Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Cree un agente de IA inteligente mediante TypeScript y Azure DocumentDB. En este inicio rápido se muestra una arquitectura de dos agentes que realiza la búsqueda semántica de hoteles y genera recomendaciones personalizadas.
Importante
En este ejemplo se usa LangChain, un marco popular para compilar aplicaciones de inteligencia artificial. LangChain proporciona abstracciones para agentes, herramientas y avisos que simplifican el desarrollo de agentes.
Prerrequisitos
Puede usar la CLI para desarrolladores de Azure para crear los recursos de Azure necesarios mediante la ejecución de los azd comandos en el repositorio de ejemplo. Para más información, consulte Implementación de la infraestructura con la CLI para desarrolladores de Azure.
Recursos de Azure
Recurso Azure OpenAI en Microsoft Foundry Models (clásico) con las siguientes implementaciones de modelos en Microsoft Azure AI Foundry:
-
gpt-4oimplementación (Agente de Síntesis) - Se recomienda una capacidad de 50 000 tokens por minuto (TPM) - Implementación de
gpt-4o-mini(Agente de planificador) - Recomendado: capacidad de 30 000 tokens por minuto (TPM) - Implementación de
text-embedding-3-small(inserciones) - Recomendado: capacidad de 10 000 tokens por minuto (TPM) -
Cuotas de token: configure un TPM suficiente para cada implementación para evitar la limitación de velocidad.
- Consulte Administración de cuotas de Azure OpenAI para la administración de cuotas.
- Si encuentra errores 429, aumente la cuota de TPM o reduzca la frecuencia de solicitud.
-
Clúster de Azure DocumentDB (con compatibilidad de MongoDB) con compatibilidad con la búsqueda vectorial:
-
Requisitos de nivel de clúster en función del algoritmo de índice vectorial preferido:
- IVF (Índice de archivo invertido): M10 o superior (algoritmo predeterminado)
- HNSW (Hierarchical Navigable Small World): M30 o superior (basado en grafos)
- DiskANN: M40 o superior (optimizado para gran escala)
-
Configuración del firewall: OBLIGATORIO. Sin una configuración de firewall adecuada, se produce un error en los intentos de conexión.
- Agregue la dirección IP del cliente a las reglas de firewall del clúster. Para obtener más información, consulte Concesión de acceso desde la dirección IP.
- Para la autenticación sin contraseña, asegúrese de que el control de acceso basado en rol (RBAC) está habilitado.
-
Requisitos de nivel de clúster en función del algoritmo de índice vectorial preferido:
Herramientas de desarrollo
- CLI para desarrolladores de Azure para el aprovisionamiento de recursos
- Node.js LTS
- TypeScript 5.0 o posterior
- CLI de Azure para la autenticación
- Visual Studio Code con la extensión DocumentDB para la administración de bases de datos (opcional)
Arquitectura de aplicaciones RAG de agente para Node.js
En el ejemplo se usa una arquitectura de dos agentes donde cada agente tiene un rol específico.

En este ejemplo se usa el marco de agente de LangChain con el SDK de OpenAI. Aprovecha la función de LangChain que llama a abstracciones para la integración de herramientas y sigue un flujo de trabajo lineal entre los agentes y la herramienta de búsqueda. La ejecución es sin estado y sin historial de conversaciones, lo que la convierte en adecuada para escenarios de consulta y respuesta de un solo turno.
Obtención del código de ejemplo de Node.js
Clone o descargue el repositorio Ejemplos de Azure DocumentDB en la máquina local para seguir el inicio rápido.
Vaya al directorio del proyecto:
cd ai/vector-search-agent-typescript
Implementación de recursos de Azure con la CLI para desarrolladores de Azure
Use la CLI para desarrolladores de Azure (azd) para aprovisionar los recursos necesarios de Azure OpenAI y DocumentDB.
Inicie sesión en Azure:
azd auth loginProvisionar e desplegar la infraestructura.
azd upCuando se le solicite, seleccione la suscripción y una ubicación (por ejemplo,
swedencentraloeastus2).Una vez completada la implementación,
azdgenera las variables de entorno que necesita. Cópielos en el.envarchivo (consulte Configuración de variables de entorno).
Sugerencia
Ejecute azd env get-values en cualquier momento para ver los valores de entorno actuales.
Configuración de las variables de entorno
Si ha creado los recursos de Azure manualmente o desea usar sus propios recursos existentes, debe configurar variables de entorno para que la aplicación se conecte a Azure OpenAI y Azure DocumentDB. Si ha usado azd up, puede omitir este paso, ya que las variables de entorno necesarias se establecen automáticamente en el azd entorno y se puede acceder a ellas con azd env get-values.
Cree un .env archivo en la raíz del proyecto para configurar variables de entorno. Puede crear una copia del .env.sample archivo desde el repositorio.
Edite el .env archivo y reemplace estos valores de marcador de posición:
En este inicio rápido se usa una arquitectura de dos agentes (planner + sintetizador) con tres implementaciones de modelos (dos modelos de chat + incrustaciones). Las variables de entorno se configuran para cada implementación del modelo.
-
AZURE_OPENAI_PLANNER_MODEL: nombre del modelo gpt-4o-mini. -
AZURE_OPENAI_SYNTH_MODEL: nombre del modelo gpt-4o que estás utilizando -
AZURE_OPENAI_EMBEDDING_MODEL: nombre del modelo de inserción de texto-3-small.
Puede elegir entre dos métodos de autenticación: autenticación sin contraseña mediante Azure Identity (recomendado) o cadena de conexión tradicional y clave de API.
Opción 1: Autenticación sin contraseña
Use la autenticación sin contraseña con Azure OpenAI y Azure DocumentDB. Establezca USE_PASSWORDLESS=true, AZURE_OPENAI_ENDPOINTy AZURE_DOCUMENTDB_CLUSTER.
# Enable passwordless authentication
USE_PASSWORDLESS=true
# Azure OpenAI Configuration (passwordless)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (passwordless)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Requisitos previos para la autenticación sin contraseña:
Asegúrese de que ha iniciado sesión en Azure:
az loginConceda a su identidad los roles siguientes:
-
Cognitive Services OpenAI Useren el recurso de Azure OpenAI -
DocumentDB Account ContributoryCosmos DB Account Reader Roleen el recurso de Azure DocumentDB
Para más información sobre cómo asignar roles, consulte Asignación de roles de Azure mediante Azure Portal.
-
Funcionamiento de la autenticación sin contraseña
Cuando USE_PASSWORDLESS=true, la aplicación usa DefaultAzureCredential del SDK de Identidad de Azure para obtener un token OAuth. En conexiones de Azure DocumentDB, usa una devolución de llamada de token de OIDC que pasa el token de acceso directamente al controlador de MongoDB. Esto significa que no se almacenan contraseñas ni cadenas de conexión en archivos de configuración.
El flujo de autenticación:
-
DefaultAzureCredentialcomprueba si hay credenciales disponibles (CLI de Azure, identidad administrada, variables de entorno) en orden. - Para Azure OpenAI, el token se pasa automáticamente a los clientes de LangChain
AzureChatOpenAIyAzureOpenAIEmbeddings. - Para Azure DocumentDB, una función de callback de token obtiene un token de acceso y lo proporciona al cliente de MongoDB a través del mecanismo de
MONGODB-OIDCautenticación.
import { AzureOpenAIEmbeddings, AzureChatOpenAI } from "@langchain/openai";
import { MongoClient, OIDCCallbackParams } from 'mongodb';
import { AccessToken, DefaultAzureCredential, TokenCredential, getBearerTokenProvider } from '@azure/identity';
/*
This file contains utility functions to create Azure OpenAI clients for embeddings, planning, and synthesis.
It supports two modes of authentication:
1. API Key based authentication using AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINTenvironment variables.
2. Passwordless authentication using DefaultAzureCredential from Azure Identity library.
*/
// Azure Identity configuration
const OPENAI_SCOPE = 'https://cognitiveservices.azure.com/.default';
const DOCUMENT_DB_SCOPE = 'https://ossrdbms-aad.database.windows.net/.default';
// Azure identity credential (used for passwordless auth)
const CREDENTIAL = new DefaultAzureCredential();
function requireEnvVars(names: string[]) {
const missing = names.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missing.length > 0) {
throw new Error(`Missing required environment variables: ${missing.join(', ')}`);
}
}
// Token callback for MongoDB OIDC authentication
async function azureIdentityTokenCallback(
params: OIDCCallbackParams,
credential: TokenCredential
): Promise<{ accessToken: string; expiresInSeconds: number }> {
const tokenResponse: AccessToken | null = await credential.getToken([DOCUMENT_DB_SCOPE]);
return {
accessToken: tokenResponse?.token || '',
expiresInSeconds: (tokenResponse?.expiresOnTimestamp || 0) - Math.floor(Date.now() / 1000)
};
Opción 2: Cadena de conexión y autenticación de clave de API
Use la autenticación basada en claves estableciendo USE_PASSWORDLESS=false (o omitiéndolo) y proporcionando los valores de AZURE_OPENAI_API_KEY y AZURE_DOCUMENTDB_CONNECTION_STRING en el archivo .env.
# Disable passwordless authentication
USE_PASSWORDLESS=false
# Azure OpenAI Configuration (API key)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_API_KEY=your-azure-openai-api-key
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (connection string)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_CONNECTION_STRING=mongodb+srv://username:password@cluster.mongocluster.cosmos.azure.com/
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Estructura de proyecto
El proyecto sigue un diseño de proyecto estándar Node.js/TypeScript. La estructura de directorios debe tener un aspecto similar a la estructura siguiente:
vector-search-agent-typescript/
├── src/
│ ├── agent.ts # Main agent application
│ ├── upload-documents.ts # Data upload utility
│ ├── cleanup.ts # Database cleanup utility
│ ├── vector-store.ts # Vector store and tool implementation
│ ├── utils/
│ │ ├── clients.ts # Azure OpenAI and DocumentDB client setup
│ │ ├── prompts.ts # System prompts and tool definitions
│ │ ├── types.ts # TypeScript type definitions
│ │ └── mongo.ts # MongoDB utility functions
│ └── scripts/ # Additional utility scripts
├── .env # Environment variable configuration
├── package.json # npm dependencies and scripts
└── tsconfig.json # TypeScript configuration
Exploración del código de Node.js para la aplicación RAG agentic
En esta sección se describen los componentes principales del flujo de trabajo del agente de IA. Resalta cómo los agentes procesan las solicitudes, cómo las herramientas conectan la inteligencia artificial a la base de datos y cómo las indicaciones guían el comportamiento de la inteligencia artificial.
aplicación de agente RAG de Node.js
El src/agent.ts archivo organiza un sistema de recomendaciones de hoteles con tecnología de IA.
La aplicación usa dos servicios de Azure:
- Azure OpenAI que usa modelos de INTELIGENCIA ARTIFICIAL que comprenden las consultas y generan recomendaciones
- Azure DocumentDB que almacena datos de hotel y realiza búsquedas de similitud vectorial
componentes de agente y herramienta de Node.js
Los tres componentes funcionan juntos para procesar la solicitud de búsqueda del hotel:
- Agente de Planner : interpreta la solicitud y decide cómo buscar
- Herramienta de búsqueda de vectores - Busca hoteles similares a los que describe el agente planificador
- Agente de sintetizador : escribe una recomendación útil basada en los resultados de la búsqueda.
Flujo de trabajo de la aplicación Agentic RAG
La aplicación procesa una solicitud de búsqueda de hotel en dos pasos:
- Planificación: El flujo de trabajo llama al agente del planificador, que analiza la consulta del usuario (como "hoteles cerca de caminos para correr") y busca en la base de datos los hoteles que coinciden.
- Sintetización: El flujo de trabajo llama al agente del sintetizador, que revisa los resultados de la búsqueda y escribe una recomendación personalizada que explica qué hoteles coinciden mejor con la solicitud.
// Authentication
const clients = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1' ? createClientsPasswordless() : createClients();
const { embeddingClient, plannerClient, synthClient, dbConfig } = clients;
console.log(`DEBUG mode is ${process.env.DEBUG === 'true' ? 'ON' : 'OFF'}`);
console.log(`DEBUG_CALLBACKS length: ${DEBUG_CALLBACKS.length}`);
// Get vector store (get docs, create embeddings, insert docs)
const store = await getExistingStore(
embeddingClient,
dbConfig);
const query = process.env.QUERY || "quintessential lodging near running trails, eateries, retail";
const nearestNeighbors = parseInt(process.env.NEAREST_NEIGHBORS || '5', 10);
//Run planner agent
const hotelContext = await runPlannerAgent(plannerClient, embeddingClient, query, store, nearestNeighbors);
if (process.env.DEBUG === 'true') console.log(hotelContext);
//Run synth agent
const finalAnswer = await runSynthesizerAgent(synthClient, query, hotelContext);
// Get final recommendation (data + AI)
console.log('\n--- FINAL ANSWER ---');
console.log(finalAnswer);
agentes de Node.js para planear y sintetizar
El src/agent.ts archivo de origen implementa los agentes de planificación y síntesis que trabajan juntos para procesar las solicitudes de búsqueda de hoteles.
Agente de Planificador
El agente de planner es el responsable de la toma de decisiones que determina cómo buscar hoteles.
El agente de planner recibe la consulta del lenguaje natural del usuario y la envía a un modelo de IA mediante el marco de agente de LangChain junto con las herramientas disponibles que puede usar. La inteligencia artificial decide llamar a la herramienta de búsqueda de vectores y proporciona parámetros de búsqueda. LangChain controla automáticamente la ejecución de la herramienta y devuelve los hoteles coincidentes. En lugar de codificar la lógica de búsqueda de forma dura, la inteligencia artificial interpreta lo que el usuario quiere y elige cómo buscar, lo que hace que el sistema sea flexible para diferentes tipos de consultas.
async function runPlannerAgent(
plannerClient: any,
embeddingClient: any,
userQuery: string,
store: AzureDocumentDBVectorStore,
nearestNeighbors = 5
): Promise<string> {
console.log('\n--- PLANNER ---');
const userMessage = `Use the "${TOOL_NAME}" tool with nearestNeighbors=${nearestNeighbors} and query="${userQuery}". Do not answer directly; call the tool.`;
const contextSchema = z.object({
store: z.any(),
embeddingClient: z.any()
});
const agent = createAgent({
model: plannerClient,
systemPrompt: PLANNER_SYSTEM_PROMPT,
tools: [getHotelsToMatchSearchQuery],
contextSchema,
});
const agentResult = await agent.invoke(
{ messages: [{ role: 'user', content: userMessage }] },
// @ts-ignore
{ context: { store, embeddingClient }, callbacks: DEBUG_CALLBACKS }
);
const plannerMessages = agentResult.messages || [];
const searchResultsAsText = extractPlannerToolOutput(plannerMessages);
return searchResultsAsText;
}
Agente de sintetizador
El agente de sintetizador es el escritor que crea recomendaciones útiles.
El agente de sintetizador recibe la consulta de usuario original junto con los resultados de búsqueda del hotel. Envía todo a un modelo de IA con instrucciones para escribir recomendaciones. Devuelve una respuesta de lenguaje natural que compara hoteles y explica las mejores opciones. Este enfoque es importante porque los resultados de búsqueda sin procesar no son fáciles de usar. El sintetizador transforma los registros de base de datos en una recomendación conversacional que explica por qué determinados hoteles coinciden con las necesidades del usuario.
async function runSynthesizerAgent(synthClient: any, userQuery: string, hotelContext: string): Promise<string> {
console.log('\n--- SYNTHESIZER ---');
let conciseContext = hotelContext;
console.log(`Context size is ${conciseContext.length} characters`);
const agent = createAgent({
model: synthClient,
systemPrompt: SYNTHESIZER_SYSTEM_PROMPT,
});
const agentResult = await agent.invoke({
messages: [{
role: 'user',
content: createSynthesizerUserPrompt(userQuery, conciseContext)
}]
});
const synthMessages = agentResult.messages;
const finalAnswer = synthMessages[synthMessages.length - 1].content;
console.log(`Output: ${finalAnswer.length} characters of final recommendation`);
return finalAnswer as string;
}
Herramientas de agente para búsqueda en almacenamiento de vectores
El src/vector-store.ts archivo de origen define la herramienta de búsqueda vectorial que usa el agente de Planner.
El archivo de herramientas define una herramienta de búsqueda que el agente de IA puede usar para buscar hoteles. Esta herramienta es cómo se conecta el agente a la base de datos. La inteligencia artificial no busca directamente la base de datos. Se pide que use la herramienta de búsqueda y la herramienta ejecuta la búsqueda real.
Node.js Función como definición de herramienta
La función de tool LangChain crea una herramienta a partir de una función TypeScript normal. La definición de la herramienta incluye el nombre, la descripción y el esquema (mediante Zod para la validación). Esta definición permite que la inteligencia artificial sepa que la herramienta existe y cómo usarla correctamente.
export const getHotelsToMatchSearchQuery = tool(
async ({ query, nearestNeighbors }, config): Promise<string> => {
try {
const store = config.context.store as AzureDocumentDBVectorStore;
const embeddingClient = config.context.embeddingClient as AzureOpenAIEmbeddings;
// Create query embedding and perform search
const queryVector = await embeddingClient.embedQuery(query);
const results = await store.similaritySearchVectorWithScore(queryVector, nearestNeighbors);
console.log(`Found ${results.length} documents from vector store`);
// Format results for synthesizer
const formatted = results.map(([doc, score]) => {
const md = doc.metadata as Partial<HotelForVectorStore>;
console.log(`Hotel: ${md.HotelName ?? 'N/A'}, Score: ${score}`);
return formatHotelForSynthesizer(md, score);
}).join('\n\n');
return formatted;
} catch (error) {
console.error('Error in getHotelsToMatchSearchQuery tool:', error);
return 'Error occurred while searching for hotels.';
}
},
{
name: TOOL_NAME,
description: TOOL_DESCRIPTION,
schema: z.object({
query: z.string(),
nearestNeighbors: z.number().optional().default(5),
}),
}
);
ejecución de la herramienta Node.js con la búsqueda de vectores de Azure DocumentDB
Cuando la IA llama a la herramienta, se ejecuta el cuerpo de la función. Genera una inserción convirtiendo la consulta de texto en un vector numérico mediante el modelo de inserción de Azure OpenAI. A continuación, busca en la base de datos enviando el vector a Azure DocumentDB, que busca hoteles con vectores similares que significan descripciones similares. Por último, da formato a los resultados convirtiendo los registros de la base de datos en texto legible que el agente de sintetizador puede comprender.
La implementación aprovecha LangChain AzureDocumentDBVectorStore para una integración perfecta con Azure DocumentDB.
¿Por qué usar este patrón?
Separar la herramienta del agente proporciona flexibilidad. La inteligencia artificial decide cuándo buscar y qué buscar, mientras que la herramienta controla cómo buscar. Puede agregar más herramientas sin cambiar la lógica del agente.
Indicaciones del agente para orientar el comportamiento de la inteligencia artificial
El src/utils/prompts.ts archivo de origen contiene avisos del sistema y definiciones de herramientas para los agentes.
El archivo prompts define las instrucciones y el contexto proporcionados a los modelos de IA para los agentes de planificador y sintetizador. Estas indicaciones guían el comportamiento de la inteligencia artificial y garantizan que comprende su rol en el flujo de trabajo.
La calidad de las respuestas de inteligencia artificial depende en gran medida de las instrucciones claras. Estos avisos establecen límites, definen el formato de salida y centran la inteligencia artificial en el objetivo del usuario de tomar una decisión. Puede personalizar estas indicaciones para cambiar el comportamiento de los agentes sin modificar ningún código.
export const PLANNER_SYSTEM_PROMPT = `You are a hotel search planner. Transform the user's request into a clear, detailed search query for a vector database.
CRITICAL REQUIREMENT: You MUST ALWAYS call the "${TOOL_NAME}" tool. This is MANDATORY for every request.
Use a tool call with:
- query (string)
- nearestNeighbors (number 1-20)
QUERY REFINEMENT RULES:
- If vague (e.g., "nice hotel"), add specific attributes: "hotel with high ratings and good amenities"
- If minimal (e.g., "cheap"), expand: "budget hotel with good value"
- Preserve specific details from user (location, amenities, business/leisure)
- Keep natural language - this is for semantic search
- Don't just echo the input - improve it for better search results
- nearestNeighbors: Use 3-5 for specific requests, 10-15 for broader requests, max 20
EXAMPLES:
User: "cheap hotel" → {"tool": "${TOOL_NAME}", "args": {"query": "budget-friendly hotel with good value and affordable rates", "nearestNeighbors": 10}}
User: "hotel near downtown with parking" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel near downtown with good parking and wifi", "nearestNeighbors": 5}}
User: "nice place to stay" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel with high ratings, good reviews, and quality amenities", "nearestNeighbors": 10}}
Do not answer the user directly. Always call the tool.`;
// ============================================================================
// Synthesizer Prompts
// ============================================================================
export const SYNTHESIZER_SYSTEM_PROMPT = `You are an expert hotel recommendation assistant using vector search results.
Only use the TOP 3 results provided. Do not request additional searches or call other tools.
GOAL: Provide a concise comparative recommendation to help the user choose between the top 3 options.
REQUIREMENTS:
- Compare only the top 3 results across the most important attributes: rating, score, location, price-level (if available), and key tags (parking, wifi, pool).
- Identify the main tradeoffs in one short sentence per tradeoff.
- Give a single clear recommendation with one short justification sentence.
- Provide up to two alternative picks (one sentence each) explaining when they are preferable.
FORMAT CONSTRAINTS:
- Plain text only (no markdown).
- Keep the entire response under 220 words.
- Use simple bullets (•) or numbered lists and short sentences (preferably <25 words per sentence).
- Preserve hotel names exactly as provided in the tool summary.
Do not add extra commentary, marketing language, or follow-up questions. If information is missing and necessary to choose, state it in one sentence and still provide the best recommendation based on available data.`;
Preparación y carga de datos en Azure DocumentDB con Node.js
En el ejemplo se usan datos de hotel de un archivo JSON. El repositorio incluye dos versiones:
-
Hotels.json- Datos de hotel sin incrustaciones vectoriales (usadas por este ejemplo) -
Hotels_Vector.json: datos del hotel con inserciones calculadas previamente (usadas por otros ejemplos).
Cómo funciona la carga
El upload-documents.ts script realiza tres pasos:
-
Cargar datos: lee registros del hotel del archivo
Hotels.json. -
Generar incrustaciones : para cada hotel, el script envía el
Descriptioncampo al modelo de Azure OpenAItext-embedding-3-smallpara generar una inserción de vectores 1536 dimensionales. Esto convierte la descripción del texto en una representación numérica que captura su significado semántico. - Inserción e índice : el script inserta documentos (con sus incrustaciones) en la colección de Azure DocumentDB y crea un índice vectorial mediante el algoritmo configurado (SIGHT, HNSW o DiskANN).
import { createClientsPasswordless, createClients } from './utils/clients.js';
import { getStore } from './vector-store.js';
/**
* Upload documents to Azure DocumentDB MongoDB Vector Store
*/
async function uploadDocuments() {
try {
console.log('Starting document upload...\n');
// Get clients based on authentication mode
const usePasswordless = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1';
console.log(`Authentication mode: ${usePasswordless ? 'Passwordless (Azure AD)' : 'API Key'}`);
console.log('\nEnvironment variables check:');
console.log(` DATA_FILE_WITHOUT_VECTORS: ${process.env.DATA_FILE_WITHOUT_VECTORS}`);
console.log(` AZURE_DOCUMENTDB_DATABASENAME: ${process.env.AZURE_DOCUMENTDB_DATABASENAME}`);
console.log(` AZURE_DOCUMENTDB_COLLECTION: ${process.env.AZURE_DOCUMENTDB_COLLECTION}`);
console.log(` AZURE_DOCUMENTDB_CLUSTER: ${process.env.AZURE_DOCUMENTDB_CLUSTER}`);
console.log(` AZURE_OPENAI_EMBEDDING_MODEL: ${process.env.AZURE_OPENAI_EMBEDDING_MODEL}`);
const requiredEnvVars = [
'DATA_FILE_WITHOUT_VECTORS',
'AZURE_DOCUMENTDB_DATABASENAME',
'AZURE_DOCUMENTDB_COLLECTION',
'AZURE_DOCUMENTDB_CLUSTER',
'AZURE_OPENAI_EMBEDDING_MODEL',
];
const missingEnvVars = requiredEnvVars.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missingEnvVars.length > 0) {
throw new Error(`Missing required environment variables: ${missingEnvVars.join(', ')}`);
}
const clients = usePasswordless ? createClientsPasswordless() : createClients();
const { embeddingClient, dbConfig } = clients;
console.log('\ndbConfig properties:');
console.log(` instance: ${dbConfig.instance}`);
console.log(` databaseName: ${dbConfig.databaseName}`);
console.log(` collectionName: ${dbConfig.collectionName}`);
// Check for data file path
const dataFilePath = process.env.DATA_FILE_WITHOUT_VECTORS!;
console.log(`\nReading data from: ${dataFilePath}`);
console.log(`Database: ${dbConfig.databaseName}`);
console.log(`Collection: ${dbConfig.collectionName}`);
console.log(`Vector algorithm: ${process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf'}\n`);
// Upload documents using existing getStore function
const startTime = Date.now();
const store = await getStore(dataFilePath, embeddingClient, dbConfig);
const duration = ((Date.now() - startTime) / 1000).toFixed(2);
console.log(`\n✓ Upload completed in ${duration} seconds`);
// Close connection
await store.close();
console.log('✓ Connection closed');
// Force exit to ensure process terminates (Azure credential timers may still be active)
process.exit(0);
} catch (error: any) {
console.error('\n✗ Upload failed:', error?.message || error);
console.error('\nFull error:', error);
process.exit(1);
}
}
// Run the upload
uploadDocuments();
Creación de índices vectoriales
El índice vectorial es lo que permite una búsqueda rápida de similitud. Cuando se crea el índice, Azure DocumentDB organiza los vectores de inserción para que las consultas como "buscar hoteles similares a esta descripción" se puedan responder de forma eficaz sin examinar todos los documentos.
El tipo de índice que elija afecta al rendimiento:
| Algoritmo | Nivel de clúster | Más adecuado para |
|---|---|---|
| FIV | M10+ | Conjuntos de datos pequeños a medianos, menor costo |
| HNSW | M30+ | Alto nivel de recuperación y consultas rápidas |
| DiskANN | M40+ | Conjuntos de datos a gran escala, miles de millones de vectores |
import {
AzureDocumentDBVectorStore,
AzureDocumentDBSimilarityType,
AzureDocumentDBConfig
} from "@langchain/azure-cosmosdb";
import type { AzureOpenAIEmbeddings } from "@langchain/openai";
import { readFileSync } from 'fs';
import { Document } from '@langchain/core/documents';
import { HotelsData, Hotel } from './utils/types.js';
import { TOOL_NAME, TOOL_DESCRIPTION } from './utils/prompts.js';
import { z } from 'zod';
import { tool } from "langchain";
import { MongoClient } from 'mongodb';
import { BaseMessage } from "@langchain/core/messages";
type HotelForVectorStore = Omit<Hotel, 'Description_fr' | 'Location' | 'Rooms'>;
// Helper function for similarity type
function getSimilarityType(similarity: string) {
switch (similarity.toUpperCase()) {
case 'COS': return AzureDocumentDBSimilarityType.COS;
case 'L2': return AzureDocumentDBSimilarityType.L2;
case 'IP': return AzureDocumentDBSimilarityType.IP;
default: return AzureDocumentDBSimilarityType.COS;
}
}
// Consolidated vector index configuration
function getVectorIndexOptions() {
const algorithm = process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf';
const dimensions = parseInt(process.env.EMBEDDING_DIMENSIONS || '1536');
const similarity = getSimilarityType(process.env.VECTOR_SIMILARITY || 'COS');
const baseOptions = { dimensions, similarity };
switch (algorithm) {
case 'vector-hnsw':
return {
kind: 'vector-hnsw' as const,
m: parseInt(process.env.HNSW_M || '16'),
efConstruction: parseInt(process.env.HNSW_EF_CONSTRUCTION || '64'),
...baseOptions
};
case 'vector-diskann':
return {
kind: 'vector-diskann' as const,
...baseOptions
};
case 'vector-ivf':
default:
Ejecución de la aplicación RAG agentic con Node.js
Instale las dependencias:
npm installAntes de ejecutar el agente, cargue los datos del hotel con inserciones. El
upload-documents.tscomando carga hoteles desde el archivo JSON, genera incrustaciones para cada hotel mediantetext-embedding-3-small, inserta documentos en Azure DocumentDB y crea un índice vectorial.npm run uploadEjecute el agente de recomendación de hotel mediante el
agent.tscomando . El agente llama al agente de planificación, al vector de búsqueda y al agente sintetizador. La salida incluye puntuaciones de similitud y el análisis comparativo del agente sintetizador con recomendaciones.npm startDEBUG mode is OFF DEBUG_CALLBACKS length: 0 Connected to existing vector store: Hotels.hotel_data --- PLANNER --- Found 5 documents from vector store Hotel: Nordick's Valley Motel, Score: 0.49866509437561035 Hotel: White Mountain Lodge & Suites, Score: 0.48731985688209534 Hotel: Trails End Motel, Score: 0.47985398769378662 Hotel: Country Comfort Inn, Score: 0.47431993484497070 Hotel: Lakefront Captain Inn, Score: 0.45787304639816284 --- SYNTHESIZER --- Context size is 3233 characters Output: 812 characters of final recommendation --- FINAL ANSWER --- 1. COMPARISON SUMMARY: • Nordick's Valley Motel has the highest rating (4.5) and offers free parking, air conditioning, and continental breakfast. It is located in Washington D.C., near historic attractions and trails. • White Mountain Lodge & Suites is a resort with unique amenities like a pool, restaurant, and meditation gardens, but has the lowest rating (2.4). It is located in Denver, surrounded by forest trails. • Trails End Motel is budget-friendly with a moderate rating (3.2), free parking, free wifi, and a restaurant. It is close to downtown Scottsdale and eateries. Key tradeoffs: - Nordick's Valley Motel excels in rating and proximity to historic attractions but lacks a pool or free wifi. - White Mountain Lodge & Suites offers resort-style amenities and forest trails but has the lowest rating. - Trails End Motel balances affordability and essential amenities but has fewer unique features compared to the others. 2. BEST OVERALL: Nordick's Valley Motel is the best choice for its high rating, proximity to trails and attractions, and free parking. 3. ALTERNATIVE PICKS: • Choose White Mountain Lodge & Suites if you prioritize resort amenities and forest trails over rating. • Choose Trails End Motel if affordability and proximity to downtown Scottsdale are your main concerns.
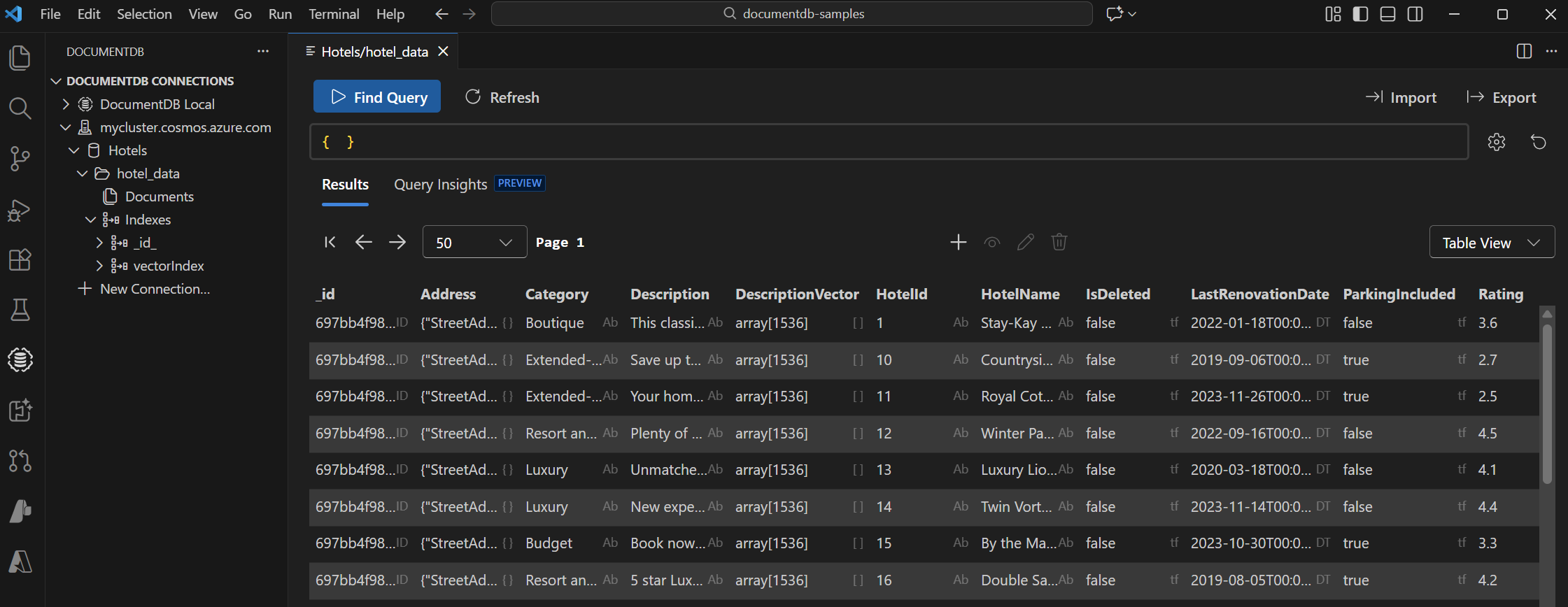
Visualización y administración de datos en Visual Studio Code
Seleccione la extensión DocumentDB en Visual Studio Code para conectarse a la cuenta de Azure DocumentDB.
Vea los datos e índices en la base de datos Hotels.
Limpieza de recursos
Si usó azd up para aprovisionar recursos, puede quitar todos los recursos de Azure con:
azd down
Si ha creado manualmente los recursos y desea quitar todos los recursos, elimine el grupo de recursos para evitar costos adicionales.
Si desea reutilizar los recursos, use el comando cleanup para eliminar la base de datos de prueba cuando haya terminado. Ejecute el siguiente comando:
npm run cleanup