Configurar flujos de datos en operaciones de Azure IoT
Importante
Versión preliminar de operaciones de Azure IoT: habilitada por Azure Arc está actualmente en versión preliminar. No se debería usar este software en versión preliminar en entornos de producción.
Tendrá que implementar una nueva instalación de Operaciones de IoT de Azure cuando esté disponible una versión disponible con carácter general. No podrá actualizar una instalación de versión preliminar.
Para conocer los términos legales que se aplican a las características de Azure que se encuentran en la versión beta, en versión preliminar o que todavía no se han publicado para que estén disponibles con carácter general, consulte los Términos de uso complementarios para las versiones preliminares de Microsoft Azure.
Un flujo de datos es la ruta de acceso que los datos toman del origen al destino con transformaciones opcionales. Puede configurar el flujo de datos creando un recurso personalizado del flujo de datos o utilizando el portal de Azure IoT Operations Studio. Un flujo de datos se compone de tres partes: el origen, la transformación y el destino.

Para definir el origen y el destino, debe configurar los puntos de conexión de flujo de datos. La transformación es opcional y puede incluir operaciones como enriquecer los datos, filtrar los datos y asignar los datos a otro campo.
Importante
Cada flujo de datos debe tener el punto de conexión predeterminado del corredor MQTT local de Operaciones de IoT de Azure como origen o destino.
Puede usar la experiencia de operaciones en Operaciones de IoT de Azure para crear un flujo de datos. La experiencia de operaciones proporciona una interfaz visual para configurar el flujo de datos. También puede usar Bicep para crear un flujo de datos mediante un archivo de plantilla de Bicep o usar Kubernetes para crear un flujo de datos mediante un archivo YAML.
Siga leyendo para aprender a configurar el origen, la transformación y el destino.
Requisitos previos
Puede implementar flujos de datos en cuanto tenga una instancia de Operaciones de IoT de Azure (versión preliminar) mediante el perfil y el punto de conexión predeterminados del flujo de datos. Sin embargo, es posible que quiera configurar perfiles y puntos de conexión de flujo de datos para personalizar el flujo de datos.
Perfil de flujo de datos
El perfil de flujo de datos especifica el número de instancias de los flujos de datos que se van a usar. Si no necesita varios grupos de flujos de datos con diferentes configuraciones de escalado, puede usar el perfil de flujo de datos predeterminado. Para obtener información sobre cómo configurar un perfil de flujo de datos, consulte Configurar perfiles de flujo de datos.
Puntos de conexión de flujo de datos
Los puntos de conexión de flujo de datos son necesarios para configurar el origen y el destino del flujo de datos. Para empezar a trabajar rápidamente, puede usar el punto de conexión de flujo de datos predeterminado para el corredor MQTT local. También puede crear otros tipos de puntos de conexión de flujo de datos, como Kafka, Event Hubs o Azure Data Lake Storage. Para obtener información sobre cómo configurar cada tipo de punto de conexión de flujo de datos, consulte Configuración de puntos de conexión de flujo de datos.
Introducción
Una vez que tenga los requisitos previos, puede empezar a crear un flujo de datos.
Para crear un flujo de datos en la experiencia de operaciones, seleccione Flujo de datos>Crear flujo de datos. A continuación, verá la página donde puede configurar el origen, la transformación y el destino del flujo de datos.
Revise las secciones siguientes para obtener información sobre cómo configurar los tipos de operación del flujo de datos.
Source
Para configurar un origen para el flujo de datos, especifique la referencia del punto de conexión y una lista de orígenes de datos para el punto de conexión.
Usar el recurso como origen
Puede usar un recurso como origen para el flujo de datos. Usar un recurso como origen solo está disponible en la experiencia de operaciones.
En Detalles del origen, seleccione Recurso.
Seleccione el recurso que desea usar como punto de conexión de origen.
Seleccione Continuar.
Se muestra una lista de puntos de datos para el recurso seleccionado.
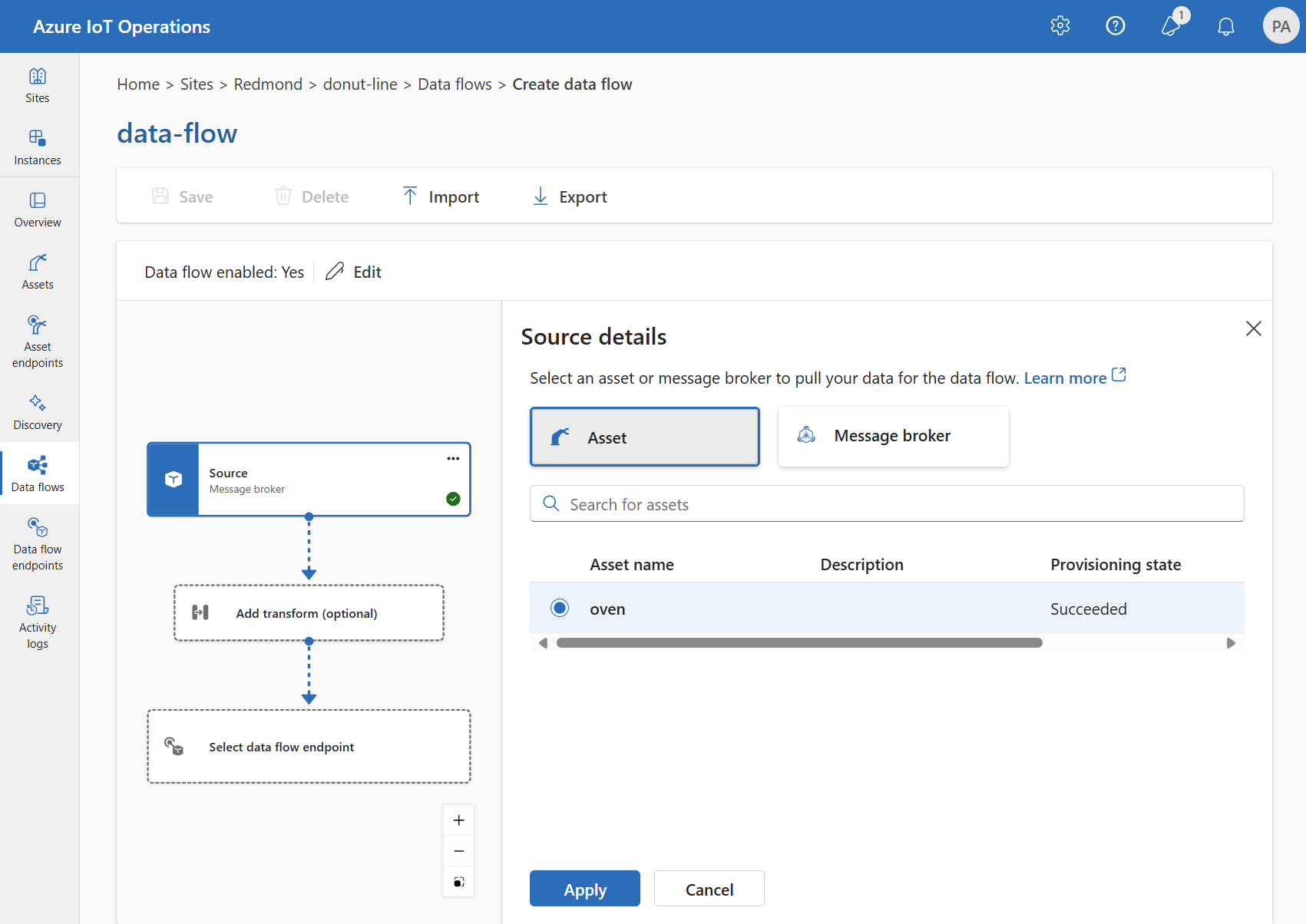
Seleccione Aplicar para usar el recurso como punto de conexión de origen.
Cuando se usa un recurso como origen, la definición del recurso se usa para inferir el esquema del flujo de datos. La definición del recurso incluye el esquema de los puntos de datos del recurso. Para más información, consulte Administrar configuraciones de recursos de forma remota.
Una vez configurados, los datos del recurso alcanzaron el flujo de datos a través del corredor MQTT local. Por lo tanto, cuando se usa un recurso como origen, el flujo de datos usa el punto de conexión predeterminado del corredor MQTT local como origen en realidad.
Usar punto de conexión MQTT predeterminado como origen
En Detalles del origen, seleccione MQTT.
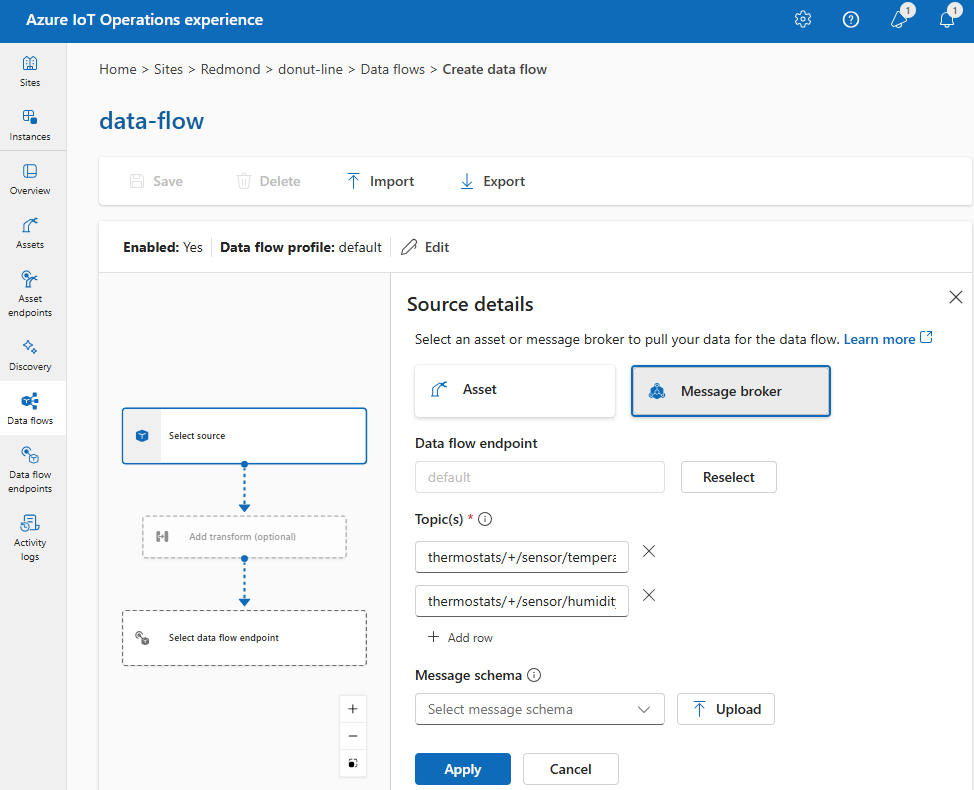
Escriba la siguiente configuración para el origen MQTT:
Configuración Descripción Tema de MQTT Filtro de tema MQTT al que suscribirse para los mensajes entrantes. Consulte Configurar temas MQTT o Kafka. Esquema de los mensajes Esquema que se va a usar para deserializar los mensajes entrantes. Consulte Especificación del esquema para deserializar datos. Seleccione Aplicar.
Si el punto de conexión predeterminado no se usa como origen, debe usarse como destino. Para más información al respecto, consulte Los flujos de datos deben usar el punto de conexión del corredor MQTT local.
Usar punto de conexión de flujo de datos MQTT o Kafka personalizado como origen
Si creó un punto de conexión de flujo de datos MQTT o Kafka personalizado (por ejemplo, para usarlo con Event Grid o Event Hubs), puede usarlo como origen para el flujo de datos. Recuerde que los puntos de conexión de tipo de almacenamiento, como Data Lake o Fabric OneLake, no se pueden usar como origen.
Para configurar, use YAML o Bicep de Kubernetes. Reemplace los valores del marcador de posición por el nombre y los temas del punto de conexión personalizados.
Actualmente no se admite el uso de un punto de conexión MQTT o Kafka personalizado como origen en la experiencia de operaciones.
Configurar orígenes de datos (temas MQTT o Kafka)
Puede especificar varios temas de MQTT o Kafka en un origen sin necesidad de modificar la configuración del punto de conexión del flujo de datos. Esta flexibilidad significa que el mismo punto de conexión se puede reutilizar en varios flujos de datos, incluso si los temas varían. Para obtener más información, consulte Reutilizar puntos de conexión de flujo de datos.
Temas de MQTT
Cuando el origen es un punto de conexión MQTT (Event Grid incluido), puede usar el filtro de tema MQTT para suscribirse a los mensajes entrantes. El filtro de tema puede incluir caracteres comodín para suscribirse a varios temas. Por ejemplo, thermostats/+/telemetry/temperature/# se suscribe a todos los mensajes de telemetría de temperatura de termostatos. Para configurar los filtros del tema MQTT:
En los Detalles del origen del flujo de datos de experiencia de operaciones, seleccione MQTT y, a continuación, use el campo Tema MQTT para especificar el filtro de tema MQTT al que suscribirse para los mensajes entrantes.
Nota:
Solo se puede especificar un filtro de tema MQTT en la experiencia de operaciones. Para usar varios filtros de temas MQTT, use Bicep o Kubernetes.
Suscripciones compartidas
Para usar suscripciones compartidas con orígenes MQTT, puede especificar el tema de suscripción compartida en forma de $shared/<GROUP_NAME>/<TOPIC_FILTER>.
En los Detalles del origen del flujo de datos de la experiencia de operaciones, seleccione MQTT y use el campo Tema MQTT para especificar el tema y el grupo de suscripciones compartidos.
Si el recuento de instancias del perfil de flujo de datos es mayor que 1, la suscripción compartida se habilita automáticamente para todos los flujos de datos que usan el origen MQTT. En este caso, se agrega el prefijo $shared y el nombre del grupo de suscripciones compartido se genera automáticamente. Por ejemplo, si tiene un perfil de flujo de datos con un recuento de instancias de 3 y el flujo de datos usa un punto de conexión MQTT como origen configurado con los temas topic1 y topic2, se convierten automáticamente en suscripciones compartidas como $shared/<GENERATED_GROUP_NAME>/topic1 y $shared/<GENERATED_GROUP_NAME>/topic2. Si desea usar un identificador diferente del grupo de suscripciones compartido, puede invalidarlo en el tema, como $shared/mygroup/topic1.
Importante
Los flujos de datos que requieren una suscripción compartida cuando el recuento de instancias es mayor que 1 son importantes cuando se usa el corredor MQTT de Event Grid como origen, ya que no admite suscripciones compartidas. Para evitar que falten mensajes, establezca el recuento de instancias del perfil de flujo de datos en 1 al usar el corredor MQTT de Event Grid como origen. Es cuando el flujo de datos es el suscriptor y recibe mensajes desde la nube.
Temas de Kafka
Cuando el origen es un punto de conexión Kafka (Event Hubs incluido), especifique los temas individuales de kafka a los que suscribirse para los mensajes entrantes. No se admiten caracteres comodín, por lo que debe especificar cada tema estáticamente.
Nota:
Cuando se usa Event Hubs a través del punto de conexión Kafka, cada centro de eventos individual dentro del espacio de nombres es el tema de Kafka. Por ejemplo, si tiene un espacio de nombres de Event Hubs con dos centros de eventos, thermostats y humidifiers, puede especificar cada centro de eventos como tema de Kafka.
Para configurar los temas de Kafka:
Actualmente, no se admite el uso de un punto de conexión de Kafka como origen en la experiencia de operaciones.
Especificación del esquema para deserializar datos
Si los datos de origen tienen campos o campos opcionales con tipos diferentes, especifique un esquema de deserialización para garantizar la coherencia. Por ejemplo, los datos pueden tener campos que no están presentes en todos los mensajes. Sin el esquema, la transformación no puede controlar estos campos, ya que tendría valores vacíos. Con el esquema, puede especificar valores predeterminados o omitir los campos.
Especificar el esquema solo es relevante cuando se usa el origen MQTT o Kafka. Si el origen es un recurso, el esquema se deduce automáticamente de la definición del recurso.
Para configurar el esquema usado para deserializar los mensajes entrantes de un origen:
En los Detalles del origen del flujo de datos de la experiencia de operaciones, seleccione MQTT y use el campo Esquema de mensaje para especificar el esquema. Puede usar el botón Cargar para cargar primero un archivo de esquema. Para más información, consulte Comprender los esquemas del mensaje.
Transformación
La operación de transformación es donde puede transformar los datos del origen antes de enviarlos al destino. Las transformaciones son opcionales. Si no necesita realizar cambios en los datos, no incluya la operación de transformación en la configuración del flujo de datos. Varias transformaciones se encadenan en fases independientemente del orden en que se especifiquen en la configuración. El orden de las fases siempre es:
- Enriquecer, Cambiar nombre o agregar una Propiedad nueva: agregue datos adicionales a los datos de origen dados un conjunto de datos y una condición para que coincidan.
- Filtrar: filtre los datos en función de una condición.
- Asignar o Procesar: mover datos de un campo a otro con una conversión opcional.
En la experiencia de operaciones, seleccione Flujo de datos>Agregar transformación (opcional).
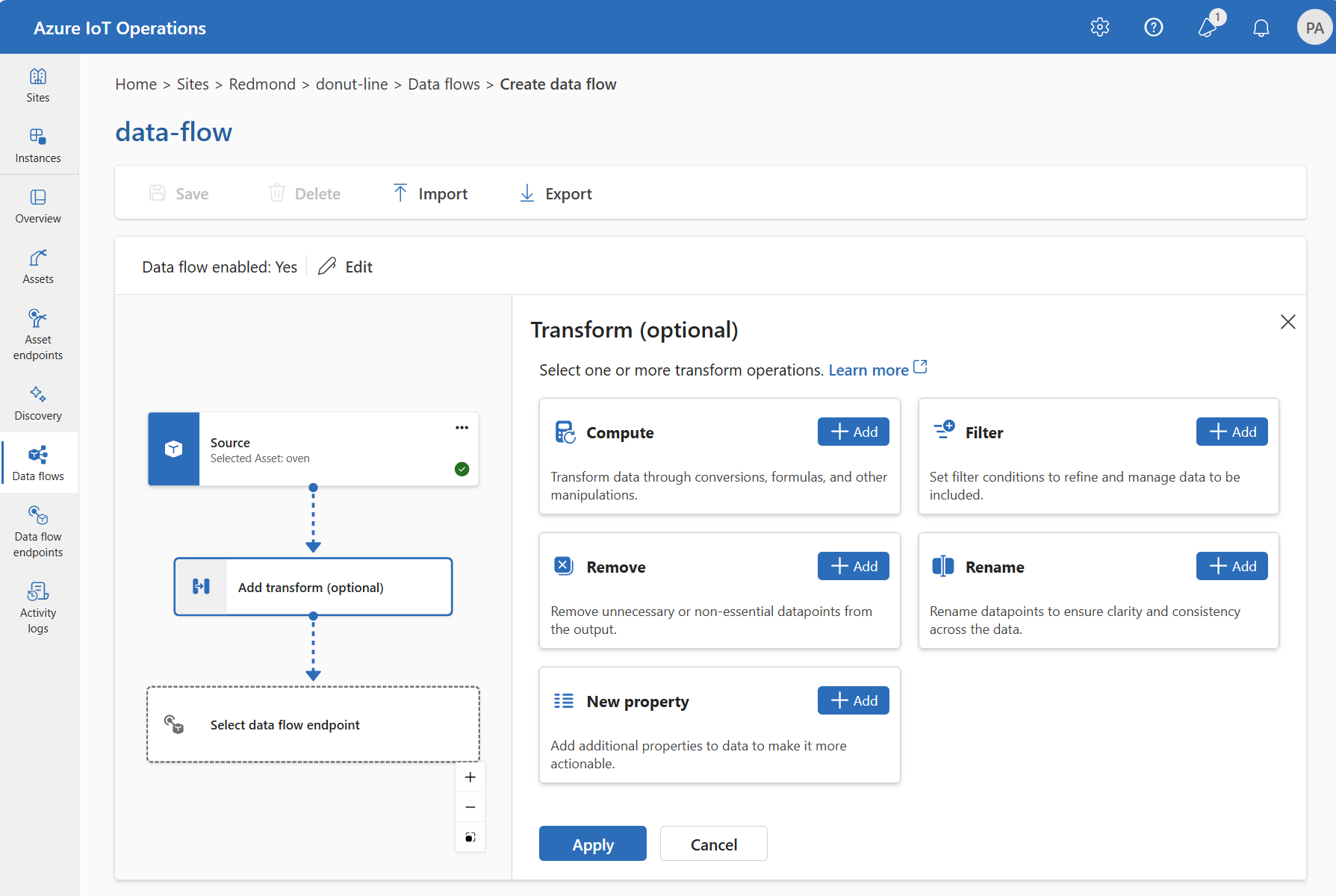
Enriquecimiento: adición de datos de referencia
Para enriquecer los datos, puede usar el conjunto de datos de referencia en el almacén de estado distribuido (DSS) de Operaciones de IoT de Azure. El conjunto de datos se usa para agregar datos adicionales a los datos de origen en función de una condición. La condición se especifica como un campo en los datos de origen que coincide con un campo del conjunto de datos.
Puede cargar datos de muestra en el DSS usando la herramienta de configuración de DSS de muestra. Los nombres de clave del almacén de estado distribuido corresponden a un conjunto de datos en la configuración del flujo de datos.
En la experiencia de operaciones, actualmente se admite la fase de Enriquecer mediante las transformaciones Cambiar nombre y Nueva propiedad.
En la experiencia de operaciones, seleccione un flujo de datos y luego Agregar transformación (opcional).
Elija las transformaciones Cambiar nombre o Nueva propiedad y, a continuación, seleccione Agregar.

Si el conjunto de datos tiene un registro con el campo asset, similar a:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Los datos del origen con el campo deviceId que coincide con thermostat1 tienen los campos location y manufacturer disponibles en las fases de filtro y mapa.
Para más información sobre la sintaxis de las condiciones, consulte Enriquecimiento de datos mediante flujos de datos y Conversión de datos mediante flujos de datos.
Filtro: Filtrar datos en función de una condición
Para filtrar los datos en una condición, puede usar la fase filter. La condición se especifica como un campo en los datos de origen que coincide con un valor.
En Transformar (opcional), seleccione Filtrar>Agregar.
Elija los puntos de datos que se van a incluir en el conjunto de datos.
Agregue una condición de filtro y una descripción.
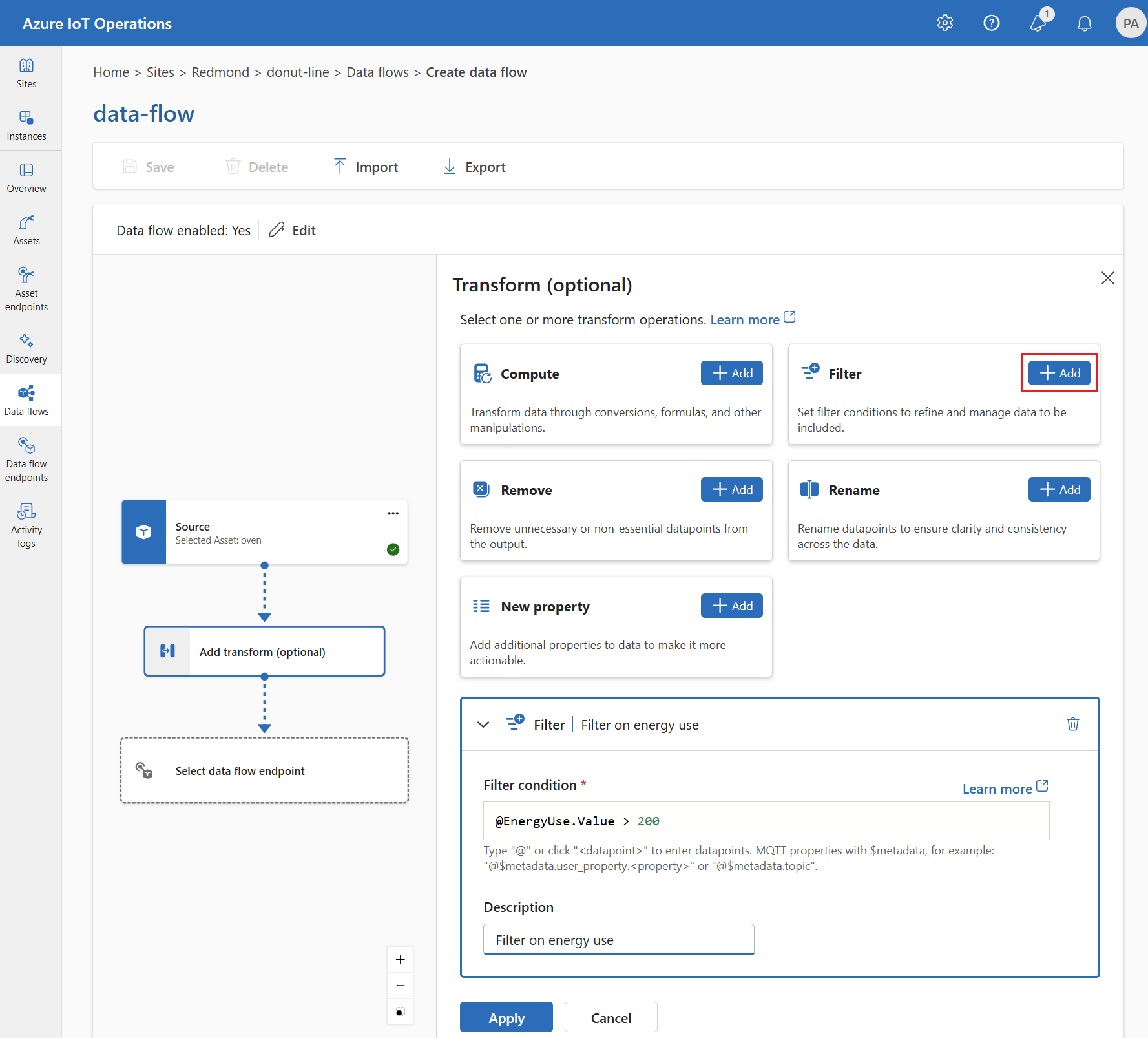
Seleccione Aplicar.
Por ejemplo, podría usar una condición de filtro como temperature > 20 para filtrar datos menores o iguales a 20 en función del campo de temperatura.
Asignación: mover datos de un campo a otro
Para asignar los datos a otro campo con conversión opcional, puede usar la operación map. La conversión se especifica como una fórmula que usa los campos de los datos de origen.
En la experiencia de operaciones, la asignación se admite actualmente mediante transformaciones de Compute.
En Transformar (opcional), seleccione Compute>Agregar.
Escriba los campos y expresiones necesarios.
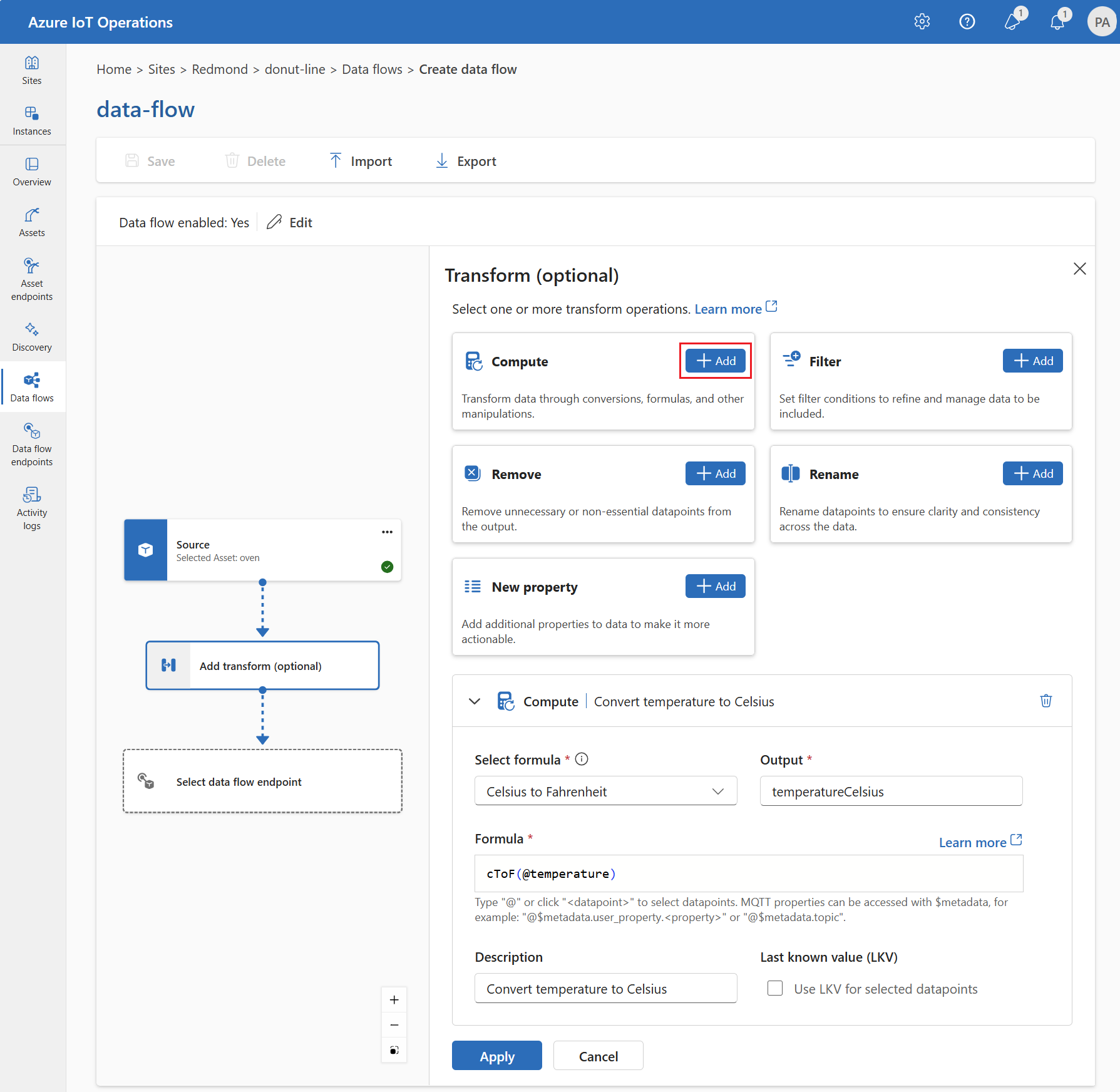
Seleccione Aplicar.
Para más información, consulte Asignación de datos mediante flujos de datos y Convertir datos mediante flujos de datos.
Serializar datos según un esquema
Si desea serializar los datos antes de enviarlos al destino, debe especificar un esquema y un formato de serialización. De lo contrario, los datos se serializan en JSON con los tipos inferidos. Los puntos de conexión de almacenamiento como Microsoft Fabric o Azure Data Lake requieren un esquema para garantizar la coherencia de los datos. Los formatos de serialización admitidos son Parquet y Delta.
Actualmente, no se admite la especificación del esquema de salida y la serialización en la experiencia de operaciones.
Para obtener más información sobre el registro de esquemas, consulte Comprender los esquemas de mensajes.
Destino
Para configurar un destino para el flujo de datos, especifique la referencia del punto de conexión y el destino de datos. Puede especificar una lista de destinos de datos para el punto de conexión.
Para enviar datos a un destino distinto del corredor MQTT local, cree un punto de conexión de flujo de datos. Para obtener información sobre cómo hacerlo, consulte Configurar puntos de conexión de flujo de datos. Si el destino no es el corredor MQTT local, debe usarse como origen. Para más información al respecto, consulte Los flujos de datos deben usar el punto de conexión del corredor MQTT local.
Importante
Los puntos de conexión de almacenamiento requieren una referencia de esquema. Si ha creado puntos de conexión de destino de almacenamiento para Microsoft Fabric OneLake, ADLS Gen 2, Azure Data Explorer y Almacenamiento local, debe especificar la referencia del esquema.
Seleccione el punto de conexión de flujo de datos que se va a usar como destino.
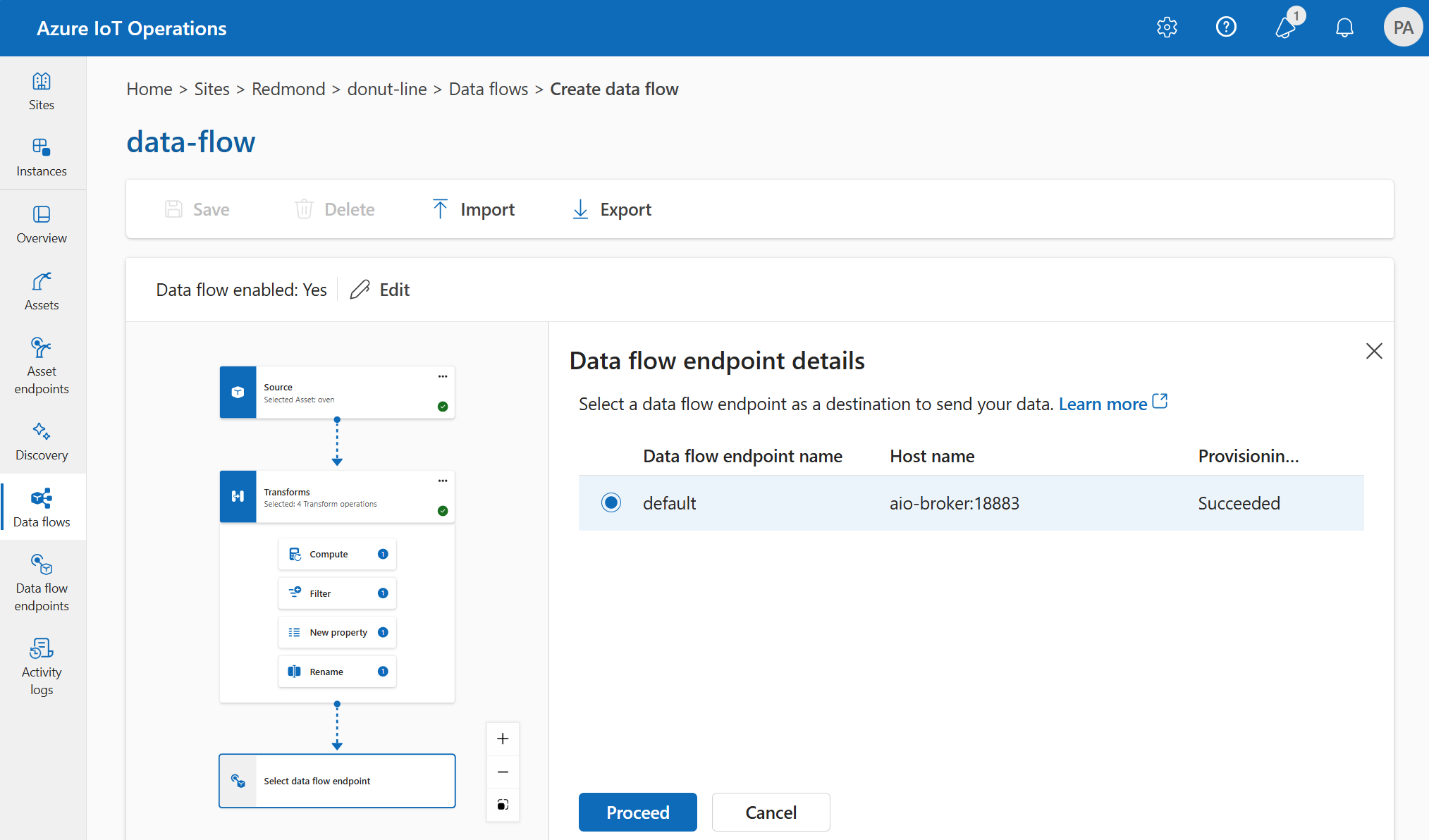
Seleccione Continuar para configurar el destino.
Escriba la configuración necesaria para el destino, incluido el tema o la tabla a los que enviar los datos. Consulte Configurar destino de datos (tema, contenedor o tabla) para obtener más información.
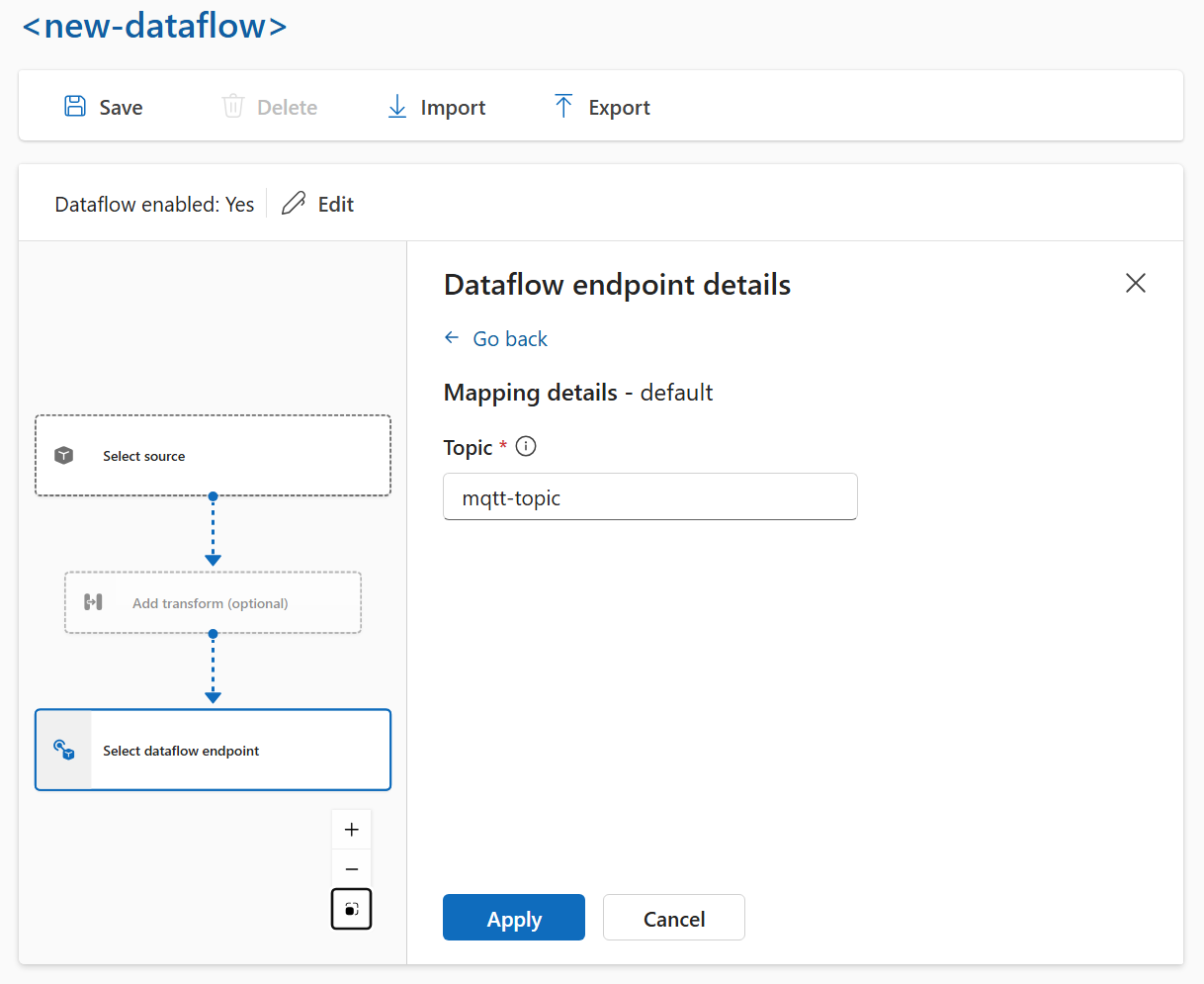
Configurar el destino de datos (tema, contenedor o tabla)
De forma similar a los orígenes de datos, el destino de datos es un concepto que se usa para mantener los puntos de conexión de flujo de datos reutilizables en varios flujos de datos. Básicamente, representa el subdirectorio en la configuración del punto de conexión del flujo de datos. Por ejemplo, si el punto de conexión de flujo de datos es un punto de conexión de almacenamiento, el destino de datos es la tabla de la cuenta de almacenamiento. Si el punto de conexión de flujo de datos es un punto de conexión de Kafka, el destino de datos es el tema de Kafka.
| Tipo de punto de conexión | Significado del destino de datos | Descripción |
|---|---|---|
| MQTT (o Event Grid) | Tema | El tema MQTT donde se envían los datos. Solo se admiten temas estáticos, sin caracteres comodín. |
| Kafka (o Event Hubs) | Tema | Tema de Kafka donde se envían los datos. Solo se admiten temas estáticos, sin caracteres comodín. Si el punto de conexión es un espacio de nombres de Event Hubs, el destino de datos es el centro de eventos individual dentro del espacio de nombres. |
| Almacén de Azure Data Lake | Contenedor | Contenedor de la cuenta de almacenamiento. No la tabla. |
| Microsoft Fabric OneLake | Tabla o carpeta | Corresponde al tipo de ruta de acceso para el punto de conexión configurado. |
| Explorador de datos de Azure | Tabla | Tabla de la base de datos de Azure Data Explorer. |
| Almacenamiento local | Carpeta | Nombre de carpeta o directorio en el montaje del volumen persistente de almacenamiento local. Al usar el Almacenamiento de contenedores de Azure habilitado por volúmenes perimetrales de ingesta en la nube de Azure Arc, esto debe coincidir con el parámetro spec.path para el subvolumen que creó. |
Para configurar el destino de datos:
Al usar la experiencia de operaciones, el campo de destino de datos se interpreta automáticamente en función del tipo de punto de conexión. Por ejemplo, si el punto de conexión de flujo de datos es un punto de conexión de almacenamiento, la página de detalles de destino le pedirá que escriba el nombre del contenedor. Si el punto de conexión de flujo de datos es un punto de conexión MQTT, la página de detalles de destino le pedirá que escriba el tema, etc.
Ejemplo
El ejemplo siguiente es una configuración de flujo de datos que usa el punto de conexión MQTT para el origen y el destino. El origen filtra los datos del tema azure-iot-operations/data/thermostat de MQTT. La transformación convierte la temperatura en Fahrenheit y filtra los datos donde la temperatura multiplicada por la humedad es inferior a 100 000. El destino envía los datos al tema MQTT factory.
Consulte las pestañas Bicep o Kubernetes para ver el ejemplo de configuración.
Para ver más ejemplos de configuraciones de flujo de datos, consulte API REST de Azure: flujo de datos y el inicio rápido de Bicep.
Comprobación de que un flujo de datos funciona
Siga el tutorial: Puente MQTT bidireccional a Azure Event Grid para comprobar que el flujo de datos funciona.
Exportar la configuración del flujo de datos
Para exportar la configuración del flujo de datos, puede usar la experiencia de operaciones o exportar el recurso personalizado de flujo de datos.
Seleccione el flujo de datos que desea exportar y seleccione Exportar en la barra de herramientas.
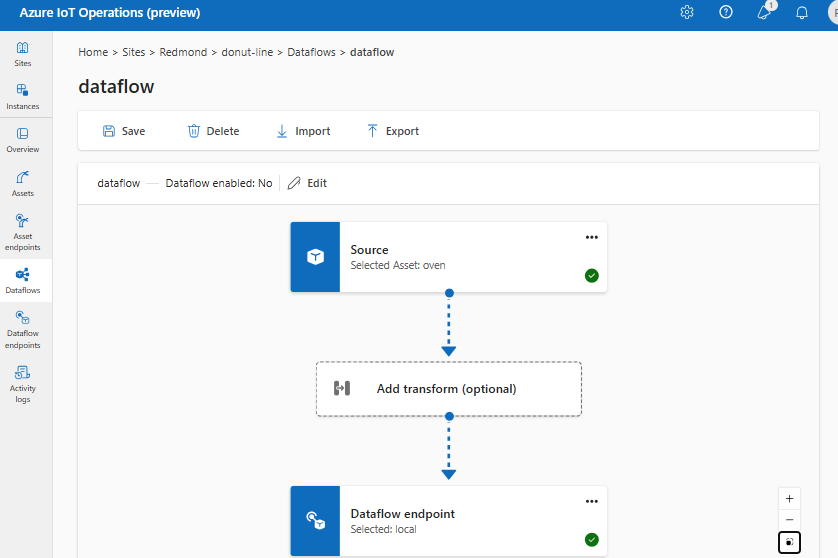
Configuración correcta del flujo de datos
Para asegurarse de que el flujo de datos funciona según lo previsto, compruebe lo siguiente:
- El punto de conexión de flujo de datos MQTT predeterminado debe usarse como origen o destino.
- El perfil de flujo de datos existe y se le hace referencia en la configuración del flujo de datos.
- El origen es un punto de conexión MQTT, un punto de conexión de Kafka o un recurso. Los puntos de conexión de tipo de almacenamiento no se pueden usar como origen.
- Cuando se usa Event Grid como origen, el recuento de instancias del perfil de flujo de datos se establece en 1 porque el corredor MQTT de Event Grid no admite suscripciones compartidas.
- Cuando se usa Event Hubs como origen, cada centro de eventos del espacio de nombres es un tema de Kafka independiente y debe especificarse como origen de datos.
- La transformación, si se usa, se configura con la sintaxis correcta, incluida la secuencia de caracteres de escape apropiada en los caracteres especiales.
- Cuando se usan puntos de conexión de tipo de almacenamiento como destino, se especifica un esquema.