Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo describe cómo utilizar Looker con un clúster Azure Databricks o un almacén Databricks SQL (anteriormente llamado punto de conexión de Databricks SQL).
Importante
Cuando las tablas derivadas persistentes (PDT) están habilitadas, de manera predeterminada Looker vuelve a generar las PDT cada 5 minutos conectándose a la base de datos asociada. Databricks recomienda cambiar la frecuencia predeterminada para evitar incurrir en costos de proceso excesivos. Para obtener más información, consulte Habilitación y administración de tablas derivadas persistentes (PDT).
Requisitos
Para conectarse a Looker manualmente, deberá cumplir los siguientes requisitos:
Un clúster o almacén SQL en el área de trabajo de Azure Databricks.
Los detalles de conexión del clúster o de SQL Warehouse, específicamente los valores nombre de host del servidor, puerto y ruta de acceso HTTP .
Un token de acceso personal de Azure Databricks o un token de Id. de Microsoft Entra (anteriormente Azure Active Directory). Para crear un token de acceso personal, siga los pasos descritos en Tokens de acceso personal de Azure Databricks para los usuarios del área de trabajo.
Nota:
Como procedimiento recomendado de seguridad, al autenticarse con herramientas automatizadas, sistemas, scripts y aplicaciones, Databricks recomienda usar tokens de acceso personales que pertenecen a entidades de servicio en lugar de usuarios del área de trabajo. Para crear tokens para entidades de servicio, consulte Administración de tokens para una entidad de servicio.
Conectarse a Looker manualmente
Para conectarse a Looker manualmente, siga los pasos que se muestran a continuación:
En Looker, haga clic en Conexiones > de administrador > Agregar conexión.
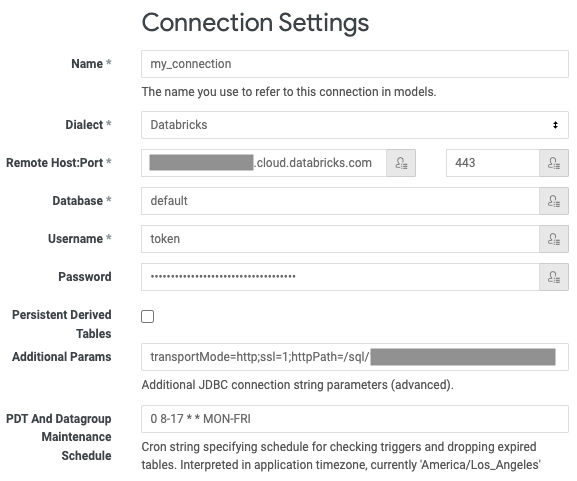
Escriba un nombre único para la conexión.
Sugerencia
Los nombres de las conexiones deben contener sólo letras minúsculas, números y guiones bajos. Es posible que se acepten otros caracteres, pero podrían provocar resultados inesperados más adelante.
En Dialecto, seleccione Databricks.
En Host remoto, escriba el nombre de host del servidor de los requisitos.
En Puerto, introduzca el puerto según los requisitos.
En Base de datos, escriba el nombre de la base de datos en el área de trabajo a la que desea acceder a través de la conexión (por ejemplo,
default).En Nombre de usuario, escriba la palabra
token.En Contraseña, escriba su token de acceso personal que aparece en los requisitos.
En Parámetros adicionales, escriba
transportMode=http;ssl=1;httpPath=<http-path>, reemplazando<http-path>por el valor de ruta de acceso HTTP de los requisitos.Si Unity Catalog está habilitado para el área de trabajo, establezca además el catálogo predeterminado. Escriba
ConnCatalog=<catalog-name>y reemplace<catalog-name>por el nombre de un catálogo.En PDT And Datagroup Maintenance Schedule (PDT y Programación de mantenimiento de grupos de datos), escriba una expresión válida
cronpara cambiar la frecuencia predeterminada a fin de volver a generar PDT. La frecuencia predeterminada es cada cinco minutos.Si desea traducir consultas a otras zonas horarias, ajuste La zona horaria de consulta.
En el caso de los campos restantes, mantenga los valores predeterminados, en particular:
- Mantenga los valores predeterminados de tiempo de esperamáximo de conexiones y grupo de conexiones.
- Deje la zona horaria de la base de datos en blanco (suponiendo que está almacenando todo en UTC).
Haga clic en Probar esta configuración.
Si la prueba se realiza correctamente, haga clic en Agregar conexión.
Modelado de la base de datos en Looker
En esta sección se crea un proyecto y se ejecuta el generador. Los pasos siguientes suponen que hay tablas permanentes almacenadas en la base de datos para la conexión.
En el menú Desarrollar , active el Modo de desarrollo.
Haga clic en Desarrollar >Administrar proyectos LookML.
Haga clic en Nuevo proyecto LookML.
Escriba un nombre de proyecto único.
Sugerencia
Los nombres de los proyectos deben contener sólo letras minúsculas, números y guiones bajos. Es posible que se acepten otros caracteres, pero podrían provocar resultados inesperados más adelante.
En Conexión, seleccione el nombre de la conexión en el paso 2.
En Esquemas, escriba
default, a menos que tenga otras bases de datos para modelar a través de la conexión.En el caso de los campos restantes, mantenga los valores predeterminados, en particular:
- Deje punto de partida establecido en Generar modelo a partir del esquema de base de datos.
- Deje Vistas de compilación de establecidas en Todas las tablas.
Haga clic en Crear proyecto.
Después de crear el proyecto y de que se ejecute el generador, Looker muestra una interfaz de usuario con un archivo .model y varios archivos .view. El archivo .model muestra las tablas del esquema y las relaciones de combinación detectadas entre ellas, y los .view archivos muestran cada dimensión (columna) disponible para cada tabla del esquema.
Pasos siguientes
Para empezar a trabajar con el proyecto, consulte los siguientes recursos en el sitio web de Looker:
Habilitación y administración de tablas derivadas persistentes (PDT)
Looker puede reducir los tiempos de consulta y las cargas de base de datos mediante la creación de tablas derivadas persistentes (PDT). Un PDT es una tabla derivada que Looker escribe en un esquema de cero en la base de datos. A continuación, Looker vuelve a generar el PDT según la programación que especifique. Para obtener más información, consulte Tablas derivadas persistentes (PDT) en la documentación de Looker.
Para habilitar pdT para una conexión de base de datos, seleccione Tablas derivadas persistentes para esa conexión y complete las instrucciones en pantalla. Para obtener más información, vea Tablas derivadas persistentes y Configuración de credenciales de inicio de sesión independientes para procesos PDT en la documentación de Looker.
Cuando los PDT están habilitados, de forma predeterminada, Looker vuelve a generar los PDT cada 5 minutos mediante la conexión a la base de datos asociada. Looker reinicia el recurso Azure Databricks asociado si se detiene. Databricks recomienda cambiar la frecuencia predeterminada estableciendo el campo PDT And Datagroup Maintenance Schedule para la conexión de base de datos a una expresión válida cron . Para obtener más información, consulte PDT y Datagroup Maintenance Schedule (Programación de mantenimiento de grupos de datos ) en la documentación de Looker.
Para habilitar pdT o cambiar la frecuencia de regeneración de PDT para una conexión de base de datos existente, haga clic en Conexiones de base de datos de administración>, haga clic en Editar junto a la conexión de base de datos y siga las instrucciones anteriores.