Análisis de registros de telemetría de Application Insights con Apache Spark en HDInsight
Aprenda a usar Apache Spark en HDInsight para analizar datos de telemetría de Application Insights.
Application Insights de Visual Studio es un servicio de análisis que supervisa sus aplicaciones web. Los datos de telemetría que Application Insights genera se pueden exportar a Azure Storage. Una vez que los datos se encuentren en Azure Storage, se puede usar HDInsight para analizarlos.
Una aplicación configurada para usar Application Insights.
Experiencia en la creación de un clúster de HDInsight basado en Linux. Para más información, consulte el artículo sobre la creación de un clúster de Apache Spark en HDInsight.
Un navegador web.
Se han utilizado los siguientes recursos para el desarrollo y pruebas de este documento:
Los datos de telemetría de Application Insights se han generado mediante una aplicación web Node.js configurada para usar Application Insights.
Se usó un clúster de Spark en HDInsight versión 3.5 basado en Linux para analizar los datos.
El siguiente diagrama muestra la arquitectura de servicio de este ejemplo:
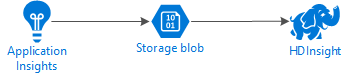
Application Insights pueden configurarse para exportar información de telemetría a blobs continuamente. Tras esto, HDInsight puede leer los datos almacenados en los blobs. Sin embargo, hay algunos requisitos que se deben seguir:
Ubicación: si la cuenta de almacenamiento y HDInsight se encuentran en distintas ubicaciones, puede aumentar la latencia. También se incrementa el costo, ya que los cargos de salida se aplican a datos que se transfieren entre regiones.
Advertencia
No se puede usar una cuenta de almacenamiento en una ubicación diferente a la de HDInsight.
Tipo de blob: HDInsight solo es compatible con blobs en bloques. Application Insights usa blobs en bloques de forma predeterminada, por lo que debería funcionar con HDInsight sin ninguna configuración adicional.
Para más información sobre cómo agregar almacenamiento a un clúster existente, vea el documento Adición de más cuentas de almacenamiento a HDInsight.
Application Insights proporciona información del modelo de datos de exportación para el formato de datos de telemetría exportados a blobs. Los pasos descritos en este documento usan Spark SQL para interactuar con los datos. Spark SQL puede generar automáticamente un esquema para la estructura de datos JSON registrado por Application Insights.
Siga los pasos de Configuración de exportación continua para configurar Application Insights de modo que la información de telemetría se exporte a un blob de Azure Storage.
Si va a crear un clúster de HDInsight, agregue la cuenta de almacenamiento durante la creación del clúster.
Para agregar la cuenta de Azure Storage a un clúster existente, use la información del documento Adición de más cuentas de almacenamiento a HDInsight.
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, donde CLUSTERNAME es el nombre del clúster.En la esquina superior derecha de la página de Jupyter, seleccione Nuevo y, a continuación, PySpark. Se abre una nueva pestaña en el explorador con un cuaderno de Jupyter Notebook basado en Python.
En el primer campo (llamado celda) de la página, escriba el texto siguiente:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Este código configura Spark para que pueda acceder de forma recursiva a la estructura de directorios de los datos de entrada. La telemetría de Application Insights se registra en una estructura de directorios similar a
/{telemetry type}/YYYY-MM-DD/{##}/.Use MAYÚS + INTRO para ejecutar el código. En el lado izquierdo de la celda, aparece un "*" entre corchetes para indicar que se está ejecutando el código de esta celda. Una vez finalizado, el "*" cambia a un número y se muestra una salida similar al siguiente texto debajo de la celda:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Se crea una nueva celda debajo de la primera. Escriba el texto siguiente en la nueva celda. Reemplace
CONTAINERySTORAGEACCOUNTpor el nombre de la cuenta de Azure Storage y el nombre del contenedor de blobs que contiene datos de Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use MAYÚS + INTRO para ejecutar esta celda. Verá un resultado similar al texto siguiente:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831La ruta de acceso de wasbs devuelta es la ubicación de los datos de telemetría de Application Insights. Cambie la línea
hdfs dfs -lsen la celda para usar la ruta de acceso de wasbs devuelta y luego use MAYÚS + INTRO para volver a ejecutar la celda. Esta vez, los resultados deberían mostrar los directorios que contienen datos de telemetría.Nota
Para el resto de los pasos descritos en esta sección, se ha usado el directorio
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. La estructura de sus directorios puede ser diferente.En la siguiente celda, escriba este código (reemplazando
WASB_PATHpor la ruta de acceso especificada en el paso anterior):jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Este código crea una trama de datos de los archivos JSON exportados por el proceso de exportación continua. Use MAYÚS + INTRO para ejecutar esta celda.
En la celda siguiente, escriba y ejecute lo siguiente para ver el esquema creado por Spark para los archivos JSON:
jsonData.printSchema()El esquema de cada tipo de telemetría es diferente. El siguiente ejemplo es el esquema que se genera para las solicitudes web (datos almacenados en el subdirectorio
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Para registrar la trama de datos como una tabla temporal y ejecutar una consulta de los datos, utilice lo siguiente:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Esta consulta devuelve la información de la ciudad de los 20 registros principales donde context.location.city no sea nulo.
Nota
La estructura de contexto está presente en toda la telemetría registrada por Application Insights. Es posible que el elemento city no se rellene en los registros. Utilice el esquema para identificar otros elementos que se puedan consultar y que puedan contener datos de los registros.
Esta consulta devuelve información similar al texto siguiente:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, donde CLUSTERNAME es el nombre del clúster.En la esquina superior derecha de la página de Jupyter, seleccione Nuevo y, después, Scala. Se abre una nueva pestaña en el explorador con un cuaderno de Jupyter Notebook basado en Scala.
En el primer campo (llamado celda) de la página, escriba el texto siguiente:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Este código configura Spark para que pueda acceder de forma recursiva a la estructura de directorios de los datos de entrada. La telemetría de Application Insights se registra en una estructura de directorios similar a
/{telemetry type}/YYYY-MM-DD/{##}/.Use MAYÚS + INTRO para ejecutar el código. En el lado izquierdo de la celda, aparece un "*" entre corchetes para indicar que se está ejecutando el código de esta celda. Una vez finalizado, el "*" cambia a un número y se muestra una salida similar al siguiente texto debajo de la celda:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Se crea una nueva celda debajo de la primera. Escriba el texto siguiente en la nueva celda. Reemplace
CONTAINERySTORAGEACCOUNTpor el nombre de la cuenta de Azure Storage y el nombre del contenedor de blobs que contiene registros de Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use MAYÚS + INTRO para ejecutar esta celda. Verá un resultado similar al texto siguiente:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831La ruta de acceso de wasbs devuelta es la ubicación de los datos de telemetría de Application Insights. Cambie la línea
hdfs dfs -lsen la celda para usar la ruta de acceso de wasbs devuelta y luego use MAYÚS + INTRO para volver a ejecutar la celda. Esta vez, los resultados deberían mostrar los directorios que contienen datos de telemetría.Nota
Para el resto de los pasos descritos en esta sección, se ha usado el directorio
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Este directorio podría no existir, a menos que los datos de telemetría sean de una aplicación web.En la siguiente celda, escriba este código (reemplazando
WASB\_PATHpor la ruta de acceso especificada en el paso anterior):var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Este código crea una trama de datos de los archivos JSON exportados por el proceso de exportación continua. Use MAYÚS + INTRO para ejecutar esta celda.
En la celda siguiente, escriba y ejecute lo siguiente para ver el esquema creado por Spark para los archivos JSON:
jsonData.printSchemaEl esquema de cada tipo de telemetría es diferente. El siguiente ejemplo es el esquema que se genera para las solicitudes web (datos almacenados en el subdirectorio
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Para registrar la trama de datos como una tabla temporal y ejecutar una consulta de los datos, utilice lo siguiente:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Esta consulta devuelve la información de la ciudad de los 20 registros principales donde context.location.city no sea nulo.
Nota
La estructura de contexto está presente en toda la telemetría registrada por Application Insights. Es posible que el elemento city no se rellene en los registros. Utilice el esquema para identificar otros elementos que se puedan consultar y que puedan contener datos de los registros.
Esta consulta devuelve información similar al texto siguiente:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Para más ejemplos de uso de Apache Spark para trabajar con datos y servicios de Azure, consulte los siguientes documentos:
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: Uso de Spark en HDInsight para analizar la temperatura de un edificio mediante datos de HVAC
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Para obtener información sobre cómo crear y ejecutar aplicaciones de Spark, consulte los siguientes documentos: