Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se muestra cómo usar Apache Spark Structured Streaming para leer y escribir datos con Apache Kafka en Azure HDInsight.
El flujo estructurado de Spark es un motor de procesamiento de flujo basado en Spark SQL. Permite expresar los cálculos de streaming de la misma forma que el cálculo por lotes de los datos estáticos.
En este tutorial, aprenderá a:
- Uso de una plantilla de Azure Resource Manager para crear clústeres
- Uso del flujo estructurado de Spark con Kafka
Cuando haya terminado los pasos que se indican en este documento, no olvide eliminar los clústeres para evitar gastos innecesarios.
Prerrequisitos
jq, un procesador JSON de línea de comandos. Vea https://stedolan.github.io/jq/.
Experiencia en el uso de Jupyter Notebooks con Spark en HDInsight. Para más información, consulte el documento Ejecución de consultas interactivas en clústeres de Azure Spark en HDInsight.
Experiencia con el lenguaje de programación Scala. El código utilizado en este tutorial está escrito en Scala.
Debe estar familiarizado con la creación de temas de Kafka. Para más información, consulte el documento Guía de inicio rápido: Creación de un clúster de Apache Kafka en HDInsight.
Importante
Los pasos que se describen en este documento necesitan un grupo de recursos de Azure que contiene un clúster Spark de HDInsight y un clúster Kafka de HDInsight. Estos dos clústeres se encuentran en una instancia de Azure Virtual Network, lo que permite al clúster Spark comunicarse directamente con el clúster Kafka.
Para su comodidad, este documento está vinculado con una plantilla que puede crear todos los recursos de Azure necesarios.
Para más información sobre cómo usar HDInsight en una red virtual, consulte el documento Plan a virtual network for HDInsight (Planeación de una red virtual para HDInsight).
Flujos estructurados con Apache Kafka
Spark Structured Streaming es un motor de procesamiento de flujos basado en Spark SQL. Cuando se usa Structured Streaming, puede escribir consultas de flujos estructurados de la misma forma que las consultas por lotes.
Los siguientes fragmentos de código muestran la lectura desde Kafka y el almacenamiento en un archivo. La primera de ellas es una operación por lotes, mientras que la segunda es una operación de streaming:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
En ambos fragmentos de código, se leen datos desde Kafka y se escriben en un archivo. Las diferencias entre los ejemplos son:
| Batch | Streaming |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
La operación de streaming también utiliza awaitTermination(30000), lo que detiene la secuencia después de 30 000 ms.
Para usar Structured Streaming con Kafka, el proyecto debe tener una dependencia en el paquete org.apache.spark : spark-sql-kafka-0-10_2.11. La versión de este paquete debe coincidir con la versión de Spark en HDInsight. Para Spark 2.4 (disponible en HDInsight 4.0), encontrará la información de dependencias para diferentes tipos de proyectos en https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Para la instancia de Jupyter Notebook que se proporciona con este tutorial, la celda siguiente carga esta dependencia del paquete:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Creación de los clústeres
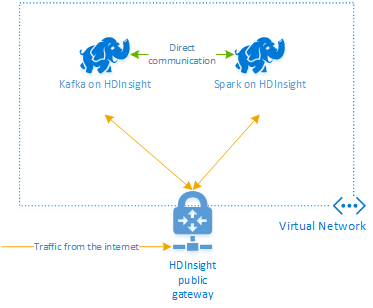
Apache Kafka en HDInsight no proporciona acceso a los agentes de Kafka a través de Internet. Todos los elementos que utilicen Kafka deben estar en la misma red virtual de Azure. En este tutorial, los clústeres Kafka y Spark se encuentran en una red virtual de Azure.
En el diagrama siguiente, se muestra cómo fluye la comunicación entre Spark y Kafka:
Nota:
El servicio Kafka se limita a la comunicación dentro de la red virtual. Se puede acceder a otros servicios del clúster, como SSH y Ambari, a través de Internet. Para más información sobre los puertos públicos disponibles en HDInsight, consulte Puertos e identificadores URI usados en HDInsight.
Para crear una instancia de Azure Virtual Network y, posteriormente, crear clústeres de Kafka y Spark dentro de ella, siga estos pasos:
Utilice el siguiente botón para iniciar sesión en Azure y abrir la plantilla en Azure Portal.

La plantilla de Azure Resource Manager se encuentra en https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json .
Esta plantilla crea los siguientes recursos:
Un clúster de Kafka en HDInsight 4.0 o 5.0.
Un clúster de Spark 2.4 o 3.1 en HDInsight 4.0 o 5.0.
Una instancia de Azure Virtual Network, que contiene los clústeres de HDInsight.
Importante
El cuaderno de flujo estructurado que se usa en este tutorial requiere Spark 2.4 o 3.1 en HDInsight 4.0 o 5.0. Si usa una versión anterior de Spark en HDInsight, recibirá errores al usar dicho cuaderno.
Utilice los datos siguientes para rellenar las entradas de la sección Plantilla personalizada:
Configuración Valor Subscription Su suscripción de Azure Resource group El grupo de recursos que contiene los recursos. Location La región de Azure en que se crean los recursos. Spark Cluster Name (Nombre de clúster de Spark) El nombre del clúster de Spark. Los seis primeros caracteres deben ser distintos del nombre de clúster de Kafka. Kafka Cluster Name (Nombre de clúster de Kafka) El nombre del clúster de Kafka. Los seis primeros caracteres deben ser distintos del nombre de clúster de Spark. Cluster Login User Name (Nombre de usuario de inicio de sesión del clúster) El nombre del usuario administrador de los clústeres. Cluster Login Password (Contraseña de inicio de sesión del clúster) La contraseña del usuario administrador de los clústeres. SSH User Name (Nombre de usuario de SSH) El usuario de SSH que se crea para los clústeres. SSH Password (Contraseña de SSH) La contraseña del usuario de SSH. 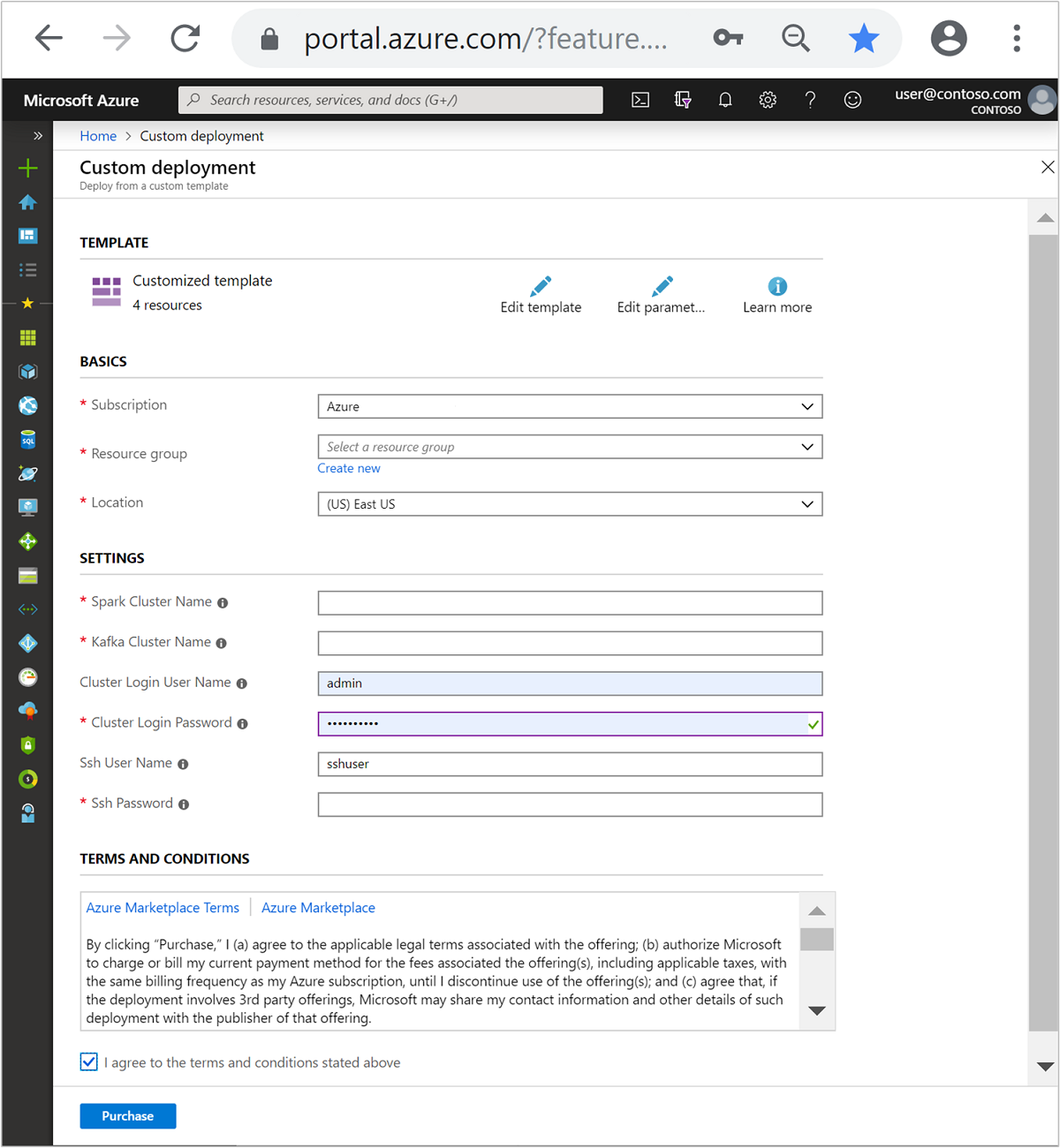
Lea los Términos y condiciones y seleccione Acepto los términos y condiciones indicados anteriormente.
Seleccione Comprar.
Nota
Los clústeres pueden tardar hasta 20 minutos en crearse.
Uso de Spark Structured Streaming
Este ejemplo muestra cómo usar Spark Structured Streaming con Kafka en HDInsight. Utiliza datos de carreras de taxi, proporcionados por la ciudad de Nueva York. El conjunto de datos utilizado por este cuaderno procede de 2016 Green Taxi Trip Data.
Recopile información de host. Utilice curl y los comandos de jq siguientes para obtener su instancia de Kafka ZooKeeper y la información de hosts del agente. Los comandos están diseñados para un símbolo del sistema de Windows; habrá ligeras diferencias en otros entornos. Reemplace
KafkaClusterpor el nombre de su clúster de Kafka yKafkaPasswordpor la contraseña de inicio de sesión del clúster. Además, reemplaceC:\HDI\jq-win64.exepor la ruta de acceso real a la instalación jq. Escriba los comandos en un símbolo del sistema de Windows y guarde la salida para su uso en pasos posteriores.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dondeCLUSTERNAMEes el nombre del clúster. Cuando se lo soliciten, escriba el nombre de inicio de sesión del clúster (administrador) y la contraseña que utilizó cuando creó el clúster.Seleccione Nuevo > Spark para crear un cuaderno.
El streaming de Spark tiene microprocesamiento por lotes, lo que significa que los datos llegan en lotes y la ejecución se realiza en los lotes de datos. Si el ejecutor tiene un tiempo de expiración de inactividad menor que el tiempo que se tarda en procesar el lote, se agregan y quitan ejecutores constantemente. Si el tiempo de espera de inactividad de los ejecutores es mayor que la duración del lote, el ejecutor nunca se quita. Por tanto es aconsejable deshabilitar la asignación dinámica, para lo que hay que establecer spark.dynamicAllocation.enabled en false cuando se ejecutan aplicaciones de streaming.
Cargue los paquetes utilizados por Notebook escribiendo la siguiente información en una celda de Notebook. Ejecute el comando con CTRL + ENTRAR.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Cree el tema de Kafka. Modifique el comando siguiente reemplazando
YOUR_ZOOKEEPER_HOSTSpor la información de host de Zookeeper extraída en el primer paso. Escriba el comando editado en el cuaderno de Jupyter Notebook para crear el tematripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersRecupere los datos de las carreras de taxi. Escriba el comando en la celda siguiente para cargar los datos de las carreras de taxi de Nueva York. Los datos se cargan en una trama de datos y, a continuación, esta se muestra como el resultado de la celda.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Establezca la información de los hosts del agente de Kafka. Reemplace
YOUR_KAFKA_BROKER_HOSTSpor la información de hosts de agente que extrajo en el paso 1. Escriba el comando editado en la siguiente celda del cuaderno de Jupyter Notebook.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Envíe los datos a Kafka. En el siguiente comando, el campo
vendoridse utiliza como el valor de clave para el mensaje de Kafka. La clave se usa por Kafka al crear particiones de datos. Todos los campos se almacenan en el mensaje de Kafka como un valor de cadena JSON. Escriba el siguiente comando en Jupyter para guardar los datos en Kafka mediante una consulta por lotes.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Declare un esquema. El comando siguiente muestra cómo usar un esquema al leer datos JSON de Kafka. Escriba el comando en la siguiente celda de Jupyter.
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Seleccione los datos e inicie la secuencia. El comando siguiente muestra cómo recuperar datos de Kafka mediante una consulta por lotes. A continuación, se escriben los resultados en HDFS en el clúster de Spark. En este ejemplo,
selectrecupera el mensaje (campo de valor) de Kafka y le aplica el esquema. Los datos, a continuación, se escriben en HDFS (WASB o ADL) en formato Parquet. Escriba el comando en la siguiente celda de Jupyter.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Puede comprobar que se crearon los archivos escribiendo el comando en la siguiente celda de Jupyter. Muestra los archivos del directorio
/example/batchtripdataen una lista.%%bash hdfs dfs -ls /example/batchtripdataMientras que en el ejemplo anterior se usó una consulta por lotes, el comando siguiente muestra cómo hacer lo mismo mediante una consulta de streaming. Escriba el comando en la siguiente celda de Jupyter.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Ejecute la celda siguiente para comprobar que los archivos se escribieron por la consulta de streaming.
%%bash hdfs dfs -ls /example/streamingtripdata
Limpieza de recursos
Para limpiar los recursos creados por este tutorial puede eliminar el grupo de recursos. Al eliminar el grupo de recursos, también se elimina el clúster de HDInsight asociado, así como cualquier otro recurso asociado al grupo de recursos.
Para quitar el grupo de recursos mediante Azure Portal:
- En Azure Portal, expanda el menú del lado izquierdo para abrir el menú de servicios y elija Grupos de recursos para mostrar la lista de sus grupos de recursos.
- Busque el grupo de recursos que desea eliminar y haga clic con el botón derecho en Más (...) en el lado derecho de la lista.
- Seleccione Eliminar grupo de recursos y confirme la elección.
Advertencia
La facturación del clúster de HDInsight se inicia una vez creado el clúster y solo se detiene cuando se elimina. Se facturan por minuto realizando una prorrata, por lo que siempre debe eliminar aquellos que ya no se estén utilizando.
Al eliminar un clúster de Kafka en HDInsight se eliminan todos los datos almacenados en Kafka.