Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Hive Warehouse Connector (HWC) de Apache es una biblioteca que le permite trabajar más fácilmente con Apache Spark y Apache Hive. Admite tareas como el traslado de datos entre DataFrames de Spark y tablas de Hive. Y también al dirigir datos de streaming de Spark a las tablas de Hive. El conector de Hive Warehouse funciona como un puente entre Spark y Hive. También admite Scala, Java y Python como lenguajes de programación para el desarrollo.
El conector de Hive Warehouse le permite aprovechar las ventajas de las características exclusivas de Hive y Spark para crear eficaces aplicaciones de macrodatos.
Apache Hive ofrece compatibilidad con las transacciones de base de datos de atomicidad, coherencia, aislamiento, durabilidad (ACID). Para obtener más información sobre ACID y las transacciones en Hive, consulte Hive Transactions (Transacciones de Hive). Hive también ofrece controles de seguridad detallados a través de Apache Ranger y el procesamiento analítico de baja latencia que no está disponible en Apache Spark.
Apache Spark tiene una API de streaming estructurada que proporciona funcionalidades de streaming que no están disponibles en Apache Hive. A partir de HDInsight 4.0, Apache Spark 2.3.1 (y superiores) y Apache Hive 3.1.0 tienen catálogos de metastore independientes, lo que dificulta la interoperabilidad.
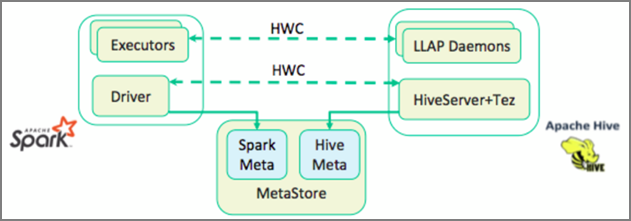
El conector de Hive Warehouse (HWC) simplifica el uso conjunto de Spark y Hive. La biblioteca HWC carga los datos de los demonios de LLAP en los ejecutores de Spark en paralelo. De este modo, es más eficaz y adaptable que usar una conexión JDBC estándar de Spark a Hive. Esto ofrece dos modos de ejecución diferentes para HWC:
- Modo JDBC de Hive a través de HiveServer2
- Modo LLAP de Hive mediante demonios de LLAP [recomendado]
De forma predeterminada, HWC está configurado para usar demonios de LLAP de Hive. Para ejecutar consultas de Hive (tanto de lectura como de escritura) mediante los modos anteriores con sus respectivas API, consulte HWC APIs (API de HWC).
Algunas de las operaciones compatibles con el conector de Hive Warehouse son:
- Descripción de una tabla
- Creación de una tabla de datos en formato ORC
- Selección de datos de Hive y recuperación de un elemento DataFrame
- Escritura de un elemento DataFrame en Hive en un lote
- Ejecución de una instrucción de actualización de Hive
- Lectura de datos de la tabla de Hive, transformación en Spark y escritura en una nueva tabla de Hive
- Escritura de un flujo de Spark o DataFrame en Hive mediante Hive Streaming
Configuración del conector de Hive Warehouse
Importante
- La instancia interactiva de HiveServer2 instalada en los clústeres de Spark 2.4 Enterprise Security Package no se admite para usarse con Hive Warehouse Connector. En su lugar, debe configurar un clúster interactivo de HiveServer2 independiente para hospedar las cargas de trabajo interactivas de HiveServer2. No se admite una configuración de Hive Warehouse Connector que use un solo clúster de Spark 2.4.
- No se admite el uso de la biblioteca de Hive Warehouse Connector (HWC) para su uso con clústeres de Interactive Query en los que está habilitada la característica Administración de cargas de trabajo (WLM).
En un escenario en el que solo tenga cargas de trabajo de Spark y quiera usar la biblioteca de HWC, asegúrese de que el clúster de Interactive Query no tenga habilitada la característica Administración de cargas de trabajo (la configuración dehive.server2.tez.interactive.queueno está establecida en las configuraciones de Hive).
Para un escenario en el que existan tanto cargas de trabajo de Spark (HWC) como cargas de trabajo nativas de LLAP, debe crear dos clústeres de Interactive Query independientes con la base de datos de metastore compartida. Un clúster para las cargas de trabajo nativas de LLAP donde la característica WLM puede estar habilitada según sea necesario, y otro clúster solo para las cargas de trabajo de HWC, donde la característica WLM no debe estar configurada. Es importante tener en cuenta que puede ver los planes de recursos de WLM desde ambos clústeres, incluso si está habilitada solo en uno de ellos. No realice cambios en los planes de recursos del clúster donde la característica WLM esté deshabilitada, ya que podría afectar a la funcionalidad de WLM en otro clúster. - Aunque Spark admite el lenguaje de computación R para simplificar su análisis de datos, la biblioteca de Hive Warehouse Connector (HWC) no es compatible con R. Para ejecutar las cargas de trabajo de HWC, puede ejecutar consultas desde Spark a Hive utilizando la API HiveWarehouseSession de estilo JDBC que solo admite Scala, Java y Python.
- La ejecución de consultas (tanto de lectura como de escritura) a través de HiveServer2 mediante el modo JDBC no es compatible con tipos de datos complejos, como los tipos Arrays/Struct/Map.
- HWC solo admite la escritura en formatos de archivo ORC. Las escrituras que no son ORC (por ejemplo, formatos de archivo de texto y parquet) no son compatibles con HWC.
Hive Warehouse Connector necesita clústeres independientes para las cargas de trabajo de Spark y de Interactive Query. Siga estos pasos para configurar estos clústeres en Azure HDInsight.
Versiones y tipos de clúster compatibles
| Versión de HWC | Versión de Spark | Versión de InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Creación de clústeres
Cree un clúster de HDInsight Spark 4.0 con una cuenta de almacenamiento y una red virtual de Azure personalizada. Para obtener información sobre cómo crear un clúster en una red virtual de Azure, consulte Add HDInsight to an existing virtual network (Adición de HDInsight a una red virtual existente).
Cree un clúster de Interactive Query de HDInsight (LLAP) 4.0 con la misma cuenta de almacenamiento y la red virtual de Azure que el clúster de Spark.
Definición de configuración de HWC
Recopilación de la información preliminar
Desde un explorador web, vaya a
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE, donde LLAPCLUSTERNAME es el nombre del clúster de Interactive Query.Vaya a Summary>HiveServer2 Interactive JDBC URL y anote el valor. El valor puede ser similar a
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Vaya a Configuraciones del sitio de Hive>avanzadas>avanzadas>hive.zookeeper.quorum y anote el valor. El valor puede ser similar a
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Vaya a Configuraciones>avanzadas>generales>hive.metastore.uris y anote el valor. El valor puede ser similar a
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Vaya a Configuraciones del sitio interactivo de hive>avanzadas>hive-interactive-site avanzadas>hive.llap.daemon.service.hosts y anote el valor. El valor puede ser similar a
@llap0.
Configuración de un clúster de Spark
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs, donde CLUSTERNAME es el nombre del clúster de Apache Spark.Expanda Custom spark2-defaults.
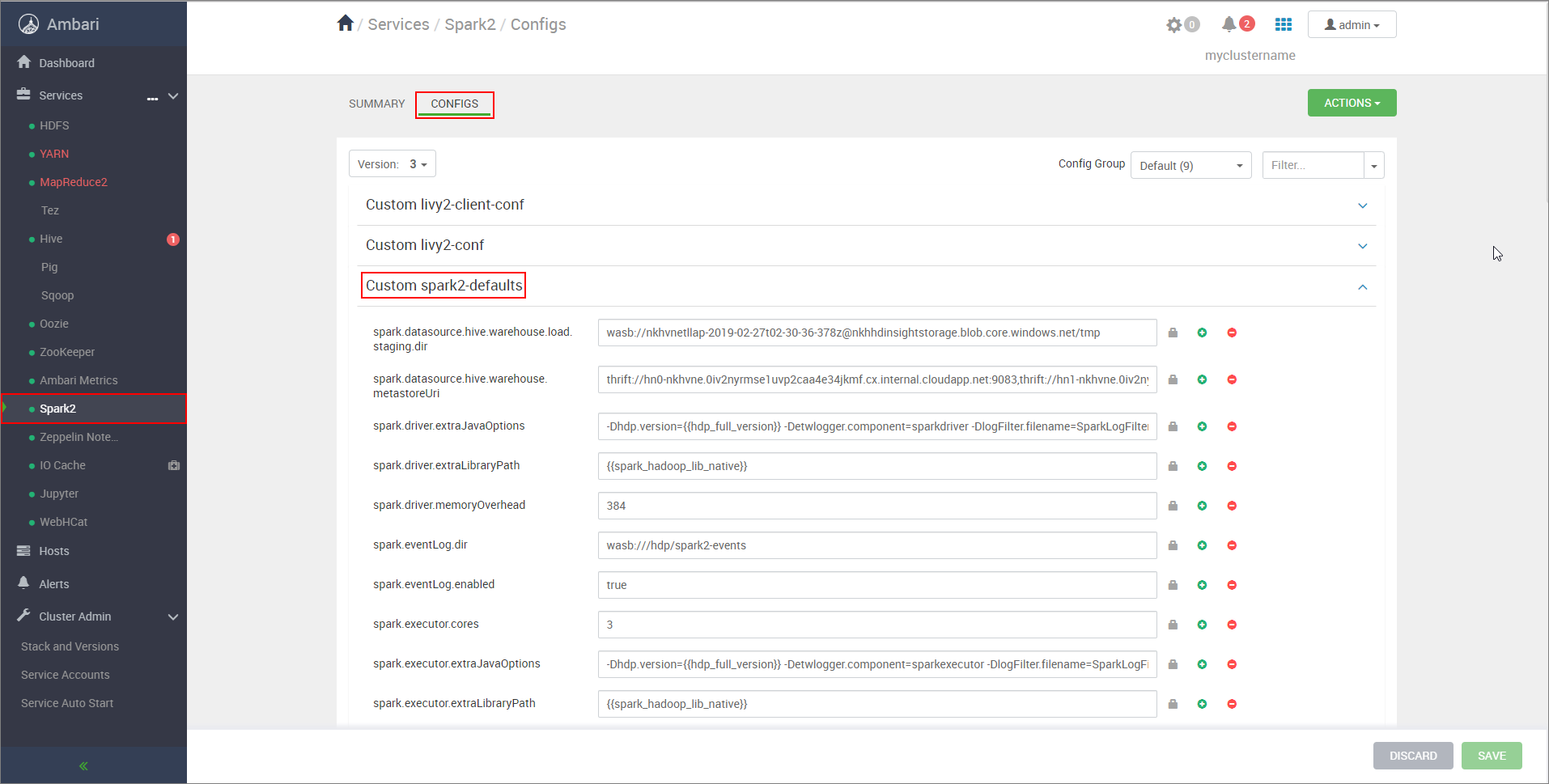
Seleccione Agregar propiedad... para agregar las configuraciones siguientes:
Configuración Value spark.datasource.hive.warehouse.load.staging.dirSi usa una cuenta de almacenamiento de ADLS Gen2, utilice abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp.
Si usa una cuenta de almacenamiento de Azure Blob Storage, utilicewasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Establézcalo en un directorio de almacenamiento provisional adecuado y compatible con HDFS. Si tiene dos clústeres diferentes, para que HiveServer2 tenga acceso al directorio de almacenamiento provisional, este debe ser una carpeta del directorio de almacenamiento provisional de la cuenta de almacenamiento del clúster de LLAP. ReemplaceSTORAGE_ACCOUNT_NAMEpor el nombre de la cuenta de almacenamiento que usa el clúster ySTORAGE_CONTAINER_NAMEes el nombre del contenedor de almacenamiento.spark.sql.hive.hiveserver2.jdbc.urlEl valor obtenido anteriormente de dirección URL JDBC interactiva de HiveServer2 spark.datasource.hive.warehouse.metastoreUriEl valor obtenido anteriormente de hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruepara el modo de clúster YARN yfalsepara el modo de cliente YARN.spark.hadoop.hive.zookeeper.quorumEl valor obtenido anteriormente de hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsEl valor obtenido anteriormente de hive.llap.daemon.service.hosts. Guarde los cambios y reinicie todos los componentes afectados.
Configuración de HWC para los clústeres de Enterprise Security Package (ESP)
Enterprise Security Package (ESP) le proporciona funcionalidades de nivel empresarial, como la autenticación basada en Active Directory, compatibilidad con varios usuarios y control de acceso basado en rol para los clústeres de Apache Hadoop en Azure HDInsight. Para más información, consulte Uso de Enterprise Security Package en HDInsight.
Además de las configuraciones mencionadas en la sección anterior, agregue la siguiente configuración para usar HWC en los clústeres de ESP.
Desde la interfaz de usuario web de Spark Ambari, vaya a Spark2>CONFIGS>Custom spark2-defaults.
Actualice las siguientes propiedades.
Configuración Value spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, donde CLUSTERNAME es el nombre del clúster de Interactive Query. Haga clic en HiveServer2 Interactive. Verá el nombre de dominio completo (FQDN) del nodo principal en el que se ejecuta LLAP, como se muestra en la captura de pantalla. Reemplace<llap-headnode>por este valor.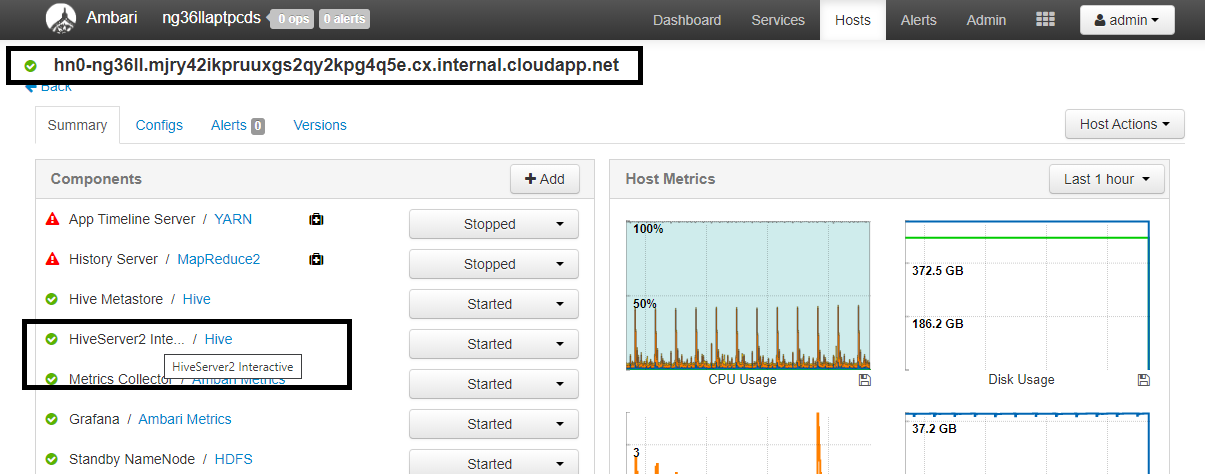
Use el comando ssh para conectarse al clúster de Interactive Query. Busque el parámetro
default_realmen el archivo/etc/krb5.conf. Reemplace<AAD-DOMAIN>por este valor como una cadena en mayúsculas; de lo contrario, la credencial no se encontrará.
Por ejemplo,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Guarde los cambios y reinicie los componentes según sea necesario.
Configuración de Hive Warehouse Connector
Puede elegir entre varios métodos diferentes para conectarse a su clúster de Interactive Query y ejecutar consultas mediante el conector de Hive Warehouse. Entre los métodos admitidos se incluyen las herramientas siguientes:
A continuación se muestran algunos ejemplos para conectarse a HWC desde Spark.
Spark-shell
Se trata de una manera de ejecutar Spark de forma interactiva a través de una versión modificada del shell de Scala.
Use el comando ssh para conectarse al clúster de Apache Spark. Modifique el comando siguiente: reemplace CLUSTERNAME por el nombre del clúster y, luego, escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDesde la sesión de ssh, ejecute el comando siguiente para anotar la versión
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorEdite el código siguiente con la versión
hive-warehouse-connector-assemblyidentificada anteriormente. Ejecute el siguiente comando para iniciar el shell de Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseDespués de iniciar el shell de Spark, se puede iniciar una instancia de Hive Warehouse Connector mediante los siguientes comandos:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit es una utilidad para enviar cualquier programa (o trabajo) de Spark a los clústeres de Spark.
El trabajo spark-submit configurará Spark y Hive Warehouse Connector según nuestras instrucciones, ejecutará el programa que le pasemos y liberará correctamente los recursos que se estaban utilizando.
Una vez que compile el código Scala/Java junto con las dependencias en un archivo jar de ensamblado, use el siguiente comando para iniciar una aplicación de Spark. Reemplace <VERSION> y <APP_JAR_PATH> por los valores reales.
Modo cliente YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarModo de clúster YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Esta utilidad también se usa cuando se ha escrito toda la aplicación en pySpark y se ha empaquetado en archivos .py (Python), de manera que se puede enviar todo el código al clúster de Spark para su ejecución.
En el caso de las aplicaciones de Python, pase un archivo .py, en lugar de /<APP_JAR_PATH>/myHwcAppProject.jar, y agregue el siguiente archivo de configuración (Python .zip) a la ruta de acceso de búsqueda con --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Ejecute consultas a los clústeres de Enterprise Security Package (ESP)
Use kinit antes de iniciar Spark-shell o Spark-submit. Reemplace USERNAME por el nombre de una cuenta de dominio con permisos para tener acceso al clúster. a continuación, ejecute el siguiente comando:
kinit USERNAME
Protección de datos en los clústeres ESP de Spark
Cree una tabla
democon algunos datos de ejemplo mediante los comandos siguientes:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Ver el contenido de la tabla con el siguiente comando. Antes de aplicar la directiva, en la tabla
demose muestra la columna completa.hive.executeQuery("SELECT * FROM demo").show()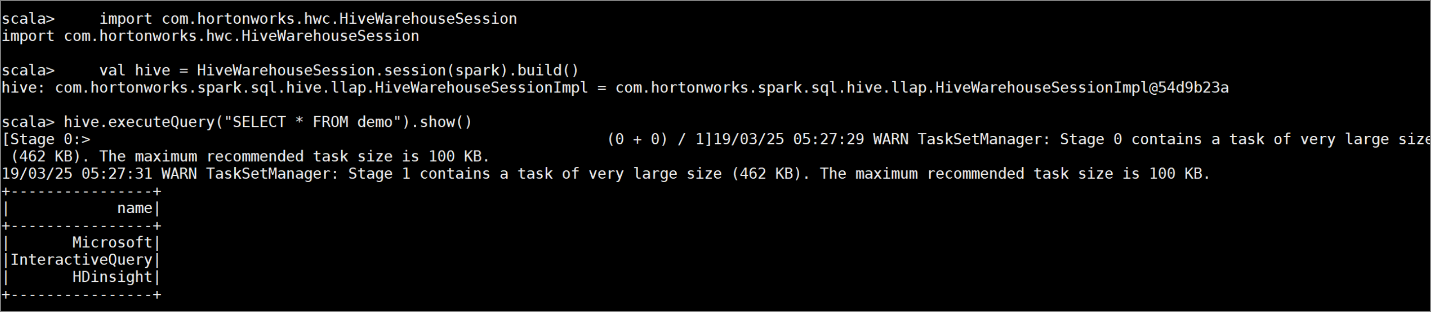
Aplique una directiva de enmascaramiento de columnas que solo muestre los últimos cuatro caracteres de la columna.
Abra la interfaz de usuario de administrador de Ranger en
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Haga clic en el servicio de Hive de su clúster en Hive.
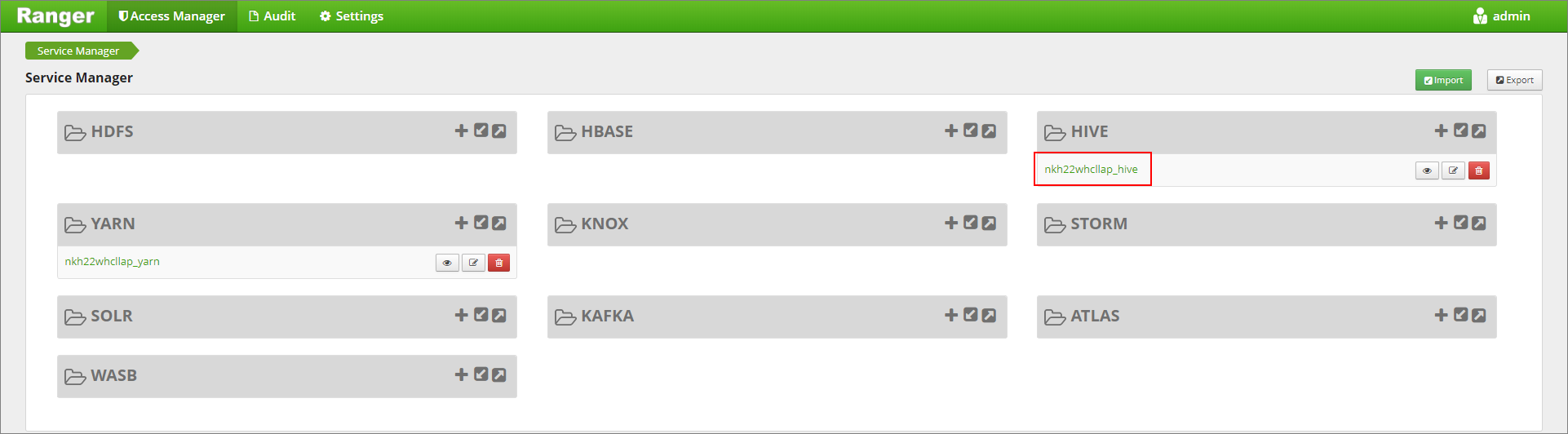
Haga clic en la pestaña Enmascaramiento y, a continuación, en Agregar nueva directiva.
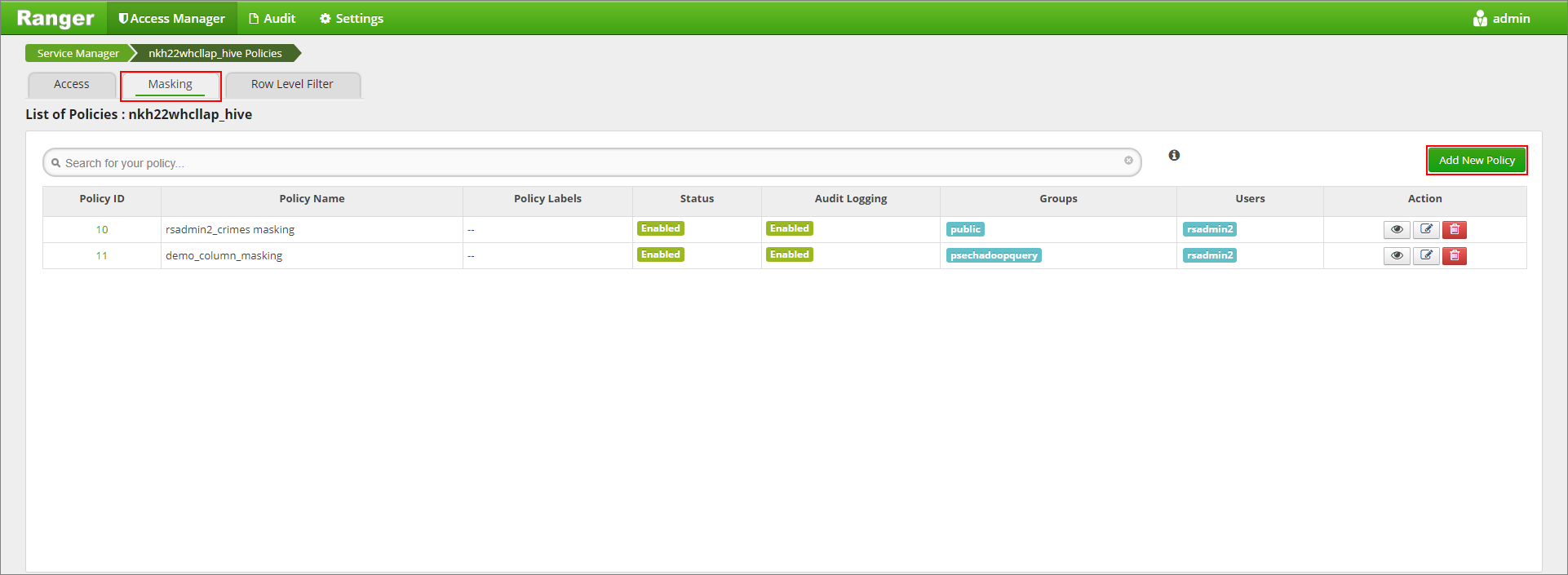
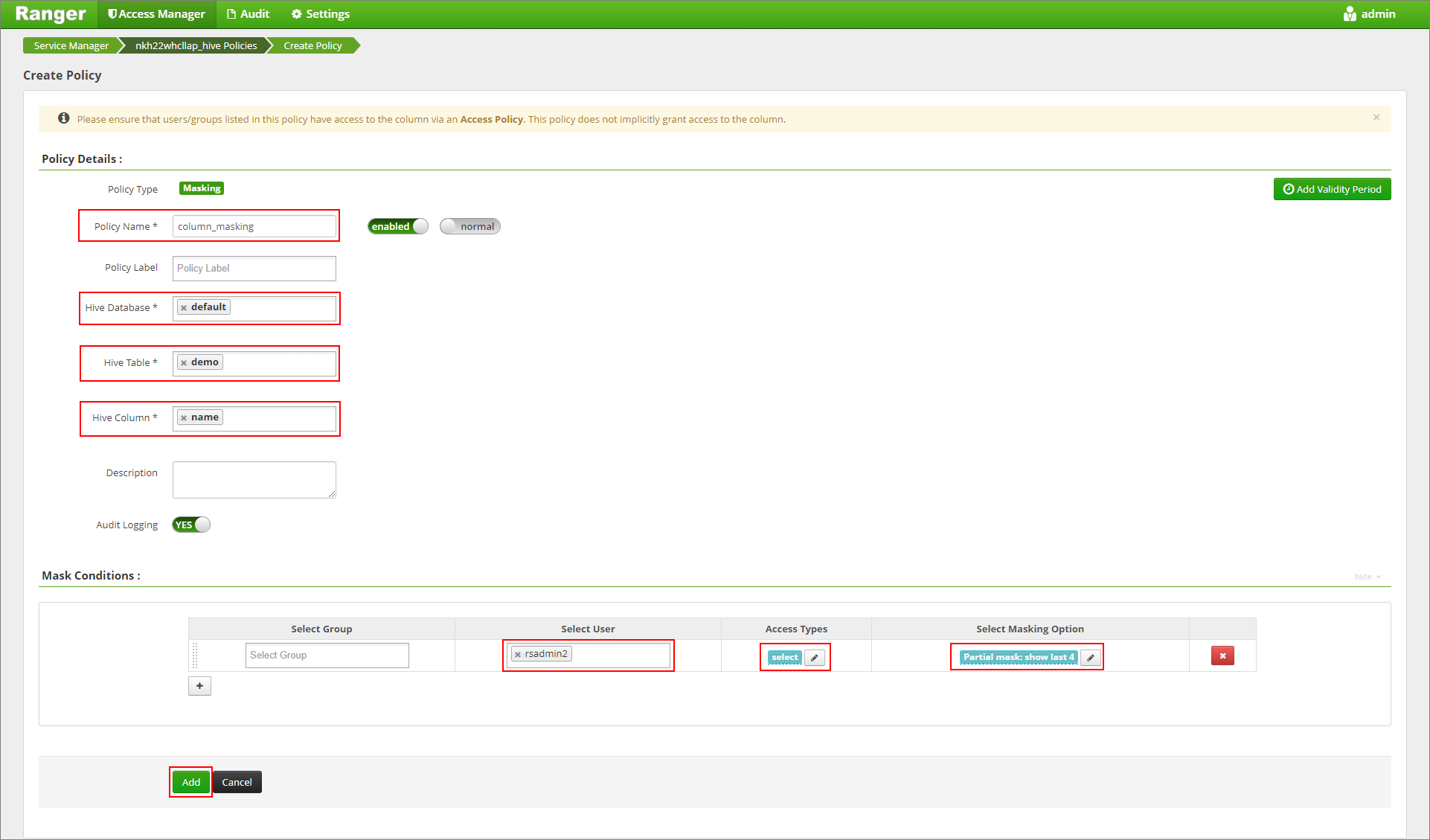
Proporcione el nombre que quiera para la directiva y seleccione las opciones siguientes. Para la base de datos: valor predeterminado; tabla de Hive: demostración; columna de Hive: nombre; usuario: rsadmin2; tipos de acceso: select (determinados) y, en el menú Select Masking Option (Seleccionar opción de enmascaramiento), Partial mask: show last 4 (Máscara parcial: mostrar últimos 4). Haga clic en Agregar.
Vuelva a consultar el contenido de la tabla. Después de aplicar la directiva de Ranger, solo podemos ver los cuatro últimos caracteres de la columna.
