Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Cree una nueva canalización de Lakeflow para la orquestación de datos con Auto Loader y, a continuación, amplíe la canalización de ejemplo mediante la limpieza de los datos y la creación de una consulta para encontrar los 100 usuarios principales.
En este tutorial, aprenderá a usar el Editor de canalizaciones de Lakeflow para:
- Cree una nueva canalización con la estructura de carpetas predeterminada y comience con un conjunto de archivos de ejemplo.
- Defina restricciones de calidad de datos mediante expectativas.
- Utiliza las características del editor para ampliar el flujo de trabajo con una nueva transformación para realizar análisis de tus datos.
Requisitos
Antes de comenzar este tutorial, debe:
- Inicie sesión en un área de trabajo de Azure Databricks.
- Tener habilitado el catálogo de Unity para el área de trabajo.
- Tener permiso para crear un recurso de computación o acceso a un recurso de computación.
- Tener permisos para crear un nuevo esquema en un catálogo. Los permisos necesarios son
ALL PRIVILEGESoUSE CATALOGyCREATE SCHEMA. - Para obtener el conjunto completo de privilegios necesarios para crear, ejecutar, actualizar y ver canalizaciones y su salida, consulte Administración de identidades, permisos y privilegios para canalizaciones.
Paso 1: crear una canalización
En este paso, creará una canalización mediante la estructura de carpetas predeterminada y los ejemplos de código. Los ejemplos de código hacen referencia a la users tabla en el wanderbricks origen de datos de ejemplo.
En el área de trabajo de Azure Databricks, haga clic en
 Nuevo y después en
Nuevo y después en  Canalización de ETL. Se abrirá el editor de canalizaciones con un nombre de canalización predeterminado, como
Canalización de ETL. Se abrirá el editor de canalizaciones con un nombre de canalización predeterminado, como New Pipeline <date> <time>.(Opcional) Seleccione el nombre y escriba un nombre descriptivo para la canalización.
(Opcional) A la derecha del nombre, haga clic en el catálogo y el esquema para establecer valores predeterminados diferentes.
(Opcional) En el archivo de origen
my_transformationcreado automáticamente, seleccione Python o SQL en la lista desplegable idioma para establecer el idioma del archivo.Haga clic en
 Use el código de ejemplo.
Use el código de ejemplo.El código de ejemplo del idioma seleccionado aparece en el
my_transformationarchivo de origen de latransformationscarpeta . Los conjuntos de datos de salida aún no se han creado, y el gráfico de la canalización a la derecha de la pantalla está vacío.Para ejecutar el código de canalización (el código de la
transformationscarpeta), haga clic en Ejecutar canalización en la parte superior derecha de la pantalla.Una vez completada la ejecución, la parte inferior del área de trabajo muestra las dos tablas nuevas que se crearon
sample_users_<date_time>ysample_aggregation_<date_time>. El gráfico de canalización en el lado derecho del área de trabajo ahora muestra las dos tablas, incluido quesample_userses el origen desample_aggregation. Anote el nombre de la tabla completasample_users_<date_time>; haga referencia a él en el paso siguiente.
Paso 2: Aplicar comprobaciones de calidad de datos
En este paso, agregará una comprobación de calidad de datos a la sample_users tabla. Las expectativas de canalización se usan para restringir los datos. En este caso, eliminará los registros de usuario que no tengan una dirección de correo electrónico válida y generará la tabla limpiada como users_cleaned.
En el navegador de recursos de canalización de la izquierda, haga clic en
y seleccione Transformación.En el cuadro de diálogo Crear nuevo archivo de transformación , realice las siguientes selecciones:
- Elija Python o SQL para el Language. Esto no tiene que coincidir con la selección anterior.
- Asigne un nombre al archivo. En este caso, elija
users_cleaned. - En Ruta de acceso de destino, deje el valor predeterminado.
- En Tipo de conjunto de datos, déjelo como Ninguno seleccionado o elija Vista materializada. Si selecciona Vista materializada, genera código de ejemplo automáticamente.
Haga clic en Crear para crear el archivo de código de transformación.
En el nuevo archivo de código, edite el código para que coincida con lo siguiente (use SQL o Python, en función de la selección en la pantalla anterior). Reemplace
sample_users_<date_time>por el nombre completo de su tablasample_usersde la sección anterior.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Haga clic en Ejecutar canalización para actualizar la canalización. Ahora debería tener tres tablas.
Paso 3: Análisis de los usuarios principales
A continuación, obtenga los 100 primeros usuarios por el número de reservas que han creado. Una la wanderbricks.bookings tabla a la users_cleaned vista materializada.
En el navegador de recursos de canalización de la izquierda, haga clic en
y seleccione Transformación.En el cuadro de diálogo Crear nuevo archivo de transformación , realice las siguientes selecciones:
- Elija Python o SQL para el Language. Esto no tiene que coincidir con las selecciones anteriores.
- Asigne un nombre al archivo. En este caso, elija
users_and_bookings. - En Ruta de acceso de destino, deje el valor predeterminado.
- En Tipo de conjunto de datos, déjelo como Ninguno seleccionado.
Haga clic en Crear para crear el archivo de código de transformación.
En el nuevo archivo de código, edite el código para que coincida con lo siguiente (use SQL o Python, en función de la selección en la pantalla anterior).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Haga clic en Ejecutar canalización para actualizar los conjuntos de datos. Una vez completada la ejecución, puede ver en el gráfico de canalización que hay cuatro tablas, incluida la nueva
users_and_bookings.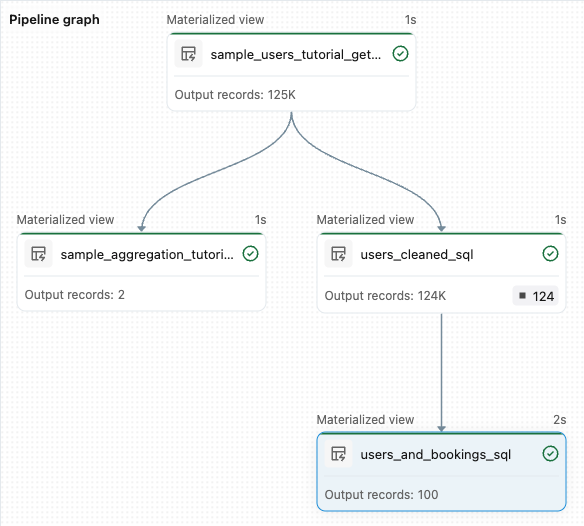
Recursos adicionales
Ahora que ha aprendido a usar algunas de las características del editor de canalizaciones de Lakeflow y ha creado una canalización, estas son otras características para obtener más información sobre:
Herramientas para trabajar con transformaciones y depuración al crear canalizaciones:
- Ejecución selectiva
- Vistas previas de datos
- Gráfico de canalización interactiva (gráfico de los conjuntos de datos de la canalización)
Integración integrada de paquetes de automatización declarativa para una colaboración eficaz, control de versiones e integración de CI/CD directamente desde el editor: