Uso de Databricks SQL en un trabajo de Azure Databricks
Puede usar el tipo de tarea SQL en un trabajo de Azure Databricks, lo que le permite crear, programar, operar y supervisar flujos de trabajo que incluyen objetos SQL de Databricks, como consultas, paneles heredados y alertas. Por ejemplo, el flujo de trabajo puede ingerir datos, preparar los datos, realizar análisis mediante consultas de Databricks SQL y, después, mostrar los resultados en un panel heredado.
En este artículo se proporciona un flujo de trabajo de ejemplo que crea un panel heredado que muestra métricas para las contribuciones de GitHub. En este ejemplo, hará lo siguiente:
- Ingerir datos de GitHub usando un script de Python y la API de REST de GitHub.
- Transformar los datos de GitHub usando una canalización de Delta Live Tables.
- Desencadenar consultas de Databricks SQL realizando análisis sobre los datos preparados.
- Mostrará el análisis en un panel heredado.
Antes de empezar
Necesita lo siguiente para poder llevar a cabo este tutorial:
- Un token de acceso personal de GitHub. Este token debe tener el permiso de repositorio.
- Un almacén SQL sin servidor o un almacén SQL pro. Consulte Tipos de almacenes de SQL.
- Un ámbito de secretos de Databricks. El ámbito de secretos se usa para almacenar de forma segura los tokens de GitHub. Consulte Paso 1: Almacenar el token de GitHub en un secreto.
Paso 1: Almacenar los tokens de GitHub en un secreto
En lugar de codificar credenciales como el token de acceso personal de GitHub en un trabajo, Databricks recomienda usar un ámbito de secretos para almacenarlos y administrarlos de forma segura. Los siguientes comandos de la CLI de Databricks son un ejemplo de cómo crear un ámbito de secretos y almacenar el token de GitHub en un secreto en ese ámbito:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- Reemplace
<scope-namepor el nombre de un ámbito de secretos de Azure Databricks para almacenar los tokens. - Reemplace
<token-key>por el nombre de una clave para asignar a los tokens. - Reemplace
<token>por el valor del token de acceso personal de GitHub.
Paso 2: Crear un script para obtener los datos de GitHub
El siguiente script de Python usa la API de REST de GitHub para obtener datos sobre confirmaciones y contribuciones de un repositorio de GitHub. Los argumentos de entrada especifican el repositorio de GitHub. Los registros se guardan en una ubicación de DBFS especificada por otro argumento de entrada.
En este ejemplo se usa DBFS para almacenar el script de Python, pero también se pueden usar carpetas de Git de Databricks o archivos de área de trabajo para almacenar y administrar el script.
Guarde este script en una ubicación en el disco local:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()Cargue el script en DBFS:
- Vaya a su página de aterrizaje de Azure Databricks y haga clic en
 Catálogo en la barra lateral.
Catálogo en la barra lateral. - Haga clic en Examinar DBFS.
- En el explorador de archivos DBFS, haga clic en Cargar. Aparecerá el cuadro de diálogo Cargar datos en DBFS.
- Escriba una ruta de acceso en DBFS para almacenar el script, haga clic en Coloque los archivos que quiera cargar o haga clic para examinar y seleccione el script de Python.
- Haga clic en Done(Listo).
- Vaya a su página de aterrizaje de Azure Databricks y haga clic en
Paso 3: Crear una canalización de Delta Live Tables para procesar los datos de GitHub
En esta sección, se crea una canalización de Delta Live Tables para convertir los datos sin procesar de GitHub en tablas que puedan ser analizadas mediante consultas de Databricks SQL. Para crear la canalización, realice los pasos siguientes:
En la barra lateral, haga clic en
 Nuevo y seleccione Cuaderno en el menú. Aparece el cuadro de diálogo Create Notebook (Crear cuaderno).
Nuevo y seleccione Cuaderno en el menú. Aparece el cuadro de diálogo Create Notebook (Crear cuaderno).En Lenguaje predeterminado, escriba un nombre y seleccione Python. Puede dejar el clúster en el valor predeterminado. El entorno de ejecución de Delta Live Tables crea un clúster antes de que ejecute la canalización.
Haga clic en Crear.
Copie el ejemplo de código Python y péguelo en su nuevo cuaderno. Puede agregar el código de ejemplo a una sola celda del cuaderno o a varias celdas.
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )En la barra lateral, haga clic en
 Flujos de trabajo, luego en la pestaña Delta Live Tables y, después, en Crear canalización.
Flujos de trabajo, luego en la pestaña Delta Live Tables y, después, en Crear canalización.Asigne un nombre a la canalización, por ejemplo,
Transform GitHub data.En el campo Bibliotecas de cuadernos, escriba la ruta de acceso al cuaderno o haga clic en
 para seleccionar el cuaderno.
para seleccionar el cuaderno.Haga clic en Añadir configuración. En el cuadro de texto
Key, escribacommits-path. En el cuadro de textoValue, introduzca la ruta de acceso de DBFS en la que se escribirán los registros de GitHub. Puede ser cualquier ruta de acceso que elija y es la misma que usará al configurar la primera tarea de Python cuando cree el flujo de trabajo.Haga clic de nuevo en Añadir configuración. En el cuadro de texto
Key, escribacontribs-path. En el cuadro de textoValue, introduzca la ruta de acceso de DBFS en la que se escribirán los registros de GitHub. Puede ser cualquier ruta de acceso que elija y es la misma que usará al configurar la segunda tarea de Python cuando cree el flujo de trabajo.En el campo Destino, escriba una base de datos de destino, por ejemplo,
github_tables. Establecer una base de datos de destino publica los datos de salida en el metastore y es necesario para las consultas posteriores que analizan los datos producidos por la canalización.Haga clic en Save(Guardar).
Paso 4: Crear un flujo de trabajo para ingerir y transformar los datos de GitHub
Antes de analizar y visualizar los datos de GitHub con Databricks SQL, es necesario ingerir y preparar los datos. Para crear un flujo de trabajo para completar estas tareas, realice los pasos siguientes:
Cree un trabajo de Azure Databricks y añada la primera tarea
Vaya a la página de aterrizaje de Azure Databricks y realice una de las siguientes acciones:
- En la barra lateral, haga clic en Flujos de trabajo y, después, en
 .
. - En la barra lateral, haga clic en Nuevo y seleccione Trabajo en el menú.
- En la barra lateral, haga clic en
En el cuadro de diálogo de tarea que aparece en la pestaña Tareas, reemplace Agregar un nombre para el trabajo... por el nombre del trabajo, por ejemplo,
GitHub analysis workflow.En el campo Nombre de tarea, escriba el nombre que quiera darle a la tarea, por ejemplo,
get_commits.En Tipo, seleccione Script de Python.
En Origen, seleccione DBFS/S3.
En Ruta de acceso, escriba la ruta de acceso al script en DBFS.
En Parámetros, escriba los argumentos siguientes para el script de Python:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Reemplace
<owner>por el nombre del propietario del repositorio. Por ejemplo, para capturar registros del repositoriogithub.com/databrickslabs/overwatch, escribadatabrickslabs. - Reemplace
<repo>por el nombre del repositorio, por ejemplo,overwatch. - Reemplace
<DBFS-output-dir>por una ruta de acceso de DBFS para almacenar los registros capturados desde GitHub. - Reemplace
<scope-name>por el nombre del ámbito de secreto que creó para almacenar el token de GitHub. - Reemplace
<github-token-key>por el nombre de la clave que asignó al token de GitHub.
- Reemplace
Haga clic en Guardar tarea.
Agregar otra tarea
Haga clic en
 debajo de la tarea que acaba de crear.
debajo de la tarea que acaba de crear.En el campo Nombre de tarea, escriba el nombre que quiera darle a la tarea, por ejemplo,
get_contributors.En Tipo, seleccione el tipo de tarea Script de Python.
En Origen, seleccione DBFS/S3.
En Ruta de acceso, escriba la ruta de acceso al script en DBFS.
En Parámetros, escriba los argumentos siguientes para el script de Python:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Reemplace
<owner>por el nombre del propietario del repositorio. Por ejemplo, para capturar registros del repositoriogithub.com/databrickslabs/overwatch, escribadatabrickslabs. - Reemplace
<repo>por el nombre del repositorio, por ejemplo,overwatch. - Reemplace
<DBFS-output-dir>por una ruta de acceso de DBFS para almacenar los registros capturados desde GitHub. - Reemplace
<scope-name>por el nombre del ámbito de secreto que creó para almacenar el token de GitHub. - Reemplace
<github-token-key>por el nombre de la clave que asignó al token de GitHub.
- Reemplace
Haga clic en Guardar tarea.
Agregar una tarea para transformar los datos
- Haga clic en debajo de la tarea que acaba de crear.
- En el campo Nombre de tarea, escriba el nombre que quiera darle a la tarea, por ejemplo,
transform_github_data. - En Tipo, seleccione Canalización de Delta Live Tables y escriba un nombre para la tarea.
- En Canalización, seleccione la canalización creada en el Paso 3: Crear una canalización de Delta Live Tables para procesar los datos de GitHub.
- Haga clic en Crear.
Paso 5: Ejecutar el flujo de trabajo de transformación de datos
Haga clic en  para ejecutar el flujo de trabajo. Para ver detalles de la ejecución, haga clic en el vínculo de la columna Hora de inicio de la ejecución en la vista Ejecuciones de trabajo. Haga clic en cada tarea para ver los detalles de la ejecución de la tarea.
para ejecutar el flujo de trabajo. Para ver detalles de la ejecución, haga clic en el vínculo de la columna Hora de inicio de la ejecución en la vista Ejecuciones de trabajo. Haga clic en cada tarea para ver los detalles de la ejecución de la tarea.
Paso 6: (Opcional) Para ver los datos de salida una vez completada la ejecución del flujo de trabajo, realice los pasos siguientes:
- En la vista de detalles de ejecución, haga clic en la tarea Delta Live Tables.
- En el panel Detalles de ejecución de la tarea, haga clic en el nombre de la canalización en Canalización. La página Detalles de canalización aparecerá.
- Seleccione la tabla
commits_by_authoren el DAG de canalización. - Haga clic en el nombre de la tabla junto a Metastore en el panel commits_by_author. Se abre la página del Explorador de catálogos.
En el Explorador de catálogos, puede ver el esquema de tabla, los datos de ejemplo y otros detalles de los datos. Siga los mismos pasos para ver los datos de la tabla github_contributors_raw.
Paso 7: Eliminar los datos de GitHub
En una aplicación real, es posible que esté continuamente ingiriendo y procesando datos. Dado que este ejemplo descarga y procesa todo el conjunto de datos, debe eliminar los datos de GitHub ya descargados para evitar un error al volver a ejecutar el flujo de trabajo. Para quitar los datos descargados, realice los pasos siguientes:
Cree un cuaderno y escriba los siguientes comandos en la primera celda:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)Reemplace
<commits-path>y<contributors-path>por las rutas de acceso de DBFS que configuró al crear las tareas de Python.Haga clic en
 y seleccione Ejecutar celda.
y seleccione Ejecutar celda.
También puede agregar este cuaderno como una tarea en el flujo de trabajo.
Paso 8: Crear las consultas de Databricks SQL
Después de ejecutar el flujo de trabajo y crear las tablas necesarias, cree consultas para analizar los datos preparados. Para crear las consultas y visualizaciones de ejemplo, realice los pasos siguientes:
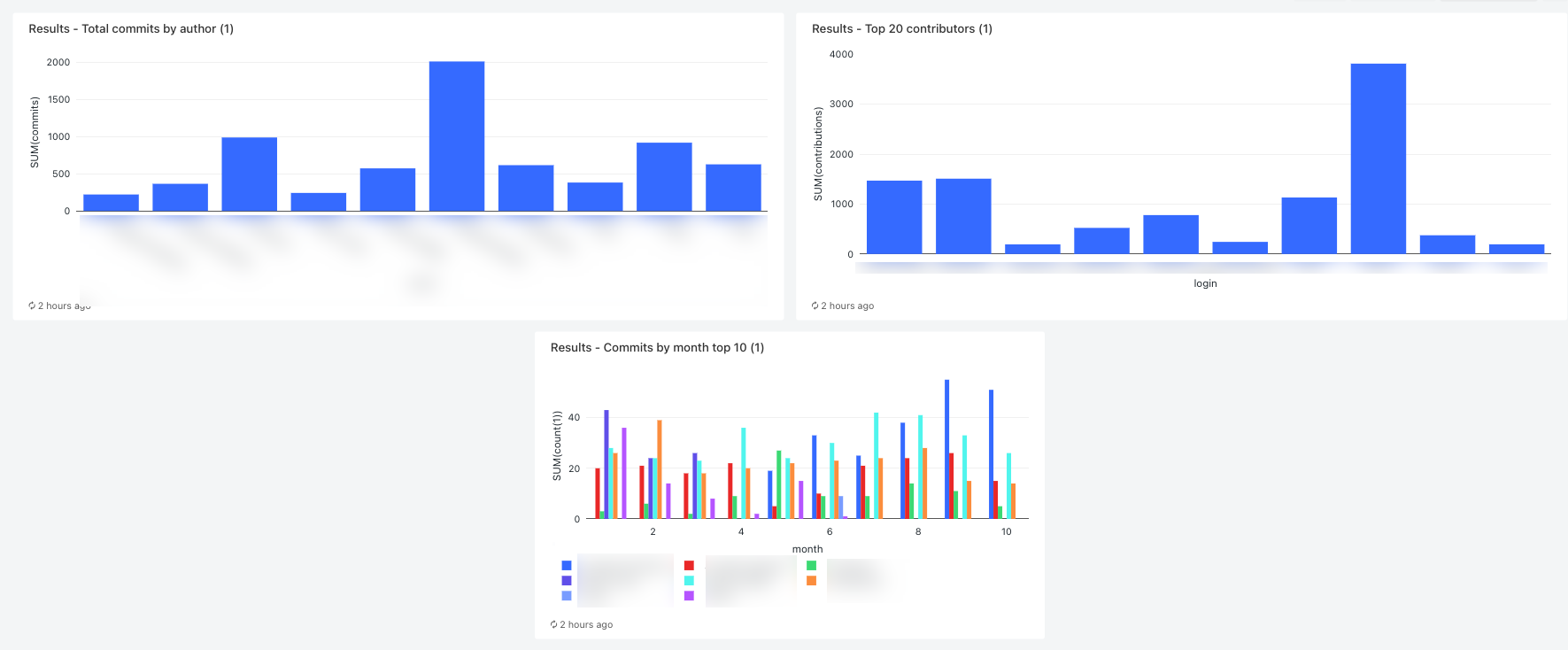
Mostrar los 10 principales colaboradores por mes
Haga clic en el icono situado bajo el logotipo de Databricks
 en la barra lateral y seleccione SQL.
en la barra lateral y seleccione SQL.Haga clic en Crear una consulta para abrir el editor de consultas de Databricks SQL.
Asegúrese de que el valor se haya establecido en hive_metastore. Haga clic en valor predeterminado junto a hive_metastore y establezca la base de datos en el valor de Destino establecido en la canalización de Delta Live Tables.
En la pestaña Nueva consulta, escriba la siguiente consulta:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, nameHaga clic en la pestaña Nueva consulta y cambie el nombre de la consulta, por ejemplo,
Commits by month top 10 contributors.De forma predeterminada, los resultados se muestran como una tabla. Para cambiar cómo se visualizan los datos, por ejemplo, mediante un gráfico de barras, en el panel Resultados, haga clic en
 y haga clic en Editar.
y haga clic en Editar.En Tipo de visualización, seleccione Barra.
En Columna X, seleccione mes.
En Columnas Y, seleccione recuento(1).
En Agrupar por, seleccione nombre.
Haga clic en Save(Guardar).
Mostrar los 20 principales colaboradores
Haga clic en + > Crear nueva consulta y asegúrese de que el catálogo está establecido en hive_metastore. Haga clic en valor predeterminado junto a hive_metastore y establezca la base de datos en el valor de Destino establecido en la canalización de Delta Live Tables.
Escriba la siguiente consulta:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20Haga clic en la pestaña Nueva consulta y cambie el nombre de la consulta, por ejemplo,
Top 20 contributors.Para cambiar la visualización de la tabla predeterminada, en el panel Resultados, haga clic en los
y haga clic en Editar.En Tipo de visualización, seleccione Barra.
En la Columna X, seleccione inicio de sesión.
En Columnas Y, seleccione contribuciones.
Haga clic en Save(Guardar).
Mostrar el total de confirmaciones por autor
Haga clic en + > Crear nueva consulta y asegúrese de que el catálogo está establecido en hive_metastore. Haga clic en valor predeterminado junto a hive_metastore y establezca la base de datos en el valor de Destino establecido en la canalización de Delta Live Tables.
Escriba la siguiente consulta:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10Haga clic en la pestaña Nueva consulta y cambie el nombre de la consulta, por ejemplo,
Total commits by author.Para cambiar la visualización de la tabla predeterminada, en el panel Resultados, haga clic en los
y haga clic en Editar.En Tipo de visualización, seleccione Barra.
En la Columna X, seleccione nombre.
En Columnas Y, seleccione confirmaciones.
Haga clic en Save(Guardar).
Paso 9: Crear un panel
- En la barra lateral, haga clic en
 Paneles
Paneles - Haga clic en Crear panel.
- Escriba un nombre para el panel, por ejemplo,
GitHub analysis. - Para cada consulta y visualización creada en el Paso 8: Crear consultas de Databricks SQL, haga clic en Añadir > Visualización y seleccione cada visualización.
Paso 10: Añada las tareas SQL al flujo de trabajo
Para añadir las nuevas tareas de consulta al flujo de trabajo que creó en Crear un trabajo de Azure Databricks y añadir la primera tarea, para cada consulta que creó en el Paso 8: Crear consultas de Databricks SQL:
- Haga clic en Flujos de trabajo en la barra lateral.
- En la columna Name (Nombre), haga clic en el nombre de trabajo.
- Haga clic en la ficha Tareas.
- Haga clic en debajo de la última tarea.
- Escriba un nombre para la tarea, en Tipo, seleccione SQL, y en Tarea SQL seleccione Consulta.
- Seleccione la consulta en consulta SQL.
- En Almacén SQL, seleccione un almacén SQL sin servidor o un almacén SQL pro para ejecutar la tarea.
- Haga clic en Crear.
Paso 11: Añadir una tarea de panel
- Haga clic en debajo de la última tarea.
- Escriba un nombre para la tarea, en Tipo, seleccione SQL, y en Tarea SQL seleccione Panel heredado.
- Seleccione el panel creado en Paso 9: Crear un panel.
- En Almacén SQL, seleccione un almacén SQL sin servidor o un almacén SQL pro para ejecutar la tarea.
- Haga clic en Crear.
Paso 12: Ejecutar el flujo de trabajo completo
Para ejecutar el flujo de trabajo, haga clic en el . Para ver detalles de la ejecución, haga clic en el vínculo de la columna Hora de inicio de la ejecución en la vista Ejecuciones de trabajo.
Paso 13: Ver los resultados
Para ver los resultados cuando finalice la ejecución, haga clic en la tarea final del panel y haga clic en el nombre del panel bajo Panel de SQL en el panel derecho.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de