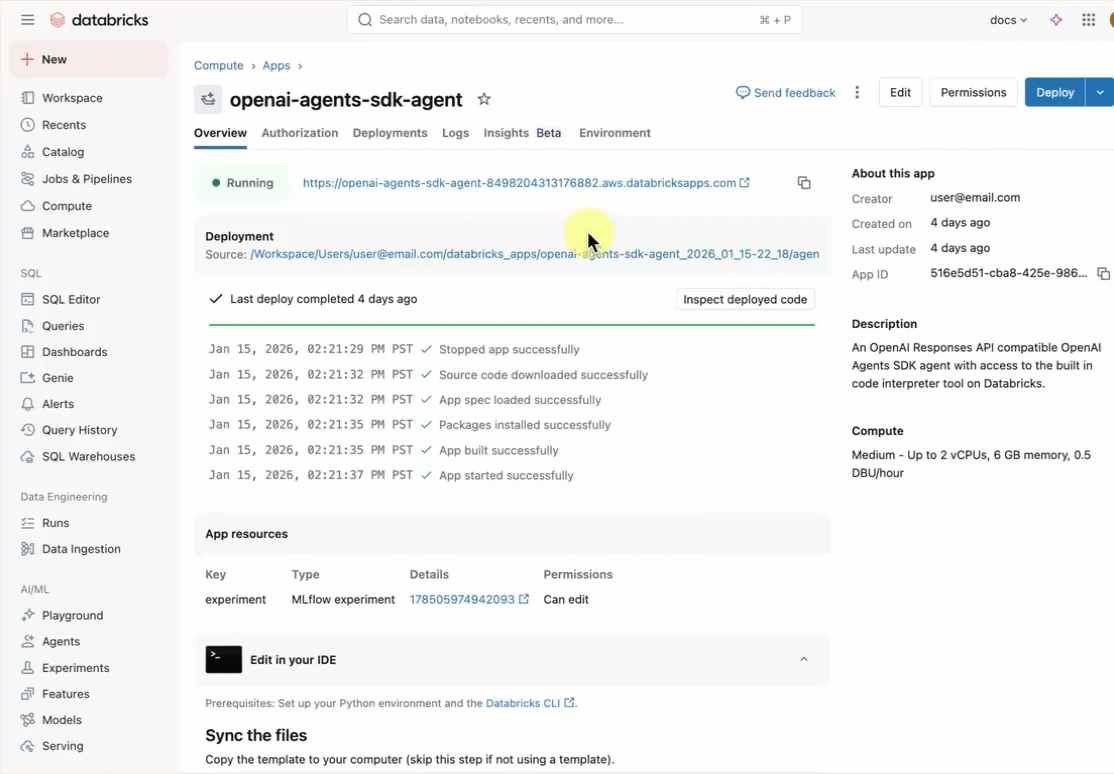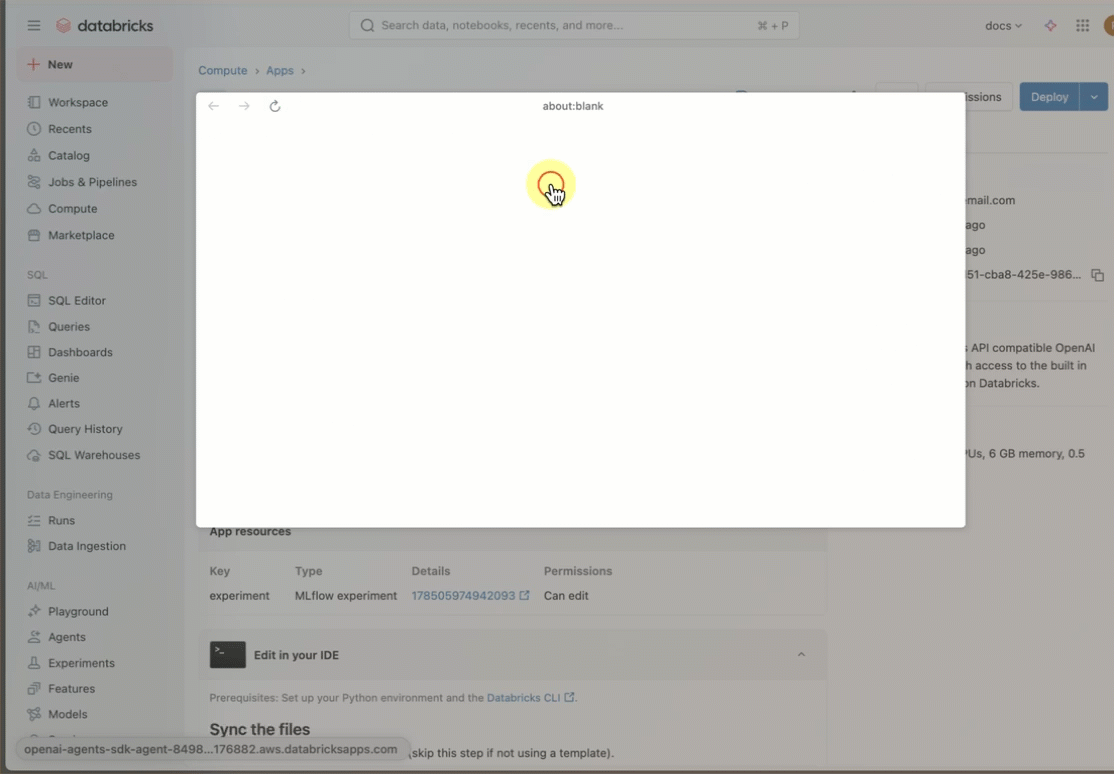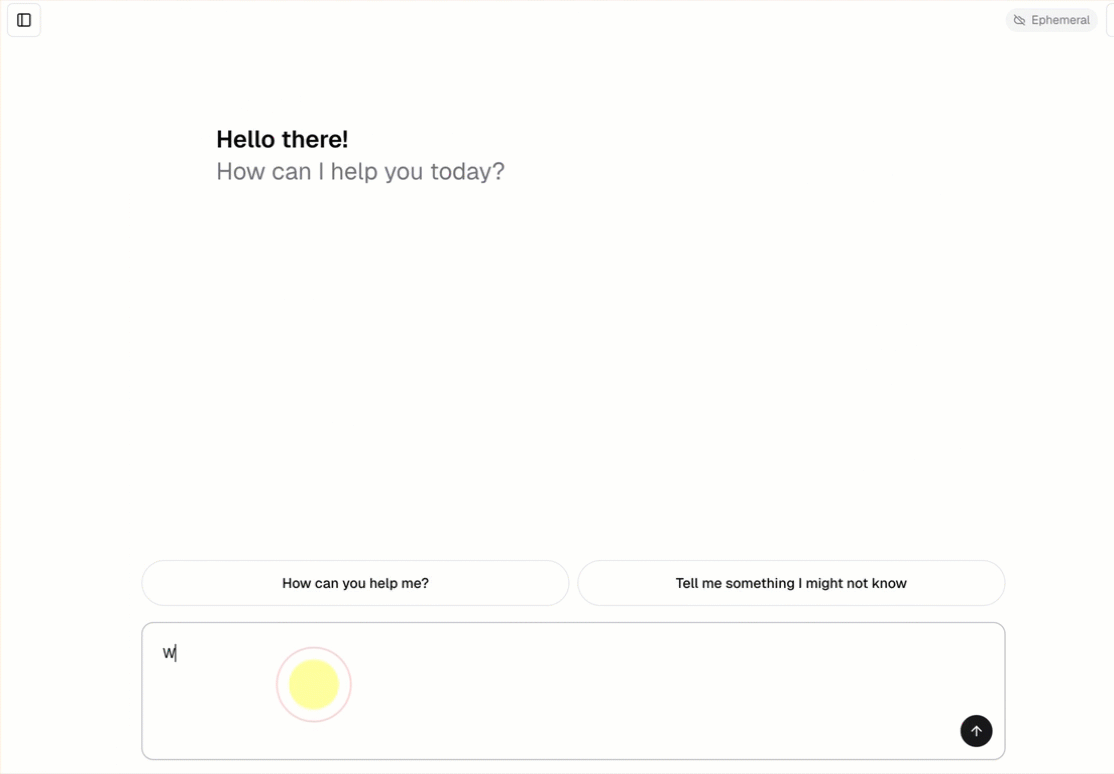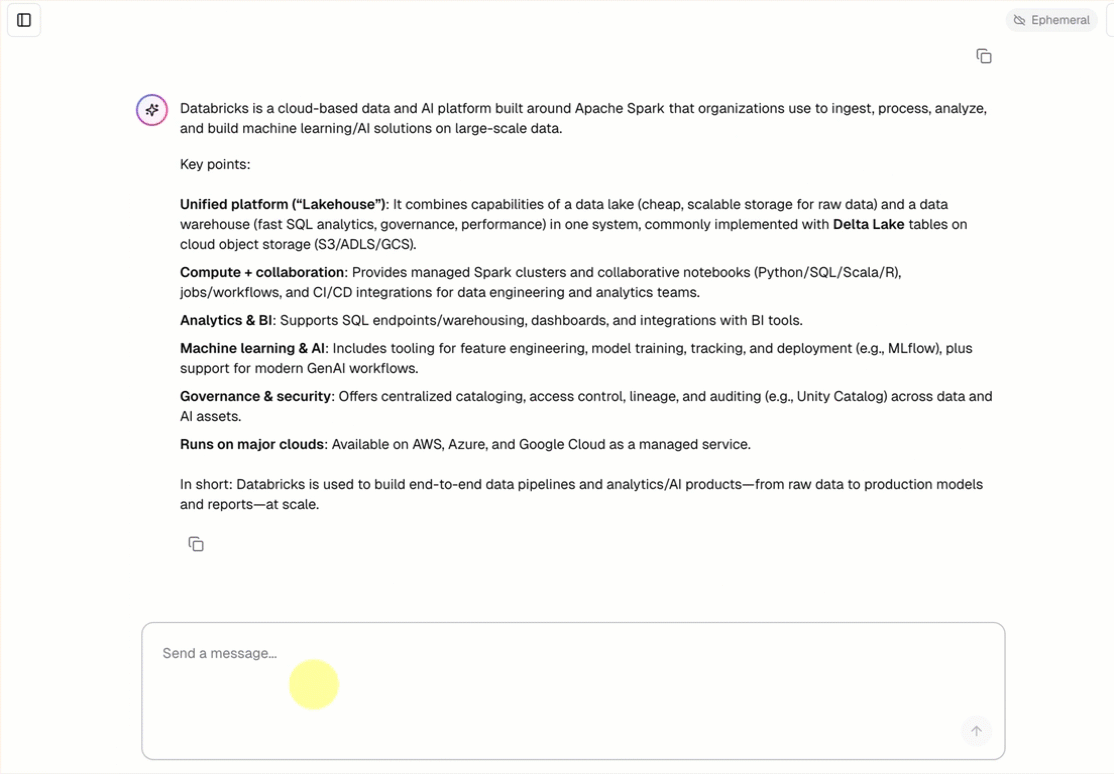
Cada plantilla de agente de conversación incluye una interfaz de usuario de chat integrada (mostrada anteriormente) sin ninguna configuración adicional necesaria. La interfaz de usuario de chat admite respuestas de streaming, representación de Markdown, autenticación de Databricks y historial de chat persistente opcional.
Requisitos
Habilite Databricks Apps en el área de trabajo. Consulte Configuración del área de trabajo y el entorno de desarrollo de Databricks Apps.
Paso 1. Clona la plantilla de la aplicación del agente
Empiece a usar una plantilla de agente precompilada desde el repositorio de plantillas de aplicación de Databricks.
En este tutorial se usa la agent-openai-agents-sdk plantilla, que incluye:
- Un agente creado mediante el SDK del agente de OpenAI
- Código de inicio para una aplicación de agente con una API REST conversacional y una interfaz de usuario de chat interactiva
- Código para evaluar el agente mediante MLflow
Elija una de las siguientes rutas de acceso para configurar la plantilla:
Interfaz de usuario del área de trabajo
Instale la plantilla de aplicación mediante la interfaz de usuario del área de trabajo. Esto instala la aplicación y la implementa en un recurso de cómputo en el área de trabajo. Después, puede sincronizar los archivos de aplicación con el entorno local para su desarrollo posterior.
En el área de trabajo de Databricks, haga clic en + Nueva>aplicación.
Haga clic en Agentes>Agente - SDK de OpenAI Agents.
Cree un nuevo experimento de MLflow con el nombre
openai-agents-templatey complete el resto de la configuración para instalar la plantilla.Después de crear la aplicación, haga clic en la dirección URL de la aplicación para abrir la interfaz de usuario de chat.
Después de crear la aplicación, descargue el código fuente en la máquina local para personalizarla:
Copie el primer comando en Sincronizar los archivos.
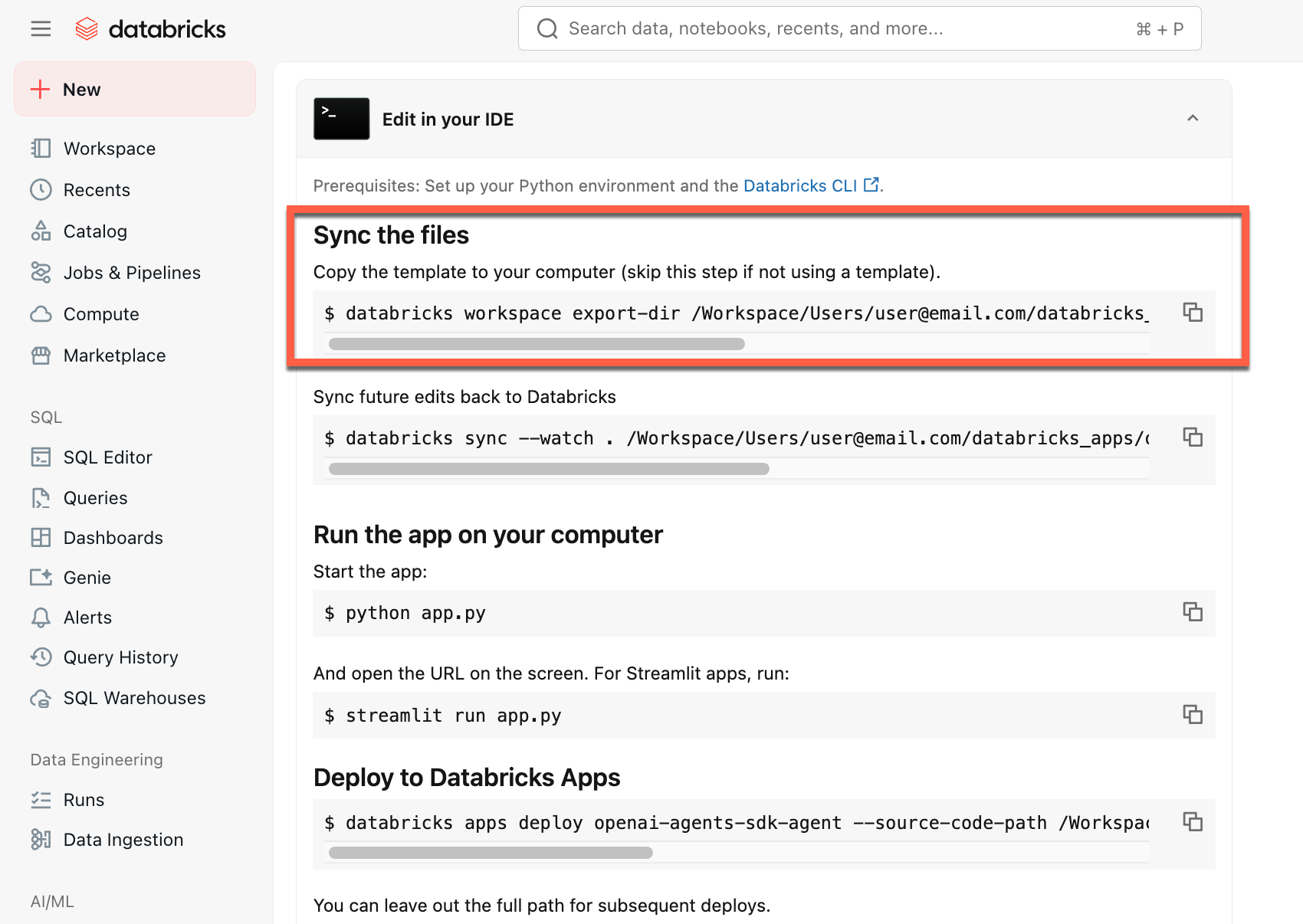
En un terminal local, ejecute el comando copiado.
Clonación desde GitHub
Para empezar desde un entorno local, clone el repositorio de plantillas del agente y abra el agent-openai-agents-sdk directorio :
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Paso 2. Descripción de la aplicación del agente
La plantilla del agente muestra una arquitectura lista para producción con estos componentes clave. Abra las secciones siguientes para obtener más detalles sobre cada componente:

Abra las secciones siguientes para obtener más detalles sobre cada componente:
 Interfaz de usuario de chat integrado
Interfaz de usuario de chat integrado
La plantilla del agente captura y ejecuta automáticamente la plantilla de aplicación de chat como front-end. Esta interfaz de usuario de chat se incluye en la misma implementación de Databricks Apps y se proporciona junto con el agente, por lo que no se requiere ninguna configuración adicional.
Puede personalizar la interfaz de usuario de chat directamente en el proyecto. Para obtener más información sobre las características de la aplicación de chat, incluido cómo habilitar el historial de chat persistente y la recopilación de comentarios de usuarios, consulte Compilación y uso compartido de una interfaz de usuario de chat con Databricks Apps.
 Servidor de Agente MLflow
Servidor de Agente MLflow
Un servidor FastAPI asincrónico que controla las solicitudes del agente con seguimiento y observabilidad integrados.
AgentServer proporciona el punto de conexión para consultar el /invocations agente y administra automáticamente el enrutamiento de solicitudes, el registro y el control de errores.

ResponsesAgent interfaz
Databricks recomienda MLflow ResponsesAgent para compilar agentes.
ResponsesAgent permite crear agentes con cualquier marco de terceros y, a continuación, integrarlos con las características de Inteligencia artificial de Databricks para lograr un registro sólido, seguimiento, evaluación, implementación y funcionalidades de supervisión.

Para obtener información sobre cómo crear un ResponsesAgent, consulte los ejemplos de documentación de MLflow: ResponsesAgent for Model Serving.
ResponsesAgent proporciona las siguientes ventajas:
Funcionalidades avanzadas del agente
- Compatibilidad con varios agentes
- Salida de streaming: transmita la salida en fragmentos más pequeños.
- Historial completo de mensajes de llamada a herramientas: devuelve varios mensajes, incluidos los mensajes intermedios de llamada a herramientas, para mejorar la calidad y la administración de conversaciones.
- Compatibilidad con la confirmación de llamadas a herramientas
- Soporte para herramientas que han estado operativas a largo plazo
Desarrollo, implementación y supervisión simplificados
-
Desarrolla agentes utilizando cualquier marco: Envuelve cualquier agente existente mediante la
ResponsesAgentinterfaz para obtener compatibilidad integrada con AI Playground, Agent Evaluation y Agent Monitoring. - Interfaces de autoría tipificadas: Escribir código de agente mediante clases de Python tipificadas, beneficiándose del IDE y la función de autocompletar en entornos de trabajo y cuadernos.
- Seguimiento automático: MLflow agrega automáticamente respuestas transmitidas en seguimientos para facilitar la evaluación y visualización.
Compatible con el esquema de OpenAI : consulte OpenAI: Respuestas vs. ChatCompletion .
-
Desarrolla agentes utilizando cualquier marco: Envuelve cualquier agente existente mediante la
 SDK de agentes de OpenAI
SDK de agentes de OpenAI
La plantilla usa el SDK de agentes de OpenAI como marco de trabajo del agente para la administración de conversaciones y la orquestación de herramientas. Puede desarrollar agentes utilizando cualquier framework. La clave está en envolver tu agente con la interfaz MLflow ResponsesAgent.
 Servidores MCP (Protocolo de contexto de modelo)
Servidores MCP (Protocolo de contexto de modelo)
La plantilla se conecta a los servidores MCP de Databricks para proporcionar a los agentes acceso a herramientas y orígenes de datos. Consulte Protocolo de contexto de modelo (MCP) en Databricks.
Creación de agentes mediante asistentes de codificación de IA
Databricks recomienda usar asistentes de codificación de IA, como Claude, Cursor y Copilot para crear agentes. Utiliza las habilidades proporcionadas por el agente, en /.claude/skills y el archivo AGENTS.md para ayudar a los asistentes de inteligencia artificial a comprender la estructura del proyecto, las herramientas disponibles y los procedimientos recomendados. Los agentes pueden leer automáticamente esos archivos para desarrollar e implementar las aplicaciones de Databricks.
Paso 3. Añade herramientas a tu agente
Proporcione a los agentes funcionalidades como consultar bases de datos, buscar documentos o llamar a API externas mediante la conexión a servidores MCP. La plantilla del agente incluye una conexión de servidor MCP predeterminada. Para agregar más herramientas, configure servidores MCP adicionales en el código del agente y conceda los permisos necesarios en databricks.yml.
Consulte Herramientas del agente de IA para ver los tipos de herramientas y ejemplos de código admitidos.
Define herramientas de funciones locales de Python
Para las operaciones que no requieren orígenes de datos externos o API, defina herramientas directamente en el código del agente. Estas herramientas se ejecutan en el mismo proceso que el agente y son útiles para transformaciones de datos, cálculos o operaciones de utilidad.
SDK de agentes de OpenAI
Utiliza el decorador @function_tool del SDK de agentes de OpenAI.
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangGraph
Usa el @tool decorador de LangChain.
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
Las herramientas de funciones locales no requieren concesiones de recursos porque databricks.yml se ejecutan dentro del proceso del agente.
Temas de creación avanzados
Respuestas de transmisión
Respuestas de streaming
El streaming permite a los agentes enviar respuestas en fragmentos en tiempo real en lugar de esperar a que se complete la respuesta. Para implementar el streaming con ResponsesAgent, emita una serie de eventos delta seguidos de un evento de finalización final:
-
Emitir eventos delta: envíe varios
output_text.deltaeventos con el mismoitem_idpara transmitir fragmentos de texto en tiempo real. -
Finalizar con evento terminado: envíe un evento final
response.output_item.donecon el mismoitem_idque los eventos delta que contienen el texto de salida final completo.
Cada evento delta transmite un fragmento de texto al cliente. El evento final hecho contiene el texto de respuesta completo y indica a Databricks que haga lo siguiente:
- Rastrea la salida de tu agente con el seguimiento de MLflow
- Agregar respuestas transmitidas en tablas de inferencia de AI Gateway
- Mostrar la salida completa en la interfaz de usuario del entorno de pruebas de IA
Propagación de errores de streaming
Mosaic AI propaga los errores detectados durante el streaming con el último token en databricks_output.error. Depende del cliente que realiza la llamada manejar y mostrar adecuadamente este error.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Entradas y salidas personalizadas
Entradas y salidas personalizadas
Algunos escenarios pueden requerir entradas adicionales del agente, como client_type y session_id, o salidas como enlaces de fuentes de recuperación que no deben incluirse en el historial del chat para interacciones futuras.
En estos escenarios, MLflow ResponsesAgent admite de forma nativa los campos custom_inputs y custom_outputs. Puede acceder a las entradas personalizadas a través de request.custom_inputs en los ejemplos de marco anteriores.
La Agent Evaluation review app no admite la representación de trazas para agentes con campos de entrada adicionales.
Proporcione custom_inputs en el AI Playground y revise la aplicación
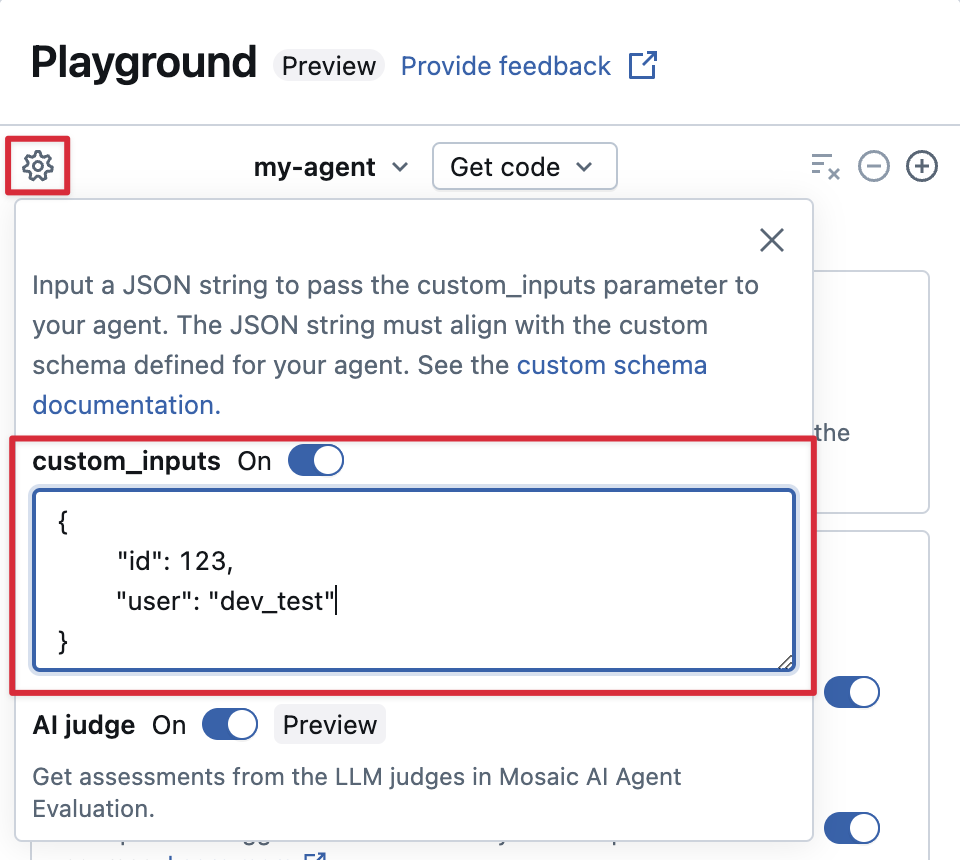
Si tu agente acepta entradas adicionales mediante el campo custom_inputs, puedes proporcionar manualmente estas entradas tanto en el AI Playground como en la Aplicación de Revisión.
En el AI Playground o la aplicación Agent Review, seleccione el icono de engranaje

Habilite custom_inputs.
Proporcione un objeto JSON que coincida con el esquema de entrada definido del agente.
Esquemas del recuperador personalizados
Esquemas de recuperación personalizados
Los agentes de inteligencia artificial suelen usar recuperadores para buscar y consultar datos no estructurados de índices de búsqueda vectorial. Para obtener herramientas de recuperación de ejemplo, consulte Conexión de agentes a datos no estructurados.
Realice un seguimiento de estos recuperadores dentro del agente con intervalos de RECUPERACIÓN de MLflow para habilitar las características del producto de Databricks, entre las que se incluyen:
- Mostrar automáticamente vínculos a documentos de origen recuperados en la interfaz de usuario de AI Playground
- Ejecución automática de la recuperación del fundamento y evaluadores de relevancia en la evaluación del agente
Nota
Databricks recomienda usar las herramientas del recuperador proporcionadas por paquetes de Databricks AI Bridge como databricks_langchain.VectorSearchRetrieverTool y databricks_openai.VectorSearchRetrieverTool porque ya se ajustan al esquema del recuperador de MLflow. Consulte Desarrollo de un recuperador localmente mediante AI Bridge.
Si su agente incluye fragmentos del recuperador con un esquema personalizado, llame a mlflow.models.set_retriever_schema al definir su agente en el código. Esto asigna las columnas de salida del recuperador a los campos esperados de MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: The Largest Open Source AI Engineering Platform'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Nota
La columna doc_uri es especialmente importante al evaluar el rendimiento del recuperador.
doc_uri es el identificador principal de los documentos devueltos por el recuperador, lo que le permite compararlos con los conjuntos de evaluación de la verdad fundamental. Consulte Conjuntos de evaluación (MLflow 2).
Paso 4. Ejecución local de la aplicación del agente
Configure el entorno local:
Instale
uv(administrador de paquetes Python),nvm(administrador de versiones de Node) y la CLI de Databricks:-
uvinstalación -
nvminstalación - Ejecute lo siguiente para usar Node 20 LTS:
nvm use 20 -
databricks CLIinstalación
-
Cambie el directorio a la
agent-openai-agents-sdkcarpeta .Ejecute los scripts de inicio rápido proporcionados para instalar dependencias, configurar el entorno e iniciar la aplicación.
uv run quickstart uv run start-app
En un navegador, vaya a http://localhost:8000 para abrir la interfaz de usuario de chat integrada y empezar a chatear con el agente.
Paso 5. Configurar la autenticación
El agente necesita autenticación para acceder a los recursos de Azure Databricks. Databricks Apps proporciona dos métodos de autenticación: autorización de aplicación (servicio principal) y autorización de usuario (en nombre del usuario). Puede configurar cualquiera de estos a través de la interfaz de usuario del área de trabajo o de manera declarativa en databricks.yml con Paquetes de Automatización Declarativa. Las plantillas de agente incluyen un databricks.yml, por lo que esa ruta es la predeterminada cuando se inicia desde una plantilla.
Para obtener la referencia completa, incluidos todos los tipos de recursos admitidos, los valores de permisos y un databricks.yml tutorial completo, consulte Autenticación para agentes de IA.
Autorización de aplicaciones (valor predeterminado)
La autorización de aplicaciones utiliza una entidad de servicio que Azure Databricks crea automáticamente para tu aplicación. Todos los usuarios comparten los mismos permisos.
Opción 1: Interfaz de usuario del área de trabajo
- Haga clic en Editar en la página principal de la aplicación.
- Vaya al paso Configurar .
- En la sección Recursos de la aplicación, agregue el recurso del experimento de MLflow con
Can Editpermiso. - Para otros recursos (índices de búsqueda vectorial, espacios de Genie, puntos de conexión de servicio, almacenes de SQL, funciones de catálogo de Unity, Lakebase), haga clic en + Agregar recurso y establezca cada permiso.
Opción 2: agrupaciones de automatización declarativa
Declare todos los recursos que usa el agente bajo resources.apps.<app>.resources en databricks.yml. Implemente el paquete para conceder al principal de servicio los permisos declarados.
resources:
apps:
my_agent:
name: 'my-agent'
source_code_path: ./
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run my_agent
Para obtener la lista completa de tipos de recursos, consulte Autorización de aplicaciones.
Autorización de usuario
La autorización de usuario permite al agente actuar con los permisos individuales de cada usuario. Úselo cuando necesite seguimientos de auditoría o control de acceso por usuario.
Agregue este código a su agente:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important
Inicialice get_user_workspace_client() dentro de las @invoke o las @stream funciones, no durante el inicio de la aplicación. Las credenciales de usuario solo existen al manejar una solicitud.
Configure las API Azure Databricks a las que el agente puede llamar en nombre del usuario declarando ámbitos.
Opción 1: Interfaz de usuario del área de trabajo
- En la interfaz de usuario de Azure Databricks, vaya a la configuración de Authorization de la aplicación.
- En Autorización de usuario, haga clic en + Agregar ámbito y seleccione los ámbitos.
- Guarde y reinicie la aplicación.
Opción 2: agrupaciones de automatización declarativa
Agregue los ámbitos en user_api_scopes en la aplicación en databricks.yml:
resources:
apps:
my_agent:
name: 'my-agent'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run my_agent
Para obtener la lista de ámbitos disponibles y completar las instrucciones de configuración, consulte Autorización de usuario.
Paso 6. Evaluación del agente
La plantilla incluye código de evaluación del agente. Consulte agent_server/evaluate_agent.py para obtener más información. Evalúe la relevancia y la seguridad de las respuestas del agente ejecutando lo siguiente en un terminal:
uv run agent-evaluate
Paso 7. Despliegue el agente en aplicaciones de Databricks
Después de configurar la autenticación, implemente el agente en Databricks. Asegúrese de que tiene instalada y configurada la CLI de Databricks .
Si ha clonado el repositorio localmente, cree la aplicación Databricks antes de implementarlo. Si ha creado la aplicación a través de la interfaz de usuario del área de trabajo, omita este paso, ya que la aplicación y el experimento de MLflow ya están configurados.
databricks apps create agent-openai-agents-sdkSincronice los archivos locales en el área de trabajo. Consulte Implementación de la aplicación.
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Implemente la aplicación de Databricks.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Para actualizar el agente en el futuro, sincroniza y vuelve a desplegar el agente.
Paso 8. Consulta del agente implementado
En el ejemplo siguiente se usa una solicitud rápida curl con un token de OAuth. Los tokens de acceso personal (PAT) no se admiten para las aplicaciones de Databricks.
Para obtener la lista completa de métodos de consulta, incluido el cliente openAI de Databricks y la API REST, consulte Query un agente implementado en Azure Databricks.
Genere un token de OAuth mediante la CLI de Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Use el token para consultar al agente:
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Limitaciones
- Solo se admiten tamaños de cálculo medianos y grandes. Consulte Configuración de recursos de proceso para una aplicación de Databricks.
- La interfaz de usuario de MLflow Review App Chat no admite actualmente agentes implementados en Aplicaciones de Databricks. Para evaluar los seguimientos existentes, use sesiones de etiquetado, que funcionan independientemente del método de implementación. Databricks está creando soporte de revisión y comentarios directamente en la plantilla de chatbot.