Julio de 2020
Estas características y mejoras de la plataforma de Azure Databricks se publicaron en julio de 2020.
Nota:
Las versiones se publican por fases. Es posible que su cuenta de Azure Databricks no se actualice hasta una semana después de la fecha de lanzamiento inicial.
Terminal web (versión preliminar pública)
Del 29 de julio al 4 de agosto de 2020: versión 3.25
El terminal web proporciona una manera cómoda e muy interactiva para que los usuarios con el permiso CAN ATTACH TO en un clúster ejecuten comandos de shell, incluidos editores como Vim o Emacs. Entre los usos de ejemplo del terminal web se incluyen la supervisión del uso de recursos y la instalación de paquetes de Linux.
Para obtener más detalles, consulte Ejecución de comandos de shell en el terminal web de Azure Databricks.
Un nuevo marco de scripts de inicialización global que es más seguro (versión preliminar pública)
Del 29 de julio al 4 de agosto de 2020: versión 3.25
El nuevo marco de script de inicialización global aporta mejoras significativas sobre los scripts de inicialización globales heredados:
- Los scripts init son más seguros y requieren permisos de administrador para las operaciones de creación, visualización y eliminación.
- Los errores de inicio relacionados con scripts quedan registrados.
- Puede establecer el orden de ejecución de varios scripts init.
- Los scripts init pueden hacer referencia a variables de entorno relacionadas con el clúster.
- Los scripts de inicialización se pueden crear y administrar mediante la página de configuración de administración o la nueva API de REST de scripts de inicialización globales.
Databricks recomienda migrar los scripts init globales heredados existentes al nuevo marco para aprovechar estas mejoras.
Para obtener más información, consulte Uso de scripts de inicialización globales.
Las listas de acceso de IP ahora son de disponibilidad general
Del 29 de julio al 4 de agosto de 2020: versión 3.25
La API de lista de acceso de IP ya está disponible con carácter general.
La versión de GA incluye un cambio, que es el cambio de nombre de los valores list_type:
WHITELISTaALLOWBLACKLISTaBLOCK
Use la API de lista de acceso de IP para configurar las áreas de trabajo de Azure Databricks, para que los usuarios se conecten al servicio solo a través de redes corporativas existentes con un perímetro seguro. Los administradores de Azure Databricks pueden usar la API de lista de acceso de IP para definir un conjunto de direcciones IP aprobadas, incluidas las listas de permitidas y bloqueadas. Todo el acceso entrante a la aplicación web y a las API de REST requiere que el usuario se conecte desde una dirección IP autorizada, lo que garantiza que no se puede acceder a las áreas de trabajo desde una red pública, como una cafetería o un aeropuerto, a menos que los usuarios usen VPN.
Esta característica requiere el plan Premium.
Para más información, consulte Configurar listas de acceso de IP para áreas de trabajo.
Nuevo cuadro de diálogo de carga de archivos
Del 29 de julio al 4 de agosto de 2020: versión 3.25
Ahora puede cargar archivos de datos tabulares pequeños (como CSV) y acceder a ellos desde un cuaderno, seleccionando Añadir datos en el menú Archivo del cuaderno. El código generado muestra cómo cargar los datos en Pandas o DataFrames. Los administradores pueden deshabilitar esta característica en la Pestaña avanzada Consola de administración.
Para obtener más información, consulte Examen de archivos en DBFS.
Mejoras en el filtro y la clasificación de SCIM API
Del 29 de julio al 4 de agosto de 2020: versión 3.25
La API de SCIM ahora incluye estas mejoras de filtrado y ordenación:
- Los usuarios administradores pueden filtrar usuarios por el atributo
active. - Todos los usuarios pueden ordenar los resultados mediante
sortByy lossortOrderparámetros de consulta. El valor predeterminado es ordenar por identificador.
Se han agregado regiones a Azure Government
25 de julio de 2020
Recientemente, Azure Databricks empezó a estar disponible en las regiones US Gov Arizona y US Gov Virginia, para entidades de la Administración pública de EE.UU. y sus asociados.
Disponibilidad general de Databricks Runtime 7.1
21 de julio de 2020
Databricks Runtime 7.1 ofrece muchas características y mejoras adicionales a Databricks Runtime 7.0, entre las que se incluyen:
- Conector de Google BigQuery
- Comandos de tipo
%pippara administrar bibliotecas de Python instaladas en una sesión de cuaderno - Koalas instalado
- Muchas mejoras de Delta Lake, entre las que se incluyen:
- Establecimiento de metadatos de confirmación definidos por el usuario
- Obtención de la versión de la última confirmación escrita por el actual
SparkSession - Conversión de tablas Parquet, creadas por Structured Streaming mediante el registro de transacciones
_spark_metadata MERGE INTOmejoras de rendimiento
Para obtener más información, consulte las notas completas de la versión de Databricks Runtime 7.1 (sin soporte técnico).
Disponibilidad general de Databricks Runtime 7.1 ML
21 de julio de 2020
Databricks Runtime 7.1 para Machine Learning se basa en Databricks Runtime 7.1, y aporta las siguientes características nuevas y cambios en la biblioteca:
- comandos "pip" y "conda magic", habilitados de manera predeterminada
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Para más información, consulte las notas completas de la versión de Databricks Runtime 7.1 for ML (sin soporte técnico).
Disponibilidad general de Databricks Runtime 7.1 para Genomics
21 de julio de 2020
Databricks Runtime 7.1 para Genomics se basa en Databricks Runtime 7.1, y ofrece las siguientes características nuevas:
- Transformación LOCO
- Función de cambio de forma en la salida de GloWGR
- Alineaciones no alineadas de salidas de RNASeq
Databricks Connect 7.1 (versión preliminar)
17 de julio de 2020
Databricks Connect 7.1 está ahora en versión preliminar pública.
Actualizaciones de IP Access List API
Del 15 al 21 de julio de 2020: versión 3.24
Las siguientes propiedades de la API de lista de acceso de IP han cambiado:
updator_user_idaupdated_bycreator_user_idacreated_by
Los cuadernos de Python ahora admiten varias salidas por celda
Del 15 al 21 de julio de 2020: versión 3.24
Ahora, los cuadernos de Python admiten varias salidas por celda. Esto significa que puede tener cualquier número de instrucciones "display", "displayHTML" o "print" en una celda. Aproveche la capacidad de ver los datos sin procesar y el trazado en la misma celda, o todas las salidas que se realizaron correctamente antes de que se produjese un error.
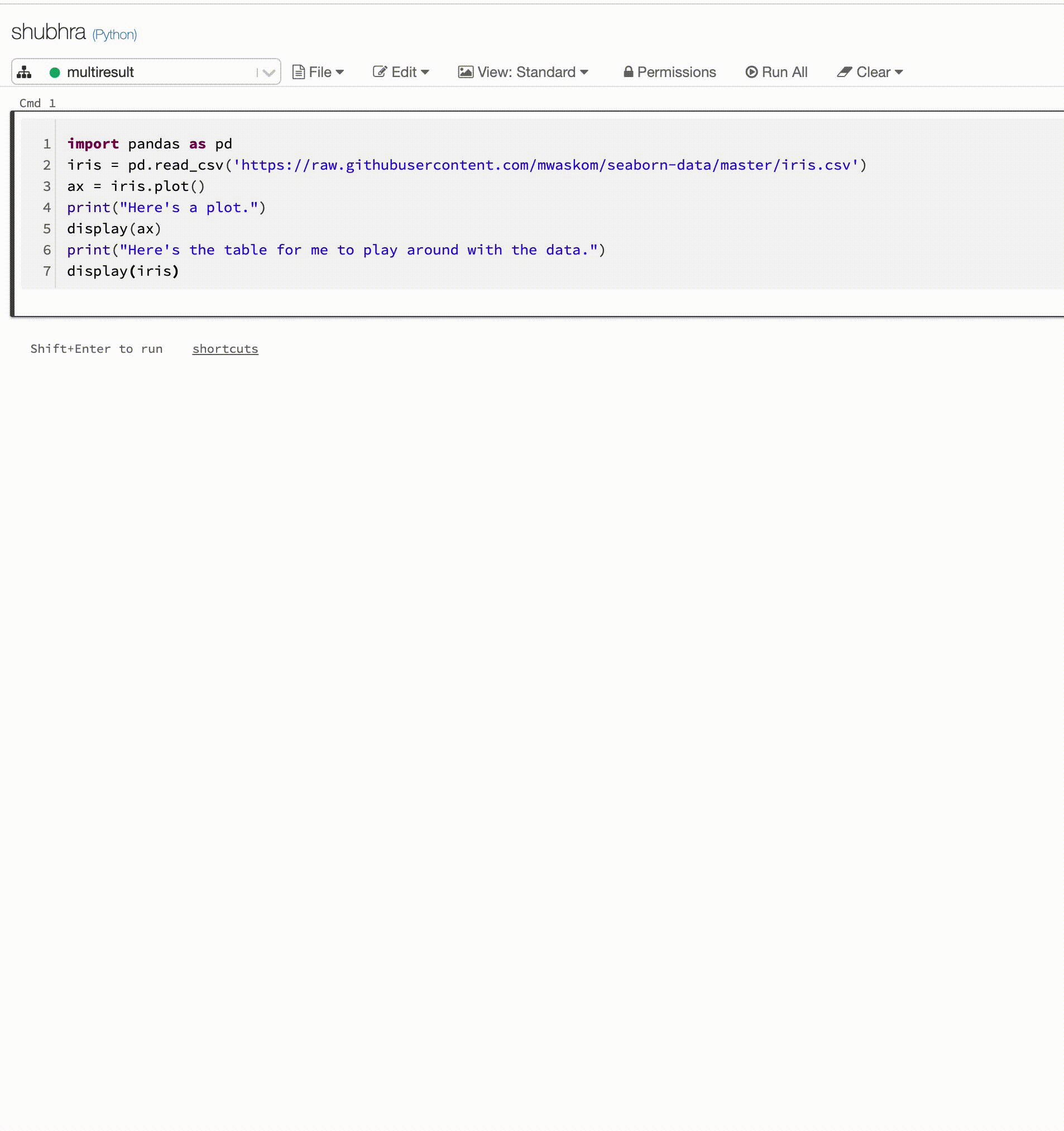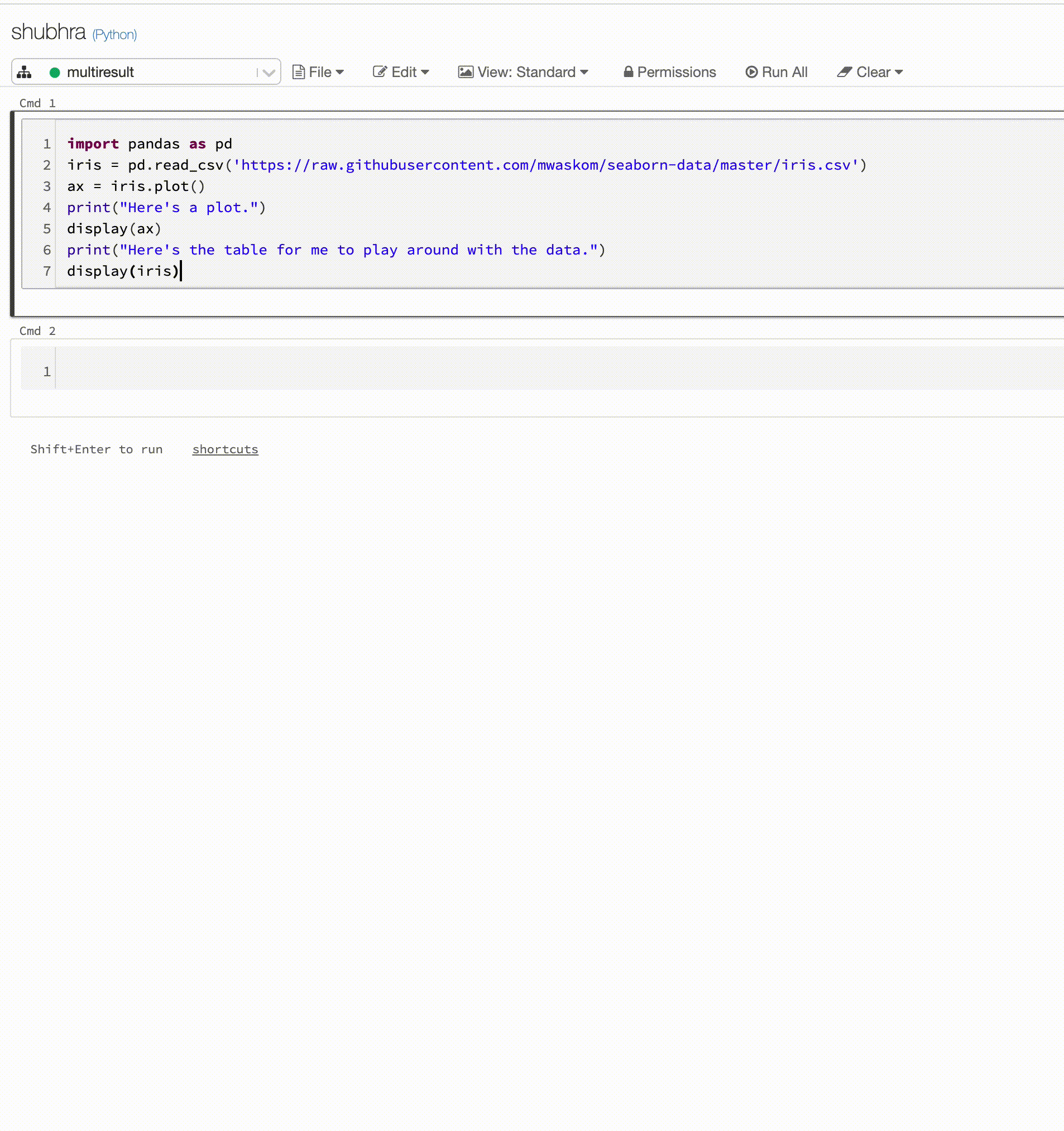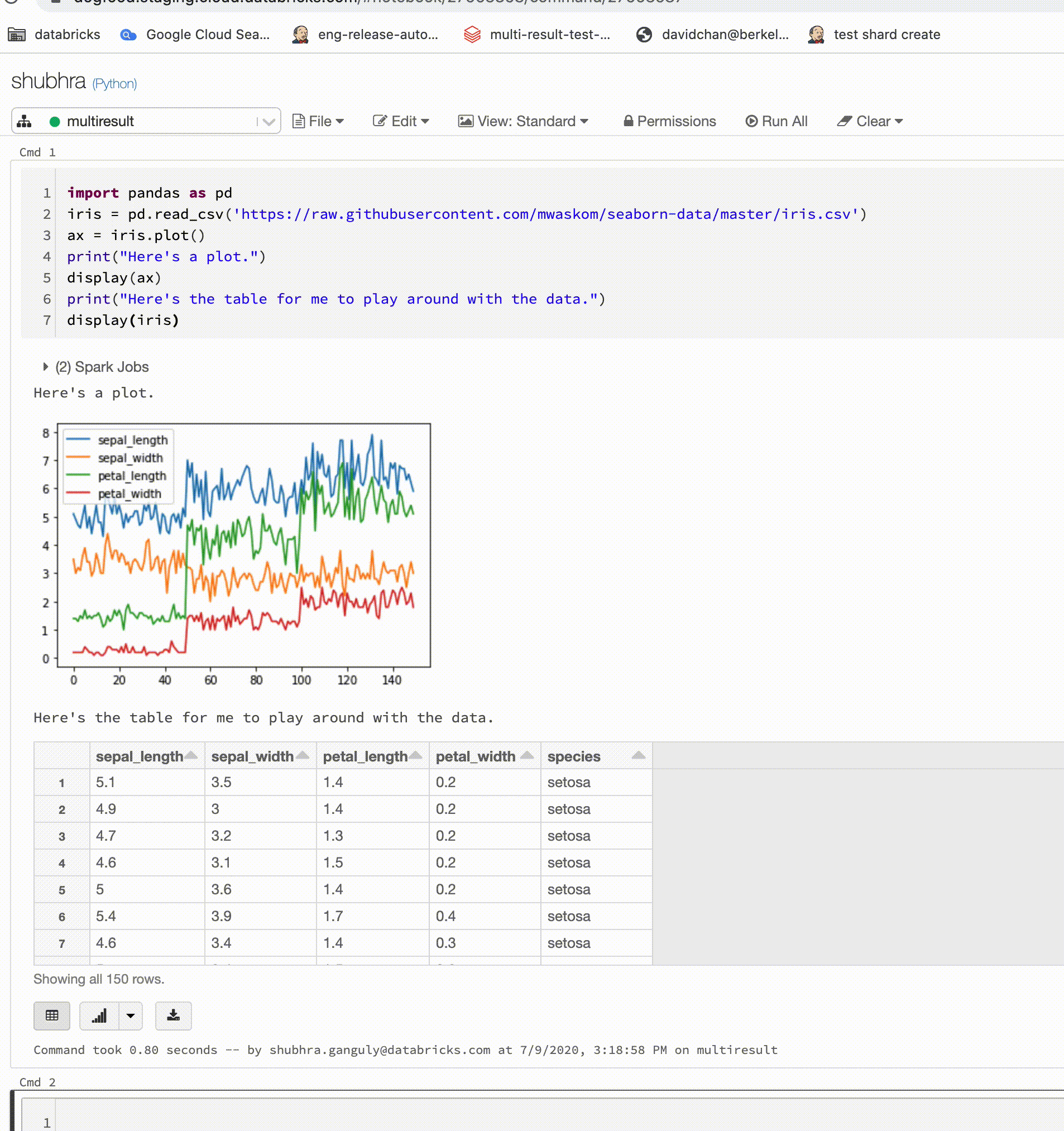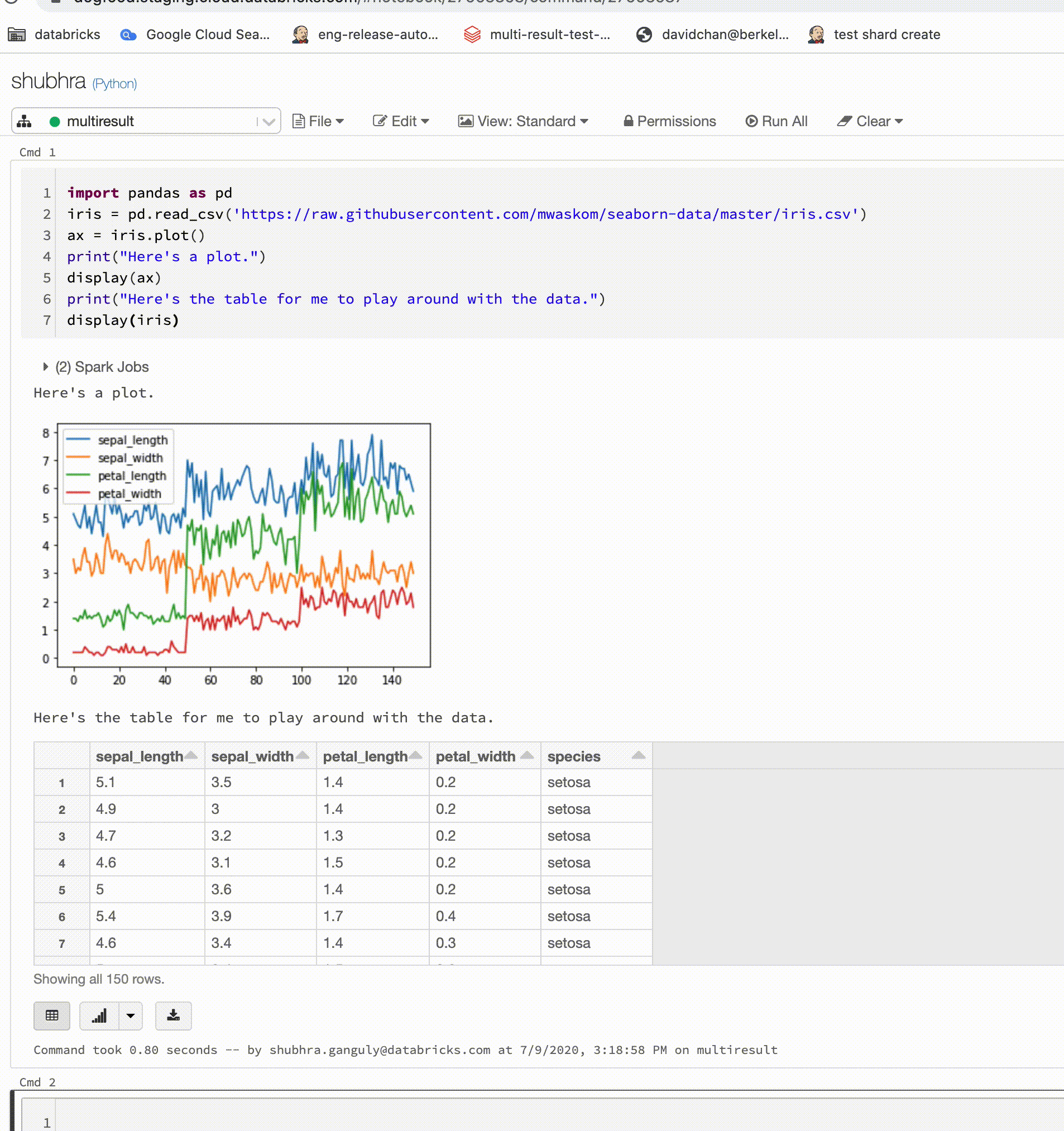
Esta característica requiere Databricks Runtime 7.1 o posterior, y está deshabilitada de manera predeterminada en Databricks Runtime 7.1. Para habilitarla, establezca spark.databricks.workspace.multipleResults.enabled true.
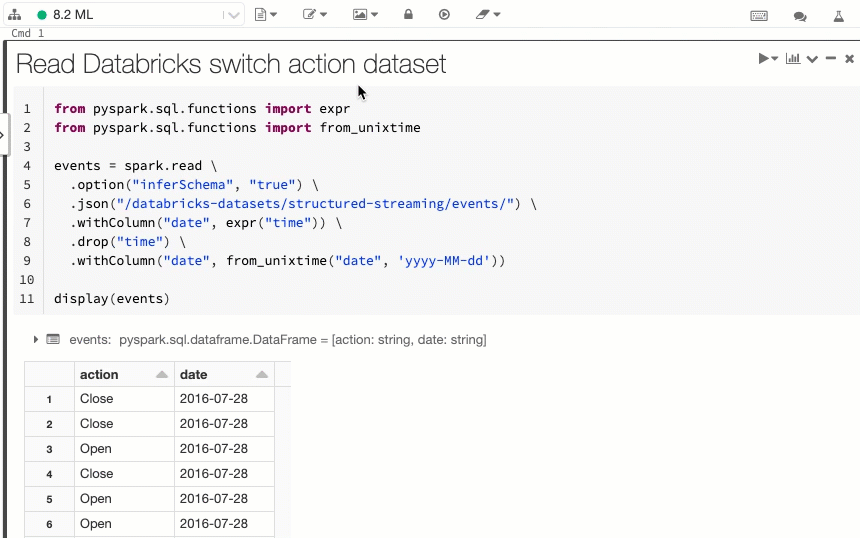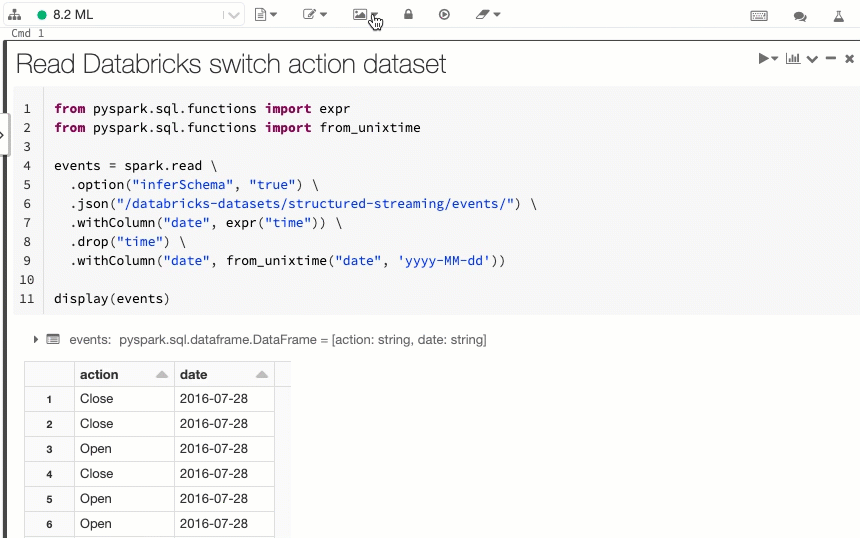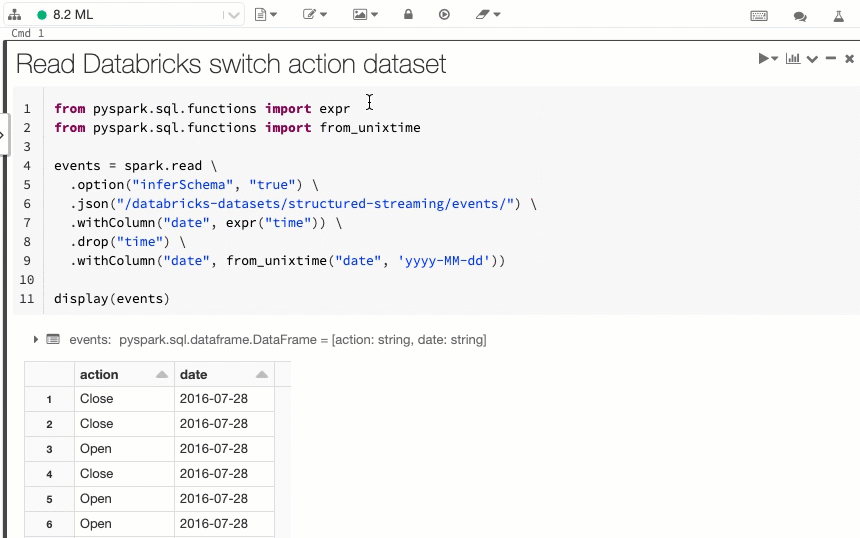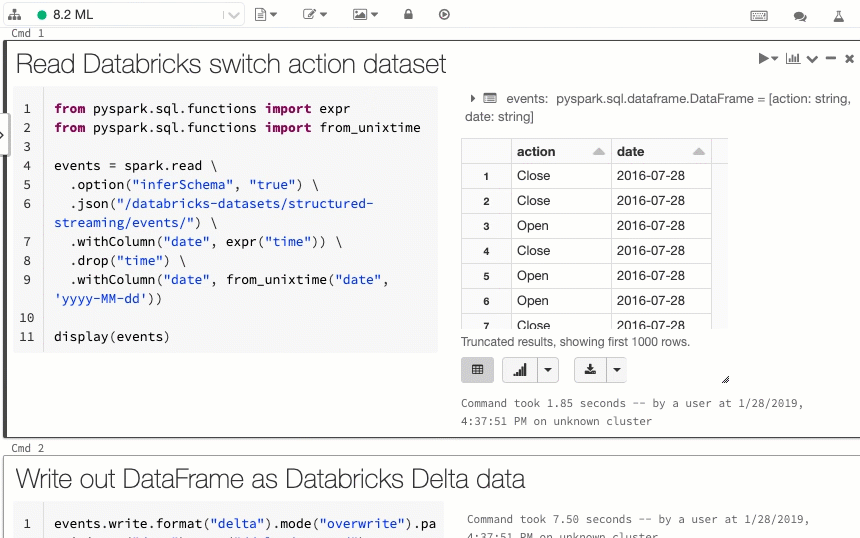
Visualización del código y de las celdas de resultados del cuaderno en paralelo
Del 15 al 21 de julio de 2020: versión 3.24
La nueva opción de visualización del cuaderno, En paralelo, le permite ver el código y los resultados unos junto a otros. Esta opción de visualización se une a la opción "Estándar" (anteriormente "Código") y a la opción "Solo resultados".
Pausa de programaciones de trabajos
Del 15 al 21 de julio de 2020: versión 3.24
Las programaciones de trabajos ahora tienen botones de Pausar y Reanudar, lo que facilita la pausa y reanudación de trabajos. Ahora puede realizar cambios en una programación de trabajo sin que se inicien ejecuciones de trabajo adicionales mientras realiza los cambios. Las ejecuciones actuales o las desencadenadas por Ejecutar ahora no se ven afectadas. Para más información, consulte Pausar y reanudar una programación de trabajo.
Los puntos de conexión de Jobs API validan el identificador de ejecución
Del 15 al 21 de julio de 2020: versión 3.24
Los puntos de conexión de API jobs/runs/cancel y jobs/runs/output ahora validan que el parámetro run_id es válido. Para los parámetros no válidos, estos puntos de conexión de API ahora devuelven el código de estado de HTTP 400, en vez del código 500.
Tokens de Microsoft Entra ID para autorizar la disponibilidad general de API de REST de Databricks
Del 15 al 21 de julio de 2020: versión 3.24
El uso de tokens de Microsoft Entra ID para autenticarse en API de área de trabajo ya está disponible con carácter general. Los tokens de Microsoft Entra ID permiten automatizar la creación y configuración de nuevas áreas de trabajo. Las entidades de servicio son objetos de aplicación en Microsoft Entra ID. También puede usar entidades de servicio dentro de las áreas de trabajo de Azure Databricks para automatizar los flujos de trabajo. Para obtener más información, consulte Tokens de Microsoft Entra ID (anteriormente, Azure Active Directory).
Formato de SQL en cuadernos de forma automática
Del 15 al 21 de julio de 2020: versión 3.24
Ahora puede dar formato a celdas de cuaderno de SQL desde un método abreviado de teclado, el menú contextual del comando y el menú Edición del cuaderno (seleccione Editar > Dar formato a celdas de SQL). El formato de celdas de SQL facilita la lectura y el mantenimiento del código con poco esfuerzo. Funciona para cuadernos de SQL, así como para las celdas %sql.

Orden de instalación reproducible para las bibliotecas de Maven y CRAN
Del 1 al 9 de julio de 2020: versión 3.23
Ahora, Azure Databricks procesa las bibliotecas Maven y CRAN en el orden en que se instalaron en el clúster.
Tome el control de los tokens de acceso personal de los usuarios con Token Management API (versión preliminar pública)
Del 1 al 9 de julio de 2020: versión 3.23
Ahora, los administradores de Azure Databricks pueden usar la API Token Management para administrar los tokens de acceso personal de los usuarios de Azure Databricks:
- Supervise y revoque los tokens de acceso personal de los usuarios.
- Controle la vigencia de los tokens futuros en el área de trabajo.
- Controle qué usuarios pueden crear y usar tokens.
Consulte Supervisión y administración de tokens de acceso personal.
Restauración de celdas del cuaderno cortadas
Del 1 al 9 de julio de 2020: versión 3.23
Ahora puede restaurar las celdas del cuaderno que se han cortado, bien mediante el método abreviado de teclado (Z) o seleccionando Edición >Deshacer el corte de las celdas. Esta funcionalidad es análoga a la de deshacer las celdas eliminadas.
Asignación de trabajos CAN MANAGE permiso a usuarios que no son administradores
Del 1 al 9 de julio de 2020: versión 3.23
Ahora puede asignar usuarios y grupos que no son administradores al permiso CAN MANAGE para trabajos. Este nivel de permiso permite a los usuarios administrar toda la configuración del trabajo, incluida la asignación de permisos, el cambio de propietario y el cambio de la configuración del clúster (por ejemplo, agregar bibliotecas y modificar la especificación del clúster). Consulte Controlar el acceso a un archivo.
Los usuarios de Azure Databricks que no sean administradores pueden ver y filtrar por nombre de usuario mediante la SCIM API
Del 1 al 9 de julio de 2020: versión 3.23
Los usuarios que no son administradores ahora pueden ver los nombres de usuario y filtrar a los usuarios por su nombre mediante el punto de conexión SCIM /Users.
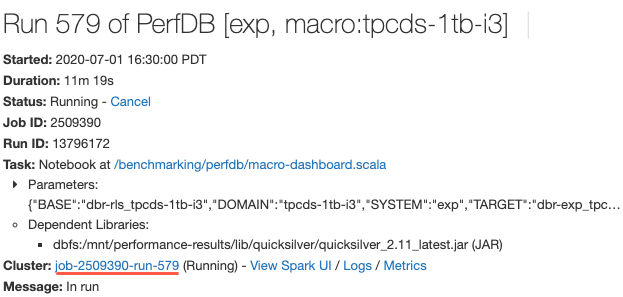
Vínculo para ver la especificación del clúster al ver los detalles de la ejecución del trabajo
Del 1 al 9 de julio de 2020: versión 3.23
Ahora, cuando vea los detalles de una ejecución de trabajo, puede hacer clic en un vínculo que lleve a la página de configuración del clúster, para ver su especificación. Antes, tendría que copiar el Id. de trabajo de la dirección URL e ir a la lista de clústeres para buscarlo.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de