Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, obtendrá información sobre cómo administrar las dependencias de las aplicaciones Spark que se ejecutan en HDInsight. Abarcamos Scala y PySpark en el ámbito de clúster y aplicación Spark.
Use los vínculos rápidos para saltar a la sección correspondiente en función de su caso de usuario:
- Configuración de dependencias JAR de trabajos de Spark mediante Jupyter Notebook
- Configuración de dependencias JAR de trabajos de Spark mediante Azure Toolkit for IntelliJ
- Configuración de dependencias JAR para el clúster Spark
- Administración segura de dependencias de JAR
- Configuración de paquetes Python de trabajos de Spark mediante Jupyter Notebook
- Administración segura de paquetes Python para el clúster Spark
Bibliotecas JAR para un trabajo de Spark
Uso de Jupyter Notebook
Cuando se inicia una sesión de Spark en Jupyter Notebook en el kernel de Spark para Scala, puede configurar paquetes desde:
- El repositorio Maven o los paquetes para obtener paquetes aportados por la comunidad en Spark Packages.
- Archivos JAR en el almacenamiento principal del clúster.
Puede usar la instrucción mágica %%configure para configurar el cuaderno para usar un paquete externo. En los cuadernos que utilizan paquetes externos, asegúrese de invocar la instrucción mágica %%configure en la primera celda de código. Esto garantiza que el kernel se configure para utilizar el paquete antes de iniciar la sesión.
Importante
Si se olvida de configurar el kernel en la primera celda, puede utilizar el parámetro %%configure con el parámetro -f, pero ello reiniciará la sesión y se perderá todo el trabajo.
Ejemplo de paquetes del repositorio de Maven o Spark Packages
Tras encontrar el paquete del repositorio Maven, recopile los valores de GroupId, ArtifactId y Version. Concatene los tres valores separados por dos puntos ( : ).
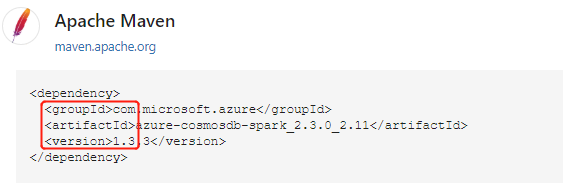
Asegúrese de que los valores recopilados coinciden con el clúster. En este caso, estamos usando el paquete de conector de Spark de Azure Cosmos DB para Scala 2.11 y Spark 2.3 para el clúster Spark de HDInsight 3.6. Si no está seguro, ejecute scala.util.Properties.versionString en la celda de código del kernel de Spark para consultar la versión de Scala del clúster. Ejecute sc.version para consultar la versión de Spark del clúster.
%%configure { "conf": {"spark.jars.packages": "com.microsoft.azure:azure-cosmosdb-spark_2.3.0_2.11:1.3.3" }}
Ejemplo de archivos JAR almacenados en el almacenamiento principal
Use el esquema de URI para los archivos JAR en el almacenamiento principal de sus clústeres. Sería wasb:// para Azure Storage, abfs:// para Azure Data Lake Storage Gen2 o adl:// para Azure Data Lake Storage Gen1. Si la transferencia segura está habilitada para Azure Storage o Data Lake Storage Gen2, el URI será wasbs:// o abfss://. Consulte Transferencia segura.
Use una lista separada por comas de rutas de acceso de archivos JAR para varios archivos JAR; se permiten los patrones globales. Los archivos JAR incluyen en las rutas de clases de controlador y ejecutor.
%%configure { "conf": {"spark.jars": "wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/azure-cosmosdb-spark_2.3.0_2.11-1.3.3.jar" }}
Después de configurar paquetes externos, puede ejecutar la importación en la celda de código para comprobar si los paquetes se han colocado correctamente.
import com.microsoft.azure.cosmosdb.spark._
Uso de Azure Toolkit for IntelliJ
El complemento Azure Toolkit for IntelliJ proporciona una experiencia de interfaz de usuario para enviar la aplicación Spark Scala a un clúster de HDInsight. Proporciona las propiedades Referenced Jars y Referenced Files para configurar las rutas de acceso de las bibliotecas JAR al enviar la aplicación Spark. Consulte más detalles sobre cómo usar el complemento Azure Toolkit for IntelliJ para HDInsight.
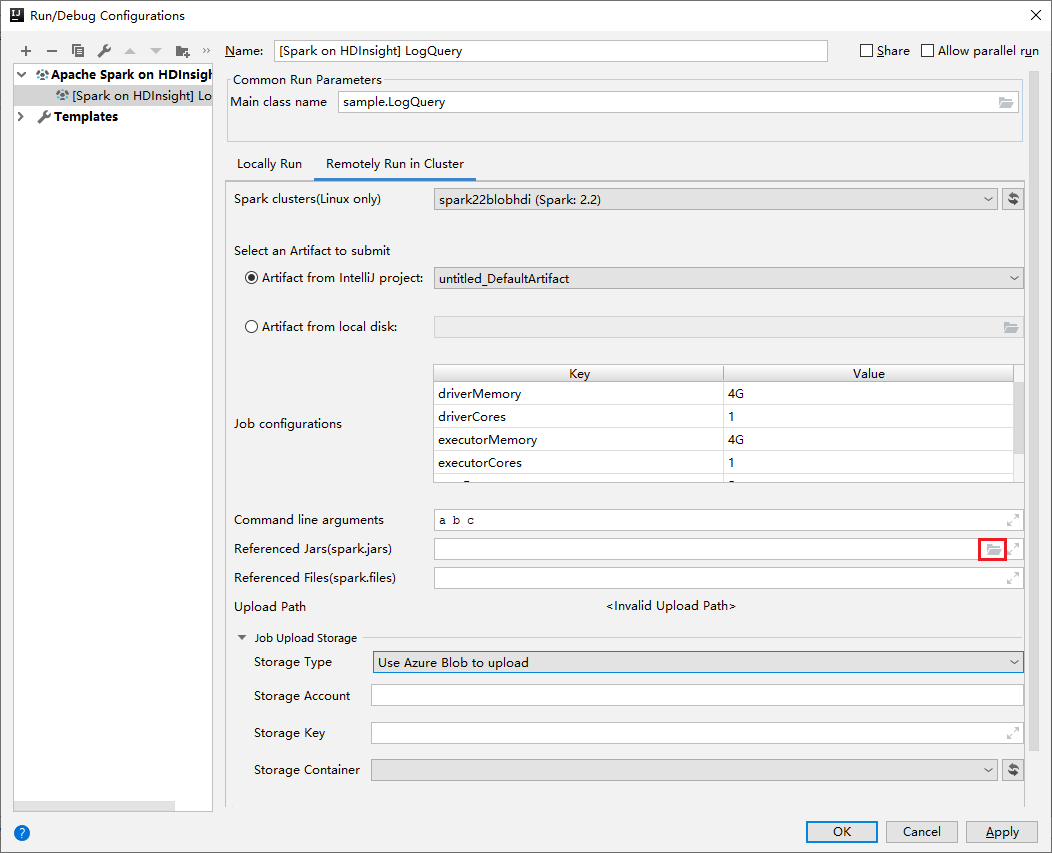
Bibliotecas JAR para clúster
En algunos casos, se recomienda configurar las dependencias JAR en el nivel de clúster para que todas las aplicaciones se puedan configurar con las mismas dependencias de manera predeterminada. El enfoque consiste en agregar las rutas de acceso de archivos JAR a la ruta de acceso de clase del controlador y ejecutor de Spark.
Ejecute los ejemplos de acciones de script para copiar los archivos JAR del almacenamiento principal
wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*al sistema de archivos local/usr/libs/sparklibsdel clúster. Este paso es necesario cuando Linux usa:para separar la lista de rutas de acceso de clase, pero HDInsight solo admite las rutas de acceso de almacenamiento con un esquema parecido awasb://. La ruta de acceso de almacenamiento remoto no funcionará correctamente si se agrega directamente a la ruta de acceso de clase.sudo mkdir -p /usr/libs/sparklibs sudo hadoop fs -copyToLocal wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*.* /usr/libs/sparklibsCambie la configuración del servicio Spark de Ambari para actualizar la ruta de acceso de clase. Vaya a Ambari > Spark > Configuraciones > Valores predeterminados de Spark2 personalizados. Agregue la propiedad como se indica a continuación. Use
:para separar las rutas de acceso si necesita agregar más de una. Se permiten los patrones globales.spark.driver.extraClassPath=/usr/libs/sparklibs/* spark.executor.extraClassPath=/usr/libs/sparklibs/*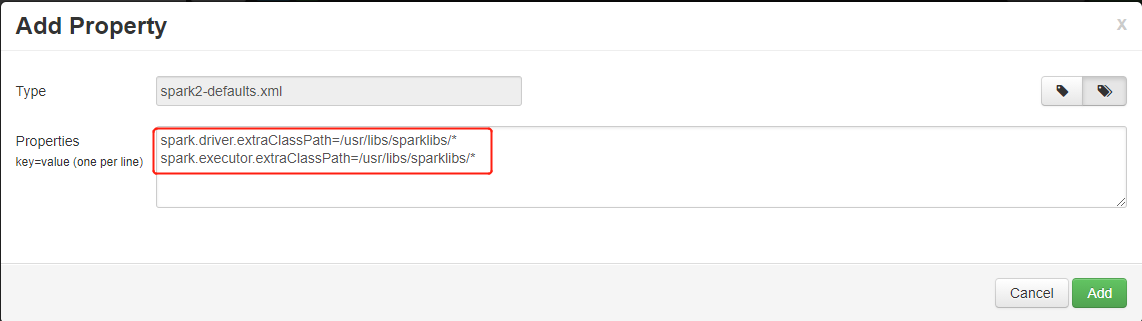 ult config" border="true":::
ult config" border="true":::Guarde las configuraciones modificadas y reinicie los servicios afectados.
 ted services" border="true":::
ted services" border="true":::
Puede automatizar los pasos con acciones de script. La acción de script para agregar bibliotecas personalizadas de Hive es una buena referencia. Al cambiar las configuraciones del servicio Spark, asegúrese de usar las API de Ambari en lugar de modificar directamente los archivos de configuración.
Administración segura de dependencias de JAR
El clúster de HDInsight tiene dependencias JAR integradas y de vez en cuando se realizan actualizaciones para estas versiones de JAR. Para evitar conflictos de versión entre los archivos JAR integrados y los archivos JAR que se proporcionan como referencia, considere la posibilidad de sombrear las dependencias de la aplicación.
Paquetes Python para un trabajo de Spark
Uso de Jupyter Notebook
El kernel de PySpark de Jupyter Notebook para HDInsight no admite la instalación de paquetes Python directamente desde el repositorio de paquetes de PyPi o Anaconda. Si tiene dependencias .zip, .egg o .py y quiere hacer referencia a ellas para una sesión de Spark, siga estos pasos:
Ejecute acciones de script de ejemplo para copiar archivos
.zip,.eggo.pydel almacenamiento principalwasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*al sistema de archivos local del clúster/usr/libs/pylibs. Este paso es necesario cuando Linux usa:para separar la lista de rutas de acceso de búsqueda, pero HDInsight solo admite las rutas de acceso de almacenamiento con un esquema parecido awasb://. La ruta de acceso de almacenamiento remoto no funcionará correctamente cuando se usesys.path.insert.sudo mkdir -p /usr/libs/pylibs sudo hadoop fs -copyToLocal wasb://mycontainer@mystorageaccount.blob.core.windows.net/libs/*.* /usr/libs/pylibsEn el cuaderno, ejecute el siguiente código en una celda de código con el kernel de PySpark:
import sys sys.path.insert(0, "/usr/libs/pylibs/pypackage.zip")Ejecute
importpara comprobar si los paquetes se incluyeron correctamente.
Paquetes de Python para el clúster
Puede instalar paquetes de Python desde Anaconda en el clúster al usar el comando Conda a través de acciones de script. Los paquetes instalados se encuentran en el nivel de clúster y se aplican a todas las aplicaciones.
El clúster de Spark de HDInsight tiene dos instalaciones de Python integradas, Anaconda Python 2.7 y Anaconda Python 3.5. Para obtener más información sobre la configuración predeterminada de Python para los servicios y sobre cómo instalar de forma segura paquetes de Python externos sin interrumpir el clúster, consulte más detalles en Administración segura de las dependencias de Python para el clúster.