Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La extensión de Azure SQL Migration para Azure Data Studio le ayuda a evaluar sus requisitos de base de datos, obtener recomendaciones de SKU de tamaño adecuado para los recursos de Azure y migrar las bases de datos de SQL Server a Azure.
Aprenda a usar esta experiencia unificada, recopilando los datos de rendimiento de la instancia de SQL Server de origen para obtener recomendaciones de Azure de tamaño adecuado para los destinos de Azure SQL.
Información general
Antes de migrar a Azure SQL, puede usar la extensión SQL Migration en Azure Data Studio para ayudarle a generar recomendaciones de tamaño correcto para Azure SQL Database, Azure SQL Managed Instance y SQL Server en destinos de Azure Virtual Machines. La herramienta le ayuda a recopilar datos de rendimiento de la instancia de SQL de origen (que se ejecuta de forma local o en otra nube) y recomienda una configuración de proceso y almacenamiento para satisfacer las necesidades de la carga de trabajo.
En el diagrama se presenta el flujo de trabajo para recomendaciones de Azure en la extensión Azure SQL Migration para Azure Data Studio:

Nota:
Las características de evaluación y recomendación de Azure de la extensión de migración de Azure SQL para Azure Data Studio también admiten instancias de SQL Server de origen que se ejecutan en Windows o Linux.
Requisitos previos
Para obtener una recomendación de Azure para la migración de base de datos de SQL Server, debe cumplir los siguientes requisitos previos:
Instale la extensión Azure SQL Migration desde el marketplace de Azure Data Studio.
Asegúrese de que el inicio de sesión que usa para conectar la instancia de SQL Server de origen tenga los permisos mínimos.
Orígenes y destinos compatibles
Las recomendaciones de Azure se pueden generar para las siguientes versiones de SQL Server:
- Se admiten SQL Server 2008 y versiones posteriores en Windows o Linux.
- Se puede admitir SQL Server en ejecución en otras nubes, pero la precisión de los resultados puede variar
Las recomendaciones de Azure se pueden generar para los siguientes destinos de Azure SQL:
- Base de datos SQL de Azure
- Familias de hardware: serie Estándar (Gen5)
- Niveles de servicio: De uso general, Crítico para la empresa, Hiperescala
- Azure SQL Managed Instance
- Familias de hardware: serie Estándar (Gen5), serie Premium, Optimizado para memoria de la serie Premium
- Niveles de servicio: De uso general, Crítico para la empresa
- SQL Server en Azure Virtual Machine
- Familias de máquinas virtuales: De uso general, optimizada para memoria
- Familias de almacenamiento: SSD prémium
Recopilación de datos de rendimiento
Antes de generar recomendaciones, es necesario recopilar los datos de rendimiento de la instancia de SQL Server de origen. Durante este paso de recopilación de datos, se consultan varias vistas dinámicas del sistema (DMV) de la instancia de SQL Server para capturar las características de rendimiento de la carga de trabajo. La herramienta captura métricas, como el uso de CPU, memoria, almacenamiento y E/S cada 30 segundos, y guarda los contadores de rendimiento localmente en la máquina como un conjunto de archivos CSV.
Nivel de instancia
Estos datos de rendimiento se recopilan una vez por instancia de SQL Server:
| Dimensión de rendimiento | Descripción | Vista de administración dinámica (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Cantidad de CPU que estaba usando el proceso de SQL Server, como un porcentaje | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Superficie de memoria general del proceso de SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Uso de memoria de SQL Server | sys.dm_os_process_memory |
Nivel de base de datos
| Dimensión de rendimiento | Descripción | Vista de administración dinámica (DMV) |
|---|---|---|
DatabaseCpuPercent |
Porcentaje total de CPU usada por una base de datos | sys.dm_exec_query_stats |
CachedSizeInMb |
Tamaño total en Megabytes de caché usada por una base de datos | sys.dm_os_buffer_descriptors |
Nivel de archivo
| Dimensión de rendimiento | Descripción | Vista de administración dinámica (DMV) |
|---|---|---|
ReadIOInMb |
El número total de megabytes leídos de este archivo | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Número total de megabytes escritos en este archivo | sys.dm_io_virtual_file_stats |
NumOfReads |
Número total de lecturas emitidas en este archivo | sys.dm_io_virtual_file_stats |
NumOfWrites |
Número total de escrituras emitidas en este archivo | sys.dm_io_virtual_file_stats |
ReadLatency |
Latencia de lectura de E/S en este archivo | sys.dm_io_virtual_file_stats |
WriteLatency |
Latencia de escritura de E/S en este archivo | sys.dm_io_virtual_file_stats |
Se requiere un mínimo de 10 minutos de recopilación de datos antes de que se pueda generar una recomendación, pero para evaluar con precisión la carga de trabajo, se recomienda ejecutar la recopilación de datos durante una duración lo suficientemente larga como para capturar el uso máximo durante las horas punta y fuera de estas.
Para iniciar el proceso de recopilación de datos, empiece por conectarse a la instancia de SQL de origen en Azure Data Studio y, a continuación, inicie el Asistente para migración de SQL. En el paso 2, seleccione "Obtener recomendación de Azure". Seleccione "Recopilar datos de rendimiento ahora" y seleccione una carpeta en la máquina donde se guardarán los datos recopilados.
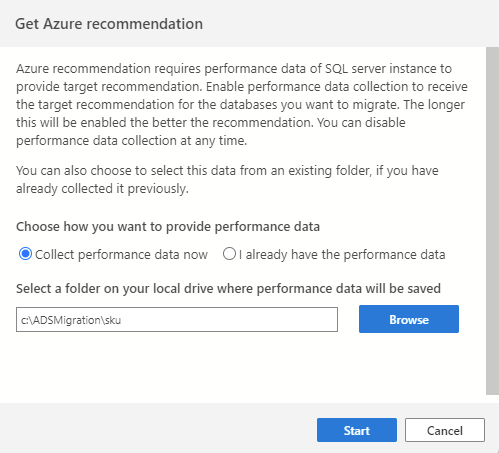
El proceso de recopilación de datos se ejecuta durante 10 minutos para generar la primera recomendación. Es importante iniciar el proceso de recopilación de datos cuando la carga de trabajo de base de datos activa refleje un uso parecido al de sus escenarios de producción.
Después de generar la primera recomendación, puede continuar con la ejecución del proceso de recopilación de datos para refinar las recomendaciones. Esta opción es especialmente útil si los patrones de uso varían durante un largo período de tiempo.
El proceso de recopilación de datos comienza una vez que seleccione Iniciar. Cada 10 minutos, los puntos de datos recopilados se agregan y la media máxima y la varianza de cada contador se escribirán en el disco en un conjunto de tres archivos CSV.
Normalmente, aparece un conjunto de archivos CSV con los siguientes sufijos en la carpeta seleccionada:
-
SQLServerInstance_CommonDbLevel_Counters.csv: contiene datos de configuración estáticos sobre el diseño y los metadatos del archivo de base de datos. -
SQLServerInstance_CommonInstanceLevel_Counters.csv: contiene datos estáticos sobre la configuración de hardware de la instancia del servidor. -
SQLServerInstance_PerformanceAggregated_Counters.csv: contiene datos de rendimiento agregados que se actualizan con frecuencia.
Durante este tiempo, deje Azure Data Studio abierto, aunque puede continuar con otras operaciones. En cualquier momento puede detener el proceso de recopilación de datos volviendo a esta página y seleccionando Detener recopilación de datos.
Generación de recomendaciones de tamaño correcto
Si ya ha recopilado datos de rendimiento de una sesión anterior o si usa otra herramienta (como Database Migration Assistant), puede importar los datos de rendimiento existentes seleccionando la opción Ya tengo los datos de rendimiento. A continuación, seleccione la carpeta donde se guardan los datos de rendimiento (tres archivos CSV) y seleccione Iniciar para iniciar el proceso de recomendación.
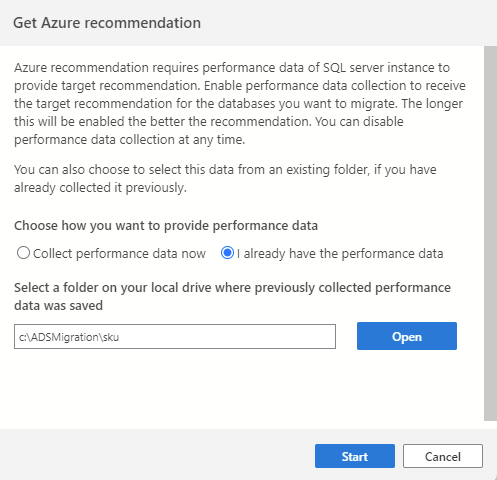
El paso uno del Asistente para la migración de SQL le pide que seleccione un conjunto de bases de datos que se van a evaluar y estas son las únicas bases de datos que se tendrán en cuenta durante el proceso de recomendación.
Sin embargo, el proceso de recopilación de datos de rendimiento recopila contadores de rendimiento para todas las bases de datos de la instancia de SQL Server de origen, no solo las seleccionadas.
Esto significa que los datos de rendimiento recopilados anteriormente se pueden usar para regenerar repetidamente recomendaciones para un subconjunto diferente de bases de datos especificando una lista diferente en el paso uno.
Parámetros de recomendación
Hay varias opciones configurables que podrían afectar a las recomendaciones.

Seleccione la opción Editar parámetros para ajustar estos parámetros según sus necesidades.
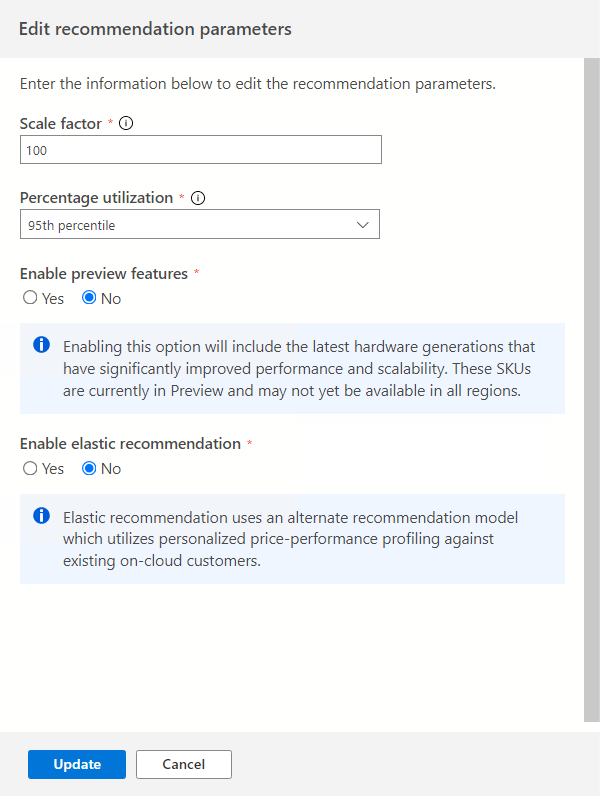
Factor de escala:
Esta opción permite proporcionar un búfer para aplicar a cada dimensión de rendimiento. Tiene en cuenta problemas como el uso estacional, el historial de rendimiento corto y los posibles aumentos en el uso futuro. Por ejemplo, si determina que un requisito de CPU de cuatro núcleos virtuales tiene un factor de escala del 150 %, el requisito de CPU real serán seis núcleos virtuales.
El volumen de factor de escala predeterminado es del 100 %.
Porcentaje de uso:
Percentil de puntos de datos que se usará a medida que se van agregando datos de rendimiento.
El valor predeterminado es el percentil 95.
Habilitación de características en vista previa:
Esta opción permite recomendar configuraciones que es posible que no estén disponibles con carácter general para todos los usuarios de todas las regiones.
Esta opción está desactivada de forma predeterminada.
Habilitación de la recomendación elástica:
Esta opción usa un modelo de recomendación alternativo que usa la generación de perfiles de rendimiento de precios personalizados en los clientes existentes en la nube.
Esta opción está desactivada de forma predeterminada.
El proceso de recopilación de datos finaliza si cierra Azure Data Studio. Los datos recopilados hasta ese momento se guardan en la carpeta.
Si cierra Azure Data Studio mientras la recopilación de datos está en curso, use una de las siguientes opciones para reiniciar la recopilación:
Vuelva a abrir Azure Data Studio e importe los archivos de datos que están guardados en la carpeta local. A continuación, genere una recomendación a partir de los datos recopilados.
Vuelva a abrir Azure Data Studio e inicie la recopilación de datos de nuevo mediante el asistente para migración.
Permisos mínimos
Para consultar las vistas del sistema necesarias para la recopilación de datos de rendimiento, se requieren permisos específicos para el inicio de sesión de SQL Server usado para esta tarea. Puede crear un usuario con privilegios mínimos para la recopilación de datos de evaluación y rendimiento mediante el siguiente script:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Limitaciones y escenarios no admitidos
Las Recomendaciones de Azure no incluyen estimaciones de precios, ya que esta situación puede variar en función de la región, la moneda y los descuentos, como la Ventaja híbrida de Azure. Para obtener estimaciones de precios, use la Calculadora de precios de Azure o cree una instancia de SQL Assessment en Azure Migrate.
No se admiten recomendaciones para Azure SQL Database con el modelo de compra basado en DTU.
Actualmente, no se admiten recomendaciones de Azure para el nivel de proceso sin servidor de Azure SQL Database y grupos elásticos.
Solución de problemas
- No se generaron recomendaciones
- Si no se generaron recomendaciones, esta situación podría significar que no se identificó ninguna configuración que pueda satisfacer completamente los requisitos de rendimiento de la instancia de origen. Para ver las razones por las que se descalificó un tamaño, nivel de servicio o familia de hardware determinado:
- Acceda a los registros desde Azure Data Studio yendo a Ayuda > Mostrar todos los comandos > Abrir carpeta de registros de extensión
- Vaya a Microsoft.mssql > SqlAssessmentLogs > abrir SkuRecommendationEvent.log
- El registro contiene un seguimiento de todas las configuraciones potenciales que se han evaluado y el motivo por el que se ha considerado o no una configuración apta:
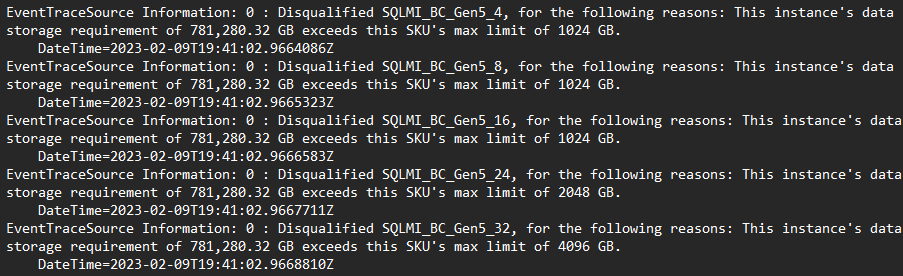
- Pruebe a regenerar la recomendación con la recomendación elástica habilitada. Esta opción usa un modelo de recomendación alternativo, que usa la generación de perfiles personalizada de rendimiento de precios en los clientes existentes en la nube.
- Si no se generaron recomendaciones, esta situación podría significar que no se identificó ninguna configuración que pueda satisfacer completamente los requisitos de rendimiento de la instancia de origen. Para ver las razones por las que se descalificó un tamaño, nivel de servicio o familia de hardware determinado:
