Ejecución del trabajo de Azure Databricks con proceso sin servidor para flujos de trabajo
Importante
El proceso sin servidor para los flujos de trabajo está en Versión preliminar pública. Para obtener información sobre la idoneidad y la habilitación, vea Habilitar proceso sin servidor.
Importante
Dado que el proceso sin servidor para flujos de trabajo no admite el control del tráfico de salida, los trabajos tienen acceso total a Internet.
El proceso sin servidor para flujos de trabajo permite ejecutar el trabajo de Azure Databricks sin configurar e implementar la infraestructura. Con el proceso sin servidor, se centra en implementar las canalizaciones de procesamiento de datos y análisis, y Azure Databricks administra eficazmente los recursos de proceso, incluida la optimización y el escalado del proceso para las cargas de trabajo. El escalado automático y Photon se habilitan automáticamente para los recursos de proceso que ejecutan el trabajo.
El proceso sin servidor para la optimización automática de flujos de trabajo optimiza automáticamente el proceso seleccionando los recursos adecuados, como los tipos de instancia, la memoria y los motores de procesamiento en función de la carga de trabajo. La optimización automática también reintenta automáticamente los trabajos con errores.
Databricks actualiza automáticamente la versión de Databricks Runtime para admitir mejoras y actualizaciones en la plataforma, a la vez que garantiza la estabilidad de los trabajos de Azure Databricks. Para ver la versión actual de Databricks Runtime que usa el proceso sin servidor para flujos de trabajo, consulte Notas de la versión de proceso sin servidor.
Dado que no se requiere el permiso de creación de clústeres, todos los usuarios del área de trabajo pueden usar el proceso sin servidor para ejecutar sus flujos de trabajo.
En este artículo se describe el uso de la interfaz de usuario de trabajos de Azure Databricks para crear y ejecutar trabajos que usan proceso sin servidor. También puede automatizar la creación y ejecución de trabajos que usan el proceso sin servidor con Jobs API, Databricks Asset Bundles y el SDK de Databricks para Python.
- Para obtener información sobre el uso de la API de trabajos para crear y ejecutar trabajos que usan el proceso sin servidor, consulte Trabajos en la referencia de la API de REST.
- Para más información sobre el uso de Conjuntos de recursos de Databricks para crear y ejecutar trabajos que usan proceso sin servidor, consulte Desarrollo de un trabajo en Azure Databricks mediante conjuntos de recursos de Databricks.
- Para más información sobre el uso del SDK de Databricks para Python para crear y ejecutar trabajos que usan proceso sin servidor, consulte SDK de Databricks para Python.
Requisitos
El área de trabajo de Azure Databricks debe tener habilitado Unity Catalog.
Dado que el proceso sin servidor para flujos de trabajo usa modo de acceso compartido, las cargas de trabajo deben admitir este modo de acceso.
El área de trabajo de Azure Databricks debe estar en una región compatible. Consultar Regiones de Azure Databricks.
Creación de un trabajo mediante proceso sin servidor
Nota:
Dado que el proceso sin servidor para flujos de trabajo garantiza que se aprovisionen recursos suficientes para ejecutar las cargas de trabajo, es posible que experimente un aumento de los tiempos de inicio al ejecutar un trabajo de Azure Databricks que requiera grandes cantidades de memoria o que incluya muchas tareas.
El proceso sin servidor se admite con los tipos de tareas notebook, script de Python, dbt y Python tipos de tareas. De manera predeterminada, el proceso sin servidor se selecciona como el tipo de proceso al crear un nuevo trabajo y agregar uno de estos tipos de tareas admitidos.
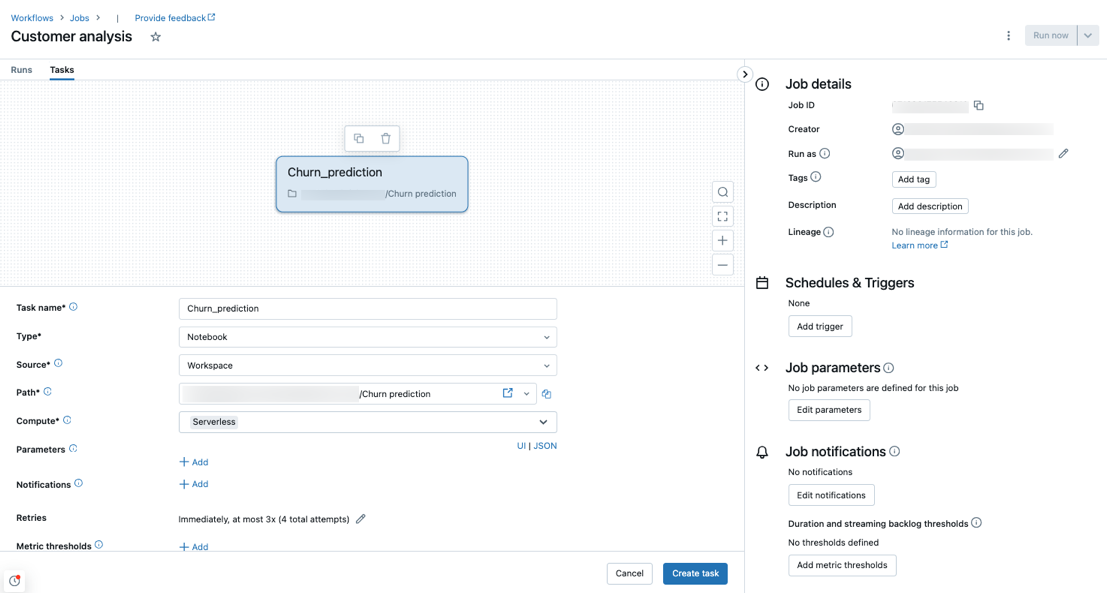
Databricks recomienda usar el proceso sin servidor para todas las tareas de trabajo. También puede especificar diferentes tipos de proceso para las tareas de un trabajo, lo que podría ser necesario si un tipo de tarea no es compatible con el proceso sin servidor para los flujos de trabajo.
Configuración de un trabajo existente para usar el proceso sin servidor
Puede cambiar un trabajo existente para usar el proceso sin servidor para los tipos de tareas admitidos al editar el trabajo. Para cambiar al proceso sin servidor, haga lo siguiente:
- En el panel lateral Detalles del trabajo, haga clic en Intercambiar en Compute, haga clic en Nuevo, escriba o actualice cualquier configuración y haga clic en Actualizar.
- Haga clic en
 el menú desplegable Compute y seleccione Serverless.
el menú desplegable Compute y seleccione Serverless.

Programación de un cuaderno mediante proceso sin servidor
Además de usar la interfaz de usuario de trabajos para crear y programar un trabajo mediante proceso sin servidor, puede crear y ejecutar un trabajo que use proceso sin servidor directamente desde un cuaderno de Databricks. Consulte Creación y administración de trabajos de cuaderno programados.
Establecer parámetros de configuración de Spark
Para automatizar la configuración de Spark en el proceso sin servidor, Databricks permite establecer solo parámetros específicos de configuración de Spark. Para ver la lista de parámetros permitidos, consulte Parámetros de configuración de Spark admitidos.
Solo se pueden establecer parámetros de configuración de Spark a nivel de sesión. Para ello, establézcalos en un cuaderno y agréguelo a una tarea incluida en el mismo trabajo que usa los parámetros. Consulte Obtener y establecer las propiedades de configuración de Apache Spark en un cuaderno.
Configuración de entornos y dependencias de cuadernos
Para administrar las dependencias de biblioteca y la configuración del entorno de una tarea de cuaderno, agregue la configuración a una celda del cuaderno. En el ejemplo siguiente se instalan bibliotecas de Python mediante pip install desde archivos del área de trabajo y con un archivo requirements.txt y se establece una variable de sesión spark.sql.session.timeZone:
%pip install -r ./requirements.txt
%pip install simplejson
%pip install /Volumes/my/python.whl
%pip install /Workspace/my/python.whl
%pip install https://some-distro.net/popular.whl
spark.conf.set('spark.sql.session.timeZone', 'Europe/Amsterdam')
Para establecer el mismo entorno en varios cuadernos, puede usar un único cuaderno para configurar el entorno y a continuación, usar el comando magic %run para ejecutar ese cuaderno desde cualquier cuaderno que requiera la configuración del entorno. Consulte Uso de %run para importar un cuaderno.
Configuración de entornos y dependencias para tareas que no son de cuaderno
Para otros tipos de tareas admitidos, como script de Python, rueda de Python o tareas dbt, un entorno predeterminado incluye bibliotecas de Python instaladas. Para ver la lista de bibliotecas instaladas, consulte la sección Bibliotecas de Python instaladas en las notas de la versión de Databricks Runtime en la que se basa el proceso sin servidor para la implementación de flujos de trabajo. Para ver la versión actual de Databricks Runtime que usa el proceso sin servidor para flujos de trabajo, consulte Notas de la versión de proceso sin servidor. Si una tarea requiere una biblioteca de Python que no está instalada, puede instalar la biblioteca desde archivos del área de trabajo, volúmenes de Unity Catalog o repositorios de paquetes públicos. Para agregar una biblioteca al crear o editar una tarea:
En el menú Desplegable entorno y bibliotecas, haga clic en
 junto al entorno Predeterminado o haga clic en + Agregar nuevo entorno.
junto al entorno Predeterminado o haga clic en + Agregar nuevo entorno.
En el cuadro de diálogo Configurar entorno, haga clic en + Agregar biblioteca.
Seleccione el tipo de dependencia en el menú desplegable en Bibliotecas.
En el cuadro de texto Ruta de acceso de archivo, escriba la ruta de acceso a la biblioteca.
Para una rueda de Python en un archivo de área de trabajo, la ruta de acceso debe ser absoluta e iniciar con
/Workspace/.Para un Python Wheel en un volumen Unity Catalog, la ruta debe ser
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.Para un archivo
requirements.txt, seleccione PyPi y escriba-r /path/to/requirements.txt.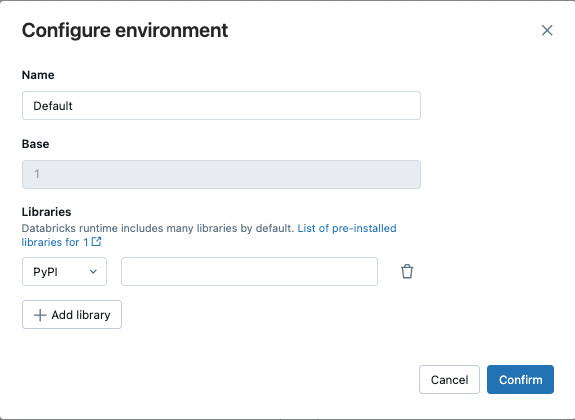
- Haga clic en Confirmar o + Agregar biblioteca para agregar otra biblioteca.
- Si va a agregar una tarea, haga clic en Crear tarea. Si va a editar una tarea, haga clic en Guardar tarea.
Configuración de la optimización automática de proceso sin servidor para no permitir reintentos
El proceso sin servidor para la optimización automática de flujos de trabajo optimiza automáticamente el proceso usado para ejecutar los trabajos y los reintentos con errores. La optimización automática está habilitada de manera predeterminada y Databricks recomienda dejarla habilitada para garantizar que las cargas de trabajo críticas se ejecuten correctamente al menos una vez. Sin embargo, si tiene cargas de trabajo que se deben ejecutar como máximo una vez, por ejemplo, trabajos que no son idempotentes, puede desactivar la optimización automática al agregar o editar una tarea:
- Junto a Reintentos, haga clic en Agregar (o si ya existe una directiva de reintento).
- En el cuadro de diálogo Directiva de reintento, desactive Habilitar la optimización automática sin servidor (puede incluir reintentos adicionales).
- Haga clic en Confirmar.
- Si va a agregar una tarea, haga clic en Crear tarea. Si va a editar una tarea, haga clic en Guardar tarea.
Supervisión del costo de los trabajos que usan el proceso sin servidor para los flujos de trabajo
Puede supervisar el costo de los trabajos que usan el proceso sin servidor para los flujos de trabajo consultando la tabla del sistema de uso facturable. Esta tabla se actualiza para incluir atributos de usuario y carga de trabajo sobre los costos sin servidor. Consulte Referencia de tabla del sistema de utilización facturable.
Visualización de los detalles de las consultas de Spark
El proceso sin servidor para flujos de trabajo tiene una nueva interfaz para ver información detallada en tiempo de ejecución de las instrucciones Spark, como métricas y planes de consulta. Para ver la información de consulta de las instrucciones de Spark incluidas en sus trabajos ejecutados en proceso sin servidor:
- Haga clic en
 Flujos de trabajo en la barra lateral.
Flujos de trabajo en la barra lateral. - En la columna Nombre, haga clic en el nombre del trabajo para el que desea ver información.
- Haga clic en la ejecución específica para la que desea ver información.
- En la sección Proceso del panel lateral Ejecución de tareas, haga clic en Historial de consultas.
- Se le redirigirá al Historial de consultas, prefiltrado en función del identificador de ejecución de la tarea en la que estaba.
Para obtener información sobre el historial de consultas, consulte Historial de consultas.
Limitaciones
Para obtener una lista de los procesos sin servidor para las limitaciones de los flujos de trabajo, consulte Limitaciones de proceso sin servidor en las notas de la versión de proceso sin servidor.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de