Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describen las principales diferencias entre el procesamiento por lotes y el streaming, dos semánticas de procesamiento de datos diferentes que se usan para cargas de trabajo de ingeniería de datos, incluida la ingesta, la transformación y el procesamiento en tiempo real.
El streaming se asocia normalmente con baja latencia y procesamiento continuo desde buses de mensajes, como Apache Kafka.
Sin embargo, en Azure Databricks tiene una definición más amplia. El motor subyacente de las canalizaciones declarativas de Spark de Lakeflow (Apache Spark y Structured Streaming) tiene una arquitectura unificada para el procesamiento por lotes y streaming:
- El motor puede tratar orígenes como el almacenamiento de objetos en la nube y Delta Lake como orígenes de streaming para un procesamiento incremental eficaz.
- El procesamiento de streaming se puede ejecutar de manera desencadenada y continua, lo que le proporciona la flexibilidad de controlar los costos y los inconvenientes de rendimiento de las cargas de trabajo de streaming.
A continuación se muestran las diferencias semánticas fundamentales que distinguen el lote y el streaming, incluidas sus ventajas y desventajas, y consideraciones para elegirlas para las cargas de trabajo.
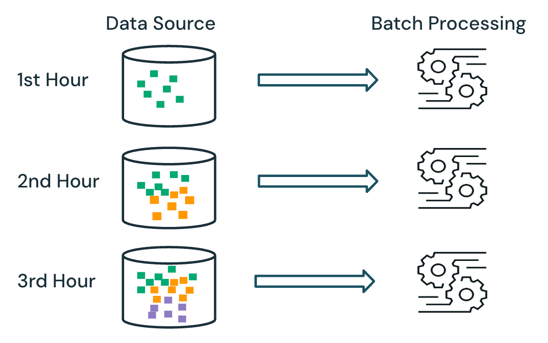
Semántica de Procesamiento por Lotes
Con el procesamiento por lotes, el motor no realiza un seguimiento de los datos que ya se están procesando en el origen. Todos los datos disponibles actualmente en el origen se procesan en el momento del procesamiento. En la práctica, un origen de datos por lotes normalmente se particiona lógicamente, por ejemplo, por día o región, para limitar el reprocesamiento de datos.
Por ejemplo, calcular el precio medio de venta de los artículos, agregado con una granularidad horaria, para un evento de ventas llevado a cabo por una empresa de comercio electrónico se puede programar como procesamiento por lotes para calcular el precio medio de ventas cada hora. Con el lote, los datos de las horas anteriores se vuelven a procesar cada hora y los resultados calculados anteriormente se sobrescriben para reflejar los resultados más recientes.
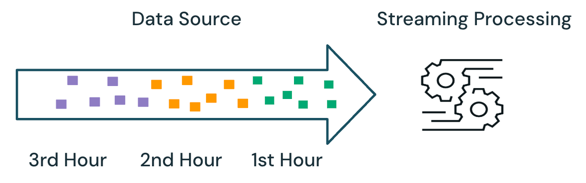
Semántica de streaming
Con el procesamiento de streaming, el motor realiza un seguimiento de los datos que se procesan y solo procesa los nuevos datos en ejecuciones posteriores. En el ejemplo anterior, puede programar el procesamiento de streaming en lugar del procesamiento por lotes para calcular el precio medio de ventas cada hora. Con el streaming, solo se procesan los nuevos datos agregados al origen desde la última ejecución. Los resultados recién calculados deben anexarse a los resultados calculados anteriormente para comprobar los resultados completos.
Procesamiento por lotes frente al streaming
En el ejemplo anterior, el streaming es mejor que el procesamiento por lotes porque no procesa los mismos datos procesados en ejecuciones anteriores. Sin embargo, el procesamiento de streaming se vuelve más complejo con escenarios como datos de llegada desordenados y de llegada tardía en el origen.
Un ejemplo de datos de llegada tardía es si algunos datos de ventas de la primera hora no llegan al origen hasta la segunda hora:
- En el procesamiento por lotes, los datos de llegada tardía de la primera hora se procesarán con datos de la segunda hora y los datos existentes de la primera hora. Los resultados anteriores de la primera hora se sobrescribirán y corregirán con los datos de llegada tardía.
- En el procesamiento de streaming, los datos que lleguen tarde en la primera hora se procesarán sin incluir los demás datos de esa primera hora que ya se hayan procesado. La lógica de procesamiento debe almacenar la información de suma y recuento de los cálculos promedios de la primera hora para actualizar correctamente los resultados anteriores.
Estas complejidades de streaming suelen introducirse cuando el procesamiento tiene estado, como combinaciones, agregaciones y desduplicaciones.
En el caso del procesamiento de streaming sin estado, como anexar nuevos datos del origen, manejar los datos desordenados y de llegada tardía es menos complejo, ya que los datos de llegada tardía se pueden anexar a los resultados anteriores a medida que llegan al origen.
En la tabla siguiente se describen las ventajas y desventajas del procesamiento por lotes y streaming y las distintas características del producto que admiten estas dos semánticas de procesamiento en Databricks Lakeflow.
| Procesamiento semántico | Ventajas | Desventajas | Productos de ingeniería de datos |
|---|---|---|---|
| Lote |
|
|
|
| Transmisión en línea |
|
|
|
Recomendaciones
En la tabla siguiente se describe la semántica de procesamiento recomendada en función de las características de las cargas de trabajo de procesamiento de datos en cada capa de la arquitectura medallion.
| Capa de Medallón | Características de carga de trabajo | Recomendación |
|---|---|---|
| Bronce |
|
|
| Plata |
|
|
| Oro |
|
|