Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica la generación aumentada de recuperación (RAG) y lo que los desarrolladores necesitan para crear una solución RAG lista para producción.
Para obtener información sobre dos maneras de crear una aplicación de "chat sobre los datos", uno de los principales casos de uso de ia generativa para empresas, consulte Aumento de LLM con RAG o ajuste preciso.
En el diagrama siguiente se muestran los pasos principales de RAG:
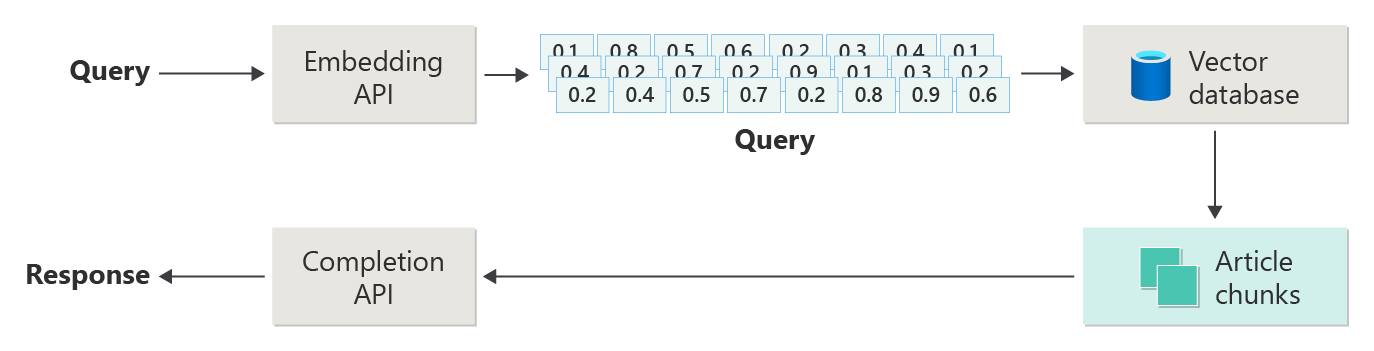
Este proceso se denomina RAG naïve. Le ayuda a comprender las partes básicas y los roles en un sistema de chat basado en RAG.
Los sistemas RAG del mundo real necesitan más preprocesamiento y posprocesamiento para controlar artículos, consultas y respuestas. En el diagrama siguiente se muestra una configuración más realista, denominada RAG avanzada:

En este artículo se proporciona un marco sencillo para comprender las fases principales en un sistema de chat basado en RAG del mundo real:
- Fase de ingesta
- Fase de flujo de inferencia
- Fase de evaluación
Ingesta
La ingesta significa guardar los documentos de la organización para que pueda encontrar rápidamente respuestas para los usuarios. El principal desafío es buscar y usar las partes de los documentos que mejor coincidan con cada pregunta. La mayoría de los sistemas usan incrustaciones vectoriales y búsqueda de similitud de coseno para hacer coincidir preguntas con el contenido. Obtendrá mejores resultados cuando comprenda el tipo de contenido (como patrones y formato) y organice los datos bien en la base de datos vectorial.
Al configurar la ingesta, céntrese en estos pasos:
- Preprocesamiento y extracción de contenido
- Estrategia de fragmentación
- Organización de fragmentación
- Estrategia de actualización
Preprocesamiento y extracción de contenido
El primer paso de la fase de ingesta es preprocesar y extraer el contenido de los documentos. Este paso es fundamental porque garantiza que el texto esté limpio, estructurado y listo para la indexación y recuperación.
El contenido limpio y preciso hace que un sistema de chat basado en RAG funcione mejor. Para empezar, examine la forma y el estilo de los documentos que desea indexar. ¿Siguen un patrón establecido, como la documentación? Si no es así, ¿qué preguntas podrían responder estos documentos?
Como mínimo, configure la canalización de ingesta en:
- Estandarizar formatos de texto
- Controlar caracteres especiales
- Quitar contenido no relacionado o antiguo
- Seguimiento de diferentes versiones de contenido
- Control del contenido con pestañas, imágenes o tablas
- Extracción de metadatos
Parte de esta información, como los metadatos, puede ayudar durante la recuperación y evaluación si la mantiene con el documento en la base de datos vectorial. También puede combinarlo con el fragmento de texto para mejorar la inserción vectorial del fragmento.
Estrategia de fragmentación
Como desarrollador, decida cómo dividir documentos grandes en fragmentos más pequeños. La fragmentación ayuda a enviar el contenido más relevante al LLM para que pueda responder mejor a las preguntas del usuario. Además, piense en cómo usará los fragmentos después de obtenerlos. Pruebe los métodos comunes del sector y pruebe la estrategia de fragmentación en su organización.
Al fragmentar, piense en lo siguiente:
- Optimización del tamaño del fragmento: elija el mejor tamaño de fragmento y cómo dividirlo, por sección, párrafo o oración.
- Fragmentos de ventana superpuestos y deslizantes: decida si los fragmentos deben ser independientes o superpuestos. También puede usar un enfoque de ventana deslizante.
- Small2Big: si divide por oración, organice el contenido para que pueda encontrar oraciones cercanas o el párrafo completo. Dar este contexto adicional al LLM puede ayudarle a responder mejor. Para más información, consulte la sección siguiente.
Organización de fragmentación
En un sistema RAG, la forma en que organiza los datos en la base de datos vectorial facilita y acelera la búsqueda de la información correcta. Estas son algunas maneras de configurar los índices y las búsquedas:
- Índices jerárquicos: use capas de índices. Un índice de resumen de nivel superior busca rápidamente un pequeño conjunto de fragmentos probables. Un índice de segundo nivel apunta a los datos exactos. Esta configuración acelera las búsquedas limitando las opciones antes de examinar con detalle.
- Índices especializados: seleccione índices que se ajusten a los datos. Por ejemplo, use índices basados en grafos si los fragmentos se conectan entre sí, como en redes de citas o gráficos de conocimiento. Use bases de datos relacionales si los datos están en tablas y filtre con consultas SQL.
- Índices híbridos: combine diferentes métodos de indexación. Por ejemplo, use primero un índice de resumen y, a continuación, un índice basado en grafos para explorar las conexiones entre fragmentos.
Optimización de alineación
Haga que los fragmentos recuperados sean más relevantes y precisos al hacer coincidirlos con los tipos de preguntas que responden. Una manera es crear una pregunta de ejemplo para cada fragmento que muestre qué pregunta responde mejor. Este enfoque ayuda de varias maneras:
- Coincidencia mejorada: durante la recuperación, el sistema compara la pregunta del usuario con estas preguntas de ejemplo para encontrar el mejor fragmento. Esta técnica mejora la relevancia de los resultados.
- Datos de entrenamiento para modelos de aprendizaje automático: estos pares de fragmentos de preguntas ayudan a entrenar los modelos de aprendizaje automático en el sistema RAG. Los modelos aprenden qué fragmentos responden a qué tipos de preguntas.
- Control directo de consultas: si la pregunta de un usuario coincide con una pregunta de ejemplo, el sistema puede encontrar y usar rápidamente el fragmento correcto, lo que acelera la respuesta.
La pregunta de ejemplo de cada fragmento actúa como una etiqueta que guía el algoritmo de recuperación. La búsqueda se centra y es más consciente del contexto. Este método funciona bien cuando los fragmentos cubren muchos temas o tipos de información diferentes.
Estrategias de actualización
Si la organización actualiza documentos a menudo, debe mantener la base de datos actualizada para que el recuperador siempre pueda encontrar la información más reciente. El componente del recuperador es la parte del sistema que busca en la base de datos vectorial y devuelve resultados. Estas son algunas maneras de mantener actualizada la base de datos vectorial:
Actualizaciones incrementales:
- Intervalos regulares: establezca actualizaciones para que se ejecuten según una programación (como diaria o semanal) en función de la frecuencia con la que cambian los documentos. Esta acción mantiene la base de datos actualizada.
- Actualizaciones basadas en desencadenadores: configure actualizaciones automáticas cuando alguien agregue o cambie un documento. El sistema vuelve a indexar solo las partes afectadas.
Actualizaciones parciales:
- Reindexación selectiva: actualice solo las partes de la base de datos que cambiaron, no todo. Esta técnica ahorra tiempo y recursos, especialmente para grandes conjuntos de datos.
- Codificación delta: almacene solo los cambios entre documentos antiguos y nuevos, lo que reduce la cantidad de datos que se van a procesar.
Control de versiones:
- Creación de instantáneas: guarde las versiones del conjunto de documentos en momentos diferentes. Esta acción le permite volver o restaurar versiones anteriores si es necesario.
- Control de versiones del documento: use un sistema de control de versiones para realizar un seguimiento de los cambios y mantener un historial de los documentos.
Actualizaciones en tiempo real:
- Procesamiento de flujos: use el procesamiento de flujos para actualizar la base de datos vectorial en tiempo real a medida que cambian los documentos.
- Consultas dinámicas: use consultas dinámicas para obtener up-torespuestas de fecha, a veces mezclando datos activos con resultados almacenados en caché para obtener velocidad.
Técnicas de optimización:
- Procesamiento por lotes: agrupe los cambios y aplíquelos juntos para ahorrar recursos y reducir la sobrecarga.
-
Enfoques híbridos: mezclar diferentes estrategias:
- Use actualizaciones incrementales para pequeños cambios.
- Use la reindexación completa para actualizaciones significativas.
- Realice un seguimiento y documente los cambios importantes en los datos.
Elija la estrategia de actualización o combinación que se adapte a sus necesidades. Pensar:
- Tamaño del corpus del documento
- Frecuencia de actualización
- Necesidades de datos en tiempo real
- Recursos disponibles
Revise estos factores para la aplicación. Cada método tiene inconvenientes en la complejidad, el costo y la rapidez con la que se muestran las actualizaciones.
Canalización de inferencia
Los artículos ahora están fragmentados, vectorizados y almacenados en una base de datos vectorial. A continuación, céntrese en obtener las mejores respuestas del sistema.
Para obtener resultados precisos y rápidos, piense en estas preguntas clave:
- ¿Está clara la pregunta del usuario y es probable que obtenga la respuesta correcta?
- ¿La pregunta interrumpe las reglas de la empresa?
- ¿Puede volver a escribir la pregunta para ayudar al sistema a encontrar mejores coincidencias?
- ¿Los resultados de la base de datos coinciden con la pregunta?
- ¿Debe cambiar los resultados antes de enviarlos al LLM para asegurarse de que la respuesta es pertinente?
- ¿La respuesta de LLM aborda completamente la pregunta del usuario?
- ¿La respuesta sigue las reglas de su organización?
Toda la canalización de inferencia funciona en tiempo real. No hay ninguna manera correcta de configurar los pasos de preprocesamiento y posterior al procesamiento. Se usa una combinación de código y llamadas LLM. Una de las ventajas más importantes es equilibrar la precisión y el cumplimiento de los costos y la velocidad.
Echemos un vistazo a las estrategias de cada fase de la canalización de inferencia.
Pasos de preprocesamiento de consultas
El preprocesamiento de consultas se inicia justo después de que el usuario envíe una pregunta:

Estos pasos ayudan a asegurarse de que la pregunta del usuario se ajusta al sistema y está lista para encontrar los mejores fragmentos de artículo mediante la similitud de coseno o la búsqueda "vecino más cercano".
Comprobación de directivas: use lógica para detectar y quitar o marcar contenido no deseado, como datos personales, idioma incorrecto o intentos de interrumpir las reglas de seguridad (denominadas "jailbreaking").
Reescritura de consultas: cambie la pregunta si es necesario: expanda acrónimos, quite la jerga o rephrase para centrarse en ideas más grandes (preguntar paso a paso).
Una versión especial de la solicitud paso a paso es Hipotética inserción de documentos (HyDE). HyDE tiene la respuesta LLM a la pregunta, crea una inserción de esa respuesta y, a continuación, busca la base de datos vectorial con ella.
Subconsultas
Las subconsultas rompen una pregunta larga o compleja en preguntas más pequeñas y fáciles. El sistema responde a cada pregunta pequeña y, a continuación, combina las respuestas.
Por ejemplo, si alguien pregunta: "¿Quién hizo contribuciones más importantes a la física moderna, Albert Einstein o Niels Bohr?" puede dividirlo en:
- Subconsulta 1: "¿Qué contribuye Albert Einstein a la física moderna?"
- Subconsulta 2: "¿Qué contribuye Niels Bohr a la física moderna?"
Las respuestas pueden incluir:
- Para Einstein: la teoría de la relatividad, el efecto fotoeléctrico y E=mc^2.
- Para Bohr: el modelo atom de hidrógeno, trabaja en mecánica cuántica y en el principio de complementariedad.
A continuación, puede hacer preguntas de seguimiento:
- Subconsulta 3: "¿Cómo cambiaron las teorías de Einstein la física moderna?"
- Subconsulta 4: "¿Cómo cambiaron las teorías de Bohr la física moderna?"
Estos seguimientos examinan el efecto de cada científico, como:
- Cómo el trabajo de Einstein llevó a nuevas ideas en cosmología y teoría cuántica
- Cómo el trabajo de Bohr nos ayudó a comprender los átomos y la mecánica cuántica
El sistema combina las respuestas para dar una respuesta completa a la pregunta original. Este método facilita la respuesta de preguntas complejas dividiéndolas en partes claras y pequeñas.
Enrutador de consulta
A veces, el contenido reside en varias bases de datos o sistemas de búsqueda. En estos casos, use un enrutador de consulta. Un enrutador de consultas elige la mejor base de datos o índice para responder a cada pregunta.
Un enrutador de consultas funciona después de que el usuario haga una pregunta, pero antes de que el sistema busque respuestas.
Este es el funcionamiento de un enrutador de consultas:
- Análisis de consultas: LLM u otra herramienta examina la pregunta para averiguar qué tipo de respuesta es necesaria.
- Selección de índice: el enrutador elige uno o varios índices que se ajustan a la pregunta. Algunos índices son mejores para hechos, otros para opiniones o temas especiales.
- Distribución de consultas: el enrutador envía la pregunta al índice o índices elegidos.
- Agregación de resultados: el sistema recopila y combina las respuestas de los índices.
- Generación de respuestas: el sistema crea una respuesta clara con la información que encontró.
Use diferentes índices o motores de búsqueda para:
- Especialización de tipos de datos: algunos índices se centran en noticias, otros en documentos académicos o en bases de datos especiales como información médica o legal.
- Optimización de tipos de consulta: algunos índices son rápidos para hechos simples (como fechas), mientras que otros controlan preguntas complejas o expertas.
- Diferencias algorítmicas: los diferentes motores de búsqueda usan métodos diferentes, como la búsqueda de vectores, la búsqueda de palabras clave o la búsqueda semántica avanzada.
Por ejemplo, en un sistema de asesoramiento médico, es posible que tenga:
- Índice de un documento de investigación para obtener detalles técnicos
- Un índice de caso práctico para ejemplos reales
- Índice de mantenimiento general para preguntas básicas
Si alguien pregunta sobre los efectos de un nuevo medicamento, el enrutador envía la pregunta al índice del documento de investigación. Si la pregunta es acerca de los síntomas comunes, usa el índice de salud general para una respuesta simple.
Pasos posteriores al procesamiento de recuperación
El procesamiento posterior a la recuperación se produce después de que el sistema encuentre fragmentos de contenido en la base de datos vectorial:

A continuación, compruebe si estos fragmentos son útiles para el símbolo del sistema LLM antes de enviarlos al LLM.
Tenga en cuenta estas cosas:
- La información adicional puede ocultar los detalles más importantes.
- La información irrelevante puede empeorar la respuesta.
Cuidado con la aguja en un problema de paja : los LLM suelen prestar más atención al inicio y al final de un aviso que el medio.
Además, recuerde la ventana de contexto máxima de LLM y el número de tokens necesarios para solicitudes largas, especialmente a escala.
Para controlar estos problemas, use una canalización de procesamiento posterior a la recuperación con pasos como:
- Filtrado de resultados: mantenga solo fragmentos que coincidan con la consulta. Omita el resto al compilar el símbolo del sistema llm.
- Volver a clasificar: coloque los fragmentos más relevantes al principio y al final del símbolo del sistema.
- Compresión del símbolo del sistema: use un modelo pequeño y barato para resumir y combinar fragmentos en un solo mensaje antes de enviarlo al LLM.
Pasos de procesamiento posteriores a la finalización
El procesamiento posterior a la finalización se produce después de la pregunta del usuario y todos los fragmentos de contenido van al LLM:

Después de que LLM proporcione una respuesta, compruebe su precisión. Una canalización de procesamiento posterior a la finalización puede incluir:
- Comprobación de hechos: busque instrucciones en la respuesta que afirman ser hechos y compruebe si son verdaderas. Si se produce un error en una comprobación de hechos, puede volver a preguntar al LLM o mostrar un mensaje de error.
- Comprobación de directivas: asegúrese de que la respuesta no incluya contenido perjudicial para el usuario o la organización.
Evaluación
Evaluar un sistema como este es más complejo que ejecutar pruebas unitarias o de integración normales. Piense en estas preguntas:
- ¿Los usuarios están satisfechos con las respuestas?
- ¿Las respuestas son precisas?
- ¿Cómo recopila comentarios de los usuarios?
- ¿Hay reglas sobre qué datos puede recopilar?
- ¿Puede ver cada paso que tomó el sistema cuando las respuestas son incorrectas?
- ¿Mantiene registros detallados para el análisis de la causa principal?
- ¿Cómo actualiza el sistema sin empeorar las cosas?
Capturar y actuar sobre los comentarios de los usuarios
Trabaje con el equipo de privacidad de su organización para diseñar herramientas de captura de comentarios, datos del sistema y registro para análisis forense y causa principal de una sesión de consulta.
El siguiente paso es crear una canalización de evaluación. Una canalización de evaluación facilita y acelera la revisión de los comentarios y descubre por qué la inteligencia artificial ha dado determinadas respuestas. Compruebe cada respuesta para ver cómo la IA la generó, si se usaron los fragmentos de contenido correctos y cómo se dividieron los documentos.
Además, busque pasos adicionales de preprocesamiento o posteriores al procesamiento que podrían mejorar los resultados. Esta revisión cercana suele encontrar brechas de contenido, especialmente cuando no existe ninguna buena documentación para la pregunta de un usuario.
Necesita una canalización de evaluación para controlar estas tareas a escala. Una buena canalización usa herramientas personalizadas para medir la calidad de las respuestas. Le ayuda a ver por qué la inteligencia artificial dio una respuesta específica, qué documentos usó y cómo funcionó la canalización de inferencia.
Conjunto de datos golden
Una manera de comprobar el funcionamiento de un sistema de chat RAG es usar un conjunto de datos dorado. Un conjunto de datos dorado es un conjunto de preguntas con respuestas aprobadas, metadatos útiles (como el tema y el tipo de pregunta), vínculos a documentos de origen y diferentes formas en que los usuarios pueden hacer lo mismo.
Un conjunto de datos dorado muestra el "mejor escenario de casos". Los desarrolladores lo usan para ver cómo funciona el sistema y ejecutar pruebas cuando agregan nuevas características o actualizaciones.
Evaluación de daños
El modelado de daños le ayuda a detectar posibles riesgos en un producto y planear formas de reducirlos.
Una herramienta de evaluación de daños debe incluir estas características clave:
- Identificación de las partes interesadas: ayuda a enumerar y agrupar a todos los afectados por la tecnología, incluidos los usuarios directos, las personas afectadas indirectamente, las generaciones futuras e incluso el entorno.
- Categorías y descripciones de daños: muestra posibles daños, como pérdida de privacidad, angustia emocional o daño económico. Le guía por ejemplos y le ayuda a pensar en problemas esperados e inesperados.
- Evaluaciones de gravedad y probabilidad: le ayuda a juzgar lo grave y probable que es cada daño, por lo que puede decidir qué corregir primero. Puede usar datos para admitir sus opciones.
- Estrategias de mitigación: sugiere formas de reducir los riesgos, como cambiar el diseño del sistema, agregar medidas de seguridad o usar otra tecnología.
- Mecanismos de comentarios: permite recopilar comentarios de las partes interesadas para que pueda seguir mejorando el proceso a medida que obtenga más información.
- Documentación e informes: facilita la creación de informes que muestran lo que encontró y lo que hizo para reducir los riesgos.
Estas características le ayudan a encontrar y corregir riesgos, y también le ayudan a crear una inteligencia artificial más ética y responsable pensando en todos los posibles impactos desde el principio.
Para obtener más información, consulte estos artículos:
Prueba y comprobación de las medidas de seguridad
La formación de equipos rojos es clave: significa actuar como un atacante para encontrar puntos débiles en el sistema. Este paso es especialmente importante para detener el jailbreak. Para obtener sugerencias sobre cómo planear y administrar la formación de equipos rojos para la inteligencia artificial responsable, consulte Planning red teaming for large language models (LLMs) and their applications ( Planning red teaming for large language models (LLMs) and their applications (Planning red teaming for large language models (LLMs) and their applications( Planning red teaming for large language models (LLMs) and their applications.
Los desarrolladores deben probar las medidas de seguridad del sistema RAG en diferentes escenarios para asegurarse de que funcionan. Este paso hace que el sistema sea más sólido y también ayuda a ajustar las respuestas para seguir normas y reglas éticas.
Consideraciones finales para el diseño de aplicaciones
Estos son algunos aspectos clave que recordar de este artículo que pueden ayudarle a diseñar la aplicación:
- Imprevisibilidad de ia generativa
- Cambios de petición de usuario y su efecto en el tiempo y el costo
- Solicitudes LLM paralelas para un rendimiento más rápido
Para crear una aplicación de IA generativa, consulte Introducción al chat mediante su propio ejemplo de datos para Python. El tutorial también está disponible para .NET, Javay javaScript.