Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica está en versión preliminar pública.
En este artículo se describe cómo usar el Editor de Canalizaciones de Lakeflow para desarrollar y depurar canalizaciones ETL (extracción, transformación y carga) en las Canalizaciones Declarativas de Lakeflow Spark (SDP).
Nota:
El Editor de canalizaciones de Lakeflow está habilitado de forma predeterminada. Puede desactivarlo o volver a habilitarlo si se ha desactivado. Consulte Habilitación del Editor de canalizaciones de Lakeflow y supervisión actualizada.
¿Qué es el Editor de canalizaciones de Lakeflow?
El Editor de canalizaciones de Lakeflow es un IDE creado para desarrollar canalizaciones. Combina todas las tareas de desarrollo de canalizaciones en una sola superficie, admite flujos de trabajo de código primero, organización de código basada en carpetas, ejecución selectiva, vistas previas de datos y gráficos de canalización. Integrado con la plataforma Azure Databricks, también permite el control de versiones, las revisiones de código y las ejecuciones programadas.
Introducción a la interfaz de usuario del Editor de canalizaciones de Lakeflow
En la imagen siguiente se muestra el Editor de canalizaciones de Lakeflow:

En la imagen se muestran las siguientes características:
- Explorador de recursos de la canalización: crear, eliminar, renombrar y organizar los recursos de la canalización. También incluye accesos directos a la configuración de canalización.
- Editor de código de varios archivos con pestañas: trabaje en varios archivos de código asociados a una canalización.
- Barra de herramientas específica de la canalización: incluye opciones de configuración de canalización y tiene acciones de ejecución de nivel de canalización.
- Gráfico acíclico dirigido interactivo (DAG): obtenga información general de las tablas, abra la barra inferior de vistas previas de datos y realice otras acciones relacionadas con la tabla.
- Vista previa de datos: inspeccione los datos de las tablas de streaming y las vistas materializadas.
- Información de ejecución a nivel de tabla: obtenga información de ejecución para todas las tablas o una sola tabla en un flujo de trabajo. La información se refiere a la última ejecución de la canalización.
- Panel de problemas: esta característica resume los errores en todos los archivos de la canalización y puede navegar hasta dónde se produjo el error dentro de un archivo específico. Complementa a los indicadores de error con código adjunto.
- Ejecución selectiva: el editor de código tiene características para el desarrollo paso a paso, como la capacidad de actualizar las tablas solo en el archivo actual mediante la acción Ejecutar archivo o una sola tabla.
- Estructura de carpetas de canalización predeterminada: las nuevas canalizaciones incluyen una estructura de carpetas predefinida y código de ejemplo que puede usar como punto de partida para la canalización.
- Creación simplificada de canalizaciones: proporcione un nombre, un catálogo y un esquema donde se deben crear tablas de forma predeterminada y se crea una canalización con la configuración predeterminada. En cualquier momento, puede ajustar la configuración desde la barra de herramientas del editor de flujos.
Creación de una nueva canalización de ETL
Para crear una nueva canalización de ETL mediante el Editor de canalizaciones de Lakeflow, siga estos pasos:
En la parte superior de la barra lateral, haga clic en
 Nuevo y seleccione
Nuevo y seleccione  Canalización de ETL.
Canalización de ETL.En la parte superior, puede asignar un nombre único a la canalización.
Justo bajo el nombre, puede ver el catálogo y el esquema predeterminados que se han elegido para usted. Cambie estos valores para proporcionar a la canalización valores predeterminados diferentes.
El catálogo predeterminado y el esquema predeterminado son donde se leen o escriben conjuntos de datos cuando no se califican los conjuntos de datos con un catálogo o esquema en el código. Consulte Objetos de base de datos en Azure Databricks para más información.
Seleccione la opción preferida para crear una canalización; para ello, elija una de las siguientes opciones:
- Comience con el código de ejemplo en SQL para crear una nueva estructura de canalización y carpeta, incluido el código de ejemplo en SQL.
- Comience con código de ejemplo en Python para crear una nueva estructura de canalización y carpeta, incluido el código de ejemplo en Python.
- Comience con una sola transformación para crear una nueva estructura de canalización y carpeta, con un nuevo archivo de código en blanco.
- Agregue recursos existentes para crear una canalización que pueda asociar con archivos de código existentes en su espacio de trabajo.
Puede tener archivos de código fuente de SQL y Python en la canalización de ETL. Al crear una nueva canalización y elegir un idioma para el código de ejemplo, el lenguaje solo es para el código de ejemplo incluido en la canalización de forma predeterminada.
Al realizar la selección, se le redirigirá a la canalización recién creada.
La canalización de ETL se crea con la siguiente configuración predeterminada:
- Catálogo de Unity
- Canal actual
- Computación sin servidor
- Modo de desarrollo desactivado. Esta configuración solo afecta a las ejecuciones programadas de la canalización. La ejecución de la canalización desde el editor siempre usa el modo de desarrollo de forma predeterminada.
Puede ajustar esta configuración desde la barra de herramientas de canalización.
Como alternativa, puede crear una canalización de ETL desde el explorador del área de trabajo:
- Haga clic en Área de trabajo en el panel izquierdo.
- Seleccione cualquier carpeta, incluidas las carpetas de Git.
- Haga clic en Crear en la esquina superior derecha y haga clic en Canalización ETL.
También puede crear una canalización de ETL desde la página trabajos y canalizaciones:
- En el área de trabajo, haga clic en
 Trabajos y canalizaciones en la barra lateral.
Trabajos y canalizaciones en la barra lateral. - En Nuevo, haga clic en Canalización ETL.
Sugerencia
La CLI de Databricks proporciona comandos para crear, modificar y administrar canalizaciones declarativas de Spark de Lakeflow desde una terminal. Consulte el grupo de comandospipelines.
Apertura de una canalización de ETL existente
Hay varias maneras de abrir una canalización de ETL existente en el Editor de canalizaciones de Lakeflow:
Abra cualquier archivo de código fuente asociado a la canalización:
- Haga clic en Área de trabajo en el panel lateral.
- Vaya a una carpeta con archivos de código fuente para la canalización.
- Haga clic en el archivo de código fuente para abrir la canalización en el editor.
Abra una canalización editada recientemente:
- En el editor, puede ir a otras canalizaciones que ha editado recientemente haciendo clic en el nombre de la canalización en la parte superior del explorador de recursos y seleccionando otra canalización en la lista de recientes que aparece.
- Desde fuera del editor, desde la página Recientes de la barra lateral izquierda, abra una canalización o un archivo configurado como código fuente para una canalización.
Al visualizar una canalización en todo el producto, puede elegir editar la canalización:
- En la página de supervisión de canalización, haga clic en
 Editar canalización.
Editar canalización. - En la página Ejecuciones de trabajos de la barra lateral izquierda, elija la pestaña Trabajos y canalizaciones y haga clic en
 y en Editar canalización.
y en Editar canalización. - Al editar un trabajo y agregar una tarea de canalización, puede hacer clic en el botón
 al elegir una canalización en Canalización.
al elegir una canalización en Canalización.
- En la página de supervisión de canalización, haga clic en
Si va a examinar Todos los archivos en el explorador de recursos y abre un archivo de código fuente desde otra canalización, se muestra un banner en la parte superior del editor, que le pide que abra esa canalización asociada.
Explorador de recursos de canalización
Al editar una canalización, la barra lateral izquierda del área de trabajo usa un modo especial denominado explorador de recursos de canalización. De forma predeterminada, el explorador de recursos de canalización se centra en la raíz de la canalización y en las carpetas y los archivos dentro de la raíz. También puede elegir ver Todos los archivos para ver los archivos fuera de la raíz de la canalización. Las pestañas abiertas en el editor de canalizaciones mientras se edita una canalización específica se recuerdan, y al cambiar a otra canalización, se restauran las pestañas que estaban abiertas la última vez que editó esa canalización.
Nota:
El editor también tiene contextos para editar archivos SQL ( denominados Editor de SQL de Databricks) y un contexto general para editar archivos del área de trabajo que no son archivos SQL ni archivos de canalización. Cada uno de estos contextos recuerda y restaura las pestañas que había abierto la última vez que usó ese contexto. Puede cambiar el contexto desde la parte superior de la barra lateral izquierda. Haga clic en el encabezado para elegir entre Área de trabajo, Editor de SQL, o las canalizaciones editadas recientemente.
Al abrir un archivo desde la página del explorador Área de trabajo, se abre en el editor correspondiente para ese archivo. Si el archivo está asociado a una canalización, es el Editor de canalizaciones de Lakeflow.
Para abrir un archivo que no forma parte de la canalización, pero conservar el contexto de canalización, abra el archivo desde la pestaña Todos los archivos del explorador de recursos.
El explorador de recursos de canalización tiene dos pestañas:
- Canalización: aquí es donde puede encontrar todos los archivos asociados a la canalización. Puede crear, eliminar, cambiar el nombre y organizarlos en carpetas. Esta pestaña también incluye accesos directos para la configuración de canalización y una vista gráfica de las ejecuciones recientes.
- Todos los archivos: todos los demás recursos del área de trabajo están disponibles aquí. Esto puede ser útil para buscar archivos para agregar a la canalización o ver otros archivos relacionados con la canalización, como un archivo YAML que define una agrupación de automatización declarativa.
Puede tener los siguientes tipos de archivos en la canalización:
- Archivos de código fuente: estos archivos forman parte de la definición de código fuente de la canalización, que se puede ver en Configuración. Databricks recomienda almacenar siempre archivos de código fuente dentro de la carpeta raíz de la canalización; De lo contrario, se muestran en una sección de archivo externo en la parte inferior del explorador y tienen un conjunto de características menos enriquecido.
- Archivos de código no fuente: estos archivos se almacenan dentro de la carpeta raíz de la canalización, pero no forman parte de la definición de código fuente de la canalización.
Importante
Debe usar el explorador de recursos de canalización en la pestaña Canalización para administrar archivos y carpetas de la canalización. Esto actualiza correctamente la configuración de la canalización. Mover o cambiar el nombre de archivos y carpetas desde el explorador del área de trabajo o la pestaña Todos los archivos interrumpe la configuración de la canalización y, a continuación, debe resolverlo manualmente en Configuración.
Carpeta raíz
El explorador de recursos de canalización está anclado en una carpeta raíz de canalización. Al crear una nueva canalización, la carpeta raíz de la canalización se crea en la carpeta principal del usuario y se denomina igual que el nombre de la canalización.
Puede cambiar la carpeta raíz en el explorador de recursos de la canalización. Esto resulta útil si ha creado una canalización en una carpeta y más adelante quiere mover todo a otra carpeta. Por ejemplo, ha creado la canalización en una carpeta normal y quiere mover el código fuente a una carpeta git para el control de versiones.
- Haga clic en el menú de desbordamiento de la carpeta raíz.
- Haga clic en Configurar nueva carpeta raíz.
- En Carpeta raíz de canalización , haga clic en
 carpeta y elija otra carpeta como carpeta raíz de canalización.
carpeta y elija otra carpeta como carpeta raíz de canalización. - Haz clic en Guardar.
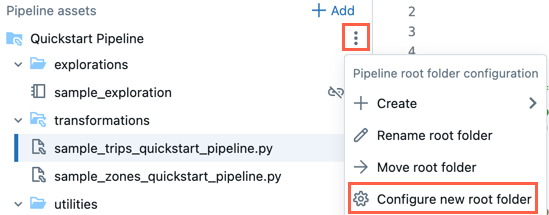
En el ![]() para la carpeta raíz, también puede hacer clic en Cambiar nombre de carpeta raíz para cambiar el nombre de la carpeta. Aquí también puede hacer clic en Mover carpeta raíz para mover la carpeta raíz, por ejemplo, a una carpeta git.
para la carpeta raíz, también puede hacer clic en Cambiar nombre de carpeta raíz para cambiar el nombre de la carpeta. Aquí también puede hacer clic en Mover carpeta raíz para mover la carpeta raíz, por ejemplo, a una carpeta git.
También puede cambiar la carpeta raíz de la canalización en la configuración:
- Haga clic en Configuración.
- En Recursos de código , haga clic en Configurar rutas de acceso.
- Haga clic en para cambiar la carpeta debajo de Carpeta raíz de canalización.
- Haz clic en Guardar.
Nota:
Si cambia la carpeta raíz de la canalización, la lista de archivos mostrada por el explorador de recursos de canalización se ve afectada, ya que los archivos de la carpeta raíz anterior se muestran como archivos externos.
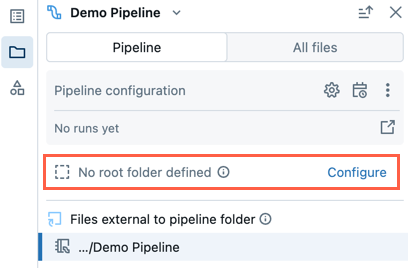
Canalización existente sin carpeta raíz
Una canalización existente creada con la experiencia de edición de cuadernos heredada no tendrá configurada una carpeta raíz. Cuando abra una canalización que no tenga configurada una carpeta raíz, se le pedirá que cree una carpeta raíz y organice los archivos de origen dentro de ella.
Puede descartarlo y seguir editando la canalización sin establecer una carpeta raíz.
Si más adelante desea configurar la carpeta raíz de la canalización, siga estos pasos:
- En el explorador de activos de canalización, haga clic en Configurar.
- Haga clic en para seleccionar la carpeta raíz en Carpeta raíz de canalización.
- Haz clic en Guardar.
Estructura de carpetas predeterminada
Al crear una canalización, se crea una estructura de carpetas predeterminada. Esta es la estructura recomendada para organizar los archivos de código fuente y los archivos sin código fuente de su pipeline, como se describe a continuación.
Se crea un pequeño número de archivos de código de ejemplo en esta estructura de carpetas.
| Nombre de carpeta | Ubicación recomendada para estos tipos de archivos |
|---|---|
<pipeline_root_folder> |
Carpeta raíz que contiene todas las carpetas y archivos de la canalización. |
transformations |
Archivos de código fuente, como python o archivos de código SQL con definiciones de tabla. |
explorations |
Archivos de código no fuente, como cuadernos, consultas y archivos de código usados para el análisis de datos explorativos. |
utilities |
Archivos de código no fuente con módulos de Python que se pueden importar desde otros archivos de código. Si elige SQL como lenguaje para el código de ejemplo, esta carpeta no se crea. |
Puede cambiar el nombre de los nombres de carpeta o cambiar la estructura para que se ajuste al flujo de trabajo. Para agregar una nueva carpeta de código fuente, siga estos pasos:
- Haga clic en Agregar en el explorador de recursos de canalización.
- Haga clic en Crear carpeta de código fuente de canalización.
- Escriba un nombre de carpeta y haga clic en Crear.
Archivos de código fuente
Los archivos de código fuente forman parte de la definición de código fuente de la canalización. Al ejecutar la canalización, se evalúan estos archivos. Los archivos y carpetas que forman parte de la definición de código fuente tienen un icono especial con un mini icono de Pipeline superpuesto.
Para agregar un nuevo archivo de código fuente, siga estos pasos:
- Haga clic en Agregar en el explorador de recursos de canalización.
- Haga clic en Transformación.
- Escriba un nombre para el archivo y seleccione Python o SQL como lenguaje.
- Haga clic en Crear.
También puede hacer clic en ![]() de cualquier carpeta del explorador de recursos de canalización para agregar un archivo de código fuente.
de cualquier carpeta del explorador de recursos de canalización para agregar un archivo de código fuente.
Una transformations carpeta para el código fuente se crea de forma predeterminada al crear una nueva canalización. Esta carpeta es la ubicación recomendada para el código fuente de canalización, como los archivos de código python o SQL con definiciones de tabla de canalización.
Archivos de código no fuente
Los archivos de código no fuente se almacenan dentro de la carpeta raíz de la canalización, pero no forman parte de la definición de código fuente de la canalización. Estos archivos no se evalúan al ejecutar la canalización. Los archivos de código no fuente no pueden ser archivos externos.
Puede usarlo para los archivos relacionados con el trabajo en la canalización que desea almacenar junto con el código fuente. Por ejemplo:
- Cuadernos que se usan para las exploraciones ad hoc ejecutadas en canalizaciones declarativas de Spark que no son de Lakeflow se calculan fuera del ciclo de vida de una canalización.
- Los módulos de Python no deben evaluarse con su código fuente, a menos que los importe explícitamente dentro de sus archivos de código fuente.
Para agregar un nuevo archivo de código no fuente, siga estos pasos:
- Haga clic en Agregar en el explorador de recursos de canalización.
- Haga clic en Exploración o Utilidad.
- Escriba un nombre para el archivo.
- Haga clic en Crear.
También puede hacer clic en el ![]() para acceder a la carpeta raíz de la canalización o un archivo que no sea código fuente, e incluir archivos que no sean código fuente en la carpeta.
para acceder a la carpeta raíz de la canalización o un archivo que no sea código fuente, e incluir archivos que no sean código fuente en la carpeta.
Al crear una nueva canalización, las siguientes carpetas para archivos de código no fuente se crean de forma predeterminada:
| Nombre de carpeta | Description |
|---|---|
explorations |
Esta carpeta es la ubicación recomendada para cuadernos, consultas, paneles y otros archivos, que luego se ejecutan en canalizaciones declarativas de Spark no pertenecientes a Lakeflow, tal como se haría normalmente fuera del ciclo de vida de ejecución de una canalización. |
utilities |
Esta carpeta es la ubicación recomendada para los módulos de Python que se pueden importar desde otros archivos a través de importaciones directas expresadas como from <filename> import, siempre que su carpeta principal esté jerárquicamente en la carpeta raíz. |
También puede importar módulos de Python ubicados fuera de la carpeta raíz, pero en ese caso, debe anexar la ruta de acceso de carpeta a sys.path en el código de Python:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
Archivos externos
La sección Archivos externos del explorador de canalización muestra los archivos de código fuente fuera de la carpeta raíz.
Para mover un archivo externo a la carpeta raíz, como la transformations carpeta , siga estos pasos:
- Haga clic en del archivo en el explorador de recursos y haga clic en Mover.
- Elija la carpeta a la que desea mover el archivo y haga clic en Mover.
Archivos asociados a varias canalizaciones
Se muestra una notificación en el encabezado del archivo si un archivo está asociado a más de una canalización. Tiene un recuento de canalizaciones asociadas y permite cambiar a las otras.
sección Todos los archivos
Además de la sección Pipeline, hay una sección Todos los archivos, donde puede abrir cualquier archivo en el área de trabajo. Aquí puede:
- Abra archivos fuera de la carpeta raíz en una pestaña sin salir del Editor de canalizaciones de Lakeflow.
- Vaya a los archivos de código fuente de otra canalización y ábralos. Esto abre el archivo en el editor y le proporciona un banner con la opción de cambiar el foco en el editor a esta segunda canalización.
- Mueva los archivos a la carpeta raíz de la canalización.
- Incluya archivos fuera de la carpeta raíz en la definición de código fuente de la canalización.
Edición de archivos de origen de canalización
Al abrir un archivo de código fuente de canalización desde el explorador del área de trabajo o el explorador de recursos de canalización, se abre en una pestaña del editor de canalizaciones de Lakeflow. Al abrir más archivos, se abren pestañas independientes, lo que le permite editar varios archivos a la vez.
Nota:
Al abrir un archivo que no está asociado a una canalización desde el explorador del área de trabajo, se abrirá el editor en un contexto diferente (ya sea el editor general del área de trabajo o, para los archivos SQL, el Editor de SQL).
Al abrir un archivo que no sea de canalización desde la pestaña Todos los archivos del explorador de recursos de canalización, se abre en una nueva pestaña en el contexto de la canalización.
El código fuente del pipeline incluye varios archivos. De forma predeterminada, los archivos de origen están en la carpeta de transformaciones del explorador de recursos de canalización. Los archivos de código fuente pueden ser archivos de Python (*.py) o SQL (*.sql). El origen puede incluir una combinación de archivos python y SQL en una sola canalización, y el código de un archivo puede hacer referencia a una tabla o vista definida en otro archivo.
También puede incluir archivos markdown (*.md) en la carpeta tranformations . Los archivos Markdown se pueden usar para la documentación o las notas, pero se omiten al ejecutar una actualización de canalización.
Las siguientes características son específicas del Editor de canalizaciones de Lakeflow:
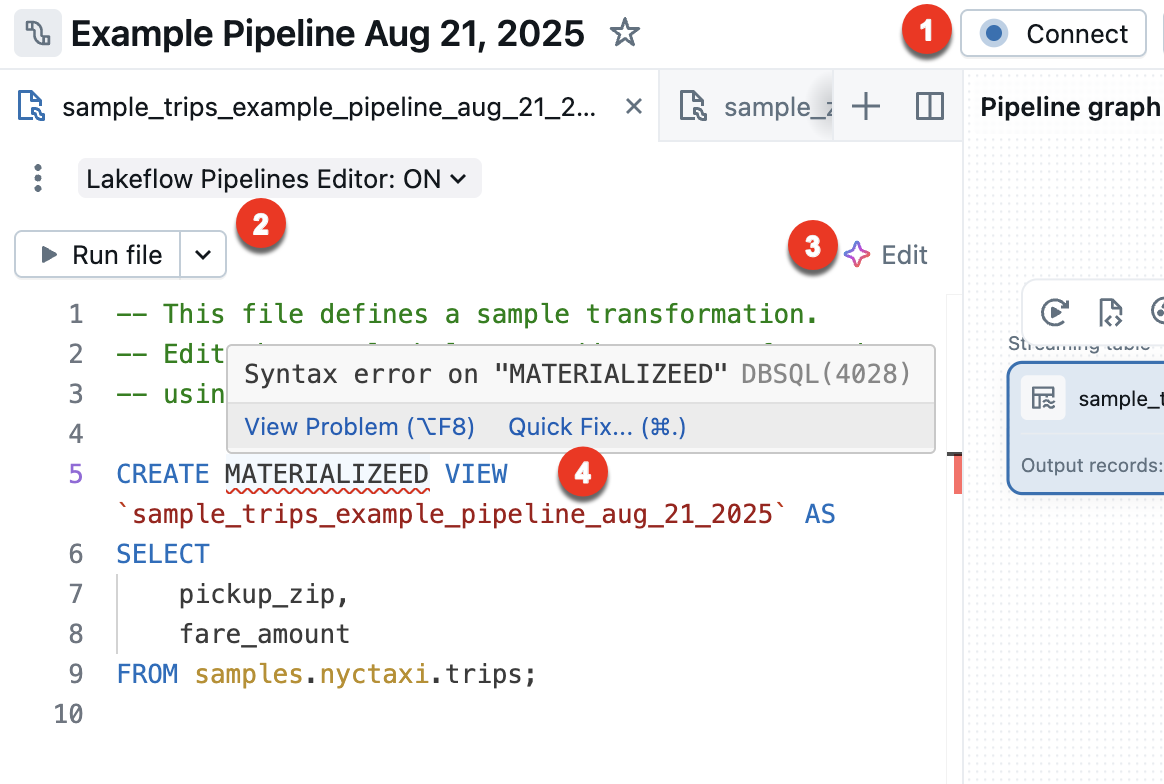
Conectar - Conéctese a computación sin servidor o computación clásica para ejecutar la canalización. Todos los archivos asociados a la canalización usan la misma conexión de proceso, por lo que, una vez conectado, no es necesario conectarse a otros archivos de la misma canalización. Para obtener más información sobre las opciones de proceso, consulte Opciones de configuración de proceso.
En el caso de los archivos que no son de canalización, como un cuaderno exploratorio, la opción conectar está disponible, pero se aplica solo a ese archivo en particular.
Ejecutar archivo: ejecute el código para actualizar las tablas definidas en este archivo de código fuente. En la sección siguiente se describen distintas formas de ejecutar el código de canalización.
Editar : use el código de Genie para editar o agregar código en el archivo.
Corrección rápida : cuando se produce un error en el código, use Genie Code para corregir el error.
El panel inferior también se ajusta, en función de la pestaña actual. La visualización de la información de canalización en el panel inferior siempre está disponible. Los archivos asociados que no son de canalización, como los archivos del editor de SQL, también muestran su salida en el panel inferior en una pestaña independiente. En la imagen siguiente se muestra un selector de pestañas vertical para cambiar el panel inferior entre ver la información de canalización o la información del cuaderno seleccionado.
Ejecución del código de canalización
Tiene cuatro opciones para ejecutar el código de canalización:
Ejecutar todos los archivos de código fuente en el pipeline
Haga clic en Ejecutar canalización o En Ejecutar canalización con actualización de tabla completa para ejecutar todas las definiciones de tabla en todos los archivos definidos como código fuente de canalización. Para más información sobre los tipos de actualización, consulte Semántica de actualización de canalización.
También puede hacer clic en Ejecución seca para validar la canalización sin actualizar ningún dato.
Ejecución del código en un único archivo
Haga clic en Ejecutar archivo o En Ejecutar archivo con actualización de tabla completa para ejecutar todas las definiciones de tabla en el archivo actual. No se evalúan otros archivos en el pipeline.
Esta opción es útil para la depuración al editar e iterar rápidamente en un archivo. Hay efectos secundarios cuando solo se ejecuta el código en un solo archivo.
- Cuando no se evalúan otros archivos, no se encuentran errores en esos archivos.
- Las tablas materializadas en otros archivos usan la materialización más reciente de la tabla, incluso si hay datos de origen más recientes.
- Podría producirse errores si aún no se ha materializado una tabla a la que se hace referencia.
- El DAG puede ser incorrecto o estar desconectado para las tablas en otros archivos que no se han materializado. Azure Databricks realiza un mejor esfuerzo para mantener el grafo correcto, pero no evalúa otros archivos para hacerlo.
Cuando haya terminado de depurar y editar un archivo, Databricks recomienda ejecutar todos los archivos de código fuente de la canalización para comprobar que la canalización funciona de un extremo a otro antes de colocar la canalización en producción.
Ejecución del código para una sola tabla
Junto a la definición de una tabla en el archivo de código fuente, haga clic en el icono Ejecutar tabla
 tabla y, a continuación, elija Actualizar tabla o Tabla de actualización completa en la lista desplegable. La ejecución del código para una sola tabla tiene efectos secundarios similares a la ejecución del código en un único archivo.
tabla y, a continuación, elija Actualizar tabla o Tabla de actualización completa en la lista desplegable. La ejecución del código para una sola tabla tiene efectos secundarios similares a la ejecución del código en un único archivo.
Nota:
La ejecución del código para una sola tabla está disponible para las tablas de streaming y las vistas materializadas. No se admiten sumideros ni vistas.
Ejecución del código para un conjunto de tablas
Puede seleccionar tablas del DAG para crear una lista de tablas que se van a ejecutar. Mantenga el puntero sobre la tabla en el DAG, haga clic en el
y elija Seleccionar tabla para actualizar. Después de elegir las tablas que desea actualizar, elija la opción Ejecutar o Ejecutar con actualización completa en la parte inferior del DAG.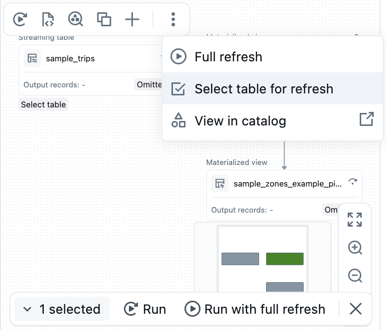
Gráfico de canalización, gráfico acíclico dirigido (DAG)
Después de ejecutar o validar todos los archivos de código fuente de la canalización, verá un grafo acíclico dirigido (DAG), denominado grafo de canalización. El gráfico muestra el gráfico de dependencias de la tabla. Cada nodo tiene estados diferentes a lo largo del ciclo de vida de la canalización, como validado, en ejecución o error.
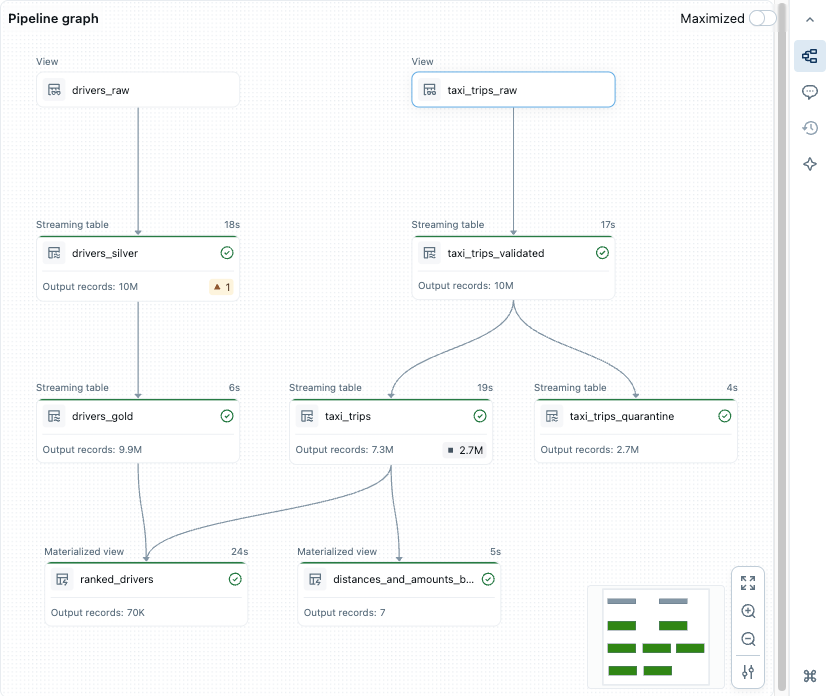
Para activar y desactivar el gráfico, haga clic en el icono del gráfico del panel derecho. También puede maximizar el gráfico. Hay opciones adicionales en la parte inferior derecha, incluidas las opciones de zoom y el ![]() Más opciones para mostrar el gráfico en un diseño vertical o horizontal.
Más opciones para mostrar el gráfico en un diseño vertical o horizontal.
Al mantener el puntero sobre un nodo se muestra una barra de herramientas con opciones, incluida la actualización de la consulta. Al hacer clic con el botón derecho en un nodo se proporcionan las mismas opciones, en un menú contextual.
Al hacer clic en un nodo se muestra la vista previa de datos y la definición de tabla. Al editar un archivo, las tablas definidas en ese archivo se resaltan en el gráfico.
Vistas previas de datos
En la sección vista previa de datos se muestran los datos de ejemplo de una tabla seleccionada.
Verá una vista previa de los datos de la tabla al hacer clic en un nodo en el gráfico acíclico dirigido (DAG).
Si no se ha seleccionado ninguna tabla, vaya a la sección Tablas y haga clic en Ver vista previa de datos![]() Si ha elegido una tabla, haga clic en Todas las tablas para volver a todas las tablas.
Si ha elegido una tabla, haga clic en Todas las tablas para volver a todas las tablas.
Al obtener una vista previa de los datos de la tabla, puede filtrar o ordenar los datos directamente. Si desea realizar análisis más complejos, puede usar o crear un cuaderno en la carpeta Exploraciones (suponiendo que mantuvo la estructura de carpetas predeterminada). De forma predeterminada, el código fuente de esta carpeta no se ejecuta durante una actualización de canalización, por lo que puede crear consultas sin afectar a la salida de la canalización.
Perspectivas de ejecución
Puede ver la información de ejecución de la tabla sobre la actualización de canalización más reciente en los paneles en la parte inferior del editor.
| Panel | Description |
|---|---|
| Tables | Enumera todas las tablas con sus estados y métricas. Si selecciona una tabla, verá las métricas y el rendimiento de esa tabla y una pestaña para la vista previa de datos. |
| Performance | Historial de consultas y perfiles para todos los flujos de esta canalización. Puede acceder a las métricas de ejecución y a los planes de consulta detallados durante y después de la ejecución. Consulte Historial de consultas de Access para canalizaciones para obtener más información. |
| Panel de Problemas | Haga clic en el panel para obtener una vista simplificada de errores y advertencias para la canalización. Puede hacer clic en una entrada para ver más detalles y, a continuación, ir al lugar en el código donde se produjo el error. Si el error está en un archivo distinto del que se muestra actualmente, se le redirigirá al archivo donde se encuentra el error. Haga clic en Ver detalles para ver la entrada del registro de eventos correspondiente para obtener detalles completos. Haga clic en Ver registros para ver el registro de eventos completo. Los indicadores de error asociados al código se muestran para los errores vinculados a una parte específica del código. Para obtener más detalles, haga clic en el icono de error o mantenga el puntero sobre la línea roja. Aparece una ventana emergente con más información. A continuación, puede hacer clic en Corrección rápida para mostrar un conjunto de acciones para solucionar el error. |
| Registro de eventos | Todos los eventos desencadenados durante la última ejecución de canalización. Haga clic en Ver registros o en cualquier entrada de la bandeja de problemas. |
Configuración de canalización
Puede configurar la canalización desde el editor de canalización. Puede realizar cambios en la configuración de canalización, la programación o los permisos.
Se puede acceder a cada uno de ellos desde un botón en el encabezado del editor o desde iconos en el explorador de recursos (la barra lateral izquierda).
Configuración (o elija
 en el explorador de recursos):
en el explorador de recursos):Puede editar la configuración de la canalización desde el panel de configuración, incluida la información general, la configuración de carpeta raíz y el código fuente, la configuración de proceso, las notificaciones, la configuración avanzada, etc.
Programación (o elija
 en el explorador de recursos):
en el explorador de recursos):Puede crear uno o más horarios para su canalización desde el cuadro de diálogo de programación. Por ejemplo, si desea ejecutarlo diariamente, puede establecerlo aquí. Crea un trabajo para ejecutar la canalización en el horario que elija. Puede agregar una nueva programación o quitar una programación existente del cuadro de diálogo de programación.
Compartir (o, en el menú del
del explorador de recursos, elija el  )
)Puede administrar los permisos en la canalización para los usuarios y grupos desde el cuadro de diálogo de permisos de la canalización.
Registro de eventos
Puede publicar el registro de eventos de una canalización en el catálogo de Unity. De forma predeterminada, el registro de eventos de la canalización se muestra en la interfaz de usuario y es accesible para consultarlo el propietario.
- Abra Configuración.
- Haga clic en el
 Flecha junto a Configuración avanzada.
Flecha junto a Configuración avanzada. - Haga clic en Editar configuración avanzada.
- En Registros de eventos, haga clic en Publicar en el catálogo.
- Proporcione un nombre, un catálogo y un esquema para el registro de eventos.
- Haz clic en Guardar.
Los eventos de canalización se publican en la tabla que especificaste.
Para más información sobre el uso del registro de eventos de canalización, consulte Consulta del registro de eventos.
Entorno de canalización
Puede crear un entorno para el código fuente agregando dependencias en Configuración.
- Abra Configuración.
- En Entorno, haga clic en Editar entorno.
- Seleccione Agregue dependencia para agregar una dependencia, como si lo agregara a un
requirements.txtarchivo. Para obtener más información sobre las dependencias, consulte Agregar dependencias al cuaderno.
Databricks recomienda fijar la versión con ==. Consulte Paquete PyPi.
El entorno se aplica a todos los archivos de código fuente de la canalización.
Notificaciones
Puede agregar notificaciones mediante la configuración de canalización.
- Abra Configuración.
- En la sección Notificaciones , haga clic en Agregar notificación.
- Agregue una o varias direcciones de correo electrónico y los eventos que desea que se envíen.
- Haga clic en Agregar notificación.
Nota:
Cree respuestas personalizadas a eventos, incluidas las notificaciones o el control personalizado, mediante ganchos de eventos de Python.
Supervisión de canalizaciones
Azure Databricks también proporciona características para supervisar las canalizaciones en ejecución. El editor muestra los resultados y la información de ejecución sobre la ejecución más reciente. Está optimizado para ayudarle a iterar de forma eficaz mientras desarrolla la canalización de forma interactiva.
La página de monitoreo de la tubería permite ver las ejecuciones históricas, lo que resulta útil cuando una tubería se ejecuta según un horario mediante una tarea.
Nota:
Hay una experiencia de supervisión predeterminada y una experiencia de supervisión en versión preliminar actualizada. En la sección siguiente se describe cómo habilitar o deshabilitar la experiencia de supervisión en versión preliminar. Para obtener información sobre ambas experiencias, consulte Supervisión de canalizaciones en la interfaz de usuario.
La función de supervisión está disponible en el botón Trabajos y canalizaciones a la izquierda del área de trabajo. También puede ir directamente a la página de supervisión desde el editor haciendo clic en los resultados de la ejecución en el explorador de activos de canalización.
Para obtener más información sobre la página de supervisión, consulte Supervisión de canalizaciones en la interfaz de usuario. La interfaz de usuario de supervisión incluye la capacidad de volver al Editor de canalizaciones de Lakeflow seleccionando Editar canalización en el encabezado de la interfaz de usuario.
Habilitación del Editor de canalizaciones de Lakeflow y supervisión actualizada
La versión preliminar del Editor de canalizaciones de Lakeflow está habilitada de forma predeterminada. Puede deshabilitarlo o volver a habilitarlo con las instrucciones siguientes. Cuando la versión preliminar del Editor de canalizaciones de Lakeflow está habilitada, también puede habilitar la experiencia de supervisión actualizada (versión preliminar).
La versión preliminar debe estar habilitada estableciendo la opción Editor de canalizaciones de Lakeflow para el área de trabajo. Consulte Administración de versiones preliminares de Azure Databricks para más información sobre cómo editar opciones.
Una vez habilitada la versión preliminar, puede habilitar el Editor de canalizaciones de Lakeflow de varias maneras:
Al crear una nueva canalización ETL, habilite el editor con el interruptor Editor de canalizaciones de Lakeflow en Canalizaciones declarativas de Spark de Lakeflow.
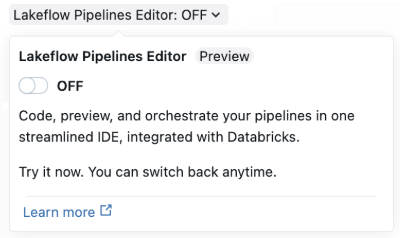
La página de configuración avanzada de la canalización se usa la primera vez que se habilita el editor. La ventana de creación de canalización simplificada se usa la próxima vez que cree una nueva canalización.
Para un canalización existente, abra un cuaderno usado en un canalización y active el conmutador Editor de canalizaciones de Lakeflow en el encabezado. También puede ir a la página de supervisión de canalizaciones y hacer clic en Configuración para habilitar el Editor de canalizaciones de Lakeflow.
Puede habilitar el Editor de canalizaciones de Lakeflow desde la configuración del usuario:
- Haga clic en el distintivo de usuario en el área superior derecha del área de trabajo y, a continuación, haga clic en Configuración y desarrollador.
- Habilite el Editor de canalizaciones de Lakeflow.
Una vez habilitado el interruptor del Editor de canalizaciones de Lakeflow, todas las canalizaciones ETL utilizan el Editor de canalizaciones de Lakeflow de forma predeterminada. Puede activar y desactivar el Editor de canalizaciones de Lakeflow desde el editor.
Nota:
Si deshabilita el nuevo editor de canalización, resulta útil dejar comentarios que describen por qué lo ha desactivado. Hay un botón Enviar comentarios en el interruptor para los comentarios que tenga en el nuevo editor.
Habilitación de la nueva página de supervisión de canalización
Importante
Esta característica está en versión preliminar pública.
Como parte de la versión preliminar del Editor de canalizaciones de Lakeflow, también puede habilitar una nueva página de supervisión de canalización para una canalización. La versión preliminar del Editor de canalizaciones de Lakeflow debe estar habilitada para habilitar la página de supervisión de canalizaciones. Cuando la vista previa del editor está habilitada, la nueva página de supervisión también está habilitada de forma predeterminada.
Haga clic en Trabajos y canalizaciones.
Haga clic en el nombre de cualquier canalización para ver los detalles de la canalización.
En la parte superior de la página, habilite la interfaz de usuario de monitoreo actualizada con el conmutador Nueva página de canalización.
Agente de ingeniería de datos
Importante
Esta característica está en versión preliminar pública.
El Editor de canalizaciones de Lakeflow se integra con el agente de ingeniería de datos de código de Genie, que puede generar, modificar y depurar canalizaciones declarativas de Lakeflow Spark directamente desde lenguaje natural. Para obtener más información, consulte Uso de Genie Code para el desarrollo de canalizaciones.
Limitaciones y problemas conocidos
Consulte las siguientes limitaciones y problemas conocidos para el editor de canalizaciones ETL en Canalizaciones declarativas de Spark de Lakeflow:
La barra lateral del explorador del área de trabajo no se centra en la canalización si comienza abriendo un archivo en la
explorationscarpeta o en un cuaderno, ya que estos archivos o cuadernos no forman parte de la definición de código fuente de la canalización.Para entrar en el modo de enfoque de la canalización en el navegador del área de trabajo, abra un archivo asociado a la canalización.
Las vistas preliminares de datos no están disponibles para las vistas habituales.
Los módulos de Python no se encuentran desde dentro de una UDF, aunque estén en la carpeta raíz o estén en
sys.path. Puede acceder a estos módulos anexando la ruta de acceso asys.pathdesde dentro de la UDF, por ejemplo:sys.path.append(os.path.abspath(“/Workspace/Users/path/to/modules”))%pip installno se admite desde archivos (el tipo de recurso predeterminado con el nuevo editor). Puede agregar dependencias en la configuración. Consulte Entorno de canalización.Como alternativa, puede seguir usando
%pip installdesde un cuaderno asociado a una canalización, en su definición del código fuente.
Preguntas más frecuentes
¿Por qué usar archivos y no cuadernos para el código fuente?
La ejecución de cuadernos basada en celdas no es compatible con las canalizaciones. Las características estándar de los cuadernos se deshabilitan o cambian al trabajar con canalizaciones, lo que provoca confusión para los usuarios familiarizados con el comportamiento del cuaderno.
En el Editor de canalizaciones de Lakeflow, el editor de archivos se usa como base para un editor de primera clase para las canalizaciones. Las características están destinadas explícitamente a las tuberías, como Tabla de ejecución
, en lugar de sobrecargar características conocidas con un comportamiento diferente.¿Puedo seguir usando cuadernos como código fuente?
Sí, puede hacerlo. Sin embargo, algunas características, como Run table
o Run file, no están presentes.Si tiene una canalización existente mediante cuadernos, sigue funcionando en el nuevo editor. Sin embargo, Databricks recomienda cambiar a archivos para las canalizaciones nuevas.
¿Cómo puedo agregar código existente a una canalización recién creada?
Puede agregar archivos de código fuente existentes a una nueva canalización. Para agregar una carpeta con archivos existentes, siga estos pasos:
- Haga clic en Configuración.
- En Código fuente , haga clic en Configurar rutas de acceso.
- Haga clic en Agregar ruta de acceso y elija la carpeta de los archivos existentes.
- Haz clic en Guardar.
También puede agregar archivos individuales:
- Haga clic en Todos los archivos en el explorador de activos del flujo de trabajo.
- Navegue hasta su archivo, haga clic en y luego en Incluir en la canalización.
Considere la posibilidad de mover estos archivos a la carpeta raíz de la canalización. Si se queda fuera de la carpeta raíz de la canalización, se muestran en la sección Archivos externos .
¿Puedo administrar el código fuente de canalización en Git?
Puede administrar el origen de la canalización en Git si elige una carpeta de Git al crear inicialmente la canalización.
Nota:
La administración del origen en una carpeta de Git agrega control de versiones para el código fuente. Sin embargo, para controlar las versiones de su configuración, Databricks recomienda usar Bundles de Automatización Declarativa para definir la configuración de la canalización en archivos de configuración de los bundles que se pueden almacenar en Git (u otro sistema de control de versiones). Para obtener más información, consulte ¿Qué son los conjuntos de automatización declarativos?.
Si no ha creado la canalización en una carpeta de Git inicialmente, puede mover el origen a una carpeta de Git. Databricks recomienda usar la acción del editor para mover toda la carpeta raíz a una carpeta git. Esto actualiza todas las configuraciones según corresponda. Consulte Carpeta raíz.
Para mover la carpeta raíz a una carpeta de Git en el explorador de recursos de canalización:
- Haga clic en para la carpeta raíz.
- Haga clic en Mover carpeta raíz.
- Elija una nueva ubicación para la carpeta raíz y haga clic en Mover.
Consulte la sección Carpeta raíz para obtener más información.
Después del traslado, verá el icono de Git conocido junto al nombre de la carpeta raíz.
Importante
Para mover la carpeta raíz de la canalización, use el explorador de recursos de canalización y los pasos anteriores. Si lo mueve de cualquier otra manera, se interrumpen las configuraciones de la canalización y debe configurar manualmente la ruta de la carpeta correcta en Ajustes.
- Haga clic en
¿Puedo tener varias canalizaciones en la misma carpeta raíz?
Puede, pero Databricks solo recomienda tener una sola canalización por carpeta raíz.
¿Cuándo debo correr una carrera seca?
Haga clic en Ejecutar en seco para comprobar el código sin actualizar las tablas.
¿Cuándo debo usar vistas temporales y cuándo debo usar vistas materializadas en mi código?
Use vistas temporales cuando no desee materializar los datos. Por ejemplo, se trata de un paso de una secuencia de pasos para preparar los datos antes de que esté listo para materializarse mediante una tabla de streaming o una vista materializada registrada en el catálogo.