Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Puede orquestar cuadernos de Databricks y modularizar código mediante Lakeflow Jobs, dbutils.notebook.run(), archivos del espacio de trabajo y %run. Elija un método en función de la necesidad de programar, pasar parámetros y control de versiones.
Métodos de orquestación y modularización de código
En la tabla siguiente se comparan los métodos disponibles para orquestar cuadernos y modularizar código en cuadernos.
| Método | Caso de uso | Notas |
|---|---|---|
| Trabajos de Lakeflow | Orquestación de notebooks (recomendado) | Método recomendado para orquestar notebooks. Admite flujos de trabajo complejos con dependencias de tareas, programación y desencadenadores. Proporciona un enfoque sólido y escalable para cargas de trabajo de producción, pero requiere instalación y configuración. |
| dbutils.notebook.run() | Orquestación de cuadernos | Utilice dbutils.notebook.run() si Jobs no puede satisfacer su caso de uso, por ejemplo, para ejecutar dinámicamente un notebook basado en un archivo de metadatos (ETL controlado por metadatos).Inicia un nuevo trabajo efímero para cada llamada, lo que puede aumentar la sobrecarga y carece de características de programación avanzadas. |
| Archivos del área de trabajo | Modularización de código (recomendado) | Método recomendado para modularizar código. Modularice el código en archivos de código reutilizables almacenados en el área de trabajo. Admite el control de versiones con repositorios e integración con IDE para mejorar la depuración y las pruebas unitarias. Requiere una configuración adicional para administrar las rutas de acceso y las dependencias de archivos. |
| %run | Modularización de código | Use %run si no puede acceder a los archivos del área de trabajo.Importe funciones o variables de otros cuadernos ejecutándolos en línea. Resulta útil para crear prototipos, pero puede dar lugar a código estrechamente acoplado que es más difícil de mantener. No admite el paso de parámetros ni el control de versiones. |
%run frente a dbutils.notebook.run()
El comando %run permite incluir otro cuaderno dentro de un cuaderno. Puede usar %run para modularizar el código colocando funciones auxiliares en un cuaderno independiente. También puede usarlo para concatenar cuadernos que implementen los pasos de un análisis. Cuando se usa %run, el cuaderno al que se llama se ejecuta de inmediato, y las funciones y variables definidas en él están disponibles en el cuaderno que hace la llamada.
La dbutils.notebook API complementa %run porque permite pasar parámetros y devolver valores de un notebook. Esto le permite crear flujos de trabajo y canalizaciones complejos con dependencias. Por ejemplo, puede obtener una lista de archivos en un directorio y pasar los nombres a otro cuaderno, lo que es imposible con %run. También puede crear flujos de trabajo if-then-else basados en valores devueltos.
A diferencia de %run, el método dbutils.notebook.run() inicia un nuevo trabajo para ejecutar el cuaderno.
Al igual que todas las API de dbutils, estos métodos solo están disponibles en Python y Scala. Sin embargo, puede usar dbutils.notebook.run() para invocar un cuaderno de R.
Utilice %run para importar un cuaderno
En este ejemplo, el primer cuaderno define una función, reverse, que está disponible en el segundo cuaderno después de usar el comando magic %run para ejecutar shared-code-notebook.

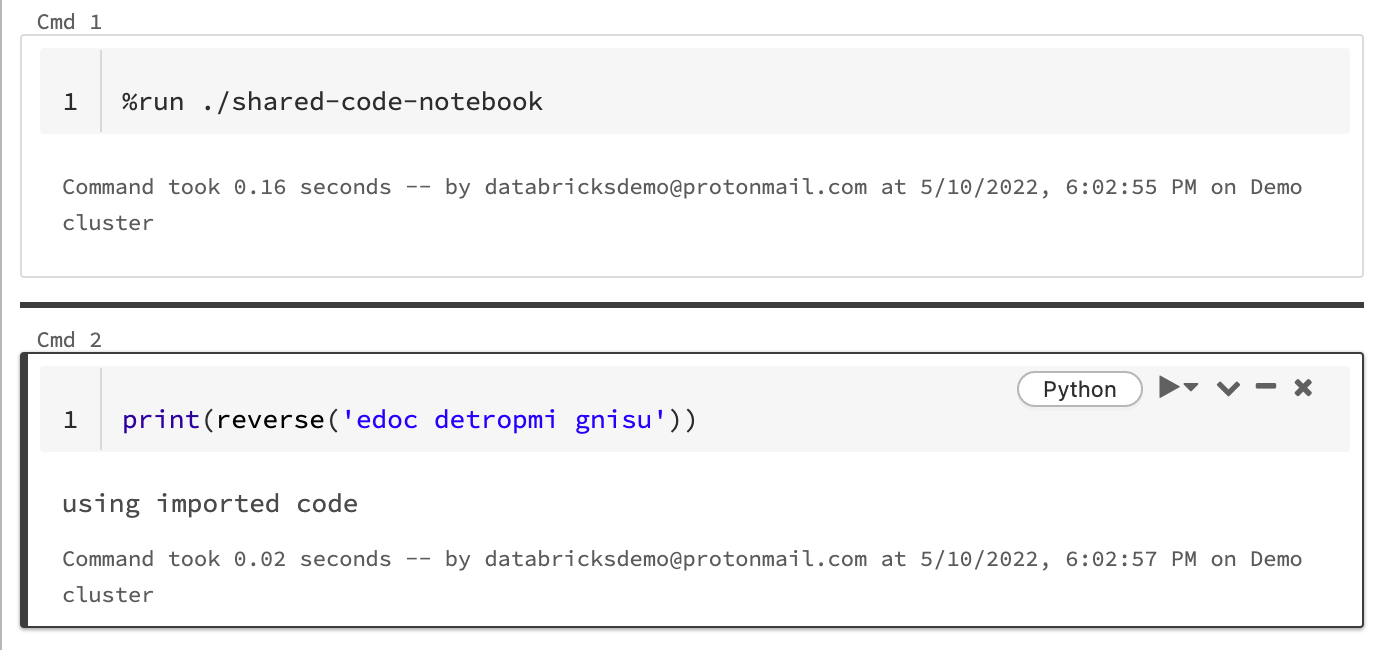
Dado que ambos notebooks están en el mismo directorio del área de trabajo, use el prefijo ./ en ./shared-code-notebook para indicar que la ruta de acceso debe resolverse en relación con el cuaderno que se está ejecutando actualmente. Puede organizar los cuadernos en directorios, como %run ./dir/notebook, o usar una ruta de acceso absoluta como %run /Users/username@organization.com/directory/notebook.
Nota:
-
%rundebe estar en una celda por sí mismo, porque ejecuta todo el cuaderno en línea. -
No puede usar
%runpara ejecutar un archivo de Python y usar la opciónimporten las entidades definidas en ese archivo en un cuaderno. Para importar desde un archivo de Python, consulte Modularizar el código mediante archivos. O bien, empaquete el archivo en una biblioteca de Python, cree un Azure Databricks library desde esa biblioteca de Python y instale la biblioteca en el clúster que utiliza para ejecutar su cuaderno. - Cuando se usa
%runpara ejecutar un cuaderno que contiene widgets, el cuaderno especificado se ejecuta de forma predeterminada con los valores predeterminados del widget. También puede pasar valores a widgets, vea Uso de widgets de Databricks con %run.
Uso dbutils.notebook.run para iniciar un nuevo trabajo
Ejecute un cuaderno y devuelva su valor de salida. El método inicia un trabajo efímero que se ejecuta de inmediato.
Los métodos disponibles en la API dbutils.notebook son run y exit. Tanto los parámetros como los valores devueltos deben ser cadenas.
run(path: String, timeout_seconds: int, arguments: Map): String
El timeout_seconds parámetro controla el tiempo de espera durante la ejecución (0 significa sin límite de tiempo). La llamada a run produce una excepción si no finaliza en el tiempo especificado. Si Azure Databricks está inactivo durante más de 10 minutos, se produce un error en la ejecución del cuaderno independientemente de timeout_seconds.
El parámetro arguments establece los valores de widget del cuaderno de destino. En concreto, si el cuaderno que está ejecutando tiene un widget denominado A, y se pasa un par clave-valor ("A": "B") como parte del parámetro de argumentos a la llamada run(), la recuperación del valor del widget A devolverá "B". Puede encontrar las instrucciones para crear y trabajar con widgets en la página de widgets de Databricks .
Nota:
- El parámetro
argumentssolo acepta caracteres latinos (juego de caracteres ASCII). El uso de caracteres no ASCII produce un error. - Los trabajos creados con la API
dbutils.notebookse deben completar en 30 días o menos.
run uso
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Pasar datos estructurados entre cuadernos
En esta sección se muestra cómo pasar datos estructurados entre cuadernos.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
Compatibilidad sin servidor Databricks recomienda alejarse de las API de RDD, ya que no son compatibles con la arquitectura de proceso sin servidor de Databricks. Use la API DataFrame en su lugar.
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Manejar errores
En esta sección, se muestra cómo controlar los errores.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Ejecución de varios cuadernos simultáneamente
Puede ejecutar varios cuadernos al mismo tiempo mediante construcciones estándar de Scala y Python, como Subprocesos (Scala, Python) y Futures (Scala, Python). Los cuadernos de ejemplo muestran cómo usar estas construcciones.
- Descargue los cuatro cuadernos siguientes. Los cuadernos están escritos en Scala.
- Importe los cuadernos en una sola carpeta del área de trabajo.
- Ejecute el cuaderno Ejecutar simultáneamente.