Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: Azure Logic Apps (consumo + estándar)
La manera en la que una arquitectura de integración controla correctamente el tiempo de inactividad o los problemas causados por sistemas dependientes puede plantear un desafío. Para ayudarle a crear integraciones sólidas y resistentes que controlen correctamente los problemas y los errores, Azure Logic Apps proporciona una experiencia de primera clase para el control de errores y excepciones.
Directivas de reintentos
Para el control de errores y excepciones más básicos, puede usar la directiva de reintento si esta funcionalidad existe en un desencadenador o una acción, como la acción HTTP. Si la solicitud original del desencadenador o la acción agota el tiempo de espera o produce un error, lo que da lugar a una respuesta 408, 429 o 5xx, la directiva de reintentos especifica que el desencadenador o la acción reenvíe la solicitud por configuración de directiva.
Límites de la directiva de reintentos
Para más información sobre las directivas de reintentos, la configuración, los límites y otras opciones, consulte Límites de las directivas de reintentos.
Tipos de directiva de reintentos
Las operaciones de conector que admiten directivas de reintento usan la directiva predeterminada a menos que seleccione otra.
| Directiva de reintentos | Descripción |
|---|---|
| Default | Para la mayoría de las operaciones, la directiva de reintento predeterminada es una directiva de intervalo exponencial que envía hasta 4 reintentos a intervalos que aumentan exponencialmente. Estos intervalos escalan en 7,5 segundos, pero se limitan entre los 5 y los 45 segundos. Las operaciones usan una directiva de reintentos predeterminada diferente, como una directiva de intervalo fijo. Para más información, consulte Directiva de reintentos predeterminada. |
| None | No volver a enviar la solicitud. Para más información, consulte Ninguna: sin directiva de reintentos. |
| Intervalo exponencial | Esta directiva espera un intervalo aleatorio seleccionado de un intervalo que crece exponencialmente antes de enviar la solicitud siguiente. Para más información, revise Directiva de reintentos de intervalo exponencial. |
| Intervalo fijo | Esta directiva espera el intervalo especificado antes de enviar la solicitud siguiente. Para más información, revise Directiva de reintentos de intervalo fijo. |
Cambio del tipo de directiva de reintentos en el diseñador
En el portal de Azure, abra su recurso de aplicación lógica.
En la barra lateral del recurso, siga estos pasos para abrir el diseñador de flujos de trabajo, en función de la aplicación lógica:
Consumo: en Herramientas de desarrollo, seleccione el diseñador para abrir el flujo de trabajo.
Estándar
En Flujos de trabajo, seleccione Flujos de trabajo.
En la página Flujos de trabajo, seleccione el flujo de trabajo.
En Herramientas, seleccione el diseñador para abrir el flujo de trabajo.
En el desencadenador o la acción donde desea cambiar el tipo de directiva de reintento, siga estos pasos para abrir la configuración:
En el diseñador, seleccione la operación.
En el panel información de la operación, seleccione Configuración.
En Redes, en Política de reintento, seleccione el tipo de política que desee.
Cambio del tipo de directiva de reintentos en el editor de vista Código
Confirme si el desencadenador o la acción admiten directivas de reintentos completando los pasos anteriores en el diseñador.
Abra el flujo de trabajo de la aplicación lógica en el editor de vista Código.
En la definición de desencadenador o acción, agregue el
retryPolicyobjeto JSON al objeto del desencadenador o lainputsacción. Si no existe ningúnretryPolicyobjeto, el desencadenador o la acción usa ladefaultdirectiva de reintento."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Obligatorio
Propiedad Value Tipo Descripción type<retry-policy-type> String Tipo de directiva de reintentos que se va a usar: default,none,fixedoexponentialcount<intentos de reintento> Entero Para los tipos de directiva fixedyexponential, el número de reintentos, que es un valor comprendido entre 1 y 90. Para más información, consulte Intervalo fijo e Intervalo exponencial.interval<intervalo de reintento> String Para los tipos de directiva fixedyexponential, el valor del intervalo de reintento en formato ISO 8601. Para la directivaexponential, también puede especificar intervalos máximos y mínimos opcionales. Para más información, consulte Intervalo fijo e Intervalo exponencial.
Consumo: de 5 segundos (PT5S) a 1 día (P1D).
Estándar: para flujos de trabajo con estado, de 5 segundos (PT5S) a 1 día (P1D). En el caso de los flujos de trabajo sin estado, de 1 segundo (PT1S) a 1 minuto (PT1M).Opcional
Propiedad Value Tipo Descripción maximumInterval<intervalo máximo> String Para la directiva exponential, el intervalo más grande para el intervalo seleccionado aleatoriamente en formato ISO 8601. El valor predeterminado es 1 día (P1D). Para más información, consulte Intervalo exponencial.minimumInterval<intervalo mínimo> String Para la directiva exponential, el intervalo más pequeño para el intervalo seleccionado aleatoriamente en formato ISO 8601. El valor predeterminado es 5 segundos (PT5S). Para más información, consulte Intervalo exponencial.
Directiva de reintentos predeterminada
Las operaciones de conector que admiten directivas de reintento usan la directiva predeterminada a menos que seleccione otra. Para la mayoría de las operaciones, la directiva de reintento predeterminada es una directiva de intervalo exponencial que envía hasta 4 reintentos a intervalos que aumentan exponencialmente. Estos intervalos escalan en 7,5 segundos, pero se limitan entre los 5 y los 45 segundos. Las operaciones usan una directiva de reintentos predeterminada diferente, como una directiva de intervalo fijo.
En la definición del flujo de trabajo, la definición de desencadenador o acción no incluye explícitamente la definición de la directiva predeterminada, pero en el ejemplo siguiente se muestra cómo se comporta la directiva de reintentos predeterminada para la acción HTTP:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Ninguna: sin directiva de reintentos
Para especificar que la acción o el desencadenador no vuelvan a intentar solicitudes con error, establezca el elemento <retry-policy-type> en none.
Directiva de reintentos de intervalo fijo
Para especificar que la acción o el desencadenador esperen el intervalo especificado antes de enviar la solicitud siguiente, establezca el elemento <retry-policy-type> en fixed.
Ejemplo
Esta directiva de reintentos intenta obtener las últimas noticias dos veces más tras la primera solicitud con error con un retraso de 30 segundos entre cada intento:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Directiva de reintentos de intervalo exponencial
La directiva de reintentos de intervalo exponencial especifica que el desencadenador o la acción espera un intervalo aleatorio antes de enviar la siguiente solicitud. Este intervalo aleatorio se selecciona de un intervalo exponencialmente creciente. Opcionalmente, puede invalidar los intervalos máximos y mínimos predeterminados especificando sus propios intervalos mínimos y máximos, en función de si tiene un flujo de trabajo de la aplicación lógica Estándar o de Consumo.
| Nombre | Límite para Consumo | Límite para Estándar | Notas |
|---|---|---|---|
| Retraso máximo | Valor predeterminado: 1 día | Valor predeterminado: 1 hora | Para cambiar el límite predeterminado en un flujo de trabajo de aplicación lógica de Consumo, use el parámetro de directiva de reintentos. Para cambiar el límite predeterminado en un flujo de trabajo de aplicación lógica Estándar, consulte Edición de la configuración de host y aplicación para aplicaciones lógicas en Azure Logic Apps de inquilino único. |
| Retraso mínimo | Valor predeterminado: 5 segundos | Valor predeterminado: 5 segundos | Para cambiar el límite predeterminado en un flujo de trabajo de aplicación lógica de Consumo, use el parámetro de directiva de reintentos. Para cambiar el límite predeterminado en un flujo de trabajo de aplicación lógica Estándar, consulte Edición de la configuración de host y aplicación para aplicaciones lógicas en Azure Logic Apps de inquilino único. |
Intervalos variables aleatorios
Para la directiva de reintentos de intervalo exponencial, la tabla siguiente muestra el algoritmo general que usa Azure Logic Apps para generar una variable aleatoria uniforme en el intervalo especificado para cada reintento. El intervalo especificado puede llegar hasta el número de reintentos, incluido.
| Número de reintentos | Intervalo mínimo | Intervalo máximo |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(intervalo, <intervalo-máximo>) |
| 2 | max(interval, <minimum-interval>) | min(2 * intervalo, <intervalo-máximo>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * intervalo, <intervalo-máximo>) |
| .... | .... | .... |
Administración del comportamiento de "ejecución posterior"
Al agregar acciones en el diseñador de flujo de trabajo, declara implícitamente la secuencia para ejecutar esas acciones. Una vez finalizada la ejecución de una acción, esta se marca con el estado Correcto, Con errores, Omitida o Agotado tiempo de espera. En otras palabras, la acción predecesora debe finalizar primero con cualquiera de los estados permitidos antes de que se pueda ejecutar la acción sucesora.
De forma predeterminada, una acción que se añade en el diseñador solo se ejecuta si la acción anterior se completa con estado Exitoso. Esta ejecución después del comportamiento especifica con precisión el orden de ejecución de las acciones de un flujo de trabajo.
En el diseñador, puede cambiar el comportamiento predeterminado "ejecutar después" de una acción editando la opción Ejecutar después de la acción. Esta configuración solo está disponible en las acciones posteriores que siguen la primera acción de un flujo de trabajo. La primera acción de un flujo de trabajo siempre se ejecuta después de que el desencadenador se ejecute correctamente. Por lo tanto, la opción Ejecutar después no está disponible y no se aplica a la primera acción.
En la definición JSON subyacente de una acción, la opción Ejecutar después es la misma que la runAfter propiedad . Esta propiedad especifica una o varias acciones predecesoras que primero deben finalizar con los estados permitidos específicos antes de que se pueda ejecutar la acción sucesora. La runAfter propiedad es un objeto JSON que proporciona flexibilidad al permitirle especificar todas las acciones predecesoras que deben finalizar antes de que se ejecute la acción sucesora. Este objeto también define una matriz de estados aceptables.
Por ejemplo, para que una acción se ejecute después de que la acción A se realice correctamente y también después de que la acción B se realice correctamente o se produzca un error cuando esté trabajando en la definición JSON de una acción, configure la siguiente runAfter propiedad:
{
// Other parts in action definition
"runAfter": {
"Action A": ["Succeeded"],
"Action B": ["Succeeded", "Failed"]
}
}
Comportamiento de "Ejecutar después" para el control de errores
Cuando una acción genera una excepción o un error no controlado, la acción se marca como Con errores y las acciones sucesoras se marcan como Omitidas. Si se produce este comportamiento para una acción que tiene ramas paralelas, el motor de Azure Logic Apps sigue las otras ramas para determinar sus estados de finalización. Por ejemplo, si una rama finaliza con una acción Omitida, el estado de finalización de esa rama se basa en el estado de la predecesora de la acción omitida. Una vez completada la ejecución del flujo de trabajo, el motor determina el estado de la ejecución completa mediante la evaluación de todos los estados de las ramas. Si alguna de las ramas finaliza con un error, la ejecución de todo el flujo de trabajo se marca como Con errores.

Para asegurarse de que una acción se pueda seguir ejecutando a pesar del estado de su predecesora, puede cambiar el comportamiento de "ejecución posterior" de una acción para controlar los estados incorrectos de la predecesora. De este modo, la acción se ejecuta cuando el estado de la predecesora es Correcto, Con errores, Omitida, Agotado tiempo de espera o todos estos estados.
Por ejemplo, para ejecutar la acción Enviar un correo electrónico de Outlook de Office 365 después de que la acción de Excel Online predecesora Agregar una fila a una tabla se marque como Con errores, en lugar de como Correcto, cambie el comportamiento de "ejecución posterior" mediante el diseñador o el editor de vista Código.
Cambio del comportamiento de "ejecución posterior" en el diseñador
En el portal de Azure, abra su recurso de aplicación lógica.
En la barra lateral del recurso, siga estos pasos para abrir el diseñador de flujos de trabajo, en función de la aplicación lógica:
Consumo: en Herramientas de desarrollo, seleccione el diseñador para abrir el flujo de trabajo.
Estándar
En la barra lateral del recurso, en Flujos de trabajo, seleccione Flujos de trabajo.
En la página Flujos de trabajo, seleccione el flujo de trabajo.
En Herramientas, seleccione el diseñador para abrir el flujo de trabajo.
En el desencadenador o la acción donde desea cambiar el comportamiento de "ejecutar después", siga estos pasos para abrir la configuración de la operación:
En el diseñador, seleccione la operación.
En el panel información de la operación, seleccione Configuración.
La sección Ejecutar después contiene una lista Seleccionar acciones , que muestra las operaciones predecesoras disponibles para la operación seleccionada actualmente, por ejemplo:

En la lista Seleccionar acciones , expanda la operación predecesora actual, que es HTTP en este ejemplo:

De forma predeterminada, el estado "ejecutar después" se establece en Es correcto. Este valor significa que la operación predecesora debe finalizar correctamente antes de que se pueda ejecutar la acción actual.

Para cambiar el comportamiento de "ejecutar después" a los estados que desee, seleccione esos estados.
En el ejemplo siguiente se selecciona Error.
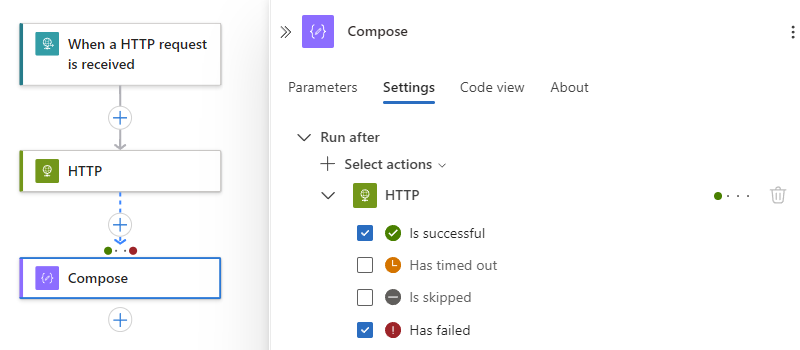
Para especificar que la operación actual solo se ejecuta cuando la acción predecesora se completa con el Ha fallado, Se omite o Ha agotado el tiempo de espera, selecciona estos estados y, a continuación, borra el estado predeterminado, por ejemplo:
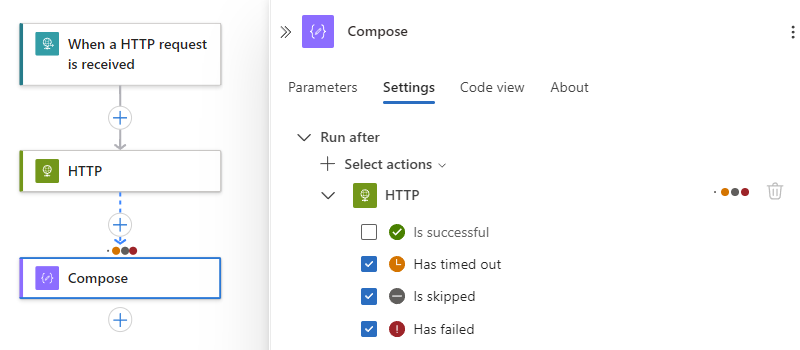
Nota:
Antes de borrar el estado predeterminado, asegúrese de seleccionar primero otro estado. Siempre debe tener al menos un estado seleccionado.
Para requerir que varias operaciones predecesoras se ejecuten y finalicen, cada una con sus propios estados de "ejecución posterior", siga estos pasos:
Abra la lista Seleccionar acciones y seleccione las operaciones predecesoras que desee.
Seleccione los estados "ejecutar después" para cada operación.
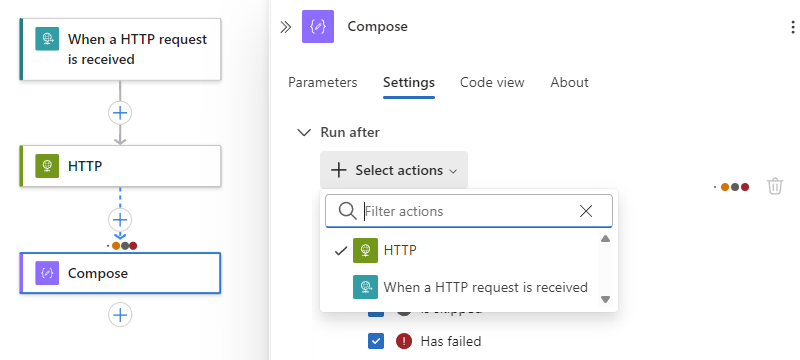
Cuando termine, cierre el panel de información de la operación.






Cambio del comportamiento de "ejecución posterior" en el editor de vista Código
En la barra lateral del recurso, siga estos pasos para abrir el editor de vistas de código, en función de la aplicación lógica:
Consumo: en Herramientas de desarrollo, seleccione la vista de código para abrir el flujo de trabajo en el editor JSON.
Estándar
En Flujos de trabajo, seleccione Flujos de trabajo.
En la página Flujos de trabajo, seleccione el flujo de trabajo.
En Herramientas, seleccione la vista de código para abrir el flujo de trabajo en el editor JSON.
En la definición JSON de la acción, edite la propiedad
runAfter, que tiene la siguiente sintaxis:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }En este ejemplo, cambie la propiedad
runAfterdeSucceededaFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Para especificar que la acción se ejecute si la acción predecesora se marca como
Failed,SkippedoTimedOut, agregue los otros estados:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Evaluación de las acciones con ámbitos y sus resultados
De forma similar a la ejecución de pasos después de acciones individuales con la configuración de "ejecución posterior", puede agrupar acciones dentro de un ámbito. Puede usar ámbitos si desea agrupar acciones lógicamente, evaluar el estado global del ámbito y realizar acciones basadas en ese estado. Una vez que todas las acciones de un ámbito acaben de ejecutarse, el propio ámbito obtiene su estado.
Para comprobar el estado de un ámbito, puede usar los mismos criterios que usa para comprobar el estado de ejecución de un flujo de trabajo, como Correcto, Con errores, etc.
De forma predeterminada, cuando las acciones del ámbito se ejecutan correctamente, el estado del ámbito se marca como Succeeded. Si la acción final de un ámbito se marca como Con errores o Anulado, el estado del ámbito se marca como Con errores.
Para capturar las excepciones en un ámbito Con errores y ejecutar acciones que controlen estos errores, puede usar la configuración de "ejecución posterior" de ese ámbito Con errores. De ese modo, si cualquier acción del ámbito produce un error, y usa la configuración de "ejecución posterior" para ese ámbito, puede crear una única acción para capturar los errores.
Para conocer los límites en los ámbitos, consulte Límites y configuración.
Configuración de un ámbito con "ejecutar después" para el control de excepciones
En Azure Portal, abra el recurso de la aplicación lógica y el flujo de trabajo en el diseñador.
El flujo de trabajo ya debe tener un desencadenador que inicie el flujo de trabajo.
En el diseñador, siga estos pasos genéricos para agregar una acción de Control denominada Ámbito al flujo de trabajo.
En la acción Ámbito, siga estos pasos genéricos para agregar acciones para ejecutar, por ejemplo:
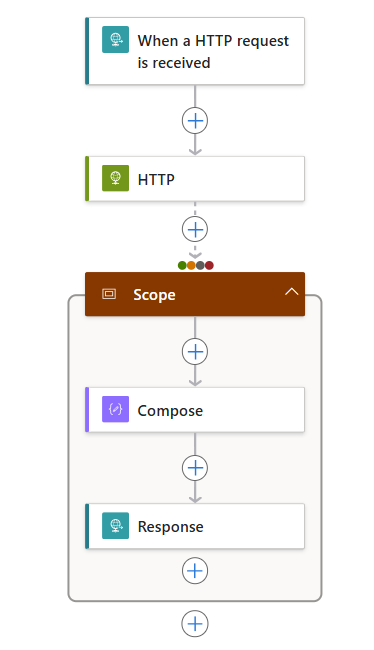
En la lista siguiente se muestran algunas acciones de ejemplo que puede incluir dentro de una acción de Ámbito:
- Obtener datos de una API.
- Procesar los datos.
- Guarde los datos en una base de datos.
Ahora, defina las reglas "ejecutar después" para ejecutar las acciones en el ámbito.
En el diseñador, seleccione el título Ámbito. Cuando se abra el panel de información del ámbito, seleccione Configuración.
Si tiene más de una acción anterior en el flujo de trabajo, en la lista Seleccionar acciones, seleccione la acción después de la cual desea ejecutar las acciones con ámbito.
Para la acción seleccionada, seleccione todos los estados de acción que pueden ejecutar las acciones con ámbito.
En otras palabras, cualquiera de los estados elegidos resultantes de la acción seleccionada hace que las acciones del ámbito se ejecuten.
En el ejemplo siguiente, las acciones con ámbito se ejecutan después de que la acción de HTTP se complete con cualquiera de los estados seleccionados:
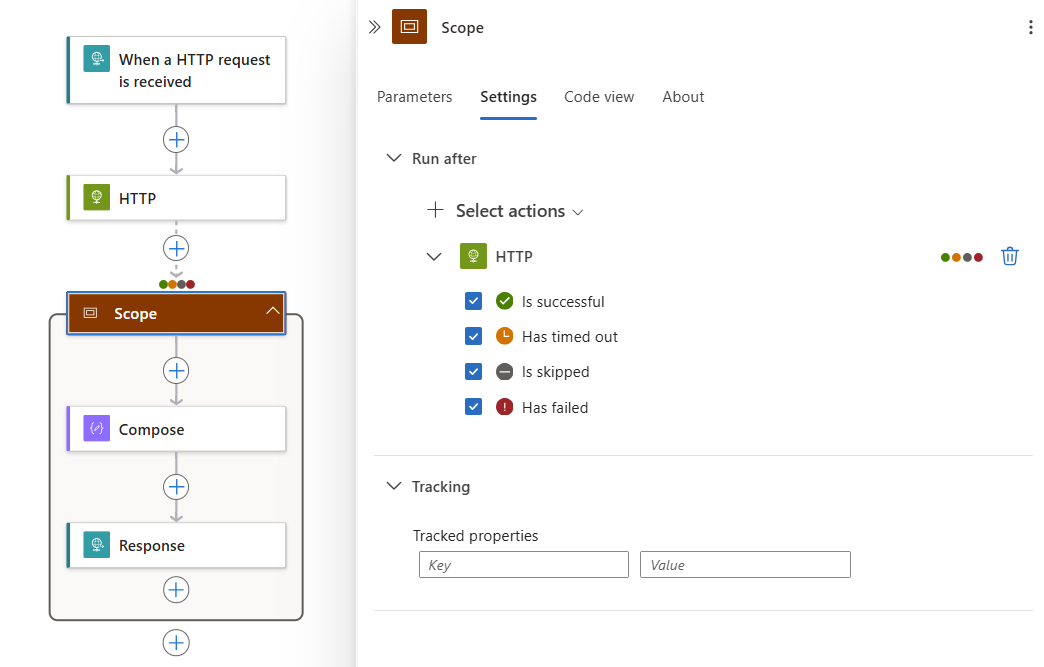
Obtención del contexto y resultados de errores
Aunque la captura de errores desde un ámbito es útil, quizás también quiera más contexto como ayuda para comprender exactamente qué acciones han producido un error y los errores o códigos de estado. La función result() devuelve los resultados de las acciones de nivel superior de una acción con ámbito. Esta función acepta el nombre del ámbito como un único parámetro y devuelve una matriz con los resultados de esas acciones de nivel superior. Estos objetos de acción tienen los mismos atributos que los devueltos por la función actions(), como la hora de inicio, la hora de finalización, el estado, las entradas, los identificadores de correlación y las salidas de la acción.
Nota:
La función result() devuelve los resultados solo de las acciones de nivel superior y no de las acciones anidadas más profundas, como las acciones Switch o Condition.
Para obtener contexto sobre las acciones que produjeron errores en un ámbito, puede usar la expresión @result() con el nombre del ámbito y la configuración de "ejecución posterior". Para filtrar la matriz devuelta por las acciones cuyo estado es Con errores, puede agregar la acción Filtrar matriz. Para ejecutar una acción para una acción errónea devuelta, tome la matriz filtrada devuelta y use un bucle For each.
El siguiente ejemplo de código JSON envía una solicitud HTTP POST con el cuerpo de la respuesta de todas las acciones que produjeron un error dentro de la acción de ámbito My_scope. Una explicación detallada sigue al ejemplo.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
En los pasos siguientes, se describe lo que sucede en este ejemplo:
Para obtener el resultado de todas las acciones de My_Scope, la acción Filtrar matriz usa esta expresión de filtro:
@result('My_Scope')La condición para Filtrar matriz es cualquier elemento
@result()que tenga un estadoFailed. Esta condición filtra la matriz que contiene todos los resultados de acción de My_Scope a una matriz con solo los resultados de acción que hayan producido un error.Realiza una acción de bucle
For_eachen las salidas de la matriz filtrada. Este paso realiza una acción para cada resultado de acción con errores que se filtrara antes.Si solo se produce un error en una acción del ámbito, las acciones del bucle
For_eachsolo se ejecutan una vez. Muchas acciones con error causan una acción por cada error.Envía una solicitud HTTP POST en el cuerpo de respuesta del elemento
For_each, que es la expresión@item()['outputs']['body'].La forma del elemento
@result()es la misma que la forma de@actions()y se puede analizar del mismo modo.Incluya dos encabezados personalizados con el nombre de la acción con errores (
@item()['name']) y el id. de seguimiento de cliente de la ejecución con errores@item()['clientTrackingId'].
Como referencia, este es un ejemplo de un solo elemento @result(), que muestra las propiedades name, body y clientTrackingId que se analizan en el ejemplo anterior. Fuera de una acción For_each, @result() devuelve una matriz de estos objetos.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Para poner en práctica diferentes patrones de control de excepciones, puede usar las expresiones descritas anteriormente en este artículo. Podría optar por ejecutar una única acción de control de excepciones fuera del ámbito, que acepte toda la matriz filtrada de errores y quite la acción For_each. También puede incluir otras propiedades útiles de la respuesta \@result(), como se ha mostrado antes.
Configuración de los registros de Azure Monitor
Los patrones anteriores son formas útiles de controlar los errores y las excepciones que se producen dentro de una ejecución. Sin embargo, también puede identificar y responder a los errores que se producen independientemente de la ejecución. Para evaluar los estados de ejecución, puede supervisar los registros y las métricas de las ejecuciones, o publicarlos en la herramienta de supervisión que prefiera.
Por ejemplo, Azure Monitor proporciona una manera simplificada de enviar todos los eventos del flujo de trabajo, incluidos todos los estados de ejecución y acción, a un destino. Puede configurar alertas para métricas y umbrales específicos en Azure Monitor. También puede enviar eventos de flujo de trabajo a un área de trabajo de Log Analytics o a una cuenta de almacenamiento de Azure. O bien, puede transmitir todos los eventos mediante Azure Event Hubs a Azure Stream Analytics. En Stream Analytics, puede escribir consultas en directo de anomalías, promedios o errores de los registros de diagnóstico. Asimismo, puede usar Stream Analytics para enviar información a otros orígenes de datos, como colas, temas, SQL, Azure Cosmos DB o Power BI.
Para más información, consulte Configuración de registros de Azure Monitor y recopilación de datos de diagnóstico para Azure Logic Apps.