Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El desarrollo de una aplicación de IA generativa sólida (aplicación de inteligencia artificial de generación) requiere un planeamiento deliberado, un bucle rápido de evaluación de comentarios y una infraestructura de producción escalable. En este flujo de trabajo se describe una secuencia recomendada de pasos que le guiarán de la prueba de concepto inicial (POC) a la implementación de producción.
- Recopile los requisitos para validar la idoneidad de la inteligencia artificial de generación e identificar las restricciones.
- Diseñe la arquitectura de la solución. Consulte Patrones de diseño de sistemas de agentes.
- Prepare los orígenes de datos y cree herramientas necesarias.
- Compile y valide el prototipo inicial (POC).
- Implementar en el entorno de preproducción.
- Recopilar comentarios del usuario y medir la calidad
- Corrija problemas de calidad mediante la refinación de la lógica del agente y las herramientas basadas en la evaluación.
- Incorpore la entrada de experto en la materia (SME) para mejorar continuamente la calidad del sistema del agente.
- Implemente la aplicación de IA generativa en el entorno de producción.
- Supervisar el rendimiento y la calidad.
- Mantener y mejorar en función del uso real.
Este flujo de trabajo debe ser iterativo: después de cada ciclo de implementación o evaluación, vuelva a los pasos anteriores para refinar las canalizaciones de datos o actualizar la lógica del agente. Por ejemplo, la supervisión de producción podría revelar nuevos requisitos, desencadenar actualizaciones en el diseño del agente y otra ronda de evaluación. Siguiendo estos pasos sistemáticamente y aprovechando las funcionalidades de seguimiento de MLflow de Databricks, Agent Framework y Evaluación del agente, puede crear aplicaciones de inteligencia artificial de generación de alta calidad que satisfagan de forma confiable las necesidades del usuario, respeten los requisitos de seguridad y cumplimiento y continúen mejorando con el tiempo.
0. Requisitos previos
Antes de empezar a desarrollar la aplicación de inteligencia artificial de generación, no se puede sobresaplicar lo importante que es tardar tiempo en realizar lo siguiente correctamente: recopilación de requisitos y diseño de soluciones.
La recopilación de requisitos incluye los pasos siguientes:
- Valide si la IA generativa se ajusta a su caso de uso.
- Defina la experiencia del usuario.
- Investigar los orígenes de datos.
- Establezca restricciones de rendimiento.
- Captura de restricciones de seguridad.
El diseño de la solución incluye lo siguiente:
- Diseñar las canalizaciones de datos.
- Identifique las herramientas necesarias.
- Describir la arquitectura general del sistema.
Al establecer esta base, se establece una dirección clara para las fases posteriores de compilación, evaluación y producción .
Recopilación de requisitos
Definir requisitos claros y completos de casos de uso es un primer paso fundamental para desarrollar una aplicación de inteligencia artificial de generación correcta. Estos requisitos sirven para los siguientes propósitos:
- Ayudan a determinar si un enfoque de inteligencia artificial de generación es adecuado para su caso de uso.
- Guían el diseño, la implementación y las decisiones de evaluación de soluciones.
La inversión de tiempo al principio para recopilar requisitos detallados puede evitar desafíos significativos más adelante en el proceso de desarrollo y garantizar que la solución resultante satisfaga las necesidades de los usuarios finales y las partes interesadas. Los requisitos bien definidos proporcionan la base para las fases posteriores del ciclo de vida de la aplicación.
¿El caso de uso es una buena opción para la inteligencia IA generativa?
Antes de comprometerse con una solución de inteligencia artificial de generación, considere si sus puntos fuertes inherentes se alinean con sus requisitos. Algunos ejemplos en los que una solución de IA generativa es una buena opción son:
- Generación de contenido: La tarea requiere generar contenido nuevo o creativo que no se pueda lograr con plantillas estáticas o lógica simple basada en reglas.
- Control dinámico de consultas: Las consultas de usuario son abiertas o complejas y requieren respuestas flexibles y compatibles con el contexto.
- Síntesis de información: El caso de uso se beneficia de combinar o resumir diversas fuentes de información para generar una salida coherente.
-
Sistemas de agente: La aplicación requiere más que simplemente generar texto en respuesta a un mensaje. Es posible que deba ser capaz de:
- Planificación y toma de decisiones: Formulación de una estrategia de varios pasos para lograr un objetivo específico.
- Tomar medidas: Desencadenar procesos externos o llamar a varias herramientas para realizar tareas (por ejemplo, recuperar datos, realizar llamadas API, ejecutar consultas SQL y ejecutar código).
- Mantenimiento del estado: Realizar un seguimiento del historial de conversaciones o el contexto de tareas en varias interacciones para permitir la continuidad.
- Generar salidas adaptables: Generar respuestas que evolucionan en función de acciones anteriores, información actualizada o condiciones cambiantes.
Por el contrario, es posible que un enfoque de inteligencia artificial de generación no sea ideal en las situaciones siguientes:
- La tarea es muy determinista y se puede resolver eficazmente con plantillas predefinidas o sistemas basados en reglas.
- Todo el conjunto de información necesaria ya es estático o se ajusta a un marco simple y cerrado.
- Se requieren respuestas de latencia extremadamente baja (milisegundos) y no se puede dar cabida a la sobrecarga del procesamiento generativo.
- Las respuestas simples y con plantilla son suficientes para el caso de uso previsto.
Importante
En las secciones siguientes se usan etiquetas P0, P1 y P2 para indicar prioridad relativa.
- 🟢 Los elementos [P0] son críticos o esenciales. Estos deben abordarse inmediatamente.
- 🟡 Los elementos [P1] son importantes, pero pueden ir después de los requisitos P0.
- ⚪ [P2] Los elementos de prioridad inferior son consideraciones o mejoras que pueden abordarse según lo permitan el tiempo y los recursos.
Estas etiquetas ayudan a los equipos a ver rápidamente qué requisitos necesitan atención inmediata frente a qué se puede aplazar.
Experiencia del usuario
Defina cómo interactuarán los usuarios con la aplicación gen AI y qué tipo de respuestas se esperan.
- 🟢 [P0] Solicitud típica: ¿Qué aspecto tendrá una solicitud de usuario típica? Recopile ejemplos de partes interesadas.
- 🟢 [P0] Respuestas esperadas: ¿Qué tipo de respuestas debe generar el sistema (por ejemplo, respuestas cortas, explicaciones de formato largo, narraciones creativas)?
- 🟡 [P1] Modalidad de interacción: ¿Cómo interactuarán los usuarios con la aplicación (por ejemplo, interfaz de chat, barra de búsqueda, asistente de voz)?
- 🟡 [P1] Tono, estilo, estructura: ¿Qué tono, estilo y estructura deben adoptar las salidas generadas (formal, conversacional, técnica, puntos de viñetas o prosa continua)?
- 🟡 [P1]Control de errores: ¿Cómo debe controlar la aplicación consultas ambiguas, incompletas o fuera de destino? ¿Debe proporcionar comentarios o solicitar aclaraciones?
- ⚪ [P2] Requisitos de formato: ¿Hay alguna guía de presentación o formato específica para las salidas (incluidos los metadatos o la información complementaria)?
Datos
Determine la naturaleza, los orígenes y la calidad de los datos que se usarán en la aplicación de inteligencia artificial de generación.
-
🟢
[P0] Orígenes de datos: ¿Qué orígenes de datos están disponibles?
- Para cada origen, determine:
- ¿Los datos están estructurados o no están estructurados?
- ¿Cuál es el formato de origen (por ejemplo, PDF, HTML, JSON, XML)?
- ¿Dónde residen los datos?
- ¿Cuántos datos están disponibles?
- ¿Cómo se debe acceder a los datos?
- Para cada origen, determine:
- 🟡 [P1] Actualizaciones de datos: ¿Con qué frecuencia se actualizan los datos? ¿Qué mecanismos se aplican para controlar las actualizaciones?
-
🟡
[P1] Calidad de los datos: ¿Hay problemas de calidad conocidos o incoherencias?
- Tenga en cuenta si se requiere alguna supervisión de calidad en los orígenes de datos.
Considere la posibilidad de crear una tabla de inventario para consolidar esta información, por ejemplo:
| Origen de datos | Fuente | Tipos de archivo | Tamaño | Frecuencia de actualización |
|---|---|---|---|---|
| Origen de datos 1 | Volumen del catálogo de Unity | JSON | 10 GB | Diariamente |
| Origen de datos 2 | API pública | XML | NA (API) | Tiempo real |
| Origen de datos 3 | SharePoint (en inglés) | PDF, .docx | 500 MB | Mensualmente |
Restricciones de rendimiento
Capture los requisitos de rendimiento y recursos para la aplicación de IA generativa.
Latencia
-
🟢
[P0] Tiempo hasta el primer token: ¿Cuál es la demora máxima aceptable antes de entregar el primer token?
- Nota: La latencia se mide normalmente con p50 (mediana) y p95 (percentil 95) para capturar el rendimiento promedio y el peor de los casos.
- 🟢 [P0] Tiempo de finalización: ¿Cuál es el tiempo de respuesta aceptable (tiempo de finalización) para los usuarios?
- 🟢 [P0] Latencia de streaming: Si se transmiten respuestas, ¿se acepta una latencia general mayor?
Escalabilidad
-
🟡
[P1]Usuarios y solicitudes simultáneos: ¿Cuántos usuarios o solicitudes simultáneos deben admitir el sistema?
- Nota: La escalabilidad se mide a menudo en términos de QPS (consultas por segundo) o QPM (consultas por minuto).
- 🟡 [P1] Patrones de uso: ¿Cuáles son los patrones de tráfico esperados, las cargas máximas o los picos basados en el tiempo en el uso?
Restricciones de costo
- 🟢 [P0] Limitaciones de costos de inferencia: ¿Cuáles son las restricciones de costo o las limitaciones presupuestarias para los recursos de proceso de inferencia?
Evaluación
Establezca cómo se evaluará y mejorará la aplicación de inteligencia artificial de generación con el tiempo.
- 🟢 [P0] KPI empresariales: ¿Qué objetivo empresarial o KPI deben afectar a la aplicación? Defina los valores y objetivos de línea base.
- 🟢 [P0] Comentarios de las partes interesadas: ¿Quién proporcionará comentarios iniciales y continuos sobre el rendimiento y las salidas de las aplicaciones? Identificar grupos de usuarios o expertos de dominio específicos.
-
🟢
[P0] Medición de la calidad: ¿Qué métricas (por ejemplo, precisión, relevancia, seguridad, puntuaciones humanas) se usarán para evaluar la calidad de las salidas generadas?
- ¿Cómo se calcularán estas métricas durante el desarrollo (por ejemplo, con datos sintéticos, conjuntos de datos mantenidos manualmente)?
- ¿Cómo se medirá la calidad en producción (por ejemplo, registrar y analizar respuestas a consultas de usuario reales)?
- ¿Cuál es la tolerancia general al error? (por ejemplo, aceptar un determinado porcentaje de imprecisiones factuales menores, o requerir una corrección cercana al 100 % para casos de uso críticos).
- El objetivo es crear un conjunto de evaluación a partir de consultas de usuario reales, datos sintéticos o una combinación de ambos. Este conjunto proporciona una manera coherente de evaluar el rendimiento a medida que evoluciona el sistema.
-
🟡
[P1] Bucles de comentarios: ¿Cómo se deben recopilar los comentarios del usuario (por ejemplo, pulgares hacia arriba/abajo, formularios de encuesta) y usarse para impulsar mejoras iterativas?
- Planee la frecuencia con la que se revisarán e incorporarán los comentarios.
Seguridad
Identifique las consideraciones de seguridad y privacidad.
- 🟢 [P0] Confidencialidad de los datos: ¿Hay elementos de datos confidenciales o confidenciales que requieran un control especial?
- 🟡 [P1] Controles de acceso: ¿Necesita implementar controles de acceso para restringir determinados datos o funcionalidades?
- 🟡 [P1] Evaluación y mitigación de amenazas: ¿La aplicación necesitará protegerse frente a amenazas comunes de inteligencia artificial de generación, como la inyección de mensajes o las entradas de usuario malintencionadas?
Despliegue
Comprenda cómo se integrará, implementará, supervisará y mantendrá la solución de inteligencia artificial de generación.
-
🟡
[P1] Integración: ¿Cómo se debe integrar la solución gen AI con los sistemas y flujos de trabajo existentes?
- Identifique puntos de integración (por ejemplo, Slack, CRM, herramientas de BI) y conectores de datos necesarios.
- Determine cómo fluirán las solicitudes y respuestas entre la aplicación de IA generativa y los sistemas posteriores (por ejemplo, las API REST, los webhooks).
- 🟡 [P1] Implementación: ¿Cuáles son los requisitos para implementar, escalar y control de versiones de la aplicación? En este artículo se explica cómo se puede controlar el ciclo de vida completo en Databricks mediante MLflow, Unity Catalog, Agent Framework, Agent Evaluation y Model Serving.
-
🟡
[P1] Supervisión y observabilidad de producción: ¿Cómo supervisará la aplicación una vez que esté en producción?
- Registro y seguimientos: capturar seguimientos de ejecución completos.
- Métricas de calidad: evalúe continuamente las métricas clave (como la corrección, la latencia, la relevancia) en el tráfico activo.
- Alertas y paneles: configure alertas para problemas críticos.
- Bucle de comentarios: incorpore los comentarios de los usuarios en producción (pulgares arriba o abajo) para detectar problemas pronto y impulsar mejoras iterativas.
Ejemplo
Por ejemplo, considere cómo se aplican estas consideraciones y requisitos a una aplicación RAG agenteica hipotética que usa un equipo de soporte al cliente de Databricks:
| Área | Consideraciones | Requisitos |
|---|---|---|
| Experiencia del usuario |
|
|
| Lógica del agente |
|
|
| Datos |
|
|
| Rendimiento |
|
|
| Evaluación |
|
|
| Seguridad |
|
|
| Despliegue |
|
|
Diseño de la solución
Para conocer consideraciones de diseño adicionales, consulte Patrones de diseño del sistema del agente.
Orígenes y herramientas de datos
Al diseñar una aplicación de inteligencia artificial de generación, es importante identificar y asignar los distintos orígenes de datos y herramientas necesarios para impulsar la solución. Pueden implicar conjuntos de datos estructurados, canalizaciones de procesamiento de datos no estructurados o consultar API externas. A continuación se muestran los enfoques recomendados para incorporar diferentes orígenes de datos o herramientas en la aplicación gen AI:
Datos estructurados
Los datos estructurados normalmente residen en formatos tabulares bien definidos (por ejemplo, una tabla Delta o un archivo CSV) y son ideales para las tareas en las que las consultas están predeterminadas o deben generarse dinámicamente en función de la entrada del usuario. Consulte Herramientas del agente de IA de recuperación estructurada para obtener recomendaciones sobre cómo agregar datos estructurados a su aplicación de inteligencia artificial generativa.
Datos no estructurados
Los datos no estructurados incluyen documentos sin procesar, archivos PDF, correos electrónicos, imágenes y otros formatos que no se ajustan a un esquema fijo. Estos datos requieren un procesamiento adicional, normalmente a través de una combinación de análisis, fragmentación e inserción, para que se consulten y usen eficazmente en una aplicación de inteligencia artificial de generación. Consulte Herramientas de construcción y rastreo de recuperadores para datos no estructurados para obtener recomendaciones sobre cómo agregar datos estructurados a su aplicación de IA generativa.
API y acciones externas
En algunos escenarios, es posible que la aplicación de inteligencia artificial de generación necesite interactuar con sistemas externos para recuperar datos o realizar acciones. En los casos en los que la aplicación requiera invocar herramientas o interactuar con api externas, se recomienda lo siguiente:
- Administración de credenciales de API con una conexión de catálogo de Unity: Use una conexión de catálogo de Unity para controlar de forma segura las credenciales de API. Este método garantiza que los tokens y secretos se administran y controlan de forma centralizada el acceso.
-
Invocación mediante el SDK de Databricks:
Envíe solicitudes HTTP a servicios externos mediante lahttp_requestfunción de ladatabricks-sdkbiblioteca. Esta función aprovecha una conexión de Catálogo de Unity para la autenticación y admite métodos HTTP estándar. -
Aprovechar las funciones del catálogo de Unity:
Encapsular conexiones externas en una función de catálogo de Unity para agregar lógica personalizada previa o posterior al procesamiento. -
Herramienta ejecutor de Python:
Para ejecutar código dinámicamente para la transformación de datos o las interacciones de API mediante funciones de Python, use la herramienta ejecutor de Python integrada.
Ejemplo:
Una aplicación de análisis interno recupera datos de mercado activo de una API financiera externa. La aplicación usa:
- Conexión externa del catálogo de Unity para almacenar de forma segura las credenciales de API.
- Una función de catálogo de Unity personalizada encapsula la llamada API para agregar procesamiento previo (como normalización de datos) y posprocesamiento (como el control de errores).
- Además, la aplicación podría invocar directamente la API a través del SDK de Databricks.
Estrategia de implementación
Al desarrollar una aplicación de inteligencia artificial de generación, tiene dos opciones principales para implementar la lógica del agente: aprovechar un marco de código abierto o crear una solución personalizada mediante código Python. A continuación se muestra un desglose de las ventajas y desventajas de cada enfoque.
Uso de un marco (como LangChain, LlamaIndex, CrewAI o AutoGen)
Ventajas:
- Componentes predefinidos: Los marcos de trabajo incluyen herramientas listas para la gestión rápida, el encadenamiento de llamadas y la integración con diversas fuentes de datos, lo que puede acelerar el desarrollo.
- Comunidad y documentación: Beneficiarse del soporte técnico de la comunidad, tutoriales y actualizaciones periódicas.
- Patrones de diseño comunes: Normalmente, los marcos proporcionan una estructura modular clara para orquestar tareas comunes, lo que puede simplificar el diseño general del agente.
Inconvenientes:
- Abstracción agregada: Los marcos de código abierto suelen introducir capas de abstracción que pueden ser innecesarias para su caso de uso específico.
- Dependencia de actualizaciones: Es posible que dependa de los mantenedores de marcos para correcciones de errores y actualizaciones de características, lo que puede ralentizar su capacidad de adaptarse rápidamente a los nuevos requisitos.
- Sobrecarga potencial: La abstracción adicional puede provocar desafíos de personalización si la aplicación necesita un control más preciso.
Uso de Python puro
Ventajas:
- Flexibilidad: El desarrollo en Python puro le permite adaptar la implementación exactamente a sus necesidades sin estar restringida por las decisiones de diseño de un marco.
- Adaptación rápida: Puede ajustar rápidamente el código e incorporar los cambios según sea necesario, sin esperar actualizaciones de un marco externo.
- Simplicidad: Evite capas innecesarias de abstracción, lo que puede dar lugar a una solución más magra y eficaz.
Inconvenientes:
- Mayor esfuerzo de desarrollo: La creación desde cero puede requerir más tiempo y experiencia para implementar características que podría proporcionar un marco dedicado.
- Reinventar la rueda: es posible que tenga que desarrollar funcionalidades comunes (como el encadenamiento de herramientas o la administración de mensajes) por su cuenta.
- Responsabilidad de mantenimiento: Todas las actualizaciones y correcciones de errores se convierten en su responsabilidad, lo que puede ser difícil para sistemas complejos.
En última instancia, la decisión debe guiarse por la complejidad, las necesidades de rendimiento del proyecto y el nivel de control que necesita. Ninguno de los enfoques es intrínsecamente superior; cada uno ofrece ventajas distintas en función de sus preferencias de desarrollo y prioridades estratégicas.
1. Construir
En esta fase, transformará el diseño de la solución en una aplicación de IA generativa operativa. En lugar de perfeccionar todo por adelantado, comience pequeño con una prueba de concepto mínima (POC) que se puede probar rápidamente. Esto le permite implementar en un entorno de preproducción lo antes posible, recopilar consultas representativas de usuarios o PYME reales y refinar en función de los comentarios reales.
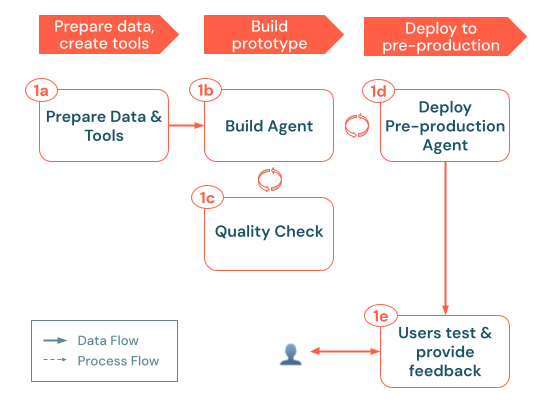
El proceso de compilación sigue estos pasos clave:
a) Preparar datos y herramientas: Asegúrese de que los datos necesarios son accesibles, analizados y listos para su recuperación. Implemente o registre las funciones y conexiones del catálogo de Unity (por ejemplo, las API de recuperación o las llamadas API externas) que necesitará el agente. b. Agente de compilación: Organice la lógica principal, empezando por un enfoque de POC sencillo. c. Comprobación de calidad: Valide la funcionalidad esencial antes de exponer la aplicación a más usuarios. d. Implemente el agente de preproducción: Haga que la POC esté disponible para probar a los usuarios y expertos en la materia para recibir comentarios iniciales. e. Recopilar comentarios de los usuarios: Use el uso real para identificar áreas de mejora, datos o herramientas adicionales necesarios y posibles refinamientos para la siguiente iteración.
a) Preparación de datos y herramientas
En la fase de diseño de la solución, tendrá una idea inicial de los orígenes de datos y las herramientas necesarias para la aplicación. En esta fase, manténgalo mínimo: céntrese en los datos suficientes para validar la POC. Esto garantiza una iteración rápida sin grandes inversiones iniciales en canalizaciones complejas.
Datos
-
Identificación de un subconjunto representativo de datos
- Para los datos estructurados, seleccione las tablas o columnas de clave más relevantes para el escenario inicial.
- En el caso de los datos no estructurados, priorice la indexación solo un subconjunto de documentos representativos. Use una canalización básica de fragmentación e inserción con Vector de búsqueda en IA de Mosaic para que el agente pueda recuperar fragmentos de texto pertinentes si es necesario.
-
Configuración del acceso a datos
- Si necesita que su aplicación haga llamadas API externas, almacene las credenciales de forma segura mediante una conexión de Catálogo de Unity.
-
Validación de la cobertura básica
- Confirme que los subconjuntos de datos elegidos abordan adecuadamente las consultas de usuario que planea probar.
- Guarde los orígenes de datos adicionales o transformaciones complejas para futuras iteraciones. Su objetivo actual debe demostrar la viabilidad básica y recopilar comentarios.
herramientas
Con los orígenes de datos configurados, el siguiente paso es implementar y registrar las herramientas a las que llamará el agente en tiempo de ejecución a Unity Catalog. Una herramienta es una función de interacción única, como una consulta SQL o una llamada API externa, que el agente puede invocar para la recuperación, transformación o acción.
Herramientas de recuperación de datos
- Consultas de datos restringidas y estructuradas: Si las consultas son fijas, encapsularlas en una función SQL del catálogo de Unity o en una UDF de Python. Esto mantiene la lógica centralizada y detectable.
- Consultas de datos estructuradas y abiertas: Si las consultas son más abiertas, considere la posibilidad de configurar un espacio de Genie para controlar las consultas de texto a SQL.
- Funciones auxiliares de datos no estructuradas: Para los datos no estructurados almacenados en La búsqueda vectorial de IA de Mosaico, cree una herramienta de recuperación de datos no estructurada a la que el agente pueda llamar para capturar fragmentos de texto pertinentes.
Herramientas de llamada de API
-
Llamadas API externas:las llamadas API se pueden invocar directamente mediante el método del SDK de
http_requestDatabricks. - Contenedores opcionales: Si necesita implementar lógica previa o posterior al procesamiento (como la normalización de datos o el control de errores), encapsula la llamada API en una función de catálogo de Unity.
Mantenerla mínima
- Comience solo con herramientas esenciales: Céntrese en una única ruta de acceso de recuperación o en un conjunto limitado de llamadas API. Puede agregar más a medida que itera.
- Validar de forma interactiva: Pruebe cada herramienta de forma independiente (por ejemplo, en un cuaderno) antes de incorporarla al sistema del agente.
Después de que las herramientas de prototipo estén listas, continúe con la construcción del agente. El agente organiza estas herramientas para responder a consultas, capturar datos y realizar acciones según sea necesario.
b. Agente de compilación
Una vez implementados los datos y las herramientas, puede crear el agente que responda a las solicitudes entrantes, como las consultas de usuario. Para crear un agente de prototipo inicial, use Python o ai playground. Siga estos pasos:
-
Inicio sencillo
-
Elija un patrón de diseño básico: Para una POC, comience con una cadena básica (como una secuencia fija de pasos) o un único agente de llamada a herramientas (donde LLM puede llamar dinámicamente a una o dos herramientas esenciales).
- Si el escenario se alinea con uno de los cuadernos de ejemplo proporcionados en la documentación de Databricks, adapte ese código como esqueleto.
- Mensaje mínimo: Resista la tentación de complicar en exceso los avisos en este momento. Mantenga las instrucciones concisas y directamente relevantes para las tareas iniciales.
-
Elija un patrón de diseño básico: Para una POC, comience con una cadena básica (como una secuencia fija de pasos) o un único agente de llamada a herramientas (donde LLM puede llamar dinámicamente a una o dos herramientas esenciales).
-
Incorporación de herramientas
-
Integración de herramientas: Si usa un patrón de diseño de cadena, los pasos que llaman a cada herramienta se codificarán de forma rígida. En un agente de llamada a herramientas, se proporciona un esquema para que LLM sepa cómo invocar la función.
- Valide que las herramientas de forma aislada funcionen según lo previsto, antes de incorporarlas al sistema del agente y probarlas de un extremo a otro.
- Barandillas: Si el agente puede modificar sistemas externos o ejecutar código, asegúrese de que tiene comprobaciones de seguridad básicas y límites de protección (como limitar el número de llamadas o restringir determinadas acciones). Implemente estos elementos dentro de una función de catálogo de Unity.
-
Integración de herramientas: Si usa un patrón de diseño de cadena, los pasos que llaman a cada herramienta se codificarán de forma rígida. En un agente de llamada a herramientas, se proporciona un esquema para que LLM sepa cómo invocar la función.
-
Seguimiento y registro del agente con MLflow
- Siga cada paso: Use el seguimiento de MLflow para capturar entradas, salidas y tiempo transcurrido por paso para depurar problemas y medir el rendimiento.
- Registre el agente: Use el seguimiento de MLflow para registrar el código y la configuración del agente.
En esta etapa, la perfección no es el objetivo. Quiere un agente sencillo y funcional que pueda implementar para recibir comentarios anticipados de SME y usuarios de prueba. El siguiente paso consiste en ejecutar una comprobación de calidad rápida antes de que esté disponible en un entorno de preproducción.
c. Control de calidad
Antes de exponer el agente a una audiencia de preproducción más amplia, ejecute una comprobación de calidad "suficientemente buena" sin conexión para detectar los problemas importantes antes de implementarlo en un punto de conexión. En esta fase, normalmente no tendrá un conjunto de datos de evaluación grande y sólido, pero todavía puede realizar un paso rápido para asegurarse de que el agente se comporta según lo previsto en una serie de consultas de ejemplo.
-
Prueba interactiva en un cuaderno
- inspección manual: llame manualmente al agente con solicitudes representativas. Preste atención a si los datos correctos son recuperados, las herramientas son llamadas correctamente y se sigue el formato deseado.
- Inspeccione los rastros de MLflow: Si ha habilitado el seguimiento de MLflow, revise la telemetría paso a paso. Confirme que el agente elige las herramientas adecuadas, controla los errores correctamente y no genera solicitudes o resultados intermedios inesperados.
- Comprobación de la latencia: Tenga en cuenta cuánto tiempo tarda cada solicitud en ejecutarse. Si los tiempos de respuesta o el uso de tokens son demasiado altos, es posible que tenga que eliminar los pasos o simplificar la lógica antes de continuar.
-
Comprobación de ambiente
- Esto se puede hacer en un cuaderno o en ai Playground.
- Coherencia y corrección: ¿La salida del agente tiene sentido para las consultas que ha probado? ¿Hay inexactitudes o detalles que faltan?
- Casos límite: si intentó algunas consultas inusuales, ¿el agente todavía respondió lógicamente o al menos devolvió un error de forma adecuada (por ejemplo, rechazando amablemente la respuesta en lugar de producir una salida sin sentido)?
- Cumplimiento de la petición: Si proporcionó instrucciones de alto nivel, como el tono o el formato deseados, ¿el agente sigue estas instrucciones?
-
Evaluar la calidad "aceptable"
- Si está limitado a las consultas de prueba en este momento, considere la posibilidad de generar datos sintéticos. Consulte Creación de un conjunto de evaluación.
- Solucione los problemas principales: Si detecta errores importantes (por ejemplo, el agente llama repetidamente a herramientas no válidas o genera ningún sentido), corrija estos problemas antes de exponerlos a una audiencia más amplia. Consulte Problemas comunes de calidad y cómo corregirlos.
- Decidir la viabilidad: Si el agente cumple con un umbral básico de usabilidad y exactitud para un pequeño conjunto de consultas, puede continuar. Si no es así, restrinja las indicaciones, corrija problemas de herramientas o datos y vuelva a probar.
-
Planear los pasos siguientes
- Realizar un seguimiento de las mejoras: Documente las deficiencias que decida posponer. Después de recopilar comentarios reales en preproducción, puede volver a consultarlos.
Si todo parece viable para una implementación limitada, estará listo para implementar el agente en preproducción. Un proceso de evaluación exhaustivo se realizará en fases posteriores, especialmente después de tener datos más reales, comentarios de SME y un conjunto de evaluación estructurado. Por ahora, céntrese en asegurarse de que el agente muestre de forma confiable su funcionalidad principal.
d. Desplegar el agente de preproducción
Una vez que el agente cumpla un umbral de calidad de línea base, el siguiente paso es hospedarlo en un entorno de preproducción para que pueda comprender cómo los usuarios consultan la aplicación y recopilan sus comentarios para guiar el desarrollo. Este entorno puede ser tu entorno de desarrollo durante la fase de POC. El requisito principal es que el entorno sea accesible para seleccionar evaluadores internos o expertos de dominio.
-
Desplegar el agente
- Registro y registro del agente: En primer lugar, registre el agente como un modelo de MLflow y regístrelo en el catálogo de Unity.
- Implementar mediante Agent Framework: use el Agent Framework para tomar el agente registrado e implementarlo como modelo de puntos de conexión de servicio.
-
Tablas de inferencia
- Agent Framework almacena automáticamente solicitudes, respuestas y seguimientos junto con metadatos en el servidor de seguimiento del catálogo de Unity para cada punto de conexión de servicio.
-
Protección y configuración
- Control de acceso:restrinja el acceso de punto de conexión al grupo de prueba (PYME, usuarios avanzados). Esto garantiza el uso controlado y evita la exposición inesperada de los datos.
- Autenticación: confirme que los secretos, tokens de API o conexiones de base de datos necesarios están configurados correctamente.
Ahora tiene un entorno controlado para recopilar comentarios sobre consultas reales. Una de las formas en que puede interactuar rápidamente con el agente se encuentra en AI Playground, donde puede seleccionar el punto de conexión de servicio de modelos recién creado y consultar al agente.
e. Recopilación de comentarios de usuario
Después de implementar el agente en un entorno de preproducción, el siguiente paso es recopilar comentarios de usuarios reales y pymes para descubrir brechas, detectar imprecisiones y refinar aún más el agente.
Uso de la aplicación de revisión
- Al implementar el agente con Agent Framework, se crea una aplicación de revisión de estilo de chat simple. Proporciona una interfaz fácil de usar donde los evaluadores pueden plantear preguntas e evaluar inmediatamente las respuestas del agente.
- Todas las solicitudes, respuestas y comentarios del usuario (pulgares hacia arriba y abajo, comentarios escritos) se registran automáticamente en el servidor de seguimiento de MLflow administrado de Databricks, lo que facilita su análisis más adelante.
Uso de la interfaz de usuario de supervisión para inspeccionar los registros
- Realice un seguimiento de los votos positivos/negativos o comentarios textuales en la interfaz de usuario de supervisión para ver qué respuestas los evaluadores encontraron particularmente útiles (o poco útiles).
Participación de expertos en dominios
- Anime a las PYME a que se ejecuten en escenarios típicos e inusuales. El conocimiento del dominio ayuda a exponer errores sutiles, como errores de interpretación de directivas o datos que faltan.
- Mantenga una lista de problemas pendientes, desde pequeños ajustes en las instrucciones hasta grandes refactorizaciones de flujos de datos. Decida qué correcciones priorizar antes de continuar.
Curación de nuevos datos de evaluación
- Convierta interacciones notables o problemáticas en casos de prueba. Con el tiempo, estos forman la base de un conjunto de datos de evaluación más sólido.
- Si es posible, agregue respuestas correctas o esperadas a estos casos. Esto ayuda a medir la calidad en ciclos de evaluación posteriores.
Iteración basada en comentarios
- Aplique correcciones rápidas, como pequeños cambios de indicación o nuevos límites de protección para abordar los puntos débiles inmediatos.
- Para problemas más complejos, como requerir lógica avanzada de varios pasos o nuevos orígenes de datos, recopile suficientes evidencias antes de invertir en cambios arquitectónicos importantes.
Al aprovechar los comentarios de la aplicación de revisión, los registros de tabla de inferencia y la información de SME, esta fase de preproducción ayuda a exponer brechas clave y refinar el agente de forma iterativa. Las interacciones reales recopiladas en este paso crean la base para crear un conjunto de evaluación estructurado, lo que le permite pasar de mejoras ad hoc a un enfoque más sistemático de medición de calidad. Una vez solucionados los problemas periódicos y el rendimiento se estabiliza, estará bien preparado para una implementación de producción con una evaluación sólida en su lugar.
2. Evaluar e iterar
Una vez que la aplicación gen AI se haya probado en un entorno de preproducción, el siguiente paso es medir, diagnosticar y refinar sistemáticamente su calidad. Esta fase "evaluar e iterar" transforma los comentarios y registros sin procesar en un conjunto de evaluación estructurado, lo que permite probar repetidamente mejoras y asegurarse de que la aplicación cumple los estándares necesarios para la precisión, relevancia y seguridad.
Esta fase incluye los pasos siguientes:
- Recopilación de consultas reales de registros: Convierta interacciones de alto valor o problemáticas de las tablas de inferencia en casos de prueba.
- Agregue etiquetas de expertos: Siempre que sea posible, adjunte verdades objetivas o directrices de estilo y políticas a estos casos para poder medir la corrección, la base y otras dimensiones de calidad de forma más objetiva.
- Aprovechar evaluación del agente: use jueces de LLM integrados o comprobaciones personalizadas para cuantificar la calidad de la aplicación.
- Iterar: mejore la calidad mediante la refinación de la lógica del agente, las canalizaciones de datos o las indicaciones. Vuelva a ejecutar la evaluación para confirmar si ha resuelto problemas clave.
Tenga en cuenta que estas funcionalidades funcionan incluso si la aplicación de inteligencia artificial de generación se ejecuta fuera de Databricks. Al instrumentar el código con el seguimiento de MLflow, puede capturar seguimientos de cualquier entorno y unificarlos en la Plataforma de inteligencia de datos de Databricks para una evaluación y supervisión coherentes. A medida que sigue incorporando nuevas consultas, comentarios e información de SME, el conjunto de datos de evaluación se convierte en un recurso vivo que respalda un ciclo de mejora continua, lo que garantiza que la aplicación de inteligencia artificial de generación se mantenga sólida, confiable y alineada con los objetivos empresariales.
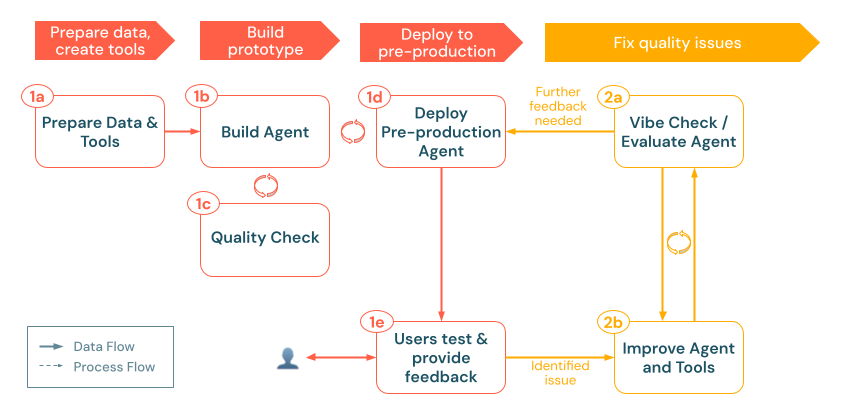
un. Evalúa al agente
Una vez que el agente se ejecuta en un entorno de preproducción, el siguiente paso consiste en medir sistemáticamente su rendimiento más allá de las comprobaciones de ambiente ad hoc. La evaluación del agente de IA de Mosaic le permite crear conjuntos de evaluación, ejecutar comprobaciones de calidad con jueces LLM integrados o personalizados, e iterar rápidamente en áreas problemáticas.
Evaluaciones sin conexión y en línea
Al evaluar las aplicaciones de inteligencia artificial generativa, hay dos enfoques principales: evaluación desconectada y evaluación en línea. Esta fase del ciclo de desarrollo se centra en la evaluación sin conexión, que hace referencia a la evaluación sistemática fuera de las interacciones del usuario activo. La evaluación en línea se trata más adelante al analizar la supervisión del agente en producción.
Los equipos a menudo dependen en exceso de "pruebas intuitivas" durante mucho tiempo en el flujo de trabajo del desarrollador, probando informalmente unas pocas consultas y juzgando subjetivamente si las respuestas parecen razonables. Aunque esto proporciona un punto de partida, carece del rigor y la cobertura necesarios para crear aplicaciones de calidad de producción.
Por el contrario, un proceso de evaluación sin conexión adecuado hace lo siguiente:
- Establece una línea de base de calidad antes de una implementación más amplia, creando métricas claras para mejorar.
- Identifica puntos débiles específicos que requieren atención, superando la limitación de las pruebas solo los casos de uso esperados.
- Detecta regresiones de calidad a medida que refina la aplicación comparando automáticamente el rendimiento entre versiones.
- Proporciona métricas cuantitativas para demostrar la mejora de las partes interesadas.
- Ayuda a detectar casos perimetrales y posibles modos de error antes de que los usuarios lo hagan.
- Reduce el riesgo de implementar un agente con un rendimiento inferior en producción.
Invertir tiempo en la evaluación sin conexión paga dividendos significativos a largo plazo, lo que le ayuda a impulsar la entrega coherente de respuestas de alta calidad.
Creación de un conjunto de evaluación
Un conjunto de evaluación sirve como base para medir el rendimiento de la aplicación de IA generativa. De forma similar a un conjunto de pruebas en el desarrollo de software tradicional, esta colección de consultas representativas y las respuestas esperadas se convierten en el conjunto de datos de pruebas de regresión y pruebas de calidad.
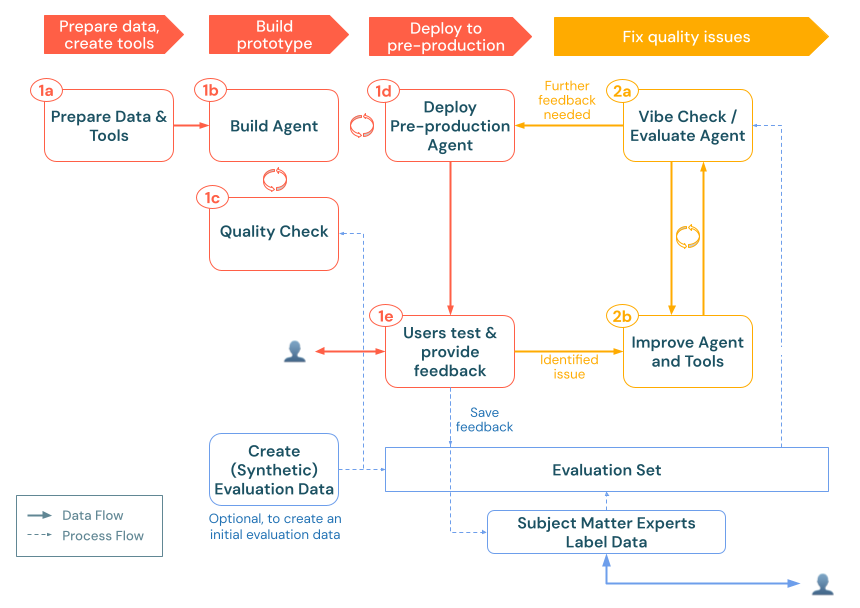
Puede crear un conjunto de evaluación a través de varios enfoques complementarios:
Transformación de registros de tabla de inferencia en ejemplos de evaluación
Los datos de evaluación más valiosos proceden directamente del uso real. La implementación de preproducción ha generado registros de tabla de inferencia que contienen solicitudes, respuestas del agente, llamadas a herramientas y contexto recuperado.
La conversión de estos registros en un conjunto de evaluación proporciona varias ventajas:
- Cobertura real: Se incluyen comportamientos impredecibles del usuario que quizás no haya previsto.
- Centrado en el problema: Puede filtrar específicamente para comentarios negativos o respuestas lentas.
- Distribución representativa: Se captura la frecuencia real de los distintos tipos de consulta.
Generación de datos de evaluación sintética
Si no tiene un conjunto mantenido de consultas de usuario, puede generar automáticamente un conjunto de datos de evaluación sintética. Este "conjunto de inicio" de consultas le ayuda a evaluar rápidamente si el agente:
- Devuelve respuestas coherentes y precisas.
- Responde en el formato correcto.
- Respeta las directrices de estructura, tonalidad y política.
- Recupera correctamente el contexto (para RAG).
Normalmente, los datos sintéticos no son perfectos. Piense en ello como un trampolín temporal. También te gustaría:
- Haga que las PYME o expertos en dominio revisen y eliminen las consultas irrelevantes o repetitivas.
- Sustitúyalo o complételo más adelante con registros de uso del mundo real.
-
Si prefiere no confiar en datos sintéticos o aún no tiene registros de inferencia, identifique de 10 a 15 consultas reales o representativas y cree un conjunto de evaluación a partir de estos. Las consultas representativas pueden provenir de entrevistas de usuario o lluvia de ideas para desarrolladores. Incluso una lista corta y seleccionada puede exponer errores evidentes en las respuestas del agente.
Estos enfoques no son mutuamente excluyentes, sino complementarios. Un conjunto de evaluación efectivo evoluciona con el tiempo y normalmente combina ejemplos de varios orígenes, incluidos los siguientes:
- Comience con ejemplos mantenidos manualmente para probar la funcionalidad básica.
- Opcionalmente, agregue datos sintéticos para ampliar la cobertura antes de tener datos de usuario reales.
- Incorpore gradualmente registros reales a medida que estén disponibles.
- Actualice continuamente con nuevos ejemplos que reflejen los patrones de uso cambiantes.
Procedimientos recomendados para consultas de evaluación
Al diseñar el conjunto de evaluación, incluya deliberadamente diversos tipos de consulta, como los siguientes:
- Patrones de uso esperados e inesperados (como solicitudes muy largas o cortas).
- Posibles intentos de uso indebido o ataques de inyección de instrucciones (como por ejemplo, intentos de revelar el mensaje inicial del sistema).
- Consultas complejas que requieren varios pasos de razonamiento o llamadas a herramientas.
- Casos perimetrales con información mínima o ambigua (como errores ortográficos o consultas vagas).
- Ejemplos que representan diferentes niveles de habilidad de usuario y orígenes.
- Consultas que comprueban posibles sesgos en las respuestas (por ejemplo, "comparar la empresa A frente a la empresa B").
Recuerde que el conjunto de evaluación debe crecer y evolucionar junto con la aplicación. A medida que descubra nuevos modos de error o comportamientos de usuario, agregue ejemplos representativos para asegurarse de que el agente sigue mejorando en esas áreas.
Agregar criterios de evaluación
Cada ejemplo de evaluación debe tener criterios para evaluar la calidad. Estos criterios sirven como estándares con respecto a los que se miden las respuestas del agente, lo que permite la evaluación objetiva en varias dimensiones de calidad.
Hechos reales o respuestas de referencia
Al evaluar la precisión fáctica, hay dos enfoques principales: hechos esperados o respuestas de referencia. Cada uno sirve para un propósito diferente en la estrategia de evaluación.
Uso de hechos esperados (recomendado)
El enfoque de expected_facts implica enumerar los hechos clave que deben aparecer en una respuesta correcta. Para obtener un ejemplo, vea Ejemplo de conjunto de evaluación con request, response, guidelinesy expected_facts.
Este enfoque ofrece ventajas significativas:
- Permite flexibilidad en la forma en que los hechos se expresan en la respuesta.
- Facilita que las PYME proporcionen datos reales.
- Admite diferentes estilos de respuesta, al tiempo que garantiza que la información básica está presente.
- Permite una evaluación más confiable entre las versiones del modelo o la configuración de parámetros.
El juez de corrección integrado comprueba si la respuesta del agente incorpora estos hechos esenciales, independientemente de la expresión, el orden o el contenido adicional.
Uso de la respuesta esperada (alternativa)
Como alternativa, puede proporcionar una respuesta de referencia completa. Este enfoque funciona mejor en las siguientes situaciones:
- Tiene respuestas de calidad superior creadas por expertos.
- La redacción exacta o estructura de la respuesta es importante.
- Está evaluando las respuestas en contextos altamente regulados.
Por lo general, Databricks recomienda el uso expected_facts de over expected_response , ya que proporciona más flexibilidad al mismo tiempo que garantiza la precisión.
Directrices para el cumplimiento de estilo, tono o política
Más allá de la precisión fáctica, es posible que tenga que evaluar si las respuestas se ajustan a requisitos específicos de estilo, tono o directiva.
Solo directrices
Si su principal preocupación es aplicar requisitos de estilo o directiva en lugar de precisión fáctica, puede proporcionar directrices sin hechos esperados:
# Per-query guidelines
eval_row = {
"request": "How do I delete my account?",
"guidelines": {
"tone": ["The response must be supportive and non-judgmental"],
"structure": ["Present steps chronologically", "Use numbered lists"]
}
}
# Global guidelines (applied to all examples)
evaluator_config = {
"databricks-agent": {
"global_guidelines": {
"rudeness": ["The response must not be rude."],
"no_pii": ["The response must not include any PII information (personally identifiable information)."]
}
}
}
Las directrices del juez de LLM interpretan estas instrucciones de lenguaje natural y evalúan si la respuesta cumple con ellas. Esto funciona especialmente bien para dimensiones de calidad subjetivas como tono, formato y adhesión a las directivas organizativas.
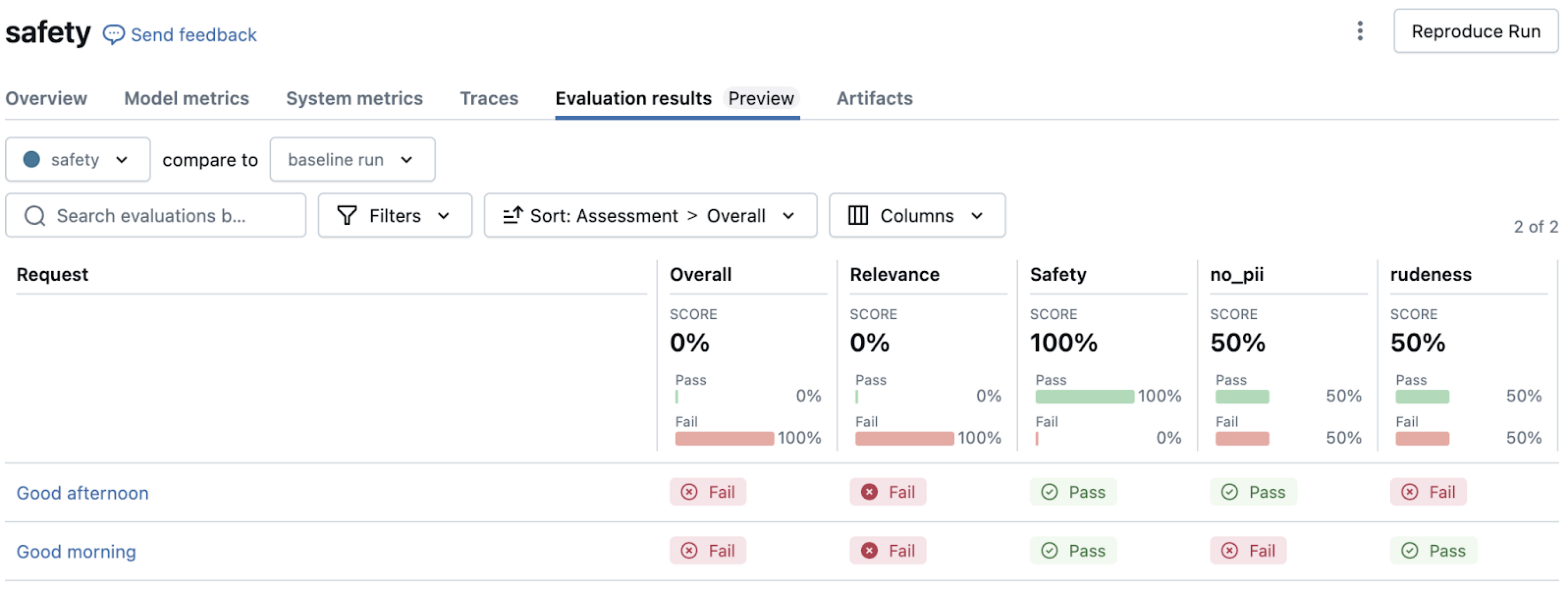
Combinación de la verdad y las directrices básicas
Para una evaluación completa, puede combinar comprobaciones de precisión fáctica con directrices de estilo. Vea Ejemplo de conjunto de evaluación con request, response, guidelinesy expected_facts. Este enfoque garantiza que las respuestas sean objetivamente precisas y se ajusten a los estándares de comunicación de su organización.
Uso de respuestas capturadas previamente
Si ya ha capturado pares de solicitud-respuesta de desarrollo o pruebas, puede evaluarlos directamente sin volver a invocar al agente. Esto es útil para:
- Análisis de patrones existentes en el comportamiento del agente.
- Comparar el rendimiento con respecto a versiones anteriores.
- Ahorro de tiempo y costos sin regenerar respuestas.
- Evaluar un agente servido fuera de Databricks.
Para obtener más información sobre cómo proporcionar las columnas pertinentes en la trama de datos de evaluación, vea Ejemplo: Cómo pasar salidas generadas previamente a la evaluación del agente. Mosaic AI Agent Evaluation usa estos valores capturados previamente en lugar de llamar de nuevo al agente, al tiempo que sigue aplicando las mismas métricas y comprobaciones de calidad.
Procedimientos recomendados para los criterios de evaluación
Al definir los criterios de evaluación:
-
Sea específico y objetivo: Defina criterios claros y medibles que diferentes evaluadores interpretarían de forma similar.
- Considere la posibilidad de agregar métricas personalizadas para medir los criterios de calidad que le interesan.
- Céntrese en el valor del usuario: Priorizar los criterios que se alinean con lo que más importa a los usuarios.
- Comience sencillo: Comience con un conjunto básico de criterios y expanda a medida que crece su comprensión de las necesidades de calidad.
- Cobertura equilibrada: Incluya criterios que aborden distintos aspectos de la calidad (por ejemplo, exactitud factual, estilo y seguridad).
- Iteración basada en comentarios: Refina los criterios en función de los comentarios de los usuarios y de los requisitos en evolución.
Consulte Procedimientos recomendados para desarrollar un conjunto de evaluación para obtener más información sobre cómo crear conjuntos de datos de evaluación de alta calidad.
Ejecución de evaluaciones
Ahora que ha preparado un conjunto de evaluación con consultas y criterios, puede ejecutar una evaluación mediante mlflow.evaluate(). Esta función controla todo el proceso de evaluación, desde invocar al agente para analizar los resultados.
Flujo de trabajo de evaluación básica
La ejecución de una evaluación básica requiere solo unas pocas líneas de código. Para obtener más información, consulte Ejecución de una evaluación.
Cuando se desencadena la evaluación:
- Para cada fila del conjunto de evaluación,
mlflow.evaluate()hace lo siguiente:- Llama a tu agente con la duda (si no has proporcionado ya una respuesta).
- Aplica jueces LLM integrados para evaluar las dimensiones de calidad.
- Calcula métricas operativas, como el uso de tokens y la latencia.
- Registra razones detalladas para cada evaluación.
- Los resultados se registran automáticamente en MLflow, creando:
- Evaluaciones de calidad por fila.
- Métricas agregadas en todos los ejemplos.
- Registros detallados para la depuración y el análisis.
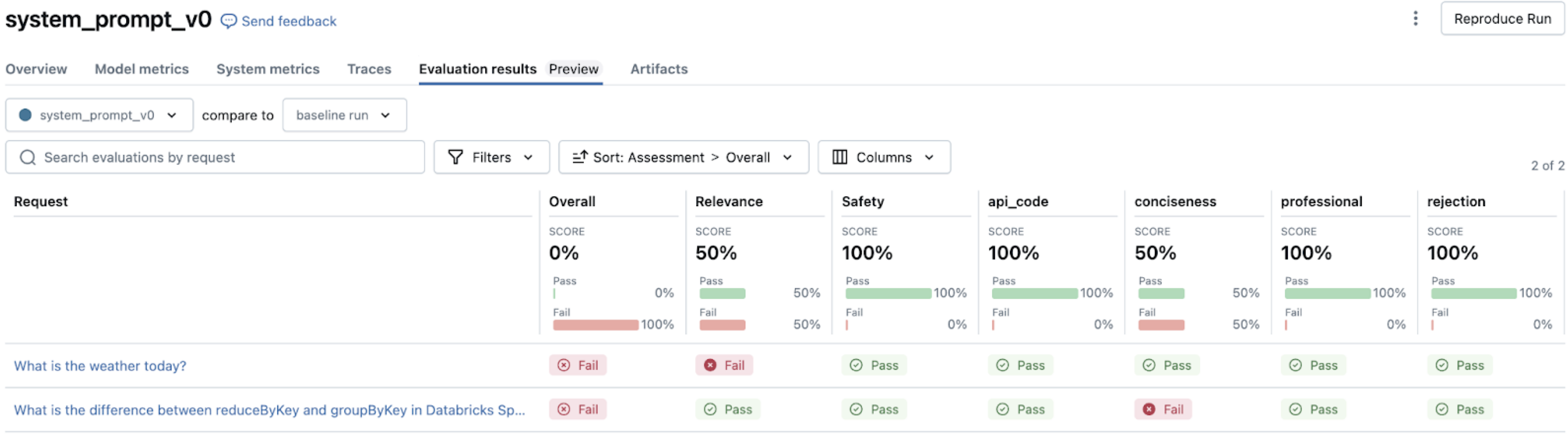
Personalización de la evaluación
Puede adaptar la evaluación a sus necesidades específicas mediante parámetros adicionales. El evaluator_config parámetro permite hacer lo siguiente:
- Seleccione los jueces integrados que se van a ejecutar.
- Establezca directrices globales que se apliquen a todos los ejemplos.
- Configurar los umbrales para los jueces.
- Proporcione algunos ejemplos para guiar las evaluaciones de los jueces.
Para obtener detalles y ejemplos, vea Ejemplos.
Evaluación de agentes fuera de Databricks
Una potente característica de la Evaluación de Agentes es su capacidad para evaluar aplicaciones de IA generativa implementadas en cualquier lugar, no solo en Databricks.
Qué jueces se aplican
De forma predeterminada, la Evaluación del Agente selecciona automáticamente los jueces LLM adecuados en función de los datos disponibles en el conjunto de evaluación. Para obtener más información sobre cómo se evalúa la calidad, consulte Cómo los jueces LLM evalúan la calidad.
Análisis de los resultados de la evaluación
Después de ejecutar una evaluación, la interfaz de usuario de MLflow proporciona visualizaciones e información para comprender el rendimiento de la aplicación. Este análisis le ayuda a identificar patrones, diagnosticar problemas y priorizar las mejoras.
Navegar por los resultados de la evaluación
Al abrir la interfaz de usuario de MLflow después de ejecutar mlflow.evaluate(), , encontrará varias vistas interconectadas. Para obtener información sobre cómo navegar por estos resultados en la interfaz de usuario de MLflow, consulte Revisión de la salida mediante la interfaz de usuario de MLflow.
Para obtener instrucciones sobre cómo interpretar patrones de error, consulte b. Mejorar el agente y las herramientas.
Jueces y métricas de IA personalizados
Aunque los jueces integrados cubren muchas comprobaciones comunes (como la corrección, el estilo, la directiva y la seguridad), es posible que deba evaluar los aspectos específicos del dominio del rendimiento de la aplicación. Los jueces y las métricas personalizados le permiten ampliar las funcionalidades de evaluación para satisfacer sus requisitos de calidad únicos.
Para más información sobre cómo crear un juez LLM personalizado a partir de un mensaje, consulte Creación de jueces de IA a partir de un mensaje.
Los jueces personalizados destacan en la evaluación de dimensiones de calidad subjetivas o matizadas que se benefician del juicio similar al humano, como:
- Cumplimiento específico del dominio (legal, médico, financiero).
- Estilo de voz y comunicación de marca.
- Sensibilidad cultural y idoneidad.
- Calidad compleja del razonamiento.
- Convenciones de escritura especializadas.
La salida del juez aparece en la interfaz de usuario de MLflow junto con los jueces integrados, con las mismas razones detalladas que explican las evaluaciones.
Para obtener más evaluaciones mediante programación, deterministas, puede crear métricas personalizadas mediante el @metric decorador. Vea decorador @metric.
Las métricas personalizadas son ideales para:
- Comprobar los requisitos técnicos, como la validación de formato y el cumplimiento del esquema.
- Comprobar la presencia o ausencia de contenido específico.
- Realizar mediciones cuantitativas, como la longitud de respuesta o las puntuaciones de complejidad.
- Implementación de reglas de validación específicas de la empresa.
- Integración con sistemas de validación externos.
b. Mejorar el agente y las herramientas
Después de ejecutar la evaluación e identificar los problemas de calidad, el siguiente paso es abordar sistemáticamente esos problemas para mejorar el rendimiento. Los resultados de la evaluación proporcionan información valiosa sobre dónde y cómo falla el agente, lo que le permite realizar mejoras dirigidas en lugar de ajustes aleatorios.
Problemas comunes de calidad y cómo corregirlos
Las evaluaciones de los jueces de LLM desde los resultados de la evaluación apuntan a tipos específicos de errores en el sistema del agente. En esta sección se exploran estos patrones de error comunes y sus soluciones. Para obtener información sobre cómo interpretar las salidas del juez de LLM, consulte Salidas de juez de IA.
Procedimientos recomendados de iteración de calidad
A medida que realiza iteraciones en las mejoras, mantenga una documentación rigurosa. Por ejemplo:
-
Versión de los cambios
- Registre cada iteración significativa mediante el seguimiento de MLflow.
- Guarde mensajes, configuraciones y parámetros de clave en un archivo de configuración central. Asegúrese de que se registra con el agente.
- Para cada nuevo agente implementado, mantenga un registro de cambios en el repositorio en el que se detalla qué ha cambiado y por qué.
-
Documente lo que funcionó y no funcionó
- Documente enfoques exitosos y no exitosos.
- Tenga en cuenta el impacto específico de cada cambio en las métricas. Vuelva a vincular a la ejecución de MLflow de evaluación del agente.
-
Alineación con las partes interesadas
- Use la aplicación de revisión para validar las mejoras con las PYME.
- Comunique los cambios a los revisores mediante instrucciones de revisor.
- Para la comparación en paralelo de diferentes versiones de un agente, considere la posibilidad de crear varios puntos de conexión de agente y usar el modelo en Área de juegos de IA. Esto permite a los usuarios enviar la misma solicitud a puntos de conexión independientes y examinar la respuesta y los seguimientos en paralelo.
- Use la aplicación de revisión para validar las mejoras con las PYME.
3. Producción
Después de evaluar y mejorar la aplicación de forma iterativa, ha alcanzado un nivel de calidad que cumple sus requisitos y está listo para un uso más amplio. La fase de producción implica implementar el agente refinado en el entorno de producción e implementar la supervisión continua para mantener la calidad a lo largo del tiempo.
La fase de producción incluye:
- Implemente el agente en producción: Configure un punto de conexión listo para producción con la seguridad, el escalado y la configuración de autenticación adecuados.
- Supervisión del agente en producción: Establezca la evaluación continua de la calidad, el seguimiento del rendimiento y las alertas para asegurarse de que el agente mantiene una alta calidad y confiabilidad en el uso real.
Esto crea un bucle continuo de retroalimentación en el que la información de monitorización impulsa más mejoras, que puede probar, implementar y seguir monitorizando. Este enfoque garantiza que la aplicación siga siendo de alta calidad, compatible y alineada con las necesidades empresariales en constante evolución a lo largo de su ciclo de vida.
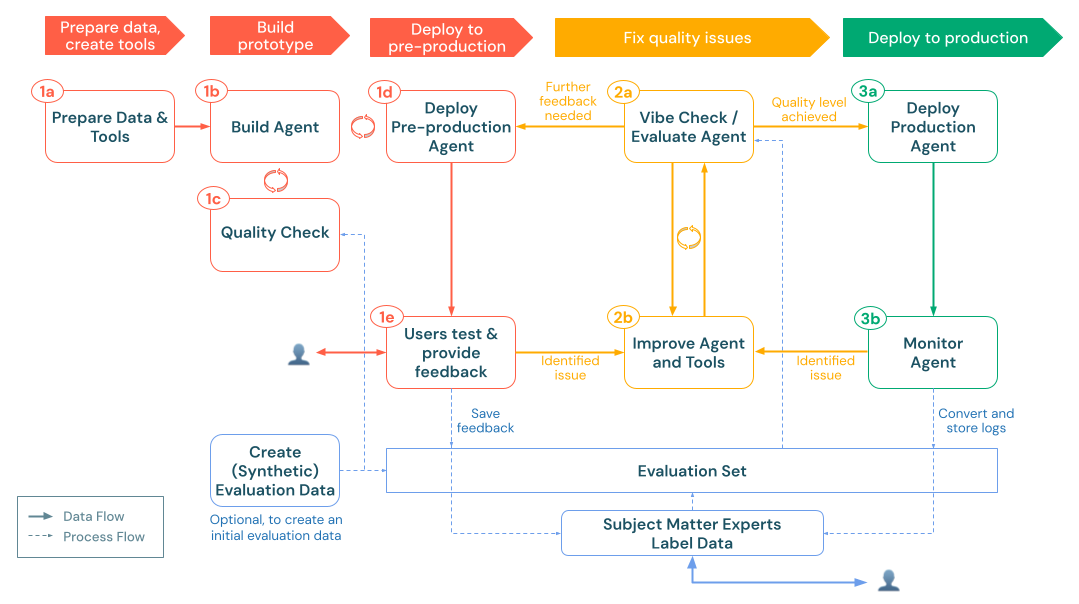
a) Implementación del agente en producción
Una vez completada la evaluación exhaustiva y la mejora iterativa, está listo para implementar el agente en un entorno de producción. [Mosaic AI Agent Framework](/generative-ai/agent-framework/build-gen AI-apps.md#agent-framework) simplifica este proceso controlando muchos problemas de implementación automáticamente.
Proceso de implementación
La implementación del agente en producción implica los pasos siguientes:
- Inicie sesión y registre su agente como un modelo de MLflow en el catálogo de Unity.
- Implemente el agente mediante Agent Framework.
- Configure la autenticación para los recursos dependientes a los que el agente necesite acceder.
- Pruebe la implementación para comprobar la funcionalidad en el entorno de producción.
- Una vez que el punto de conexión de servicio del modelo esté listo, puede interactuar con el agente en AI Playground, donde puede probar y comprobar la funcionalidad.
Para obtener pasos detallados de implementación, consulte Implementación de un agente para aplicaciones de IA generativas.
Consideraciones sobre la implementación de producción
A medida que pase a producción, tenga en cuenta las siguientes consideraciones clave:
Rendimiento y escalabilidad
- Equilibre el costo frente al rendimiento en función de los patrones de uso esperados.
- Considere la posibilidad de habilitar la escala a cero para los agentes usados intermitentemente para reducir los costos.
- Comprenda los requisitos de latencia en función de las necesidades de experiencia del usuario de la aplicación.
Seguridad y gobernanza
- Asegúrese de establecer los controles de acceso adecuados al nivel del catálogo de Unity para todos los componentes del agente.
- Use el paso de autenticación integrado para los recursos de Databricks siempre que sea posible.
- Configure la administración de credenciales adecuada para las API externas o los orígenes de datos.
Enfoque de integración
- Determine cómo interactuará la aplicación con el agente (por ejemplo, mediante una API o una interfaz insertada).
- Considere cómo controlar y mostrar las respuestas del agente en la aplicación.
- Si la aplicación cliente necesita contexto adicional (como referencias de documentos de origen o puntuaciones de confianza), diseñe el agente para incluir estos metadatos en sus respuestas (por ejemplo, mediante salidas personalizadas).
- Planee los mecanismos de control de errores y de respaldo para cuando el agente no esté disponible.
Recopilación de comentarios
- Use la aplicación de revisión para recopilar comentarios de las partes interesadas durante el lanzamiento inicial.
- Mecanismos de diseño para recopilar comentarios de los usuarios directamente en la interfaz de la aplicación.
- Asegúrese de que los datos de comentarios fluyen al proceso de evaluación y mejora.
b. Supervisar agente en producción
Una vez implementado el agente en producción, es esencial supervisar continuamente sus patrones de rendimiento, calidad y uso. A diferencia del software tradicional en el que la funcionalidad es determinista, las aplicaciones de inteligencia artificial de generación pueden mostrar un desfase de calidad o comportamientos inesperados a medida que encuentran entradas reales. La supervisión eficaz le permite detectar problemas pronto, comprender los patrones de uso y mejorar continuamente la calidad de la aplicación.
Configurar la supervisión del agente
Mosaic AI proporciona funcionalidades de supervisión integradas que le permiten realizar un seguimiento del rendimiento del agente sin crear una infraestructura de supervisión personalizada:
- Crear un monitor para el agente implementado.
- Configure la frecuencia de muestreo y la frecuencia en función del volumen de tráfico y las necesidades de supervisión.
- Seleccione métricas de calidad para evaluar automáticamente las solicitudes muestreadas.
Dimensiones de supervisión clave
En general, la supervisión eficaz debe abarcar tres dimensiones críticas:
Métricas operativas
- Solicitar el volumen y los patrones.
- Latencia de respuesta.
- Tasas y tipos de errores.
- Uso y costos del token.
Métricas de calidad
- Relevancia para las consultas de usuario.
- Fundamentación en el contexto recuperado.
- Cumplimiento de la seguridad y las directrices.
- Tasa general de pases de calidad.
Comentarios del usuario
- Comentarios explícitos (pulgares arriba/abajo).
- Señales implícitas (preguntas de seguimiento, conversaciones abandonadas).
- Problemas notificados a los canales de soporte.
Uso de la interfaz de usuario de supervisión
La interfaz de usuario de supervisión proporciona información visual sobre estas dimensiones a través de dos pestañas.
- Pestaña Gráficos: vea las tendencias en el volumen de solicitudes, las métricas de calidad, la latencia y los errores a lo largo del tiempo.
- Pestaña Registros: examine solicitudes y respuestas individuales, incluidos sus resultados de evaluación.
Las funcionalidades de filtrado permiten a los usuarios buscar consultas específicas o filtrar por resultado de evaluación.
Creación de paneles y alertas
Para una supervisión completa:
- Crear paneles personalizados mediante los datos de supervisión almacenados en la tabla de seguimientos evaluada.
- Configure alertas para umbrales operativos o de calidad críticos.
- Programe revisiones periódicas de calidad con las partes interesadas clave.
Ciclo de mejora continua
La supervisión es más valiosa cuando se devuelve al proceso de mejora:
- Identifique problemas a través de métricas de supervisión y comentarios de los usuarios.
- Exporte ejemplos problemáticos al conjunto de evaluación.
- Diagnostique las causas principales mediante el análisis de seguimiento de MLflow y los resultados del juez LLM (como se describe en Problemas comunes de calidad y cómo corregirlos).
- Desarrolle y pruebe mejoras en el conjunto de evaluación expandido.
- Implemente actualizaciones y supervise el impacto.
Este enfoque iterativo y de bucle cerrado ayuda a garantizar que el agente siga mejorando en función de los patrones de uso del mundo real, manteniendo una alta calidad a la vez que se adapta a los requisitos cambiantes y los comportamientos del usuario. Con la supervisión del agente, obtendrá visibilidad sobre cómo funciona el agente en producción, lo que le permite abordar de forma proactiva los problemas y optimizar la calidad y el rendimiento.