Aumento de un modelo de lenguaje grande con generación aumentada de recuperación y ajuste preciso
En los artículos de esta serie se describen los modelos de recuperación de conocimiento que usan las LLM para generar sus respuestas. De forma predeterminada, un modelo de lenguaje grande (LLM) solo tiene acceso a sus datos de entrenamiento. Sin embargo, puede aumentar el modelo para incluir datos en tiempo real o datos privados. En este artículo se describe uno de los dos mecanismos para aumentar un modelo.
El primer mecanismo es Generación aumentada de recuperación (RAG), que es una forma de preprocesamiento que combina la búsqueda semántica con priming contextual (que se describe en otro artículo).
El segundo mecanismo es el ajuste preciso, que hace referencia al proceso de entrenamiento adicional del modelo en un conjunto de datos específico después de su entrenamiento inicial y amplio, con el objetivo de adaptarlo para mejorar las tareas o comprender los conceptos relacionados con ese conjunto de datos. Este proceso ayuda al modelo a especializarse o mejorar su precisión y eficiencia en el control de determinados tipos de entrada o dominios.
En las secciones siguientes se describen estos dos mecanismos con más detalle.
Descripción de RAG
RAG se usa a menudo para habilitar el escenario de "chat sobre mis datos", donde las empresas que tienen un gran corpus de contenido textual (documentos internos, documentación, etc.) y quieren usar este corpus como base para las respuestas a las solicitudes del usuario.
En un nivel alto, se crea una entrada de base de datos para cada documento (o parte de un documento denominado "fragmento"). El fragmento se indexa en su inserción, un vector (matriz) de números que representan facetas del documento. Cuando un usuario envía una consulta, busca en la base de datos documentos similares y, a continuación, envía la consulta y los documentos al LLM para redactar una respuesta.
Nota:
El término Generación aumentada de recuperación (RAG) de forma modificativa. El proceso de implementación de un sistema de chat basado en RAG descrito en este artículo se puede aplicar si hay un deseo de usar datos externos para usarse en una capacidad de apoyo (RAG) o para usarse como pieza central de la respuesta (RCG). Esta distinción matizada no se aborda en la mayoría de las lecturas relacionadas con RAG.
Creación de un índice de documentos vectorizados
El primer paso para crear un sistema de chat basado en RAG es crear un almacén de datos vectoriales que contenga la inserción de vectores del documento (o una parte del documento). Tenga en cuenta el siguiente diagrama que describe los pasos básicos para crear un índice vectorizado de documentos.

Este diagrama representa una canalización de datos, que es responsable de la ingesta, el procesamiento y la administración de los datos utilizados por el sistema. Esto incluye el preprocesamiento de los datos que se van a almacenar en la base de datos vectorial y asegurarse de que los datos que se introducen en el LLM tienen el formato correcto.
Todo el proceso se basa en la noción de inserción, que es una representación numérica de datos (normalmente palabras, frases, oraciones o documentos completos) que captura las propiedades semánticas de la entrada de una manera que los modelos de aprendizaje automático pueden procesar.
Para crear una inserción, envíe el fragmento de contenido (oraciones, párrafos o documentos completos) a la API de inserción de Azure OpenAI. Lo que se devuelve de la API de inserción es un vector. Cada valor del vector representa alguna característica (dimensión) del contenido. Las dimensiones pueden incluir temas, significado semántico, sintaxis y gramática, uso de palabras y frases, relaciones contextuales, estilo y tono, etc. Juntos, todos los valores del vector representan el espacio dimensional del contenido. Es decir, si puede pensar en una representación 3D de un vector con tres valores, un vector determinado reside en un área determinada del plano x, y, z. ¿Qué ocurre si tiene 1000 valores (o más)? Aunque no es posible que los seres humanos dibujen un gráfico de 1000 dimensiones en una hoja de papel para que sea más comprensible, los equipos no tienen problemas para entender ese grado de espacio dimensional.
El siguiente paso del diagrama muestra el almacenamiento del vector junto con el propio contenido (o un puntero a la ubicación del contenido) y otros metadatos de una base de datos vectorial. Una base de datos vectorial es como cualquier tipo de base de datos, con dos diferencias:
- Las bases de datos vectoriales usan un vector como índice para buscar datos.
- Las bases de datos vectoriales implementan un algoritmo denominado búsqueda similar al coseno, también conocido como vecino más cercano, que usa vectores que coinciden con los criterios de búsqueda.
Con el corpus de documentos almacenados en una base de datos vectorial, los desarrolladores pueden crear un componente de recuperador que recupere documentos que coincidan con la consulta del usuario de la base de datos para proporcionar el LLM con lo que necesita para responder a la consulta del usuario.
Respuesta a consultas con los documentos
Un sistema RAG usa primero la búsqueda semántica para encontrar artículos que podrían resultar útiles para el LLM al redactar una respuesta. El siguiente paso es enviar los artículos coincidentes junto con el mensaje original del usuario al LLM para redactar una respuesta.
Considere el siguiente diagrama como una implementación de RAG simple (a veces denominada "RAG naïve").
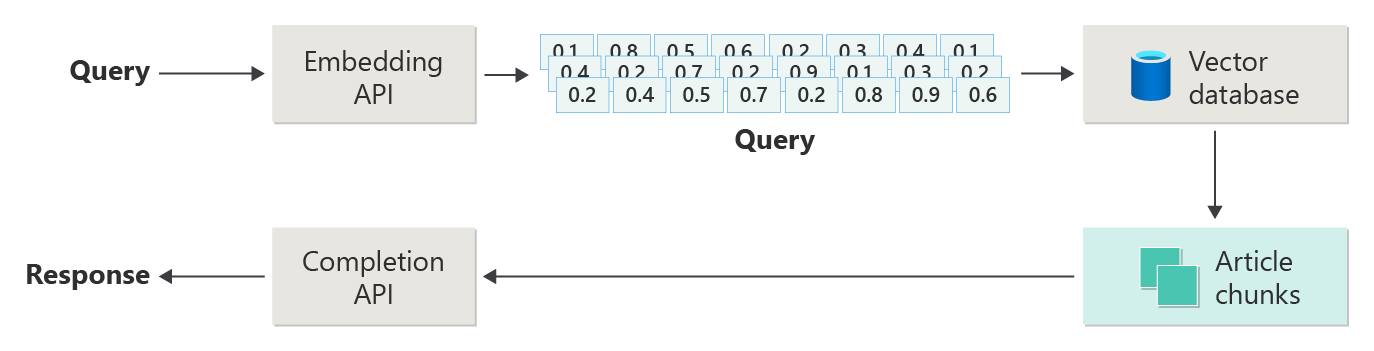
En el diagrama, un usuario envía una consulta. El primer paso es crear una inserción para que el mensaje del usuario devuelva un vector. El siguiente paso consiste en buscar la base de datos vectorial de esos documentos (o partes de documentos) que son una coincidencia "vecino más cercano".
La similitud de coseno es una medida que se usa para determinar la similitud de dos vectores, que básicamente evalúa el coseno del ángulo entre ellos. Una similitud de coseno cercana a 1 indica un alto grado de similitud (ángulo pequeño), mientras que una similitud cerca de -1 indica disimilaridad (ángulo que se aproxima a 180 grados). Esta métrica es fundamental para tareas como la similitud de documentos, donde el objetivo es buscar documentos con contenido o significado similar.
Los algoritmos "Vecino más cercano" funcionan buscando los vectores más cercanos (vecinos) a un punto determinado en el espacio vectorial. En el algoritmo k-nearest vecinos (KNN), 'k' hace referencia al número de vecinos más cercanos que se deben tener en cuenta. Este enfoque se usa ampliamente en la clasificación y la regresión, donde el algoritmo predice la etiqueta de un nuevo punto de datos en función de la etiqueta mayoritario de sus vecinos más cercanos en el conjunto de entrenamiento. La similitud knN y coseno se suelen usar conjuntamente en sistemas como motores de recomendación, donde el objetivo es buscar elementos más similares a las preferencias de un usuario, representados como vectores en el espacio de inserción.
Toma los mejores resultados de esa búsqueda y envía el contenido coincidente junto con el mensaje del usuario para generar una respuesta que (esperamos) se informe mediante la coincidencia de contenido.
Desafíos y consideraciones
La implementación de un sistema RAG incluye su conjunto de desafíos. La privacidad de los datos es fundamental, ya que el sistema debe controlar los datos del usuario de forma responsable, especialmente al recuperar y procesar información de orígenes externos. Los requisitos computacionales también pueden ser significativos, ya que tanto los procesos de recuperación como los generativos consumen muchos recursos. Garantizar la precisión y relevancia de las respuestas al administrar sesgos presentes en los datos o el modelo es otra consideración fundamental. Los desarrolladores deben navegar por estos desafíos cuidadosamente para crear sistemas RAG eficaces, éticos y valiosos.
En el siguiente artículo de esta serie, Crear sistemas avanzados de generación aumentada de recuperación proporciona más detalles sobre la creación de datos y canalizaciones de inferencia para habilitar un sistema RAG listo para producción.
Si desea empezar a experimentar con la creación de una solución de IA generativa inmediatamente, se recomienda echar un vistazo a Introducción al chat con su propio ejemplo de datos para Python. También hay versiones del tutorial disponibles en .NET, Java y JavaScript.
Ajuste de un modelo
Ajuste preciso, en el contexto de un LLM, hace referencia al proceso de ajustar los parámetros del modelo en un conjunto de datos específico del dominio después de entrenarse inicialmente en un conjunto de datos grande y diverso.
Las LLM se entrenan (previamente entrenadas) en un amplio conjunto de datos, captando la estructura del lenguaje, el contexto y una amplia gama de conocimientos. Esta fase implica aprender patrones de lenguaje generales. El ajuste está agregando más entrenamiento al modelo entrenado previamente en función de un conjunto de datos específico más pequeño. Esta fase de entrenamiento secundaria tiene como objetivo adaptar el modelo para que funcione mejor en tareas concretas o comprender dominios específicos, mejorando su precisión y relevancia para esas aplicaciones especializadas. Durante el ajuste preciso, los pesos del modelo se ajustan para predecir o comprender mejor los matices de este conjunto de datos más pequeño.
Algunas consideraciones:
- Especialización: ajuste adecuado adapta el modelo a tareas específicas, como análisis de documentos legales, interpretación de texto médico o interacciones de servicio al cliente. Esto hace que el modelo sea más eficaz en esas áreas.
- Eficiencia: es más eficaz ajustar un modelo entrenado previamente para una tarea específica que entrenar un modelo desde cero, ya que el ajuste preciso requiere menos datos y recursos computacionales.
- Capacidad de adaptación: el ajuste adecuado permite la adaptación a nuevas tareas o dominios que no formaban parte de los datos de entrenamiento originales, lo que hace que las MÁQUINAS LLM sean herramientas versátiles para diversas aplicaciones.
- Rendimiento mejorado: en el caso de las tareas que son significativamente diferentes de los datos en los que se entrenó originalmente el modelo, el ajuste fino puede dar lugar a un mejor rendimiento, ya que ajusta el modelo para comprender el lenguaje, el estilo o la terminología específicos usados en el nuevo dominio.
- Personalización: en algunas aplicaciones, el ajuste fino puede ayudar a personalizar las respuestas o predicciones del modelo para adaptarse a las necesidades o preferencias específicas de un usuario u organización. Sin embargo, el ajuste preciso también presenta ciertas desventajas y limitaciones. Comprenderlos puede ayudar a decidir cuándo optar por el ajuste adecuado frente a alternativas como la generación aumentada por recuperación (RAG).
- Requisito de datos: el ajuste preciso requiere un conjunto de datos suficientemente grande y de alta calidad específico de la tarea o dominio de destino. La recopilación y la selección de este conjunto de datos pueden ser complicadas y intensivas en los recursos.
- Riesgo de sobreajuste: existe un riesgo de sobreajuste, especialmente con un conjunto de datos pequeño. El sobreajuste hace que el modelo funcione bien en los datos de entrenamiento, pero poco en los datos nuevos y no vistos, lo que reduce su generalización.
- Costo y recursos: aunque menos intensivo que el entrenamiento desde cero, el ajuste preciso todavía requiere recursos computacionales, especialmente para grandes modelos y conjuntos de datos, lo que podría ser prohibitivo para algunos usuarios o proyectos.
- Mantenimiento y actualización: es posible que los modelos optimizados necesiten actualizaciones periódicas para mantenerse vigentes a medida que cambia la información específica del dominio a lo largo del tiempo. Este mantenimiento continuo requiere recursos y datos adicionales.
- Desfase de modelos: dado que el modelo está ajustado para tareas específicas, podría perder parte de su comprensión general del lenguaje y versatilidad, lo que conduce a un fenómeno conocido como desfase del modelo.
La personalización de un modelo con ajuste preciso explica cómo ajustar un modelo. En un nivel alto, se proporciona un conjunto de datos JSON de posibles preguntas y respuestas preferidas. La documentación sugiere que hay mejoras notables al proporcionar pares de preguntas y respuestas de 50 a 100, pero el número correcto varía considerablemente en el caso de uso.
Ajuste adecuado frente a la generación aumentada por recuperación
En la superficie, puede parecer que hay bastante superposición entre la optimización y la generación aumentada de recuperación. Elegir entre ajuste y generación aumentada por recuperación depende de los requisitos específicos de la tarea, incluidas las expectativas de rendimiento, la disponibilidad de los recursos y la necesidad de una especificidad del dominio frente a la generalización.
Cuándo se prefiere ajustar la generación aumentada de recuperación:
- Rendimiento específico de la tarea: el ajuste preciso es preferible cuando el alto rendimiento de una tarea específica es crítico y existen datos suficientes específicos del dominio para entrenar el modelo de forma eficaz sin riesgos de sobreajuste significativos.
- Control sobre datos : si tiene datos propietarios o altamente especializados que difieren significativamente de los datos en los que se entrenó el modelo base, el ajuste preciso le permite incorporar este conocimiento único en el modelo.
- Necesidad limitada de actualizaciones en tiempo real: si la tarea no requiere que el modelo se actualice constantemente con la información más reciente, el ajuste fino puede ser más eficaz, ya que los modelos RAG suelen necesitar acceso a bases de datos externas actualizadas o a Internet para extraer datos recientes.
Cuándo se prefiere la generación aumentada de recuperación a través del ajuste preciso:
- Contenido dinámico o en evolución: RAG es más adecuado para las tareas en las que es fundamental tener la información más actual. Dado que los modelos RAG pueden extraer datos de orígenes externos en tiempo real, son más adecuados para aplicaciones como la generación de noticias o la respuesta a preguntas sobre eventos recientes.
- Generalización sobre especialización : si el objetivo es mantener un rendimiento sólido en una amplia gama de temas en lugar de destacar en un dominio estrecho, RAG podría ser preferible. Usa bases de conocimiento externas, lo que le permite generar respuestas en diversos dominios sin el riesgo de sobreajustar a un conjunto de datos específico.
- Restricciones de recursos: en el caso de las organizaciones con recursos limitados para la recopilación de datos y el entrenamiento del modelo, el uso de un enfoque RAG podría ofrecer una alternativa rentable a la optimización, especialmente si el modelo base ya funciona razonablemente bien en las tareas deseadas.
Consideraciones finales que podrían influir en las decisiones de diseño de la aplicación
Esta es una breve lista de aspectos que se deben tener en cuenta y otros aspectos de este artículo que afectan a las decisiones de diseño de aplicaciones:
- Decida entre la optimización y la generación aumentada de recuperación en función de las necesidades específicas de la aplicación. El ajuste adecuado podría ofrecer un mejor rendimiento para las tareas especializadas, mientras que RAG podría proporcionar flexibilidad y contenido actualizado para aplicaciones dinámicas.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de