Ejemplo de streaming de Apache Spark (DStream) con Apache Kafka en HDInsight
Aprenda a usar Apache Spark para transmitir datos dentro y fuera de Apache Kafka en HDInsight mediante DStreams. En este ejemplo se usa una instancia de Jupyter Notebook que se ejecuta en el clúster de Spark.
Nota:
Los pasos que se describen en este documento crean un grupo de recursos de Azure que contiene un clúster Spark de HDInsight y un clúster Kafka de HDInsight. Estos dos clústeres se encuentran en una instancia de Azure Virtual Network, lo que permite al clúster Spark comunicarse directamente con el clúster Kafka.
Cuando haya terminado los pasos indicados en este documento, no olvide eliminar los clústeres para evitar gastos innecesarios.
Importante
En este ejemplo se utiliza DStreams, que es una tecnología de streaming de Spark anterior. Para ver un ejemplo en el que se utilizan las características de streaming de Spark más recientes, consulte el documento Flujo estructurado de Apache Spark con Apache Kafka.
Creación de los clústeres
Apache Kafka en HDInsight no proporciona acceso a los agentes de Kafka a través de Internet. Cualquier comunicación con Kafka debe realizarse en la misma red virtual de Azure que utilizan los nodos del clúster Kafka. En este ejemplo, los clústeres Kafka y Spark se encuentran en una red virtual de Azure. En el diagrama siguiente, se muestra cómo fluye la comunicación entre los clústeres:
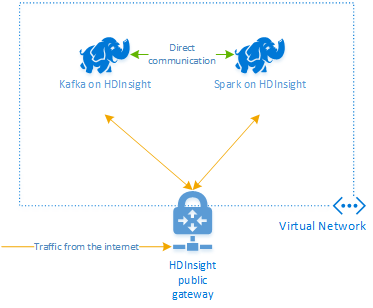
Nota:
Aunque Kafka tiene limitadas la comunicación en la red virtual, se puede acceder a otros servicios del clúster, como SSH y Ambari, a través de Internet. Para más información sobre los puertos públicos disponibles en HDInsight, consulte Puertos e identificadores URI usados en HDInsight.
Aunque puede crear manualmente la red virtual de Azure y los clústeres Kafka y Spark, resulta más sencillo utilizar una plantilla de Azure Resource Manager. Siga los pasos que se indican a continuación para implementar una red virtual de Azure y los clústeres Kafka y Spark en la suscripción de Azure.
Utilice el siguiente botón para iniciar sesión en Azure y abrir la plantilla en Azure Portal.

Advertencia
Para garantizar la disponibilidad de Kafka en HDInsight, el clúster debe contener al menos cuatro nodos de trabajo. Esta plantilla crea un clúster de Kafka que contiene cuatro nodos de trabajo.
Esta plantilla crea un clúster de HDInsight 4.0 para Kafka y Spark.
Utilice los datos siguientes para rellenar las entradas de la sección Implementación personalizada:
Propiedad Valor Resource group cree un grupo o seleccione uno existente. Location seleccione una ubicación geográfica próxima a usted. Nombre del clúster base este valor se utiliza como nombre base en los clústeres Spark y Kafka. Por ejemplo, si especifica hdistreaming, creará un clúster Spark denominado spark-hdistreaming y un clúster Kafka denominado kafka-hdistreaming. Cluster Login User Name (Nombre de usuario de inicio de sesión del clúster) nombre de usuario del administrador de los clústeres Spark y Kafka. Cluster Login Password (Contraseña de inicio de sesión del clúster) contraseña de usuario del administrador de los clústeres Spark y Kafka. SSH User Name (Nombre de usuario de SSH) usuario de SSH que se va a crear para los clústeres Spark y Kafka. SSH Password (Contraseña de SSH) contraseña del usuario de SSH para los clústeres Spark y Kafka. 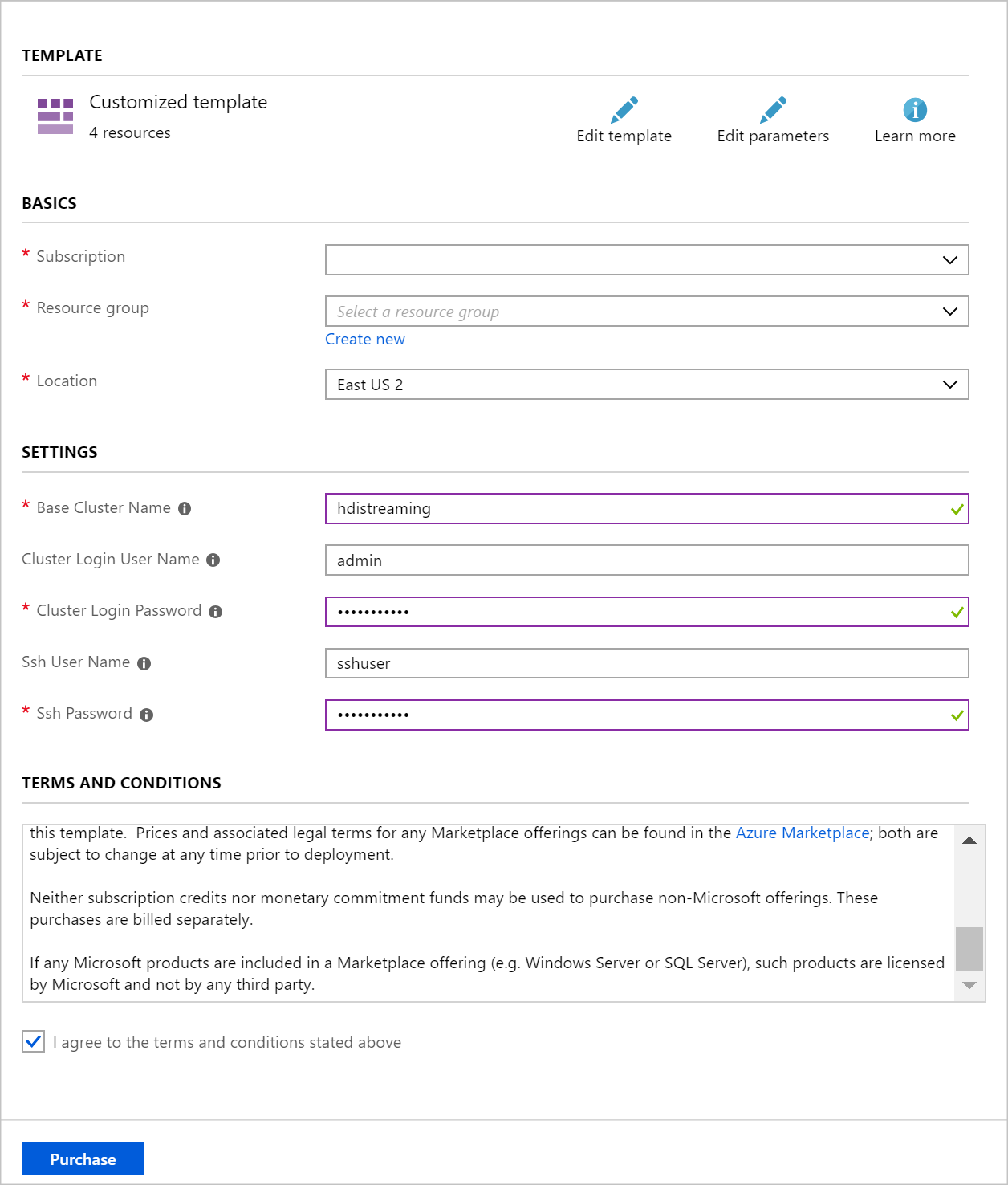
Consulte los Términos y condiciones y seleccione Acepto los términos y condiciones indicados anteriormente.
Por último, seleccione Adquirir. Se tarda aproximadamente 20 minutos en crear los clústeres.
Cuando se crean los recursos, aparece una página de resumen.
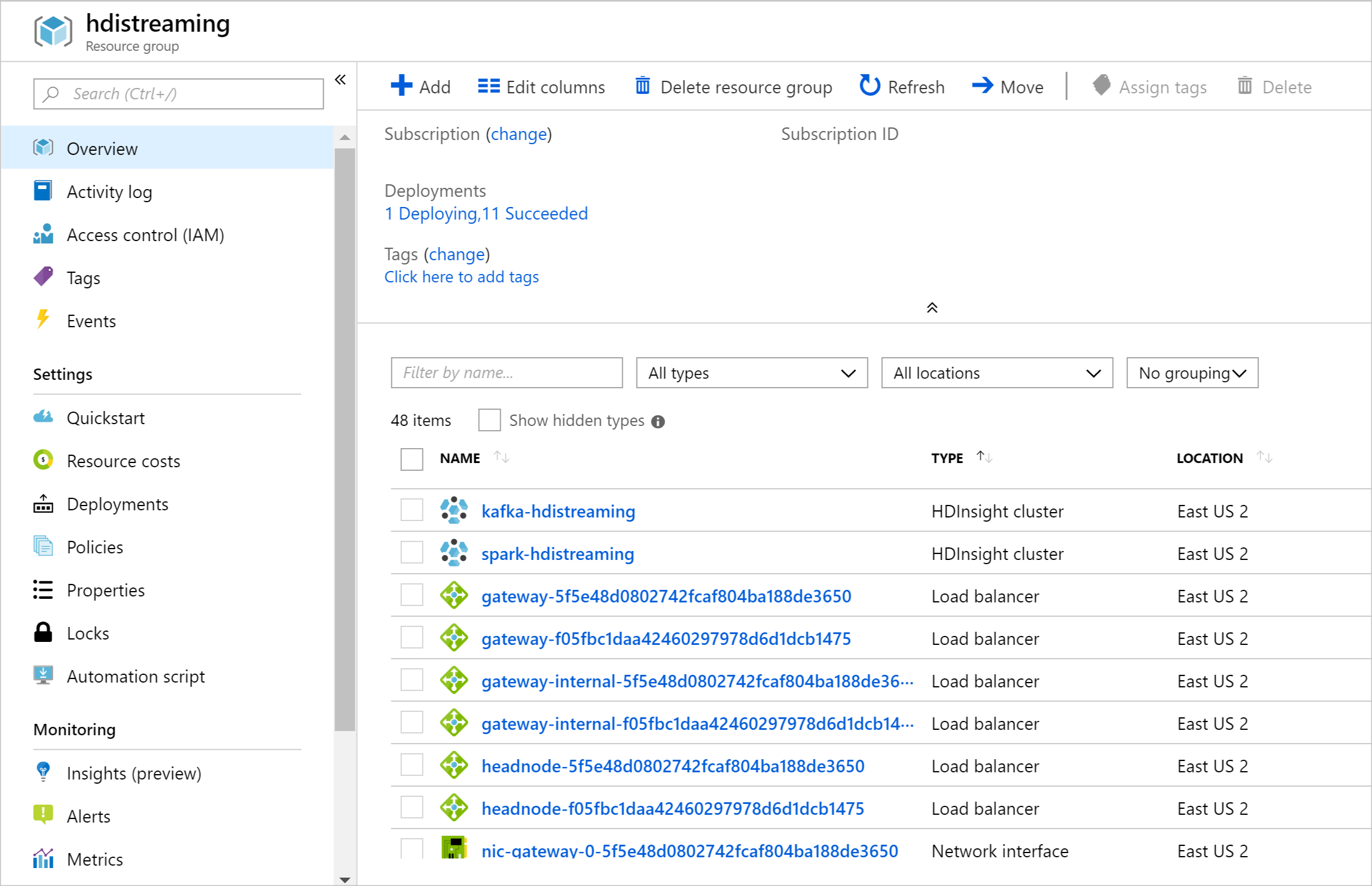
Importante
Observe que los nombres de los clústeres de HDInsight son spark-BASENAME y kafka-BASENAME, donde BASENAME es el nombre que indicó en la plantilla. Estos nombres se utilizarán más adelante al establecer la conexión con los clústeres.
Usar los blocs de notas
El código para el ejemplo descrito en este documento está disponible en https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Eliminación del clúster
Advertencia
La facturación de los clústeres de HDInsight se prorratea por minuto, tanto si se usan como si no. Por consiguiente, asegúrese de eliminar el clúster cuando termine de usarlo. Consulte Eliminación de un clúster de HDInsight.
Como el procedimiento descrito en este documento crea los dos clústeres en el mismo grupo de recursos de Azure, puede eliminar el grupo de recursos de Azure Portal. Al eliminar el grupo, se eliminan también todos los recursos creados con el procedimiento descrito en este documento, la red virtual de Azure Virtual Network y la cuenta de almacenamiento que utilizan los clústeres.
Pasos siguientes
En este ejemplo ha aprendido a usar Spark para leer y escribir en Kafka. Utilice los vínculos siguientes para conocer otras formas de trabajar con Kafka:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de