Uso de transformaciones de dbt en un trabajo de Azure Databricks
Los proyectos de dbt Core se pueden ejecutar como una tarea en un trabajo de Azure Databricks. Si ejecuta un proyecto de dbt Core como una tarea de trabajo, podrá beneficiarse de las siguientes características de los trabajos de Azure Databricks:
- Automatización de las tareas dbt y programación de flujos de trabajo que las incluyan.
- Supervisión de las transformaciones de dbt y envío de notificaciones sobre el estado de estas.
- Inclusión del proyecto de dbt en un flujo de trabajo que tenga otras tareas. Por ejemplo, el flujo de trabajo puede ingerir datos con Auto Loader, transformar los datos con dbt y analizar los datos con una tarea de cuaderno.
- Archivado automático de los artefactos de las ejecuciones de trabajos, entre los que se incluyen los registros, los resultados, los manifiestos y la configuración.
Para obtener más información sobre dbt Core, consulte la documentación de dbt.
Flujos de trabajo de desarrollo y producción
Una buena práctica con Databricks consiste en desarrollar los proyectos de dbt con un almacenamiento SQL de Databricks. Si usa un almacenamiento SQL de Databricks, podrá probar el código SQL que se genera con dbt, así como usar el historial de consultas del almacenamiento SQL para depurar las consultas que se generan con dbt.
Para ejecutar las transformaciones de dbt que estén en fase de producción, una buena práctica consiste en usar la tarea dbt en un trabajo de Databricks. De manera predeterminada, la tarea dbt ejecutará el proceso de Python de dbt mediante un proceso de Azure Databricks y el SQL que se genere con dbt se ejecutará en el almacenamiento SQL que se seleccione.
Puede ejecutar transformaciones de dbt en un almacenamiento de SQL sin servidor, un almacenamiento de SQL Pro, un proceso de Azure Databricks o cualquier otro almacenamiento compatible con dbt. En este artículo se describen las dos primeras opciones con ejemplos.
Si el área de trabajo está habilitada para Unity Catalog y Flujos de trabajo sin servidor está habilitado, el trabajo se ejecuta en un proceso sin servidor de manera predeterminada.
Nota:
Si los modelos dbt se desarrollan con un almacenamiento SQL y se ejecutan en un proceso de Azure Databricks durante la fase de producción, puede que se experimenten diferencias sutiles tanto en el rendimiento como en la compatibilidad del lenguaje SQL. Databricks recomienda usar la misma versión de Databricks Runtime para el proceso y el almacenamiento SQL.
Requisitos
Para obtener información sobre cómo usar dbt Core y el paquete
dbt-databrickspara crear y ejecutar proyectos de dbt en el entorno de desarrollo que use, consulte Conexión a dbt Core.Use el paquete de Databricks dbt-databricks en lugar del paquete dbt-spark. El paquete dbt-databricks es una bifurcación de dbt-spark que está optimizada para su uso en Databricks.
Para usar proyectos de dbt en un trabajo de Azure Databricks, deberá configurar la integración de Git con las carpetas Git de Databricks. Los proyectos de dbt no se pueden ejecutar desde DBFS.
Debe tener habilitados los almacenes de SQL profesionales o sin servidor.
Debe tener el derecho de SQL de Databricks.
Creación y ejecución de un trabajo de dbt por primera vez
En el siguiente ejemplo se usa el proyecto jaffle_shop; un proyecto de ejemplo que sirve para mostrar los conceptos básicos de dbt. Para crear un trabajo donde se ejecute el proyecto "jaffle shop", complete los pasos siguientes.
Vaya a la página de aterrizaje de Azure Databricks y realice una de las siguientes acciones:
- Haga clic en
 Jobs en la barra lateral y haga clic en
Jobs en la barra lateral y haga clic en  .
. - En la barra lateral, haga clic en
 Nuevo y seleccione Trabajo.
Nuevo y seleccione Trabajo.
- Haga clic en
En el cuadro de texto de la tarea en la pestaña Tareas, reemplace Agregar un nombre para el trabajo... por el nombre del trabajo que quiera usar.
En el campo Nombre de tarea, escriba el nombre que quiera darle a la tarea.
En el campo Tipo, seleccione el tipo de tarea dbt.
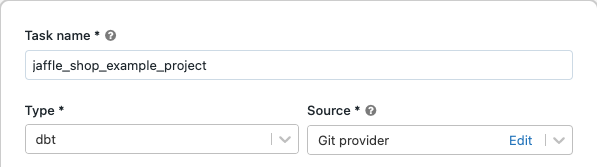
En el menú desplegable Origen, puede seleccionar Área de trabajo a fin de usar un proyecto dbt ubicado en una carpeta del área de trabajo de Azure Databricks o Proveedor de Git para un cuaderno ubicado en un repositorio de Git remoto. Dado que en este ejemplo se usa el proyecto de la tienda jaffle ubicado en un repositorio de Git, seleccione Proveedor de Git, haga clic en Editar y escriba los detalles del repositorio de GitHub de la tienda jaffle.
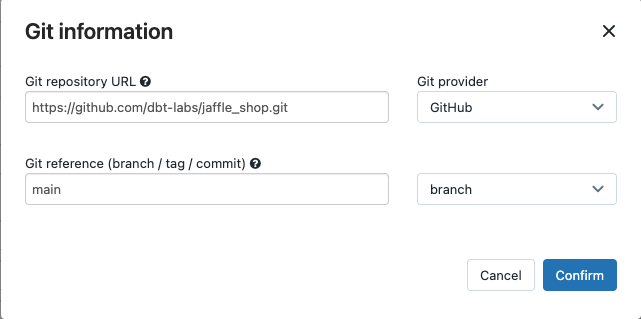
- En Dirección URL del repositorio de GIT, escriba la URL del proyecto "jaffle shop".
- En el campo Referencia de GIT (rama / etiqueta / commit), introduzca el valor
main. También puede usar una etiqueta o SHA.
Haga clic en Confirmar.
En los cuadros de texto comandos dbt, especifique los comandos dbt que se van a ejecutar (deps, seed y run). Debe agregar el prefijo
dbta todos los comandos. Los comandos se ejecutarán en el orden que se especifique.
En SQL warehouse, seleccione un almacenamiento de SQL para ejecutar el código SQL generado por dbt. En el menú desplegable SQL warehouse solo se muestran los almacenamientos de SQL sin servidor y Pro.
(Opcional) Es posible especificar un esquema para la salida de la tarea. De manera predeterminada, se usa el esquema
default.(Opcional) Si desea cambiar la configuración de proceso que ejecuta dbt Core, haga clic en Proceso de la CLI de dbt.
(Opcional) Es posible especificar una versión del paquete dbt-databricks para la tarea. Por ejemplo, para anclar la tarea dbt a una versión específica para las fases de desarrollo y producción, siga estos pasos:
- En Bibliotecas dependientes, haga clic en el
 , que se muestra al lado de la versión actual del paquete dbt-databricks.
, que se muestra al lado de la versión actual del paquete dbt-databricks. - Haga clic en Agregar.
- En el cuadro de diálogo Agregar biblioteca dependiente, seleccione PyPI e introduzca la versión del paquete dbt en el cuadro de texto Paquete (por ejemplo,
dbt-databricks==1.6.0). - Haga clic en Agregar.

Nota
Una buena práctica en Databricks consiste en anclar las tareas de dbt a una versión específica del paquete dbt-databricks para asegurarse de que se va a usar la misma versión para las ejecuciones de las fases de desarrollo y producción. Use la versión 1.6.0 del paquete de Databricks dbt-databricks o una posterior.
- En Bibliotecas dependientes, haga clic en el
Haga clic en Crear.
Para ejecutar el trabajo en este momento, haga clic en el
 .
.
Visualización de los resultados de la ejecución de la tarea de trabajo de dbt
Para probar los resultados de ejecución del trabajo una vez que esta se complete, puede ejecutar consultas SQL desde un cuaderno o ejecutar consultas en el almacenamiento de Databricks. Por ejemplo, vea las siguientes consultas de ejemplo:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Reemplace el elemento <schema> por el nombre de esquema que haya configurado durante el proceso de configuración de la tarea.
Ejemplo de API
También puede usar la API Jobs para crear y administrar trabajos donde se incluyan tareas dbt. En el siguiente ejemplo se crea un trabajo con una sola tarea dbt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Avanzado) Ejecución de dbt con un perfil personalizado
Para ejecutar la tarea de dbt con un almacén de SQL (recomendado) o un proceso de uso completo, use una profiles.ymlpersonalizada que defina el almacenamiento o el proceso de Azure Databricks al que conectarse. Para crear un trabajo que ejecute el proyecto jaffle shop con un almacenamiento o un clúster de propósito general, siga estos pasos.
Nota:
Solo se puede usar un almacenamiento de SQL o un proceso de propósito general como destino para una tarea de dbt. No se puede usar el proceso de trabajo como destino para dbt.
Cree una bifurcación del repositorio jaffle_shop.
Clone el repositorio que ha bifurcado al escritorio. Por ejemplo, podría ejecutar un comando como el siguiente:
git clone https://github.com/<username>/jaffle_shop.gitReemplace el elemento
<username>por su alias de GitHub.Cree un archivo que se llame
profiles.ymlen el directoriojaffle_shopcon el siguiente contenido:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Reemplace el elemento
<schema>por el nombre de esquema que vaya a usar para las tablas del proyecto. - Para ejecutar la tarea de dbt con un almacenamiento de SQL, reemplace
<http-host>por el valor de Nombre de host del servidor de la pestaña Detalles de conexión del almacenamiento de SQL. Para ejecutar la tarea de dbt con un proceso de propósito general, reemplace<http-host>por el valor de Nombre de host del servidor de la pestaña Opciones avanzadas, JDBC/ODBC del proceso de Azure Databricks. - Para ejecutar la tarea de dbt con un almacenamiento de SQL, reemplace
<http-path>por el valor de Ruta de acceso HTTP de la pestaña Detalles de conexión del almacenamiento de SQL. Para ejecutar la tarea de dbt con un proceso de propósito general, reemplace<http-path>por el valor de Ruta de acceso HTTP de la pestaña Opciones avanzadas, JDBC/ODBC del proceso de Azure Databricks.
En este archivo no deben especificarse secretos como los token de acceso, ya que este se introducirá en el control de código fuente. En su lugar, en este archivo, las credenciales se insertan dinámicamente en tiempo de ejecución mediante la funcionalidad de plantillas de dbt.
Nota
Las credenciales generadas son válidas durante la ejecución, hasta un máximo de 30 días, y se revocan automáticamente después de la finalización.
- Reemplace el elemento
Introduzca este archivo en Git e insértelo en el repositorio bifurcado que creó. Por ejemplo, podría ejecutar comandos como los siguientes:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushHaga clic en el
Flujos de trabajo, que se ubica en la barra lateral de la UI de Databricks.Seleccione el trabajo de dbt y haga clic en la pestaña Tareas.
En Origen, haga clic en el elemento Editar e introduzca los detalles del repositorio de GitHub bifurcado "jaffle shop".
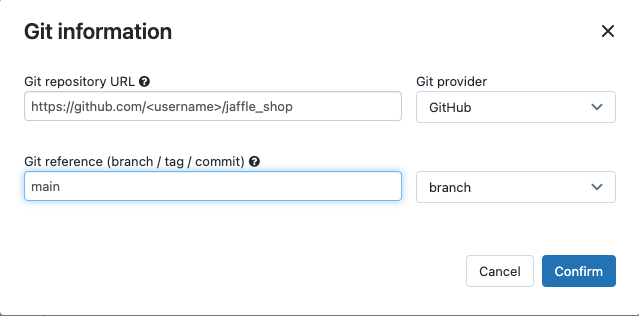
En SQL warehouse, seleccione None (Manual).
En el campo Directorio de perfiles, introduzca la ruta de acceso relativa del directorio donde se ubica el archivo
profiles.yml. Deje el valor de la ruta de acceso en blanco si quiere que se use el valor predeterminado de la raíz del repositorio.
(Avanzado) Uso de modelos de Python de dbt en un flujo de trabajo
Nota:
La compatibilidad de dbt con los modelos de Python está en versión beta y requiere dbt 1.3 o versiones superiores.
dbt ahora admite modelos de Python en almacenamientos de datos específicos, incluidos Databricks. Con los modelos de Python de dbt, puede usar herramientas del ecosistema de Python para implementar transformaciones que son difíciles de implementar con SQL. Puede crear un trabajo de Azure Databricks para ejecutar una sola tarea con el modelo de Python de dbt, o bien puede incluir la tarea dbt como parte de un flujo de trabajo que incluya varias tareas.
No se pueden ejecutar modelos de Python en una tarea de dbt con un almacenamiento de SQL. Para obtener más información sobre el uso de modelos de Python de dbt con Azure Databricks, consulte Almacenamientos de datos específicos en la documentación de dbt.
Errores y solución de problemas
Error El archivo de perfil no existe
Mensaje de error:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Causas posibles:
No se encontró el archivo profiles.yml en la ruta $PATH que se especificó. Asegúrese de que el archivo profiles.yml se incluya en la raíz del proyecto de dbt.