Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica está en versión preliminar pública.
Importante
En este artículo se describe la experiencia heredada de la tabla de inferencia, que solo es relevante para determinados puntos de conexión de procesamiento aprovisionados y modelos personalizados.
- A partir del 20 de febrero de 2026, las tablas de inferencia heredadas no se pueden habilitar en puntos de conexión de servicio de modelos nuevos o existentes.
- A partir del 30 de abril de 2026, ya no se admitirá la experiencia de la tabla de inferencia heredada.
Databricks recomienda las tablas de inferencia habilitadas por la puerta de enlace de IA para su disponibilidad en el modelo personalizado, el modelo fundacional y los puntos de servicio del agente. Consulte Migración a tablas de inferencia del AI Gateway para obtener instrucciones sobre cómo migrar a tablas de inferencia habilitadas para el AI Gateway.
Nota:
Si está atendiendo una aplicación de inteligencia artificial de generación en Databricks, puede usar la supervisión de inteligencia artificial de generación de Databricks para configurar automáticamente tablas de inferencia y realizar un seguimiento de las métricas operativas y de calidad de la aplicación.
En este artículo se describen las tablas de inferencia para supervisar los modelos servidos. En el diagrama siguiente se muestra un flujo de trabajo típico con tablas de inferencia. La tabla de inferencia captura automáticamente las solicitudes entrantes y las respuestas salientes para un punto de conexión de servicio del modelo y las registra como una tabla delta del catálogo de Unity. Puede usar los datos de esta tabla para supervisar, depurar y mejorar los modelos de ML.
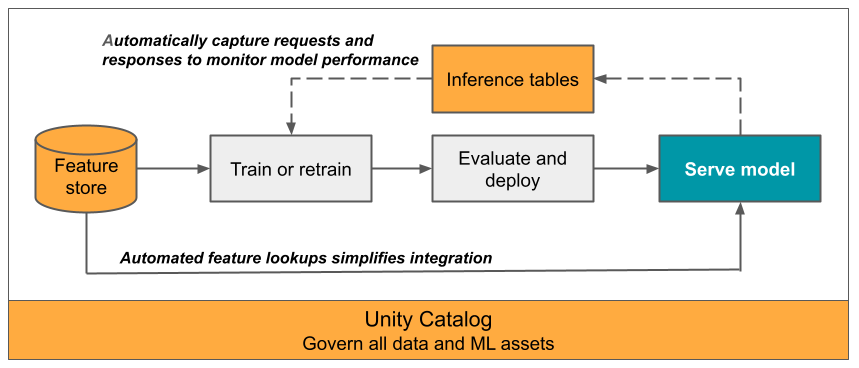
¿Qué son las tablas de inferencia?
La supervisión del rendimiento de los modelos en los flujos de trabajo de producción es un aspecto importante del ciclo de vida de los modelos de inteligencia artificial y ML. Tablas de inferencia simplifican la supervisión y el diagnóstico de los modelos mediante el registro continuo de las entradas y respuestas de las solicitudes (predicciones) desde los puntos de conexión de Mosaic AI Model Serving y guardándolos en una tabla Delta en el Catálogo de Unity. Después, puede usar todas las funcionalidades de la plataforma de Databricks, como consultas sql de Databricks, cuadernos y generación de perfiles de datos para supervisar, depurar y optimizar los modelos.
Puede habilitar las tablas de inferencia en cualquier punto de conexión existente o recién creado y las solicitudes a ese punto de conexión se registran automáticamente en una tabla de UC.
Algunas aplicaciones comunes para las tablas de inferencia son las siguientes:
- Supervisar la calidad de los datos y del modelo. Puede supervisar continuamente el rendimiento del modelo y el desfase de datos mediante la generación de perfiles de datos. La generación de perfiles de datos genera automáticamente paneles de calidad de datos y modelos que puede compartir con las partes interesadas. Además, puede habilitar las alertas para saber cuándo necesita volver a entrenar el modelo en función de los cambios en los datos entrantes o las reducciones en el rendimiento del modelo.
- Depuración de incidencias de producción. Las tablas de inferencias registran datos como códigos de estado HTTP, tiempos de ejecución de modelos y códigos JSON de solicitud y respuesta. Puede usar estos datos de rendimiento con fines de depuración. También puede usar los datos históricos en tablas de inferencia para comparar el rendimiento del modelo en las solicitudes históricas.
- Cree un corpus de entrenamiento. Al unir tablas de inferencia con etiquetas de verdad básica, puede crear un corpus de entrenamiento que puede usar para volver a entrenar o ajustar y mejorar el modelo. Con los trabajos de Lakeflow, puede configurar un bucle continuo de retroalimentación y automatizar el reentrenamiento.
Requisitos
- Su área de trabajo debe estar habilitada para Unity Catalog.
- Tanto el creador del punto de conexión como el modificador deben tener el permiso Puede administrar en el punto de conexión. Consulte las Listas de control de acceso.
- Tanto el creador del punto de conexión como el modificador deben tener los permisos siguientes en Unity Catalog:
-
USE CATALOGpermisos en el catálogo especificado. -
USE SCHEMApermisos en el esquema especificado. -
CREATE TABLEpermisos en el esquema.
-
Habilitar y deshabilitar las tablas de inferencia
En esta sección se muestra cómo habilitar o deshabilitar tablas de inferencia mediante la interfaz de usuario de Databricks. También puede usar la API; Consulte Habilitación de tablas de inferencia en puntos de conexión de servicio de modelos mediante la API para obtener instrucciones.
El propietario de las tablas de inferencia es el usuario que ha creado el punto de conexión. Todas las listas de control de acceso (ACL) de la tabla siguen los permisos estándar de Unity Catalog y el propietario de la tabla puede modificarlos.
Advertencia
La tabla de inferencia podría dañarse si realiza alguna de las acciones siguientes:
- Se cambia el esquema de la tabla.
- Cambie el nombre de la tabla.
- Elimine la tabla.
- Se pierden permisos en el catálogo o esquema de Unity Catalog.
En este caso, el auto_capture_config del estado del punto de conexión muestra un estado de FAILED para la tabla de carga. Si esto sucede, debe crear un nuevo punto de conexión para seguir usando tablas de inferencia.
Para habilitar tablas de inferencia durante la creación de puntos de conexión, siga estos pasos:
Haga clic en Servicio en la interfaz de usuario de Databricks Mosaic AI.
Haga clic en Crear punto de conexión de servicio.
Seleccione Habilitar tabla de inferencia.
En los menús desplegables, seleccione el catálogo y el esquema deseados donde desea que se encuentre la tabla.
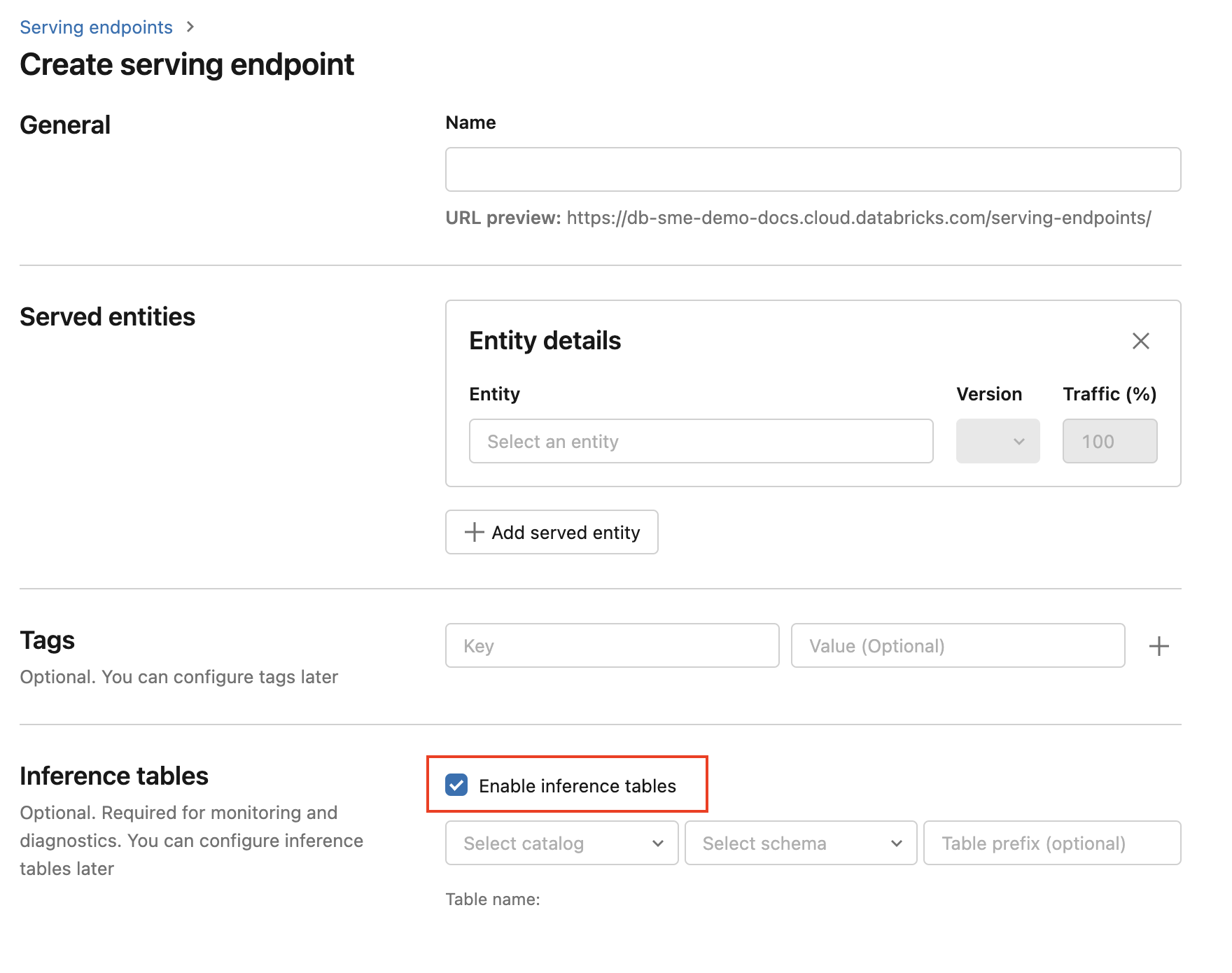
El nombre de tabla predeterminado es
<catalog>.<schema>.<endpoint-name>_payload. Si lo desea, puede escribir un prefijo de tabla personalizado.Haga clic en Crear punto de conexión de servicio.
También puede habilitar tablas de inferencia en un punto de conexión existente. Para editar una configuración de punto de conexión existente, haga lo siguiente:
- Vaya a la página del punto de conexión.
- Haga clic en Editar configuración.
- Siga las instrucciones anteriores, empezando por el paso 3.
- Cuando haya terminado, haga clic en Actualizar punto de conexión de servicio.
Siga estas instrucciones para deshabilitar las tablas de inferencia:
- Vaya a la página del punto de conexión.
- Haga clic en Editar configuración.
- Haga clic en Habilitar tabla de inferencia para quitar la marca de verificación.
- Cuando esté satisfecho con las especificaciones del punto de conexión, haga clic en Actualizar.
Migración a tablas de inferencia de puerta de enlace de IA
Importante
Después de que un punto de conexión migra para usar una tabla de inferencia del AI Gateway, no puede volver a la tabla heredada.
Nota:
Las tablas de inferencia de puerta de enlace de AI tienen esquemas diferentes en comparación con las tablas de inferencia heredadas.
Para obtener información sobre los precios, consulte la página de precios de Mosaic AI Gateway.
En esta sección se explica cómo migrar de tablas de inferencia heredadas a tablas de inferencia de AI Gateway.
Hay dos pasos principales para actualizar la configuración:
- Actualice el punto de conexión de servicio para deshabilitar la tabla de inferencia heredada.
- Actualice el endpoint de servicio para habilitar la tabla de inferencia de AI Gateway.
Uso de la interfaz de usuario para migrar la configuración de la tabla de inferencia
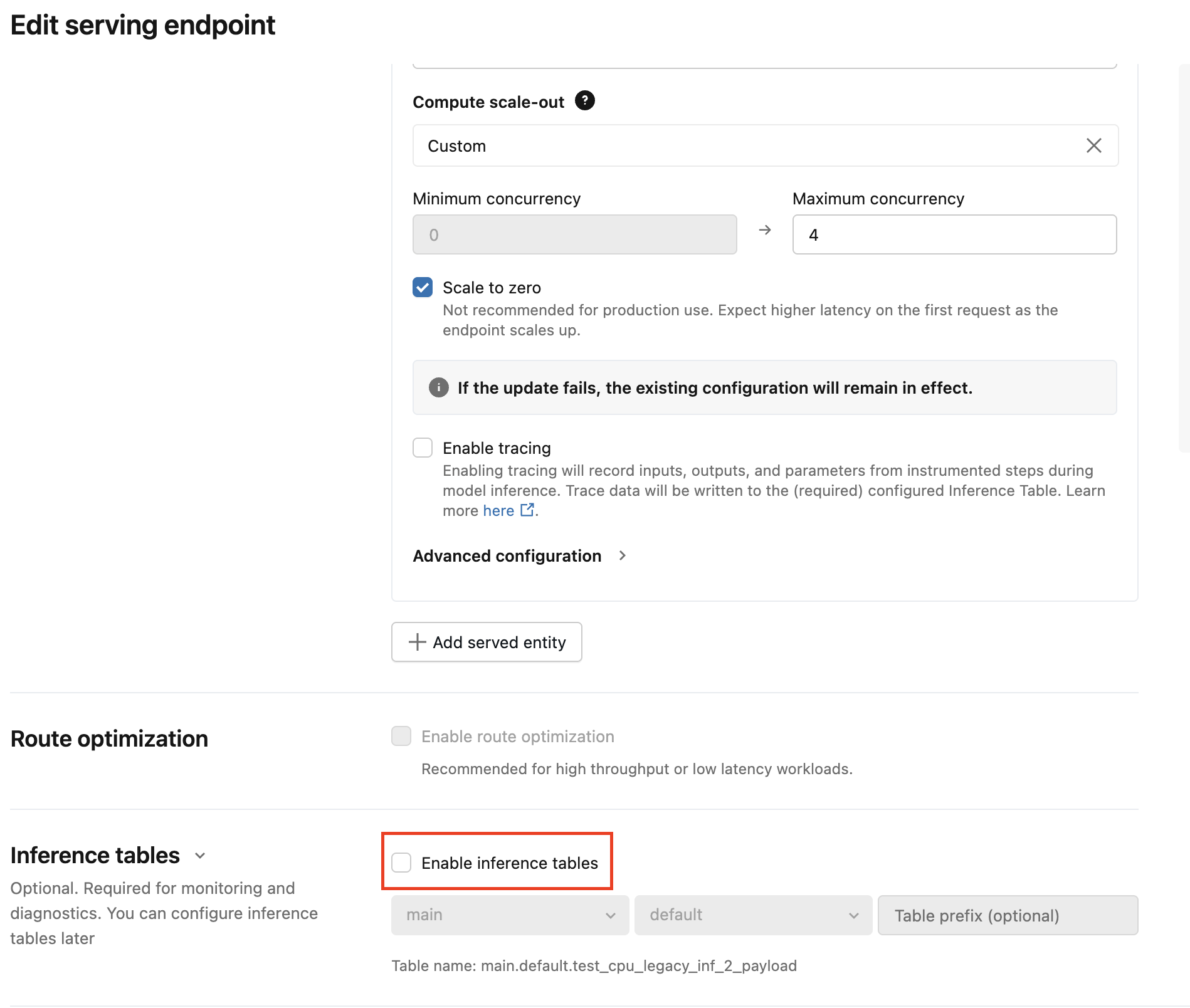
Para un pequeño número de puntos de conexión de servicio, edite la configuración del punto de conexión en la interfaz de usuario:
Haga clic en Servicio en la interfaz de usuario de Databricks Mosaic AI y vaya a la página del punto de conexión.
Haga clic en Editar configuración.
Haga clic en Habilitar tablas de inferencia para quitar la marca de verificación.
Haga clic en Actualizar y espere a que el estado del punto de conexión se convierta en Listo.
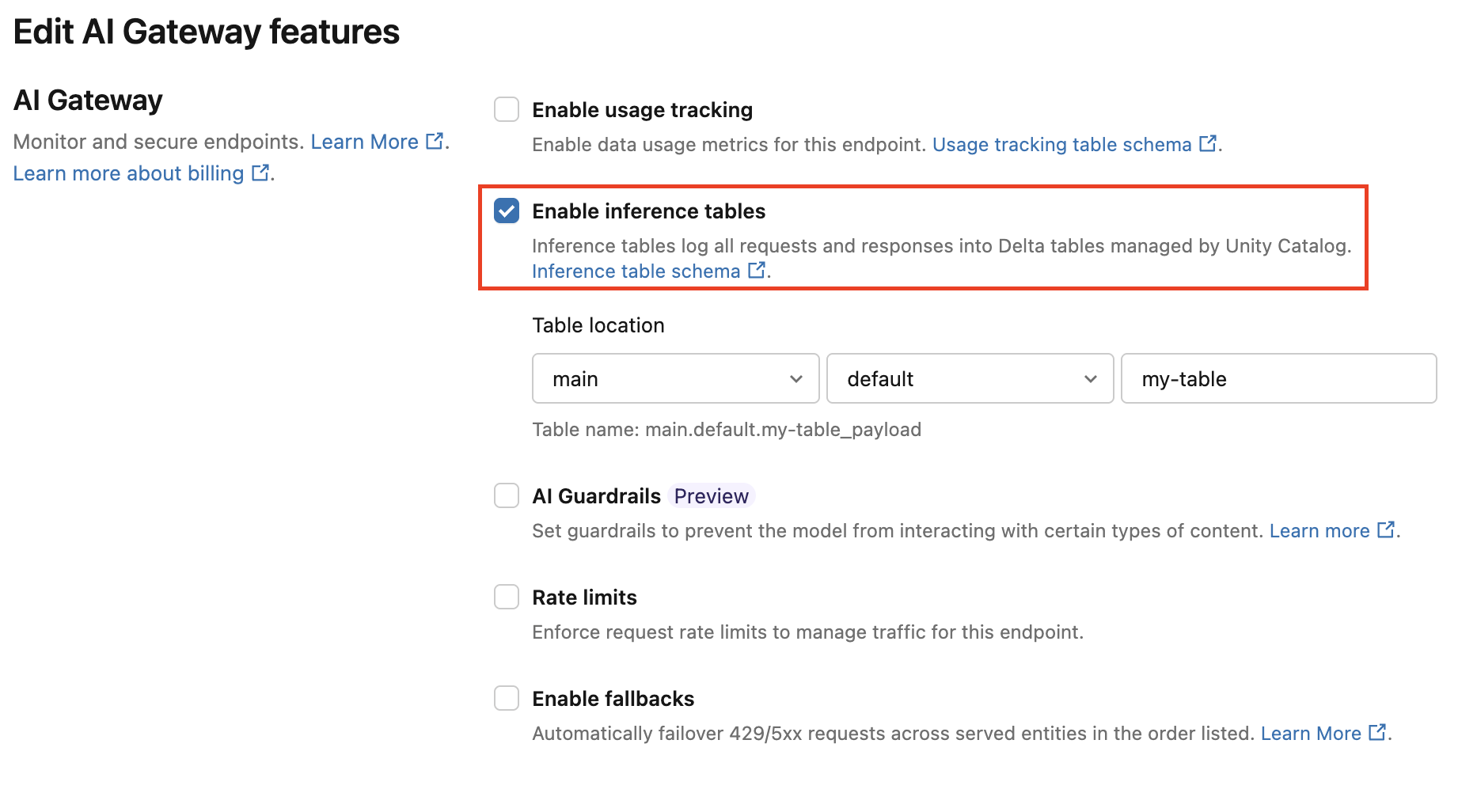
Siga estas instrucciones para habilitar la tabla de inferencia de AI Gateway:
Haga clic en Servicio en la interfaz de usuario de Databricks Mosaic AI y vaya a la página del punto de conexión.
Haga clic en Editar AI Gateway.
Haga clic en Habilitar tablas de inferencia.
En el menú desplegable, seleccione el catálogo y el esquema deseados donde desea que se encuentre la tabla.
El nombre de tabla predeterminado es
<catalog>.<schema>.<endpoint-name>_payload. Opcionalmente, escriba un prefijo de tabla personalizado.Haga clic en Update(Actualizar).
Uso del cuaderno para migrar la configuración de la tabla de inferencia
Para muchos puntos de conexión, puede usar la API para automatizar el proceso de migración. Databricks proporciona un cuaderno de ejemplo que migra por lotes los puntos de conexión y ejemplos sobre cómo migrar datos existentes de tablas de inferencia heredadas a tablas de inferencia de AI Gateway.
Migración al cuaderno de tablas de inferencia de AI Gateway
Flujo de trabajo: Supervisión del rendimiento del modelo mediante tablas de inferencia
Para supervisar el rendimiento del modelo mediante tablas de inferencia, siga estos pasos:
- Habilite las tablas de inferencia en su punto de conexión, ya sea durante la creación del punto de conexión o actualizándolo posteriormente.
- Programe un flujo de trabajo para procesar las cargas útiles JSON en la tabla de inferencia, desempaquetándolas de acuerdo con el esquema del endpoint.
- (Opcional) Unir las solicitudes y respuestas desempaquetadas con etiquetas de referencia para permitir el cálculo de las métricas de calidad del modelo.
- Cree una supervisión sobre la tabla Delta resultante y actualice las métricas.
Los cuadernos de inicio implementan este flujo de trabajo.
Bloc de notas inicial para monitorizar una tabla de inferencia
En el cuaderno siguiente se implementan los pasos descritos anteriormente para desempaquetar solicitudes de una tabla de inferencia de generación de perfiles de datos. El cuaderno se puede ejecutar a petición o en una programación periódica mediante Lakeflow Jobs.
Cuaderno de inicio de generación de perfiles de datos de tabla de inferencia
Cuaderno de inicio para supervisar la calidad del texto desde los puntos de conexión que sirven a modelos de lenguaje a gran escala (LLM)
En el cuaderno siguiente se desempaquetan las solicitudes de una tabla de inferencia, se calcula un conjunto de métricas de evaluación de texto (como la legibilidad y la toxicidad) y se habilita la supervisión de estas métricas. El cuaderno se puede ejecutar a petición o en una programación periódica mediante Lakeflow Jobs.
Cuaderno de inicio de generación de perfiles de datos de tabla de inferencia de LLM
Consulta y análisis de resultados en la tabla de inferencia
Una vez que los modelos servidos estén listos, todas las solicitudes realizadas a los modelos se registran automáticamente en la tabla de inferencia, junto con las respuestas. Puede ver la tabla en la interfaz de usuario, consultar la tabla desde DBSQL o un cuaderno, o consultar la tabla mediante la API de REST.
Para ver la tabla en la interfaz de usuario: en la página del punto de conexión, haga clic en el nombre de la tabla de inferencia para abrir la tabla en el Explorador de catálogos.

Para consultar la tabla desde DBSQL o un cuaderno de Databricks: puede ejecutar código similar al siguiente para consultar la tabla de inferencia.
SELECT * FROM <catalog>.<schema>.<payload_table>
Si ha habilitado tablas de inferencia mediante la interfaz de usuario, payload_table es el nombre de tabla que ha asignado al crear el punto de conexión. Si ha habilitado tablas de inferencia mediante la API, payload_table se notifica en la secciónstate de la respuestaauto_capture_config. Para obtener un ejemplo, consulte Habilitación de tablas de inferencia en puntos de conexión de servicio de modelos mediante la API.
Nota de rendimiento
Después de invocar el punto de conexión, podrá verse la invocación en la tabla de inferencia al cabo de una hora de haber enviado una solicitud de evaluación. Además, Azure Databricks garantiza que la entrega de registros se produzca al menos una vez, por lo que es posible, aunque poco probable, que se envíen registros duplicados.
Esquema de tabla de inferencia del Unity Catalog
Cada solicitud y respuesta que se registra en una tabla de inferencia se escribe en una tabla Delta con el siguiente esquema:
Nota:
Si invoca el punto de conexión con un lote de entradas, todo el lote se registra como una fila.
| Nombre de la columna | Descripción | Tipo |
|---|---|---|
databricks_request_id |
Identificador de solicitud generado por Azure Databricks adjunto a todas las solicitudes de servicio del modelo. | CUERDA |
client_request_id |
Un identificador de solicitud generado opcionalmente por el cliente, que se puede especificar en el cuerpo de la solicitud para el servicio del modelo. Consulte Especifique client_request_id para más información. |
CUERDA |
date |
Fecha UTC en la que se recibió la solicitud de servicio del modelo. | FECHA |
timestamp_ms |
La marca de tiempo en milisegundos en que se recibió la solicitud de servicio de modelo. | LARGO |
status_code |
El código de estado HTTP devuelto por el modelo. | INT |
sampling_fraction |
La fracción de muestreo utilizada en caso de que la solicitud haya sido submuestreada. Este valor está comprendido entre 0 y 1, donde 1 representa que se incluyeron el 100 % de las solicitudes entrantes. | DOBLE |
execution_time_ms |
Tiempo de ejecución en milisegundos para los que el modelo realizó la inferencia. Esto no incluye latencias de red de sobrecarga y solo representa el tiempo necesario para que el modelo genere predicciones. | LARGO |
request |
Cuerpo JSON de solicitud sin procesar que se envió al punto de conexión de servicio del modelo. | CUERDA |
response |
Cuerpo JSON de solicitud sin procesar que se envió al punto de conexión de servicio del modelo. | CUERDA |
request_metadata |
Mapa de metadatos relacionados con el punto de conexión de servicio del modelo asociado a la solicitud. Este mapa contiene el nombre del punto de conexión, el nombre del modelo y la versión del modelo que se usa para el punto de conexión. | MAPA<CADENA, CADENA> |
Especificar client_request_id
El campo client_request_id es un valor opcional que el usuario puede proporcionar en el cuerpo de la solicitud de servicio de modelos. Esto permite al usuario proporcionar su propio identificador para una solicitud que se muestra en la tabla de inferencia final en client_request_id y se puede usar para unir la solicitud con otras tablas que utilizan client_request_id, como la combinación de etiquetas de verdad básica. Para especificar un valor client_request_id, inclúyalo como clave de nivel superior de la carga de la solicitud. Si no se especifica ningún valor client_request_id, el valor aparece como null en la fila correspondiente a la solicitud.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
El valor client_request_id se puede usar más adelante en combinaciones de etiquetas de verdad básica si hay otras tablas que tienen etiquetas asociadas con client_request_id.
Limitaciones
- Las claves administradas por el cliente no son compatibles.
- Para los puntos de conexión que hospedan modelos de base, las tablas de inferencia solo son compatibles con cargas de trabajo de rendimiento aprovisionado.
- Azure Firewall puede producir errores en la creación de la tabla Delta de Unity Catalog, por lo que no se admite de forma predeterminada. Póngase en contacto con el equipo de cuentas de Databricks para su habilitación.
- Cuando se habilitan las tablas de inferencia, el límite de simultaneidad máxima total en todos los modelos servidos en un único punto de conexión es 128. Póngase en contacto con el equipo de la cuenta de Azure Databricks para solicitar un aumento de este límite.
- Si una tabla de inferencia contiene más de 500 000 archivos, no se registra ningún dato adicional. Para evitar superar este límite, ejecute OPTIMIZE o configure la retención en la tabla mediante la eliminación de datos anteriores. Para comprobar el número de archivos de la tabla, ejecute
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - La entrega de registros de tablas de inferencia es el mejor esfuerzo actualmente, pero puede esperar que los registros estén disponibles en un plazo de 1 hora a partir de una solicitud. Póngase en contacto con el equipo de la cuenta de Databricks para obtener más información.
Para conocer las limitaciones generales del punto de conexión del servicio de modelos, consulte Límites y regiones del servicio de modelos.