Continuidad empresarial y recuperación ante desastres para Azure Logic Apps
Para ayudar a reducir el impacto y los efectos que los eventos imprevisibles tienen en la empresa y los clientes, asegúrese de contar con una solución de recuperación ante desastres (DR) para poder proteger los datos, restaurar rápidamente los recursos que complementan las funciones empresariales críticas y seguir ejecutando las operaciones para mantener la continuidad empresarial (BC). Por ejemplo, las interrupciones pueden incluir pérdidas en la infraestructura o los componentes subyacentes, como los recursos de almacenamiento, red o proceso, errores irrecuperables de aplicaciones o incluso una pérdida total del centro de información. Al tener una solución de continuidad empresarial y recuperación ante desastres (BCDR) lista, la empresa o la organización puede responder más rápidamente a las interrupciones (planeadas o no) y reducir el tiempo de inactividad para los clientes.
En este artículo se proporcionan instrucciones y estrategias de BCDR que puede aplicar al crear flujos de trabajo automatizados mediante Azure Logic Apps. Los flujos de trabajo de aplicaciones lógicas le ayudan a integrar datos y organizarlos más fácilmente entre aplicaciones, servicios en la nube y sistemas locales mediante la reducción de la cantidad de código que se debe escribir. Al planificar la continuidad empresarial y recuperación ante desastres, asegúrese de tener en cuenta no solo las aplicaciones lógicas, sino también estos recursos de Azure que se usan con ellas:
Las Conexiones que se crean a partir de flujos de trabajo de aplicaciones lógicas a otras aplicaciones, servicios y sistemas. Para obtener más información, vea Conexiones a recursos más adelante en este tema.
Las puertas de enlace de datos locales, que son recursos de Azure que se crean y se usan en las aplicaciones lógicas para acceder a los datos de sistemas locales. Cada recurso de puerta de enlace representa una instalación de puerta de enlace independiente en un equipo local. Para obtener más información, vea Puertas de enlace de datos locales más adelante en este tema.
Las cuentas de integración donde se definen y almacenan los artefactos que las aplicaciones lógicas usan para escenarios de integración empresarial de negocio a negocio (B2B). Por ejemplo, puede configurar la recuperación ante desastres entre regiones para cuentas de integración.
Ubicaciones principales y secundarias
Cada aplicación lógica debe especificar la ubicación que quiera usar para la implementación, como una región de Azure, por ejemplo, "Oeste de EE. UU". Esta estrategia de recuperación ante desastres se centra en la configuración de la aplicación lógica principal para que realice una conmutación por error en una aplicación lógica en espera o de copia de seguridad en una ubicación alternativa donde también esté disponible Azure Logic Apps. De este modo, si la aplicación lógica principal sufre pérdidas, interrupciones o errores, la secundaria puede continuar el trabajo. En esta estrategia es necesario que la aplicación lógica secundaria y los recursos dependientes ya estén implementados y listos en la ubicación alternativa.
Nota:
Si la aplicación lógica también funciona con artefactos B2B, como entidades, acuerdos entre socios comerciales, esquemas, mapas y certificados, que se almacenan en una cuenta de integración, tanto la cuenta de integración como las aplicaciones lógicas deben usar la misma ubicación.
Si sigue los procedimientos recomendados de DevOps, ya usa plantillas de Azure Resource Manager para definir e implementar las aplicaciones lógicas y sus recursos dependientes. Las plantillas de Resource Manager le permiten usar una única definición de implementación y, después, utilizar archivos de parámetros para proporcionar los valores de configuración que se usarán en cada destino de implementación. Esta capacidad significa que puede implementar la misma aplicación lógica en entornos diferentes, por ejemplo, de desarrollo, prueba y producción. También puede implementar la misma aplicación lógica en diferentes regiones de Azure, lo que permite estrategias de recuperación ante desastres que usan regiones emparejadas.
En cuanto a la estrategia de conmutación por error, las aplicaciones lógicas y las ubicaciones deben cumplir estos requisitos:
La instancia de aplicación lógica secundaria tiene acceso a las mismas aplicaciones, servicios y sistemas que la instancia de aplicación lógica principal.
Las dos instancias de aplicación lógica tienen el mismo tipo de host. Así pues, ambas instancias se implementan en regiones de Azure Logic Apps multiinquilino globales o en regiones de Azure Logic Apps de inquilino único. Para obtener procedimientos recomendados y más información sobre las regiones emparejadas para BCDR, consulte Replicación entre regiones en Azure: Continuidad empresarial y recuperación ante desastres.
Ejemplo: Azure multiinquilino
En este ejemplo se muestran instancias de aplicaciones lógicas principales y secundarias, que se implementan en regiones independientes de la instancia multiinquilino global de Azure para este escenario. Las dos instancias de aplicación lógica y los recursos dependientes que necesitan se definen en una sola plantilla de Resource Manager. Los valores de configuración que se usan para cada ubicación de implementación se especifican en archivos de parámetros independientes:
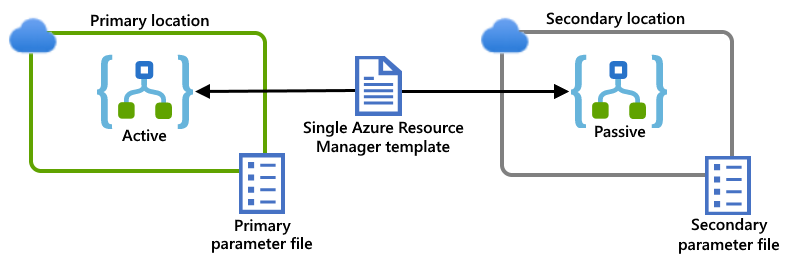
Conexiones a recursos
Azure Logic Apps proporciona cientos de operaciones de conectores que el flujo de trabajo de la aplicación lógica puede usar para trabajar con otras aplicaciones, servicios, sistemas y recursos, como cuentas de Azure Storage, bases de datos de SQL Server, cuentas de correo electrónico profesionales o educativas, etc. Si la aplicación lógica necesita acceder a estos recursos, debe crear conexiones que autentiquen el acceso a estos recursos. Cada conexión es un recurso de Azure independiente que existe en una ubicación específica y que los recursos de otras ubicaciones no pueden usar.
En la estrategia de recuperación ante desastres, tenga en cuenta las ubicaciones en las que existen los recursos dependientes en relación con las instancias de la aplicación lógica:
La instancia principal y los recursos dependientes existen en ubicaciones diferentes. En este caso, la instancia secundaria se puede conectar a los mismos recursos o puntos de conexión dependientes. Sin embargo, debe crear conexiones específicas para la instancia secundaria. De ese modo, si la ubicación principal deja de estar disponible, las conexiones de la secundaria no se verán afectadas.
Por ejemplo, imagine que la aplicación lógica principal se conecta a un servicio externo, como Salesforce. Normalmente, la disponibilidad y la ubicación del servicio externo son independientes de la disponibilidad de la aplicación lógica. En este caso, la instancia secundaria se puede conectar al mismo servicio, pero debe tener su propia conexión.
Tanto la instancia principal como los recursos dependientes existen en la misma ubicación. En este caso, los recursos dependientes deben tener copias de seguridad o versiones replicadas en otra ubicación, de modo que la instancia secundaria todavía pueda acceder a esos recursos.
Por ejemplo, imagine que la aplicación lógica principal se conecta a un servicio que se encuentra en la misma ubicación o región, por ejemplo, Azure SQL Database. Si toda la región deja de estar disponible, es probable que el servicio Azure SQL Database de esa región tampoco esté disponible. En este caso, le interesará que la instancia secundaria use una base de datos replicada o de copia de seguridad junto con una conexión independiente a esa base de datos.
Puertas de enlace de datos locales
Si la aplicación lógica se ejecuta en la instancia multiinquilino de Azure y necesita acceso a recursos locales como bases de datos de SQL Server, tendrá que instalar la puerta de enlace de datos local en un equipo local. Después, puede crear un recurso de puerta de enlace de datos en Azure Portal para que la aplicación lógica pueda usar la puerta de enlace al crear una conexión con el recurso.
El recurso de puerta de enlace de datos está asociado a una ubicación o región de Azure, al igual que el recurso de la aplicación lógica. En la estrategia de recuperación ante desastres, asegúrese de que la puerta de enlace de datos sigue disponible para que la use la aplicación lógica. Puede habilitar la alta disponibilidad para la puerta de enlace cuando tenga varias instalaciones de puerta de enlace.
Diferencias entre roles activos-activos y activos-pasivos
Puede configurar las ubicaciones principal y secundaria para que las instancias de la aplicación lógica en estas ubicaciones puedan desempeñar estos roles:
| Rol principal-secundario | Descripción |
|---|---|
| Activo-activo | Las instancias principal y secundaria de la aplicación lógica en las dos ubicaciones controlan las solicitudes de forma activa mediante uno de estos patrones: - Equilibrio de carga: puede hacer que las dos instancias escuchen en un punto de conexión y equilibrar la carga del tráfico en cada instancia según sea necesario. - Consumidores simultáneos: puede hacer que las dos instancias actúen como consumidores simultáneos para que compitan por los mensajes de una cola. Si se produce un error en una instancia, la otra asume la carga de trabajo. |
| Activo-pasivo | La instancia de aplicación lógica principal controla de forma activa toda la carga de trabajo, mientras que la secundaria es pasiva (está deshabilitada o inactiva). La secundaria espera una señal de que la principal no está disponible o no funciona debido a una interrupción o un error, y asume la carga de trabajo como instancia activa. |
| Combinación | Algunas aplicaciones lógicas desempeñan un rol activo-activo, mientras que otras asumen un rol activo-pasivo. |
Ejemplos de rol activo-activo
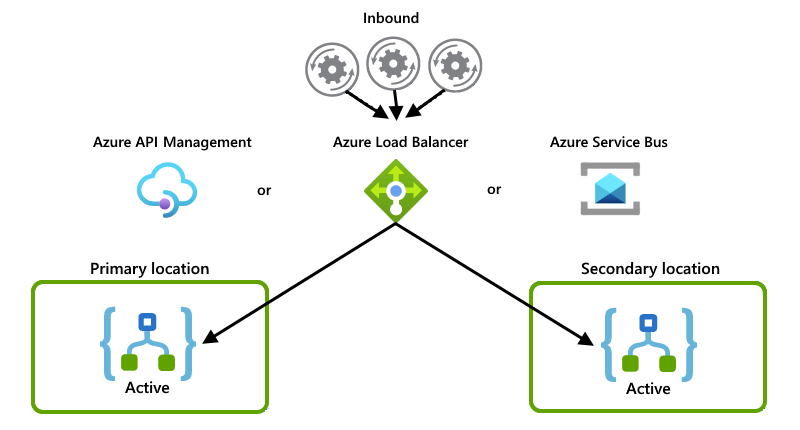
En estos ejemplos se muestra la configuración activo-activo donde las dos instancias de aplicación lógica controlan de forma activa las solicitudes o los mensajes. Otro sistema o servicio distribuye las solicitudes o los mensajes entre las instancias, por ejemplo, una de estas opciones:
Un equilibrador de carga "físico", como un componente de hardware que enruta el tráfico
Un equilibrador de carga "temporal", como Azure Load Balancer o Azure API Management. Con API Management, puede especificar directivas que determinen cómo equilibrar la carga del tráfico entrante. O bien, puede usar un servicio que admita el seguimiento de estado, por ejemplo, Azure Service Bus.
Aunque en este ejemplo se muestra principalmente Azure Load Balancer, puede usar la opción que mejor se adapte a las necesidades del escenario:
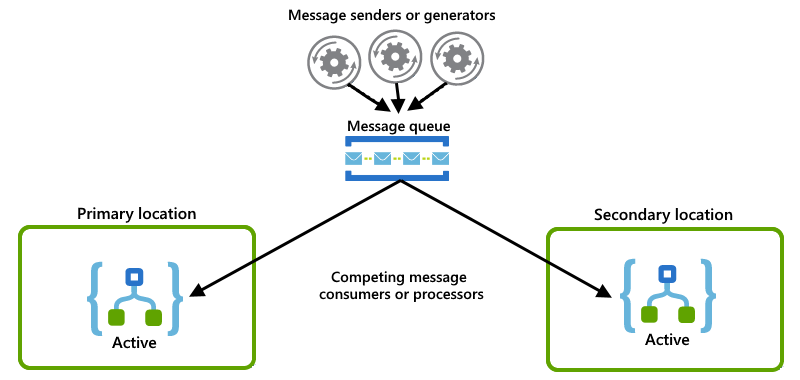
Cada instancia de aplicación lógica actúa como un consumidor y las dos instancias compiten por los mensajes de una cola:
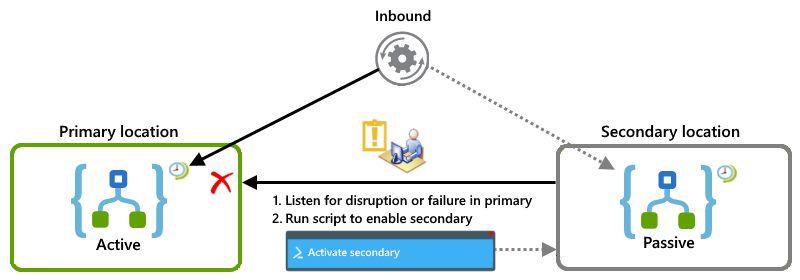
Ejemplos de rol activo-pasivo
En este ejemplo se muestra la configuración activo-pasivo en la que la instancia de aplicación lógica principal está activa en una ubicación, mientras que la secundaria permanece inactiva en otra. Si la principal experimenta una interrupción o un error, puede hacer que un operador ejecute un script que active la secundaria para asumir la carga de trabajo.
Combinación con activo-activo y activo-pasivo
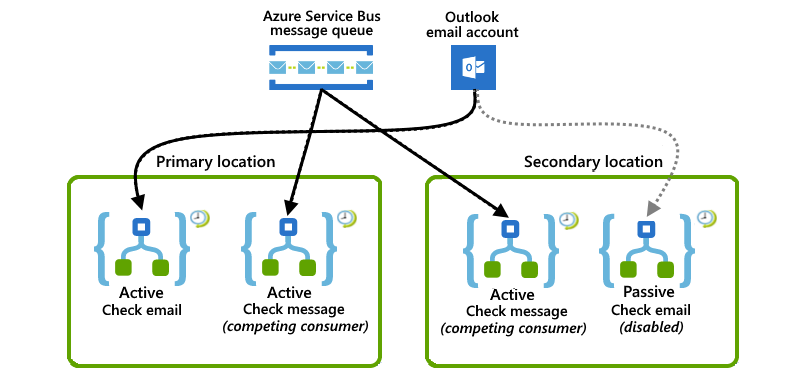
En este ejemplo se muestra una configuración combinada en la que la ubicación principal tiene instancias de aplicación lógica activas, mientras que la secundaria tiene instancias de aplicación lógica activas-pasivas. Si la ubicación principal sufre una interrupción o un error, la aplicación lógica activa en la ubicación secundaria, que ya controla una carga de trabajo parcial, puede asumir toda la carga de trabajo.
En la ubicación principal, una aplicación lógica activa escucha los mensajes en una cola de Azure Service Bus, mientras que otra aplicación lógica activa busca correos electrónicos mediante un desencadenador de sondeo de Office 365 Outlook.
En la ubicación secundaria, una aplicación lógica activa trabaja con la de la ubicación principal escuchando y compitiendo por los mensajes de la misma cola de Service Bus. Mientras tanto, una aplicación lógica inactiva pasiva espera para comprobar los mensajes de correo electrónico cuando la ubicación principal deja de estar disponible, pero está deshabilitada para evitar que los mensajes se vuelvan a leer.
Estado e historial de la aplicación lógica
Cuando se desencadena la aplicación lógica y comienza a ejecutarse, su estado se almacena en la misma ubicación en la que se ha iniciado y no se transfiere a otra. Si se produce un error o una interrupción, se abandonan todas las instancias de flujo de trabajo en curso. Si ha configurado ubicaciones principales y secundarias, las nuevas instancias de flujo de trabajo comienzan a ejecutarse en la secundaria.
Reducción de instancias en curso abandonadas
Para minimizar el número de instancias de flujo de trabajo en curso abandonadas, puede elegir entre varios patrones de mensaje para implementar, por ejemplo:
Patrón de lista de distribución fija
Este patrón de mensajes empresariales divide un proceso empresarial en fases más pequeñas. En cada fase, se configura una aplicación lógica que controla la carga de trabajo de esa fase. Para comunicarse entre sí, las aplicaciones lógicas usan un protocolo de mensajería asincrónico como colas o temas de Azure Service Bus. Al dividir un proceso en fases más pequeñas, se reduce el número de procesos empresariales que podrían quedarse bloqueados en una instancia de aplicación lógica con errores. Para obtener más información general sobre este patrón, vea Patrones de integración empresarial: lista de distribución.
En este ejemplo se muestra un patrón de lista de distribución en el que cada aplicación lógica representa una fase y usa una cola de Service Bus para comunicarse con la siguiente aplicación lógica del proceso.
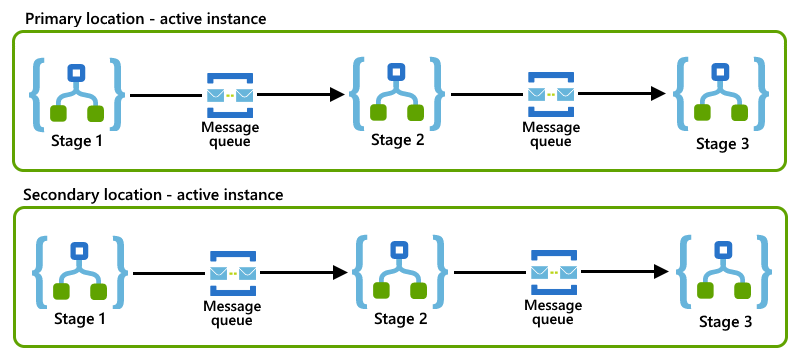
Si las instancias principal y secundaria de la aplicación lógica siguen el mismo patrón de lista de distribución en sus ubicaciones, puede implementar el patrón de consumidores simultáneos si configura roles activos-activos para esas instancias.
Acceso al historial de ejecuciones y desencadenadores
Para obtener más información sobre las ejecuciones de flujo de trabajo anteriores de la aplicación lógica, puede revisar su historial de desencadenadores y ejecuciones. El historial de ejecución de una aplicación lógica se almacena en la misma ubicación o región en la que se ha ejecutado, lo que significa que no se puede migrar a otra ubicación. Si la instancia principal realiza una conmutación por error a una instancia secundaria, solo se puede acceder al historial de ejecuciones y desencadenadores de cada instancia en las ubicaciones correspondientes en las que se hayan ejecutado. Sin embargo, puede obtener información independiente de la ubicación sobre el historial de la aplicación lógica si configura las aplicaciones lógicas para que envíen eventos de diagnóstico a un área de trabajo de Azure Log Analytics. Después, puede revisar el estado y el historial entre las aplicaciones lógicas que se ejecutan en varias ubicaciones.
Instrucciones sobre los tipos de desencadenador
El tipo de desencadenador que use en las aplicaciones lógicas determina las opciones de configuración de las aplicaciones lógicas en todas las ubicaciones de la estrategia de recuperación ante desastres. Estos son los tipos de desencadenador disponibles que puede usar en las aplicaciones lógicas:
- Desencadenador de periodicidad
- Desencadenador de sondeo
- Desencadenador de solicitud
- Desencadenador de webhook
Desencadenador de periodicidad
El desencadenador de periodicidad es independiente de cualquier servicio o punto de conexión específico, y solo se activa en función de una programación especificada y ningún otro criterio, por ejemplo:
- Una frecuencia y un intervalo fijos, por ejemplo, cada 10 minutos
- Una programación más avanzada, como el último lunes de cada mes a las 17:00.
Si la aplicación lógica se inicia con un desencadenador de periodicidad, debe configurar las instancias principal y secundaria de la aplicación lógica con los roles activos-pasivos. Para reducir el objetivo de tiempo de recuperación (RTO), que hace referencia a la duración de destino para la restauración de un proceso empresarial después de una interrupción o un desastre, puede configurar las instancias de la aplicación lógica con una combinación de roles activos-pasivos y roles pasivos-activos. En esta configuración, la programación se divide entre las ubicaciones.
Por ejemplo, imagine que tiene una aplicación lógica que se debe ejecutar cada 10 minutos. Puede configurar las ubicaciones y las aplicaciones lógicas de forma que si la ubicación principal deja de estar disponible, la secundaria pueda asumir el trabajo:
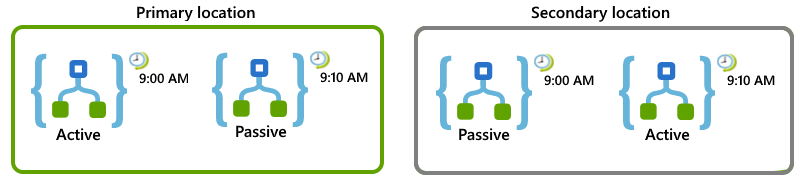
En la ubicación principal, configure roles activos-pasivos para estas aplicaciones lógicas:
En el caso de la aplicación lógica habilitada activa, establezca el desencadenador de periodicidad para que se inicie al comenzar la hora y se repita cada 20 minutos, por ejemplo, 9:00, 9:20, etc.
En el caso de la aplicación lógica deshabilitada pasiva, establezca el desencadenador de periodicidad en la misma programación, pero para que se inicie a los 10 minutos de comenzar la hora y se repita cada 20 minutos, por ejemplo, 9:10, 9:30, etc.
En la ubicación secundaria, configure estas aplicaciones lógicas como pasiva-activa:
Para la aplicación lógica deshabilitada pasiva, establezca el desencadenador de periodicidad en la misma programación que la aplicación lógica activa de la ubicación principal, que empieza al principio de la hora y se repite cada 20 minutos, por ejemplo, 9:00, 9:10 y así sucesivamente.
Para la aplicación lógica habilitada activa, establezca el desencadenador de periodicidad en la misma programación que la aplicación lógica pasiva de la ubicación principal, que empieza a los 10 minutos de la hora y se repite cada 20 minutos, por ejemplo, 9:10, 9:20 y así sucesivamente.
Ahora, si se produce un evento de interrupción en la ubicación principal, se activa la aplicación lógica pasiva en la ubicación alternativa. De este modo, si para identificar el error se necesita tiempo, esta configuración limita el número de repeticiones que faltan durante ese retraso.
Desencadenador de sondeo
Para comprobar de forma periódica si hay nuevos datos disponibles para el procesamiento desde un servicio o punto de conexión concreto, la aplicación lógica puede usar un desencadenador de sondeo que llame repetidamente al servicio o punto de conexión en función de una programación de periodicidad fija. Los datos proporcionados por el servicio o el punto de conexión pueden tener cualquiera de estos tipos:
- Datos estáticos, que describen los datos que siempre están disponibles para la lectura
- Datos volátiles, que describen los datos que ya no están disponibles para la lectura
Para evitar leer repetidamente los mismos datos, la aplicación lógica debe recordar qué datos se han leído previamente mediante el mantenimiento del estado en el lado cliente o en el del servidor, servicio o sistema.
Las aplicaciones lógicas que funcionan con el estado del lado cliente usan desencadenadores que pueden mantener el estado.
Por ejemplo, un desencadenador que lee un mensaje nuevo de una bandeja de entrada de correo electrónico requiere que el desencadenador pueda recordar el mensaje leído más recientemente. De este modo, el desencadenador inicia la aplicación lógica solo cuando llega el siguiente mensaje no leído.
Las aplicaciones lógicas que funcionan con el estado del servidor, el servicio o el sistema usan valores de propiedad u opciones que se encuentran en el lado del servidor, el servicio o el sistema.
Por ejemplo, un desencadenador basado en consultas que lee una fila de una base de datos requiere que la fila tenga una columna
isReadestablecida enFALSE. Cada vez que el desencadenador lee una fila, la aplicación lógica actualiza esa fila y cambia la columnaisReaddeFALSEaTRUE.Este enfoque del lado servidor funciona de forma similar para colas o temas de Service Bus que tienen semántica de puesta en cola, donde un desencadenador puede leer y bloquear un mensaje mientras la aplicación lógica lo procesa. Cuando la aplicación lógica finaliza el procesamiento, el desencadenador elimina el mensaje de la cola o el tema.
Desde la perspectiva de la recuperación ante desastres, al configurar las instancias principal y secundaria de la aplicación lógica, asegúrese de que tiene en cuenta estos comportamientos en función de si la aplicación lógica realiza el seguimiento del estado en el lado cliente o en el lado servidor:
En el caso de una aplicación lógica que funcione con el estado del lado cliente, asegúrese de que la aplicación lógica no lea el mismo mensaje más de una vez. Solo puede haber una instancia de aplicación lógica activa en un momento determinado en una ubicación. Asegúrese de que la instancia de aplicación lógica de la ubicación alternativa está inactiva o deshabilitada hasta que la instancia principal conmute por error a la ubicación alternativa.
Por ejemplo, el desencadenador de Office 365 Outlook mantiene el estado del lado cliente y realiza el seguimiento de la marca de tiempo del último correo electrónico que se haya leído para evitar que se lea un duplicado.
En el caso de una aplicación lógica que funciona con el estado del lado servidor, puede configurar las instancias para que desempeñen roles activos-activos en los que funcionan como consumidores simultáneos o roles activos-pasivos en los que la instancia alternativa espera hasta que la principal conmute por error a la ubicación alternativa.
Por ejemplo, la lectura desde una cola de mensajes, como una cola de Azure Service Bus, usa el estado del lado servidor, ya que el servicio de puesta en cola mantiene bloqueos en los mensajes para evitar que otros clientes lean los mismos mensajes.
Nota
Si la aplicación lógica tiene que leer los mensajes en un orden concreto, por ejemplo, desde una cola de Service Bus, puede usar el patrón de consumidor simultáneo, pero solo cuando lo combina con sesiones de Service Bus, lo que también se conoce como patrón de convoy secuencial. De lo contrario, tendrá que configurar las instancias de la aplicación lógica con los roles activos-pasivos.
Desencadenador de solicitud
El desencadenador de solicitud hace que se pueda llamar a la aplicación lógica desde otras aplicaciones, servicios y sistemas, y normalmente se usa para proporcionar estas funciones:
API REST directa para la aplicación lógica a la que otros usuarios pueden llamar
Por ejemplo, use el desencadenador de solicitud para iniciar la aplicación lógica para que otras aplicaciones lógicas puedan llamar al desencadenador mediante la acción Flujo de trabajo de llamada: Logic Apps.
Webhook o mecanismo de devolución de llamada para la aplicación lógica
Una manera de poder ejecutar manualmente las operaciones de usuario o rutinas para llamar a la aplicación lógica, por ejemplo, mediante un script de PowerShell que realiza una tarea específica.
Desde una perspectiva de recuperación ante desastres, el desencadenador de solicitud es un receptor pasivo porque la aplicación lógica no realiza ningún trabajo y espera hasta que otro servicio o sistema llame de forma explícita al desencadenador. Como punto de conexión pasivo, puede configurar las instancias principal y secundaria de estas maneras:
Activo-activo: las dos instancias controlan las solicitudes o llamadas de forma activa. El autor de la llamada o el enrutador equilibra o distribuye el tráfico entre esas instancias.
Activo-pasivo: solo la instancia principal está activa y controla todo el trabajo, mientras que la instancia secundaria espera hasta que se produce una interrupción o un error en la principal. El autor de la llamada o el enrutador determina cuándo se debe llamar a la instancia secundaria.
Como arquitectura recomendada, puede utilizar Azure API Management como proxy para las aplicaciones lógicas que usan desencadenadores de solicitud. API Management proporciona resistencia entre regiones integrada y la capacidad de enrutar el tráfico a través de varios puntos de conexión.
Desencadenador de webhook
Un desencadenador de webhook proporciona la funcionalidad para que la aplicación lógica se suscriba a un servicio pasando una dirección URL de devolución de llamada a ese servicio. Después, la aplicación lógica puede escuchar y esperar a que se produzca un evento específico en ese punto de conexión de servicio. Cuando se produce el evento, el servicio llama al desencadenador de webhook mediante la dirección URL de devolución de llamada, que luego ejecuta la aplicación lógica. Cuando está habilitado, el desencadenador de webhook se suscribe al servicio. Cuando está deshabilitado, el desencadenador de webhook cancela la suscripción al servicio.
Desde una perspectiva de recuperación ante desastres, configure instancias principales y secundarias que usan desencadenadores de webhook para reproducir roles activos-pasivos, ya que solo una instancia debe recibir eventos o mensajes del punto de conexión suscrito.
Evaluación del estado de la instancia principal
Para que la estrategia de recuperación ante desastres funcione, la solución necesita formas de realizar estas tareas:
- Comprobar la disponibilidad de la instancia principal
- Supervisar el estado de la instancia principal
- Activar la instancia secundaria
En esta sección se describe una solución que puede usar de forma directa o como base para un diseño propio. A continuación se muestra una introducción visual general para esta solución:
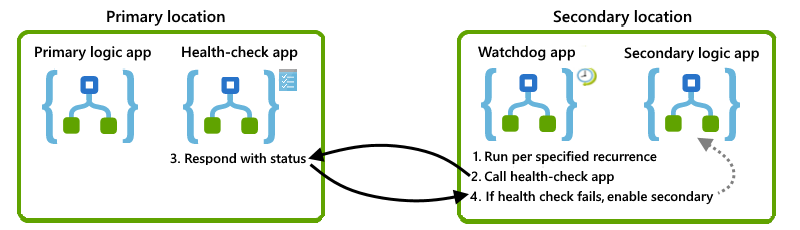
Comprobación de la disponibilidad de la instancia principal
Para determinar si la instancia principal está disponible, en ejecución y puede funcionar, puede crear una aplicación lógica de "comprobación de estado" que se encuentre en la misma ubicación que la instancia principal. Después, puede llamar a esta aplicación de comprobación de estado desde una ubicación alternativa. Si la aplicación de comprobación de estado responde de forma correcta, la infraestructura subyacente para el servicio Azure Logic Apps de esa región está disponible y en funcionamiento. Si la aplicación de comprobación de estado no responde, puede suponer que la ubicación ya no es correcta.
Para esta tarea, creará una aplicación lógica de comprobación de estado básica que realiza estas tareas:
Recibe una llamada de la aplicación de guardián mediante el desencadenador de solicitud.
Responda con un estado que indica si la aplicación lógica comprobada sigue funcionando mediante la acción de respuesta.
Importante
La aplicación lógica de comprobación de estado debe usar una acción de respuesta para que la aplicación responda de forma sincrónica, no asincrónica.
Opcionalmente, para determinar si la ubicación principal es correcta, puede tener en cuenta el estado de otros servicios que interactúen con la aplicación lógica de destino en esta ubicación. Simplemente expanda la aplicación lógica de comprobación de estado para que también evalúe el estado de estos otros servicios.
Creación de una aplicación lógica guardián
Para supervisar el estado de la instancia principal y llamar a la aplicación lógica de comprobación de estado, cree una aplicación lógica "guardián" en una ubicación alternativa. Por ejemplo, puede configurar la aplicación lógica guardián para que, si se produce un error al llamar a la lógica de comprobación de estado, el guardián pueda enviar una alerta al equipo de operaciones para que pueda investigar el error y el motivo de que la instancia principal no responda.
Importante
Asegúrese de que la aplicación lógica guardián esté en una ubicación distinta a la principal. Si Azure Logic Apps en la ubicación principal experimenta problemas, es posible que el flujo de trabajo de la aplicación lógica guardián no se ejecute.
Para esta tarea, cree una aplicación lógica guardián en la ubicación secundaria que realice estas tareas:
Se ejecute según una periodicidad fija o programada mediante el desencadenador de periodicidad.
Puede establecer la periodicidad en un valor que esté por debajo del nivel de tolerancia para el objetivo de tiempo de recuperación (RTO).
Llame al flujo de trabajo de la aplicación lógica de comprobación de estado en la ubicación principal mediante la acción HTTP.
También puede crear una aplicación lógica guardián más sofisticada que, después de varios errores, llama a otra aplicación lógica que controla automáticamente el cambio a la ubicación secundaria cuando se produce un error en la principal.
Activación de la instancia secundaria
Para activar de forma automática la instancia secundaria, puede crear una aplicación lógica que llame a la API de administración, como el conector de Azure Resource Manager para activar las aplicaciones lógicas adecuadas en la ubicación secundaria. Puede expandir la aplicación guardián para llamar a esta aplicación lógica de activación después de que se produzca un número específico de errores.
Redundancia de zona con zonas de disponibilidad
En cada región de Azure, las zonas de disponibilidad son ubicaciones separadas físicamente que toleran los errores locales. Estos errores pueden abarcar desde errores de software y hardware hasta eventos como terremotos, inundaciones e incendios. Estas zonas logran tolerancia a través de la redundancia y el aislamiento lógico de los servicios de Azure.
Para proporcionar resistencia y disponibilidad distribuida, en todas las regiones de Azure existen al menos tres zonas de disponibilidad independientes que admiten y habilitan la redundancia de zona. La plataforma Azure Logic Apps distribuye estas zonas y cargas de trabajo de aplicaciones lógicas entre estas zonas. Esta funcionalidad es un requisito clave para habilitar las arquitecturas resistentes y proporcionar alta disponibilidad si se producen errores en el centro de datos en una región.
Actualmente, esta funcionalidad está en versión preliminar y está disponible para las nuevas aplicaciones lógicas de consumo en regiones concretas. Para más información, consulte la siguiente documentación:
- Protección de aplicaciones lógicas de consumo frente a errores de región con redundancia de zona y zonas de disponibilidad
- Regiones y zonas de disponibilidad de Azure
Recopilación de datos de diagnóstico
Puede configurar el registro de las ejecuciones de la aplicación lógica y enviar los datos de diagnóstico resultantes a servicios como Azure Storage, Azure Event Hubs y Azure Log Analytics para un mayor control y procesamiento.
Si quiere usar estos datos con Azure Log Analytics, puede hacer que estén disponibles para las ubicaciones principal y secundaria si configura las opciones de diagnóstico de la aplicación lógica y envía los datos a varias áreas de trabajo de Log Analytics. Para más información, consulte Configuración de registros de Azure Monitor y recopilación de datos de diagnóstico para Azure Logic Apps.
Si quiere enviar los datos a Azure Storage o Azure Event Hubs, puede hacer que estén disponibles para las ubicaciones principal y secundaria si configura la redundancia geográfica. Para obtener más información, consulte estos artículos:
Pasos siguientes
- Diseño de aplicaciones de Azure confiables
- Lista de comprobación de resistencia para servicios de Azure específicos
- Administración de datos para lograr la resistencia en Azure
- Copia de seguridad y recuperación ante desastres para aplicaciones de Azure
- Recuperación después de una interrupción del servicio en toda la región
- Contratos de nivel de servicio (SLA) de Microsoft para servicios de Azure