Las operaciones Apache Spark admitidas por el Hive Warehouse Connector en Azure HDInsight
En este artículo se muestran las operaciones basadas en Spark que admite Hive Warehouse Connector (HWC). Todos los ejemplos que se muestran a continuación se ejecutarán a través del shell de Apache Spark.
Requisito previo
Complete los pasos de configuración de Hive Warehouse Connector.
Introducción
Para iniciar una sesión de spark-shell, realice los pasos siguientes:
Use el comando ssh para conectarse al clúster de Apache Spark. Modifique el comando siguiente: reemplace CLUSTERNAME por el nombre del clúster y, luego, escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDesde la sesión de ssh, ejecute el comando siguiente para anotar la versión
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorEdite el código siguiente con la versión
hive-warehouse-connector-assemblyidentificada anteriormente. Ejecute el siguiente comando para iniciar el shell de Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseDespués de iniciar spark-shell, se puede iniciar una instancia del conector de Hive Warehouse mediante los siguientes comandos:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Creación de DataFrames de Spark a partir de consultas de Hive
Los resultados de todas las consultas mediante la biblioteca HWC se devuelven como un elemento DataFrame. En los ejemplos siguientes se muestra cómo crear una consulta de subárbol.
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
Los resultados de la consulta son DataFrames de Spark, que se pueden usar con bibliotecas de Spark como MLIB y SparkSQL.
Escritura de DataFrames de Spark en tablas de Hive
Spark no admite la escritura en tablas ACID administradas de Hive de forma nativa. Pero con HWC puede escribir cualquier elemento DataFrame en una tabla de Hive. Puede ver como funciona esta funcionalidad en el ejemplo siguiente:
Cree una tabla denominada
sampletable_coloradoy especifique sus columnas con el comando siguiente:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()Filtre la tabla
hivesampletableen que la columnastatees igual aColorado. Esta consulta de Hive devuelve un elemento DataFrame de Spark y el resultado se guarda en la tabla de Hivesampletable_coloradomediante la funciónwrite.hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()Vea los resultados con el siguiente comando:
hive.table("sampletable_colorado").show()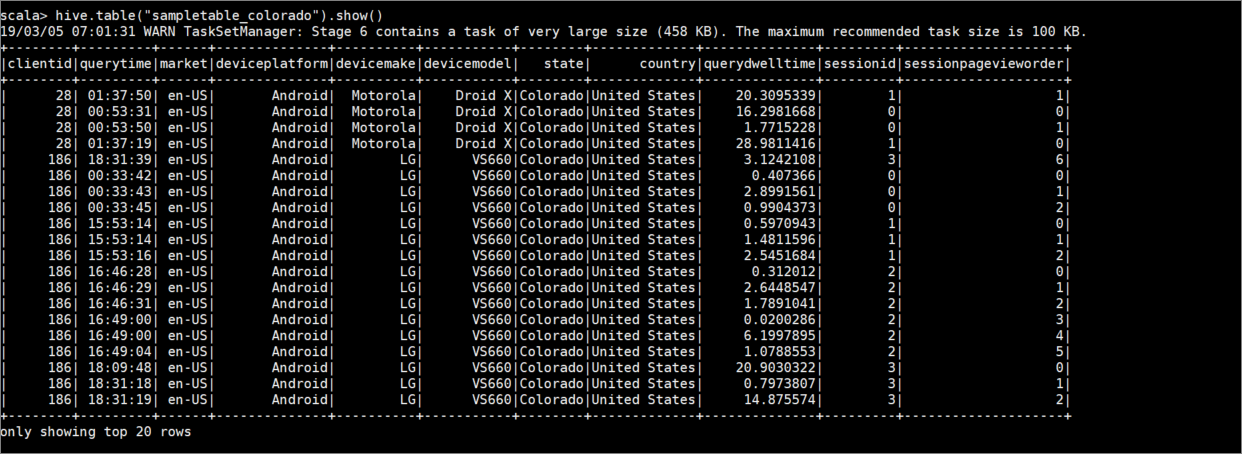
Escrituras de flujos estructurados
Al usar el conector de Hive Warehouse, puede emplear los flujos de Spark para escribir datos en las tablas de Hive.
Importante
No se admiten las escrituras de streaming estructurado en clústeres de Spark 4.0 con ESP habilitado.
En el ejemplo se ingieren datos de una secuencia de Spark en el puerto de localhost 9999 en una tabla de Hive. Hive Warehouse Connector.
Desde el shell de Spark abierto, inicie una secuencia de Spark con el siguiente comando:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()Genere datos para el flujo de Spark que creó. Para ello, siga estos pasos:
- Abra una segunda sesión de SSH en el mismo clúster de Spark.
- En el símbolo del sistema, escriba
nc -lk 9999. Este comando usa la utilidadnetcatpara enviar datos desde la línea de comandos al puerto especificado.
Vuelva a la primera sesión de SSH y cree una nueva tabla de Hive para contener los datos de streaming. En spark-shell, escriba el siguiente comando:
hive.createTable("stream_table").column("value","string").create()Después, escriba los datos de streaming en la tabla recién creada mediante el siguiente comando:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()Importante
Actualmente, las opciones
metastoreUriydatabasedeben establecerse de forma manual debido a un problema conocido en Apache Spark. Para obtener más información acerca de este problema, consulte SPARK-25460.Vuelva a la segunda sesión de SSH y escriba los valores siguientes:
foo HiveSpark barVuelva a la primera sesión de SSH y observe la breve actividad. Use el siguiente comando para ver los datos:
hive.table("stream_table").show()
Use Ctrl + C para detener netcat en la segunda sesión de SSH. Use :q para salir de spark-shell en la primera sesión de SSH.