Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los cuadernos de Databricks admiten el formato de código, autocompletar, varios lenguajes y comandos mágicos para desarrollar código en Python, SQL, Scala y R.
Para obtener más información sobre la funcionalidad avanzada disponible con el editor, como autocompletar, selección de variables, compatibilidad con varios cursores y diferencias en paralelo, consulte Navegar por el cuaderno de Databricks y el editor de archivos.
Cuando se usa el cuaderno o el editor de archivos, Genie Code está disponible para ayudarle a generar, explicar y depurar código. Consulte Uso de Genie Code para obtener más información.
Los cuadernos de Databricks también incluyen un depurador interactivo integrado para cuadernos de Python. Consulte Depurar cuadernos de Databricks.
Importante
El cuaderno debe estar asociado a una sesión de proceso activa para poder utilizar las funciones de asistencia al código, como el autocompletado, el formateo de código Python y el depurador.
Modularización del código
Con Databricks Runtime 11.3 LTS y versiones posteriores, puede crear y administrar archivos de código fuente en el área de trabajo de Azure Databricks y, a continuación, importar estos archivos en los cuadernos según sea necesario.
Para obtener más información sobre cómo trabajar con archivos de código fuente, consulte Compartir código entre cuadernos de Databricks y Trabajar con módulos de Python y R.
Formatear celdas de código
Azure Databricks proporciona herramientas que permiten dar formato a Python y código SQL en celdas del cuaderno. Estas herramientas reducen el esfuerzo de mantener el código con formato y ayudan a aplicar los mismos estándares de codificación en todos los cuadernos.
Biblioteca de formateo Python black
Importante
Esta característica está en versión preliminar pública.
Azure Databricks admite el formato de código Python mediante black dentro del cuaderno. El cuaderno debe estar asociado a un clúster con black y tokenize-rt Python paquetes instalados.
En Databricks Runtime 11.3 LTS y versiones posteriores, Azure Databricks preinstala black y tokenize-rt. Puede usar el formateador directamente sin necesidad de instalar estas bibliotecas.
En Databricks Runtime 10.4 LTS y versiones anteriores, debe instalar black==22.3.0 y tokenize-rt==4.2.1 desde PyPI en el cuaderno o el clúster para usar el formateador de Python. Puede ejecutar el siguiente comando en el cuaderno:
%pip install black==22.3.0 tokenize-rt==4.2.1
O instalar la biblioteca en el clúster.
Para obtener más información sobre la instalación de bibliotecas, consulte Python administración del entorno.
Para archivos y cuadernos en carpetas Git de Databricks, puede configurar el formateador de Python basado en el archivo pyproject.toml. Para usar esta característica, cree un archivo pyproject.toml en el directorio raíz de la carpeta de Git y configúrelo de acuerdo con el Formato de configuración negro. Edite la sección [tool.black] del archivo. La configuración se aplica cuando se da formato a cualquier archivo y cuaderno en esa carpeta de Git.
Cómo dar formato a Python y celdas SQL
Debe tener el permiso PUEDE EDITAR en el cuaderno para dar formato al código.
Azure Databricks utiliza un formateador SQL personalizado para dar formato al código SQL y el formateador de código black para Python.
Puede activar el formateador de las siguientes maneras:
Dar formato a una sola celda
- Atajo de teclado: pulse Cmd+Mayús+F.
- Menú contextual de comandos:
- Dar formato a una celda SQL: seleccione Dar formato de SQL en el menú contextual desplegable de comandos de una celda de SQL. Este elemento de menú solo es visible en las celdas del cuaderno de SQL o en las que tienen un comando
%sqllanguage magic. - Dar formato a una celda de Python: seleccione Dar formato de Python en el menú contextual desplegable de comandos de una celda de Python. Este elemento de menú solo es visible en las celdas del cuaderno de Python o en las que tienen un comando
%pythonlanguage magic.
- Dar formato a una celda SQL: seleccione Dar formato de SQL en el menú contextual desplegable de comandos de una celda de SQL. Este elemento de menú solo es visible en las celdas del cuaderno de SQL o en las que tienen un comando
- Menú Editar del cuaderno: seleccione una celda de Python o de SQL y elija Editar > Dar formato a la celda.
Dar formato a varias celdas
Seleccione varias celdas y elija Editar > Formato de celda(s). Si selecciona celdas de más de un idioma, solo se da formato a las celdas SQL y Python. Esto incluye las que usan
%sqly%python.Formatea todas las celdas Python y SQL en el cuaderno
Seleccione Editar > Dar formato al bloc de notas. Si el cuaderno contiene más de un lenguaje, solo se da formato a las celdas SQL y Python. Esto incluye las que usan
%sqly%python.
Para personalizar el formato de las consultas SQL, consulte Instrucciones SQL de formato personalizado.
Limitaciones del formato de código
- Black aplica los estándares PEP 8 para la sangría de 4 espacios. La sangría no se puede configurar.
- No se admite el formato de cadenas de Python insertadas dentro de una UDF de SQL. Del mismo modo, no se admite el formato de cadenas SQL dentro de un Python UDF.
Lenguajes de código en cuadernos
Establecimiento del idioma predeterminado
El idioma predeterminado del cuaderno aparece debajo del nombre del cuaderno.

Para cambiar el idioma predeterminado, haga clic en el botón idioma y seleccione el nuevo idioma en el menú desplegable. Para garantizar que los comandos actuales continúen funcionando, los comandos en el idioma predeterminado anterior tienen como prefijo automáticamente un comando mágico de lenguaje.
Combinación de lenguajes
De manera predeterminada, las celdas usan el lenguaje predeterminado del cuaderno. Puede invalidar el idioma predeterminado de una celda haciendo clic en el botón de idioma y seleccionando un idioma en el menú desplegable.
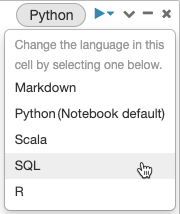
Como alternativa, puede usar el comando mágico de idioma %<language> al principio de una celda. Los comandos magic admitidos son %python, %r, %scala y %sql.
Nota:
Cuando se invoca un comando mágico de lenguaje, el comando se envía al REPL en el contexto de ejecución del cuaderno. Las variables definidas en un lenguaje (y, por lo tanto, en el REPL de ese lenguaje) no están disponibles en el REPL de otro lenguaje. Los REPL solo pueden compartir el estado mediante recursos externos, como archivos en DBFS u objetos del almacenamiento de objetos.
Los cuadernos también admiten algunos comandos mágicos auxiliares:
-
%sh: le permite ejecutar código shell en su cuaderno de notas. Para producir un error en la celda si el comando del shell tiene un estado de salida distinto de cero, agregue la opción-e. Este comando solo se ejecuta en el controlador de Apache Spark y no en los trabajadores. Para ejecutar un comando del shell en todos los nodos, use un script de inicio. -
%fs: le permite usar comandos del sistema de archivosdbutils. Por ejemplo, para ejecutar el comandodbutils.fs.lspara enumerar archivos, puede especificar%fs lsen su lugar. Para obtener más información, consulte Trabajar con archivos en Azure Databricks. -
%md: permite incluir varios tipos de documentación, como texto, imágenes y fórmulas matemáticas y ecuaciones. Consulte la sección siguiente.
Resaltado de sintaxis de SQL y autocompletar en comandos de Python
El resaltado de sintaxis y SQL autocomplete están disponibles cuando se usa SQL dentro de un comando de Python, como en un comando spark.sql.
Explorar los resultados de las celdas SQL
En un cuaderno de Databricks, los resultados de una celda de lenguaje SQL se hacen automáticamente disponibles como un DataFrame implícito asignado a la variable _sqldf. A continuación, puede usar esta variable en cualquier Python y celdas SQL que ejecute después, independientemente de su posición en el cuaderno.
Nota:
Esta característica tiene las siguientes limitaciones:
- La
_sqldfvariable no está disponible en cuadernos que utilizan un almacén de SQL para el cómputo. - El uso de
_sqldfen las celdas de Python posteriores se admite en Databricks Runtime 13.3 y versiones posteriores. - El uso
_sqldfde celdas SQL posteriores solo se admite en Databricks Runtime 14.3 y versiones posteriores. - Si la consulta usa las palabras clave
CACHE TABLEoUNCACHE TABLE, la_sqldfvariable no está disponible.
En la captura de pantalla siguiente se muestra cómo se puede usar _sqldf en las celdas Python y SQL siguientes:
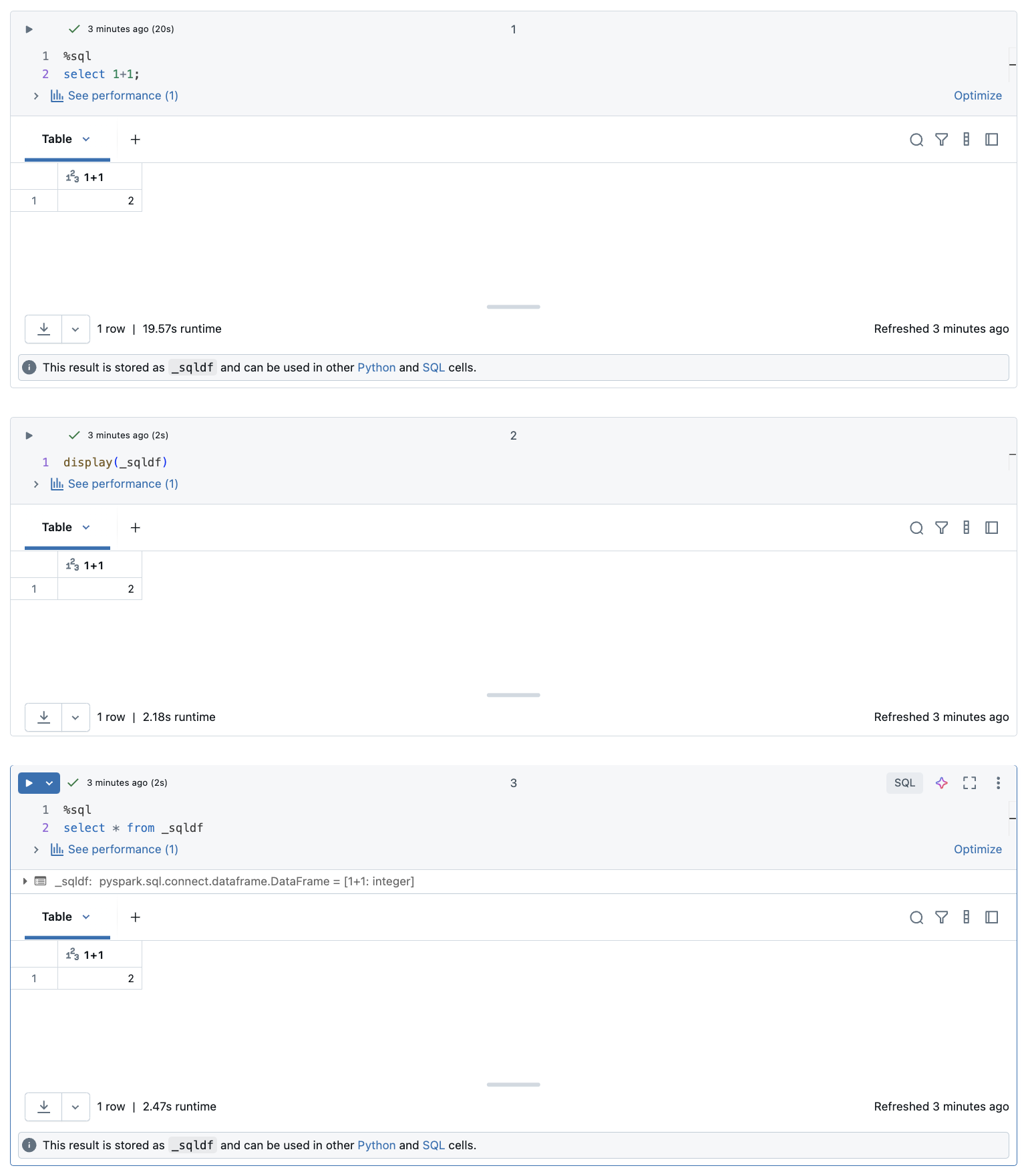
Importante
La variable _sqldf se reasigna cada vez que se ejecuta una celda SQL. Para evitar perder la referencia a un resultado de DataFrame específico, asígnelo a un nuevo nombre de variable antes de ejecutar la siguiente celda SQL:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Ejecución de celdas SQL en paralelo
Mientras se ejecuta un comando y el cuaderno se adjunta a un clúster interactivo, puede ejecutar una celda SQL simultáneamente con el comando actual. La celda SQL se ejecuta en una nueva sesión paralela.
Para ejecutar una celda en paralelo:
Haga clic en Ejecutar ahora. La celda se ejecuta inmediatamente.
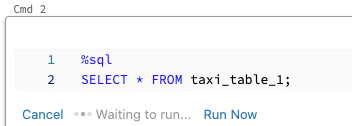
Dado que la celda se ejecuta en una nueva sesión, las vistas temporales, las UDF y la implicit Python DataFrame (_sqldf) no se admiten para las celdas que se ejecutan en paralelo. Además, los nombres predeterminados de catálogo y de base de datos se usan durante la ejecución en paralelo. Si el código hace referencia a una tabla de un catálogo o base de datos diferente, debe especificar el nombre de la tabla mediante el espacio de nombres de tres niveles (catalog.schema.table).
Ejecutar celdas SQL en un almacén SQL
Puedes ejecutar comandos SQL en un notebook de Databricks en un almacén SQL, un tipo de recurso computacional optimizado para análisis SQL. Consulte Uso de un libro con un almacén SQL.
Uso de comandos mágicos
Los cuadernos de Databricks admiten varios comandos mágicos que amplían la funcionalidad más allá de la sintaxis estándar para simplificar las tareas comunes. Las magias de línea tienen el prefijo % y se aplican a una sola línea. Las magias celulares tienen el prefijo %% y se aplican a todo el cuerpo de la celda.
| Comando mágico | Ejemplo | Descripción |
|---|---|---|
%python |
%pythonprint("Hello") |
Cambie el idioma de la celda a Python. Ejecuta código Python en la celda. |
%r |
%rprint("Hello") |
Cambie el lenguaje de celda a R. Ejecuta código R en la celda. |
%scala |
%scalaprintln("Hello") |
Cambie el lenguaje de celda a Scala. Ejecuta código Scala en la celda. |
%sql |
%sqlSELECT * FROM table |
Cambie el lenguaje de celda a SQL. Los resultados están disponibles como _sqldf en celdas Python/SQL. |
%md |
%md# TitleContent here |
Cambie el idioma de celda a Markdown. Representa el contenido de Markdown en la celda. Admite texto, imágenes, fórmulas y LaTeX. |
%pip |
%pip install pandas |
Instalar paquetes de Python (dentro del ámbito del cuaderno). Consulte Bibliotecas de Python cuyo ámbito es Notebook. |
%run |
%run /path/to/notebook |
Ejecute otro cuaderno, importando sus funciones y variables. Consulte Flujos de trabajo del Notebook. |
%fs |
%fs ls /path |
Ejecute comandos del sistema de archivos dbutils. Una abreviatura de los comandos dbutils.fs. Consulte Trabajar con archivos. |
%sh |
%sh ls -la |
Ejecute comandos de shell. Solo se ejecuta en el nodo del controlador. Utilizar -e para que se produzca un error en caso de error. |
%tensorboard |
%tensorboard --logdir /logs |
Muestra la interfaz de usuario de TensorBoard en línea. Solo está disponible en Databricks Runtime ML. Consulte TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Establezca el tamaño máximo de salida de celda. Intervalo: 1-20 MB. Se aplica a todas las celdas posteriores del cuaderno. |
%skip |
%skipprint("This won't run") |
Omitir la ejecución de la celda. Impide que la celda se ejecute cuando se ejecuta el cuaderno. |
%%profile |
%%profilemy_function() |
Perfilar la ejecución del código Python. Muestra un árbol de llamadas jerárquico con información de tiempo. Requiere Databricks Runtime 17.2 y versiones posteriores. |
%%oprofile |
%%oprofilemy_function() |
Perfilar la creación de objetos durante la ejecución de la celda. Muestra una tabla de nuevos objetos netos creados, agrupados por tipo. Requiere Databricks Runtime 17.2 y versiones posteriores. |
%uv pip |
%uv pip install simplejson |
Instalar y administrar paquetes de Python (dentro del ámbito del cuaderno) con uv y los subcomandos estándar de pip (install, uninstall, list, show, freeze, check, tree). Consulte Instalación más rápida con %uv pip. |
Nota:
IPython Automagic: los cuadernos de Databricks tienen IPython automagic habilitado de forma predeterminada, lo que permite que determinados comandos como pip funcionen sin el % prefijo. Por ejemplo, pip install pandas funciona igual que %pip install pandas.
Importante
- Las variables y el estado están aislados entre REPLs de diferentes lenguajes de programación. Por ejemplo, las variables de Python no son accesibles en celdas de Scala.
- Una celda del cuaderno solo puede tener un comando mágico, y debe ser la primera línea de la celda.
-
%rundebe aparecer solo en una celda, ya que ejecuta todo el cuaderno en línea. - Al usar
%pipen Databricks Runtime 12.2 LTS y versiones anteriores, coloque todos los comandos de instalación de paquetes al principio de su cuaderno, ya que el estado de Python se restablece después de la instalación.