Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Machine Learning Studio (clásico)
Machine Learning Studio (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este artículo, se crea un experimento de aprendizaje automático en Machine Learning Studio (clásico) que predice el precio de un coche en función de diferentes variables, como la marca y las especificaciones técnicas.
Si no está familiarizado con el aprendizaje automático, la serie de vídeos Data Science for Beginners (Ciencia de datos para principiantes) le puede brindar una excelente introducción al aprendizaje automático con un lenguaje y conceptos de uso diario.
En este inicio rápido se sigue el flujo de trabajo predeterminado para un experimento:
- Crear un modelo
- Entrenamiento del modelo
- Evaluar y probar el modelo
Obtener los datos
Lo primero que necesita en el aprendizaje automático son datos. En Studio (versión clásica) hay varios conjuntos de datos que puede usar; otra opción es importarlos de diversos orígenes. En este ejemplo, usaremos el conjunto de datos de ejemplo, Automobile price data (Raw), incluido en su espacio de trabajo. Este conjunto de datos incluye entradas para diversos automóviles individuales, por ejemplo, información sobre la marca, el modelo, las especificaciones técnicas y el precio.
Sugerencia
Puede encontrar una copia de trabajo del experimento siguiente en la galería de Azure AI. Vaya a Su primer experimento de ciencia de los datos: predicción de los precios de automóviles y haga clic en Abrir en Studio para descargar una copia del experimento en su área de trabajo de Machine Learning Studio (clásico).
Aquí se muestra cómo obtener el conjunto de datos en el experimento.
Cree un experimento nuevo, para lo que debe hacer clic en +NUEVO en la parte inferior de la ventana de Machine Learning Studio (clásico). Seleccione EXPERIMENTO> (Experimento en blanco).
El experimento recibe un nombre predeterminado que puede ver en la parte superior del lienzo. Seleccione este texto y cambie su nombre por algo significativo, por ejemplo, predicción de precios de automóviles. No es necesario que el nombre sea único.
A la izquierda del lienzo de experimentos, hay una paleta de conjuntos de datos y módulos. Escriba automobile en el cuadro de búsqueda de la parte superior de esta paleta para encontrar el conjunto de datos llamado Automobile price data (Raw) (Datos de precios de automóviles [sin formato]). Arrastre este conjunto de datos al lienzo del experimento.
Para ver la apariencia de estos datos, haga clic en el puerto de salida, en la parte inferior del conjunto de datos de automóvil y, después, seleccione Visualizar.
Sugerencia
Los conjuntos de datos y los módulos tienen puertos de entrada y de salida representados por pequeños círculos: los puertos de entrada arriba y los puertos de salida abajo. Para crear un flujo de datos a través del experimento, se conectará un puerto de salida de un módulo a un puerto de entrada de otro. En cualquier momento, puede hacer clic en el puerto de salida de un conjunto de datos o de un módulo para ver el aspecto de los datos en ese punto del flujo de datos.
En este conjunto de datos, cada fila representa un automóvil y las variables asociadas a cada automóvil aparecen como columnas. Vamos a predecir el precio de la columna del extremo derecho (columna 26, llamada "precio") con las variables para un automóvil específico.
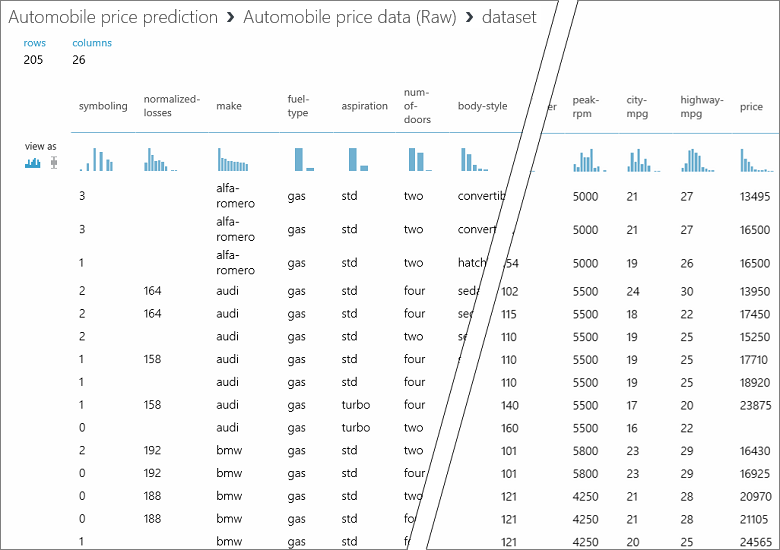
Cierre la ventana de visualización haciendo clic en la "x" en la esquina superior derecha.
Preparación de los datos
Normalmente, un conjunto de datos requiere algún procesamiento previo antes de que se pueda analizar. Es posible que haya observado los valores que faltan en las columnas de varias filas. Estos valores que faltan se deben limpiar para que el modelo pueda analizar los datos de manera adecuada. Vamos a quitar todas las filas que tengan valores ausentes. Además, la columna normalized-losses tiene una gran proporción de valores que faltan, por lo que excluiremos esa columna del modelo por completo.
Sugerencia
Limpiar los valores que faltan de los datos de entrada es un requisito previo para usar la mayoría de los módulos.
Primero, se agrega un módulo que quita completamente la columna normalized-losses. A continuación, se agrega otro módulo que quita las filas que tienen datos que faltan.
Escriba select columns en el cuadro de búsqueda de la parte superior de la paleta de módulos para localizar el módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos). Después, arrastre este módulo al lienzo del experimento. Este módulo nos permite seleccionar las columnas de datos que queremos incluir o excluir del modelo.
Conecte el puerto de salida del conjunto de datos Automobile price data (Raw) al puerto de entrada del módulo Select Columns in Dataset.
Haga clic en el módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) y haga clic en Launch column selector (Iniciar el selector de columnas) en el panel Propiedades.
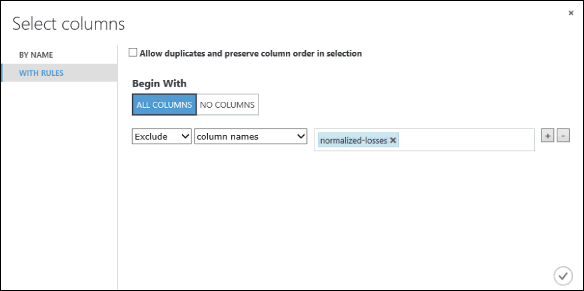
A la izquierda, haga clic en Con reglas
En Empiezan por, haga clic en Todas las columnas. Estas reglas indican a Select Columns in Dataset (Seleccionar columnas en conjunto de datos) que pase por todas las columnas (excepto por las que estamos a punto de excluir).
En los menús desplegables, seleccione Excluir y nombres de columna y luego haga clic en el cuadro de texto. A continuación, se mostrará una lista de columnas. Seleccione normalized-losses; se agregará al cuadro de texto.
Haga clic en el botón Aceptar con la marca de verificación para cerrar el selector de columnas (en la esquina inferior derecha).
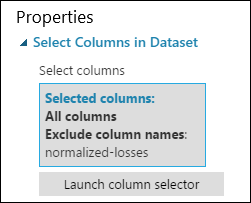
Ahora el panel de propiedades de Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) indica que se pasará por todas las columnas del conjunto de datos excepto normalized-losses.
Sugerencia
Puede agregar un comentario a un módulo; para ello, haga doble clic en el módulo y escriba algún texto. Esto puede ayudarle a ver de un vistazo lo que el módulo hace en el experimento. En este caso, haga doble clic en el módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) y escriba el comentario «Excluir pérdidas normalizadas».
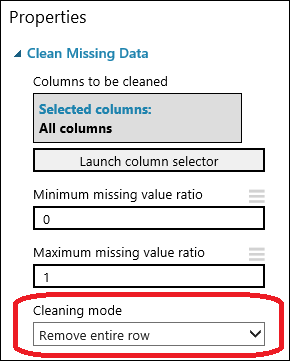
Arrastre el módulo Clean Missing Data al lienzo del experimento y conéctelo con el módulo Select Columns in Dataset. En el panel Propiedades, seleccione Remove entire row (Quitar la fila entera) en Cleaning mode (Modo de limpieza). Estas opciones indican a Clean Missing Data (Limpiar los datos que faltan) que limpie los datos quitando las filas con valores que faltan. Haga doble clic en el módulo y escriba el comentario "Quitar las filas sin valor".
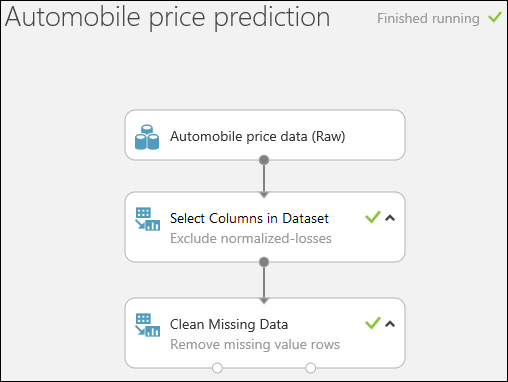
Ejecute el experimento haciendo clic en EJECUTAR en la parte inferior de la página.
Cuando el experimento finalice, todos los módulos tendrán una marca de verificación verde para indicar que se han completado correctamente. Observe también el estado Ejecución finalizada en la esquina superior derecha.
Sugerencia
¿Por qué ejecutamos el experimento ahora? Al ejecutar el experimento, las definiciones de columna de nuestros datos pasan desde el conjunto de datos hasta los módulos Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) y Clean Missing Data (Limpiar los datos que faltan). Esto significa que los módulos que conectamos a Clean Missing Data (Limpiar los datos que faltan) tendrán también esta misma información.
Ahora tenemos datos limpios. Si quiere ver el conjunto de datos limpio, haga clic en el puerto de salida izquierdo del módulo Clean Missing Data (Limpiar los datos que faltan) y seleccione Visualizar. Observe que la columna normalized-losses ya no se incluye y que no hay valores que faltan.
Ahora los datos están limpios y ya puede especificar qué características se van a usar en el modelo predictivo.
Definir las características
En el aprendizaje automático, las características son propiedades mensurables individuales de algo que le interesa. En nuestro conjunto de datos, cada fila representa un automóvil y cada columna es una característica de ese automóvil.
Encontrar un buen conjunto de funciones para la creación de un modelo de predicción requiere experimentación y conocimientos acerca del problema que desea resolver. Algunas características son mejores para la predicción del objetivo que otras. Algunas características tienen una correlación fuerte con otras y se pueden quitar. Por ejemplo, city-mpg y highway-mpg están estrechamente relacionadas así que podemos mantener una y quitar la otra sin que tenga un impacto importante sobre la predicción.
Creemos un modelo que use un subconjunto de las funciones de nuestro conjunto de datos. Puede volver más tarde y seleccionar diferentes características, ejecutar de nuevo el experimento y ver si obtiene mejores resultados. Pero, para empezar, vamos a intentar las siguientes características:
marca, estilo de la carrocería, distancia entre ejes, tamaño del motor, potencia, rpm máximas, consumo en autopista, precio
Arrastre otro módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) al lienzo del experimento. Conecte el puerto de salida izquierdo del módulo Clean Missing Data (Limpiar los datos que faltan) a la entrada del módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos).
Haga doble clic en el módulo y escriba "Seleccionar funciones para la predicción".
Haga clic en Iniciar el selector de columnas en el panel Propiedades.
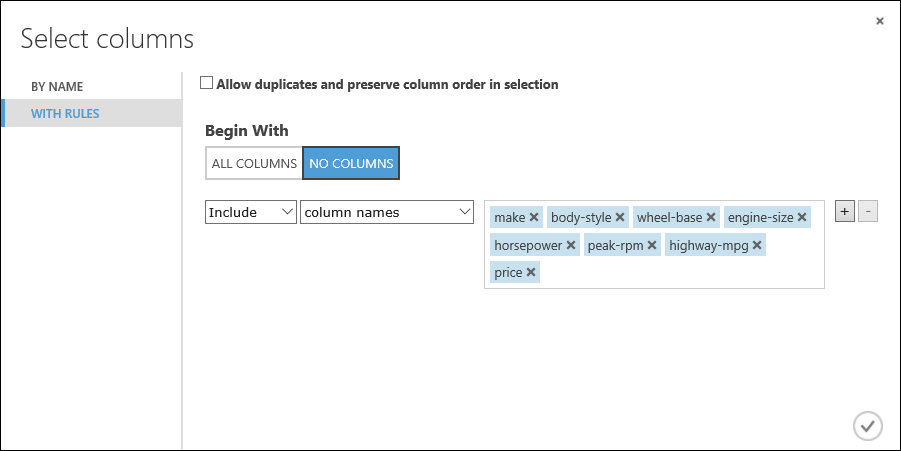
Haga clic en With rules(Con reglas).
En Empezar por, haga clic en No columns (Ninguna columna). En la fila del filtro, seleccione Incluir y nombres de columna y seleccione nuestra lista de nombres de columna en el cuadro de texto. Este filtro indica al módulo que no pase por ninguna columna (características), a excepción de las especificadas.
Haga clic en el botón de marca de verificación (Aceptar).
Este módulo genera un conjunto de datos filtrado que contiene solo las características que queremos pasar al algoritmo de aprendizaje que usaremos en el siguiente paso. Posteriormente puede volver e intentarlo de nuevo con una selección diferente de características.
Elegir y aplicar un algoritmo
Ahora que los datos están listos, la construcción de un modelo predictivo consiste en entrenar y probar. Usaremos nuestros datos para entrenar el modelo y luego probarlo para ver en que medida se aproxima en sus predicciones de los precios.
Clasificación y regresión son dos tipos de algoritmos de aprendizaje automático supervisado. Clasificación predice una respuesta a partir de un conjunto definido de categorías, como el color (rojo, azul o verde). Regresión se usa para predecir un número.
Como queremos predecir un precio, que es un número, usaremos un algoritmo de regresión. En este ejemplo, vamos a usar un modelo de regresión lineal.
Para entrenar el modelo le proporcionamos un conjunto de datos que incluye el precio. El modelo analiza los datos y busca correlaciones entre las características de un automóvil y su precio. A continuación, probaremos el modelo; le daremos un conjunto de características de automóviles con los que estamos familiarizados y veremos si el modelo se acerca en la predicción del precio conocido.
Usaremos nuestros datos para entrenar el modelo y probarlo, para lo cual los dividiremos en conjuntos de datos distintos, de entrenamiento y de prueba.
Seleccione y arrastre el módulo Split Data (Dividir datos) al lienzo del experimento y conéctelo al último módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos).
Haga clic en el módulo Split Data (Dividir datos) para seleccionarlo. Busque Fraction of rows in the first output dataset (Fracción de filas del primer conjunto de datos de salida) (en el panel Propiedades a la derecha de lienzo) y establézcalo en 0,75. De esta forma, usaremos el 75 % de los datos para entrenar el modelo y retendremos el 25 % para prueba.
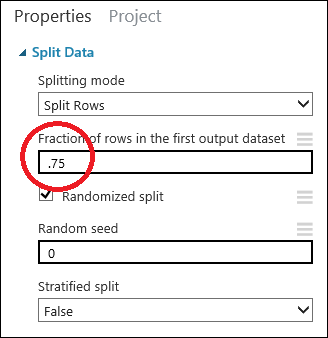
Sugerencia
Al cambiar el parámetro Semilla aleatoria, se pueden producir muestras aleatorias diferentes para el entrenamiento y la prueba. Este parámetro controla la inicialización del generador de números pseudoaleatorios.
Ejecute el experimento. Cuando se ejecuta el experimento, los módulos Select Columns in Dataset (Seleccionar columnas en el conjunto de datos) y Split Data (Dividir datos) pasan las definiciones de columna a los módulos que se agregarán a continuación.
Para seleccionar el algoritmo de aprendizaje, expanda la categoría Machine Learning en la paleta de módulos situada a la izquierda del lienzo y luego expanda Inicializar modelo. Se muestran varias categorías de módulos que se pueden usar para inicializar algoritmos de Aprendizaje automático. Para este experimento, seleccione el módulo Linear Regression (Regresión lineal) en la categoría Regression (Regresión) y arrástrelo al lienzo del experimento. (Otra forma de encontrar el módulo es escribir "regresión lineal" en el cuadro Buscar de la paleta).
Busque y arrastre el módulo Train Model al lienzo del experimento. Conecte la salida del módulo Linear Regression (Regresión lineal) a la entrada izquierda del módulo Train Model (Entrenar modelo) y conecte la salida de datos de entrenamiento (puerto izquierdo) del módulo Split Data (Dividir datos) a la entrada derecha del módulo Train Model (Entrenar modelo).
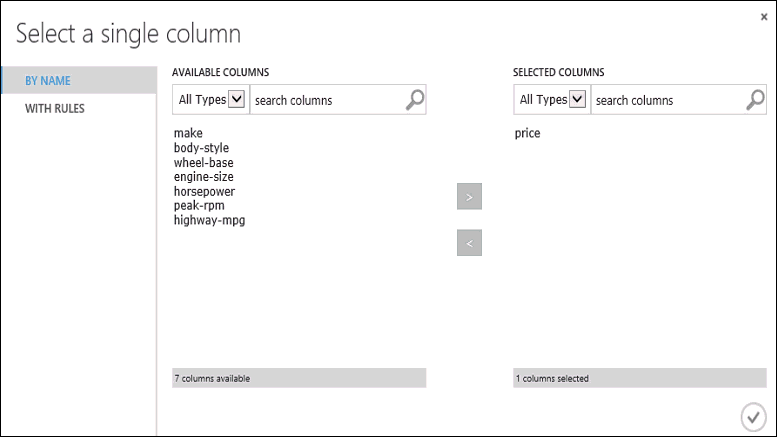
Haga clic en el módulo Train Model, haga clic en Launch column selector en el panel Propiedades y, luego, seleccione la columna price. El precio es el valor que nuestro modelo va a predecir.
Para seleccionar la columna precio en el selector de columnas, muévala de la lista Columnas disponibles a la lista Columnas seleccionadas.
Ejecute el experimento.
Ahora tenemos un modelo de regresión entrenado que puede usarse para puntuar nuevos datos de automóviles para realizar predicciones de precios.
Predecir los precios de los automóviles nuevos
Ahora que hemos entrenado el modelo usando el 75 % de nuestros datos, podemos usarlo para puntuar el otro 25 % de los datos y ver cómo funciona el modelo.
Encuentre y arrastre el módulo Score Model al lienzo del experimento. Conecte la salida del módulo Train Model (Entrenar modelo) al puerto de entrada izquierdo de Score Model (Entrenar modelo). Conecte la salida de los datos de prueba (puerto derecho) del módulo Split Data al puerto de entrada derecho de Score Model.
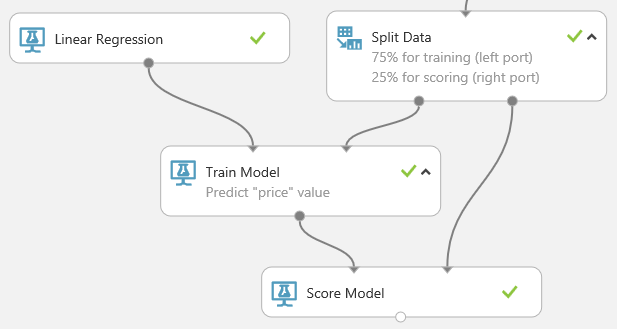
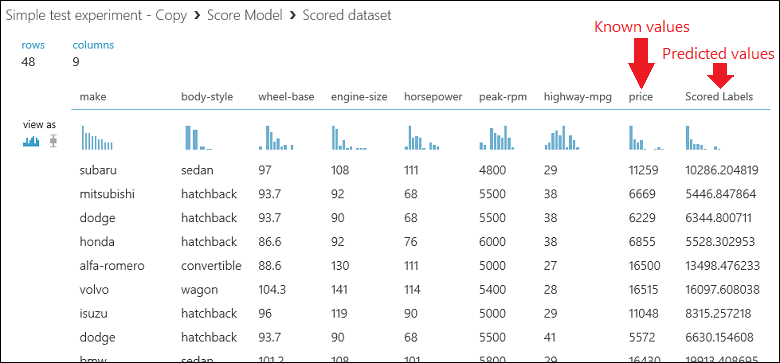
Para ejecutar el experimento y ver la salida desde el módulo Score Model (Puntuar modelo), haga clic en el puerto de salida de Score Model (Puntuar modelo) y seleccione Visualizar. La salida muestra los valores previstos para el precio y los valores conocidos de los datos de prueba.
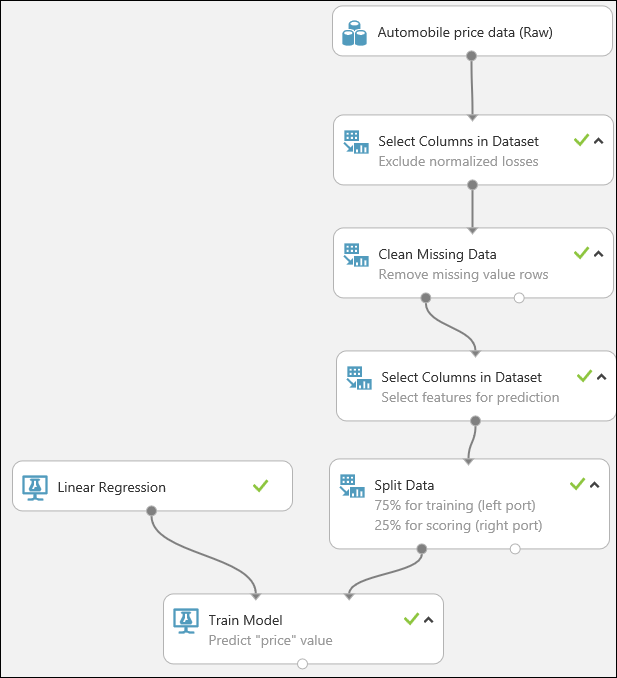
Por último, probamos la calidad de los resultados. Seleccione y arrastre el módulo Evaluate Model (Evaluar modelo) al lienzo del experimento y conecte la salida del módulo Score Model (Puntuar modelo) a la entrada izquierda del módulo Evaluate Model (Evaluar modelo). El experimento final debe tener un aspecto similar a este:
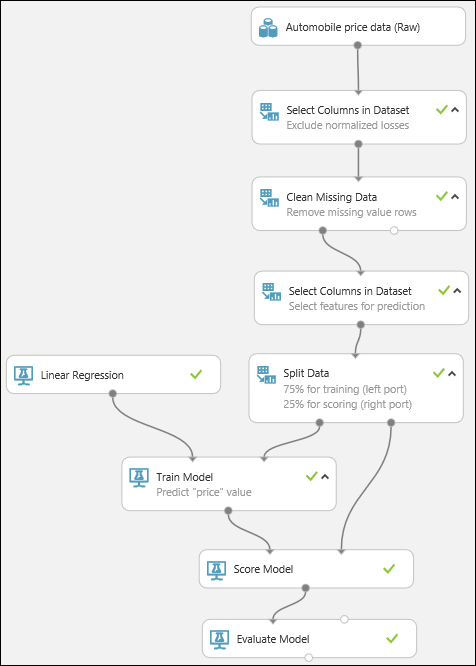
Ejecute el experimento.
Para ver la salida del módulo Evaluate Model (Evaluar modelo), haga clic en el puerto de salida y seleccione Visualizar.
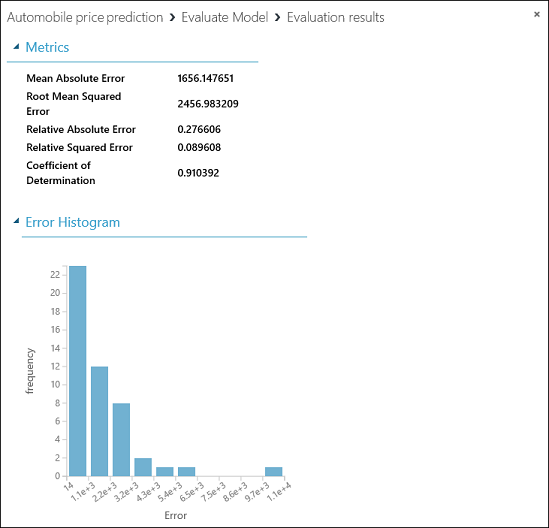
Se muestran las siguientes estadísticas para nuestro modelo:
- Desviación media (MAE): la media de errores absolutos (un error es la diferencia entre el valor de predicción y el valor real).
- Error cuadrático medio (RMSE): la raíz cuadrada de la media de los errores al cuadrado de las predicciones realizadas sobre el conjunto de datos de prueba.
- Error absoluto relativo: la media de errores absolutos en relación con la diferencia absoluta entre los valores reales y la media de todos los valores reales.
- Error al cuadrado relativo: la media de errores al cuadrado en relación con la diferencia al cuadrado entre los valores reales y la media de todos los valores reales.
- Coeficiente de determinación: conocido también como valor R cuadrado, es una métrica estadística que indica cómo de bien se ajusta un modelo a los datos.
Para cada una de las estadísticas de errores, cuanto menor sea el valor, mejor. Un valor inferior indica que las predicciones se ajustan más a los valores reales. En Coeficiente de determinación, cuanto más cercano sea su valor a uno (1,0), mejores son las predicciones.
Limpieza de recursos
Si ya no necesita los recursos que creó en este artículo, elimínelos para evitar incurrir en cualquier cargo. Aprenda a hacerlo en el artículo sobre la Exportación y eliminación de datos de usuario integrados.
Pasos siguientes
En este inicio rápido, ha creado un experimento sencillo con un conjunto de datos de ejemplo. Para explorar el proceso de creación e implementación de un modelo en mayor profundidad, continúe con el tutorial de soluciones predictivas.