Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Machine Learning es un servicio en la nube que acelera y administra el ciclo de vida del proyecto de aprendizaje automático (ML). Los profesionales de ML, científicos de datos e ingenieros lo usan en sus flujos de trabajo diarios para entrenar e implementar modelos y administrar operaciones de aprendizaje automático (MLOps).
Puede crear un modelo en Machine Learning o usar un modelo creado a partir de una plataforma de código abierto, como PyTorch, TensorFlow o scikit-learn. Las herramientas de MLOps le ayudan a supervisar, volver a entrenar y volver a implementar modelos.
Sugerencia
Evaluación gratuita Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning. Puede obtener créditos para gastarlos en servicios de Azure. Después de usar los créditos, puede mantener la cuenta y usar los servicios gratuitos de Azure. La tarjeta de crédito no se cobra a menos que cambie explícitamente la configuración y pida que se le cobre.
¿Para quién es Azure Machine Learning?
Machine Learning es para individuos y equipos que implementan MLOps dentro de su organización para que los modelos de aprendizaje automático lleguen a producción en un entorno de producción seguro y auditable.
Los científicos de datos y los ingenieros de aprendizaje automático pueden usar herramientas para acelerar y automatizar sus flujos de trabajo diarios. Los desarrolladores de aplicaciones pueden usar herramientas para integrar modelos en aplicaciones o servicios. Los desarrolladores de plataformas pueden usar un sólido conjunto de herramientas, respaldado con API duraderas de Azure Resource Manager, para crear herramientas de ML avanzadas.
Las empresas que trabajan en la nube de Microsoft Azure pueden usar una seguridad conocida y el control de acceso basado en rol para la infraestructura. Puede configurar un proyecto para denegar el acceso a los datos protegidos y seleccionar operaciones.
Productividad para todos los miembros del equipo
A menudo, los proyectos de aprendizaje automático requieren un equipo con diversas capacidades para crear y mantener. Machine Learning tiene herramientas que le permiten:
Colaborar con el equipo mediante cuadernos, recursos de proceso, procesos sin servidor, datos y entornos compartidos
Desarrollo de modelos de equidad y explicación, seguimiento y auditoría para cumplir los requisitos de cumplimiento de linaje y auditoría
Implementar modelos de ML de forma rápida y sencilla a gran escala, y administrarlos y controlarlos de forma eficaz con MLOps.
Ejecutar cargas de trabajo de aprendizaje automático en cualquier lugar con gobernanza, seguridad y cumplimiento integrados.
Herramientas compatibles multiplataforma que satisfagan sus necesidades
Cualquier persona de un equipo de ML puede usar sus herramientas preferidas para realizar el trabajo. Independientemente de si está ejecutando experimentos rápidos, ajuste de hiperparámetros, creación de canalizaciones o administración de inferencias, puede usar interfaces conocidas, entre las que se incluyen:
- Azure Machine Learning Studio
- SDK de Python (v2)
- CLI de Azure (v2)
- API REST de Azure Resource Manager
A medida que refina el modelo y colabora con otros usuarios en el resto del ciclo de desarrollo de Machine Learning, puede compartir y buscar activos, recursos y métricas para los proyectos en la interfaz de usuario de Machine Learning Studio.
Estudio
Machine Learning Studio ofrece varias experiencias de creación en función del tipo de proyecto y nivel de la experiencia de aprendizaje automático anterior, sin necesidad de instalar nada.
Notebooks: escriba y ejecute código propio en servidores de Jupyter Notebook administrados integrados directamente en Estudio. O bien, abra los cuadernos en VS Code, en la web o en el escritorio.
Visualización de métricas de ejecución: analice y optimice los experimentos con la visualización.
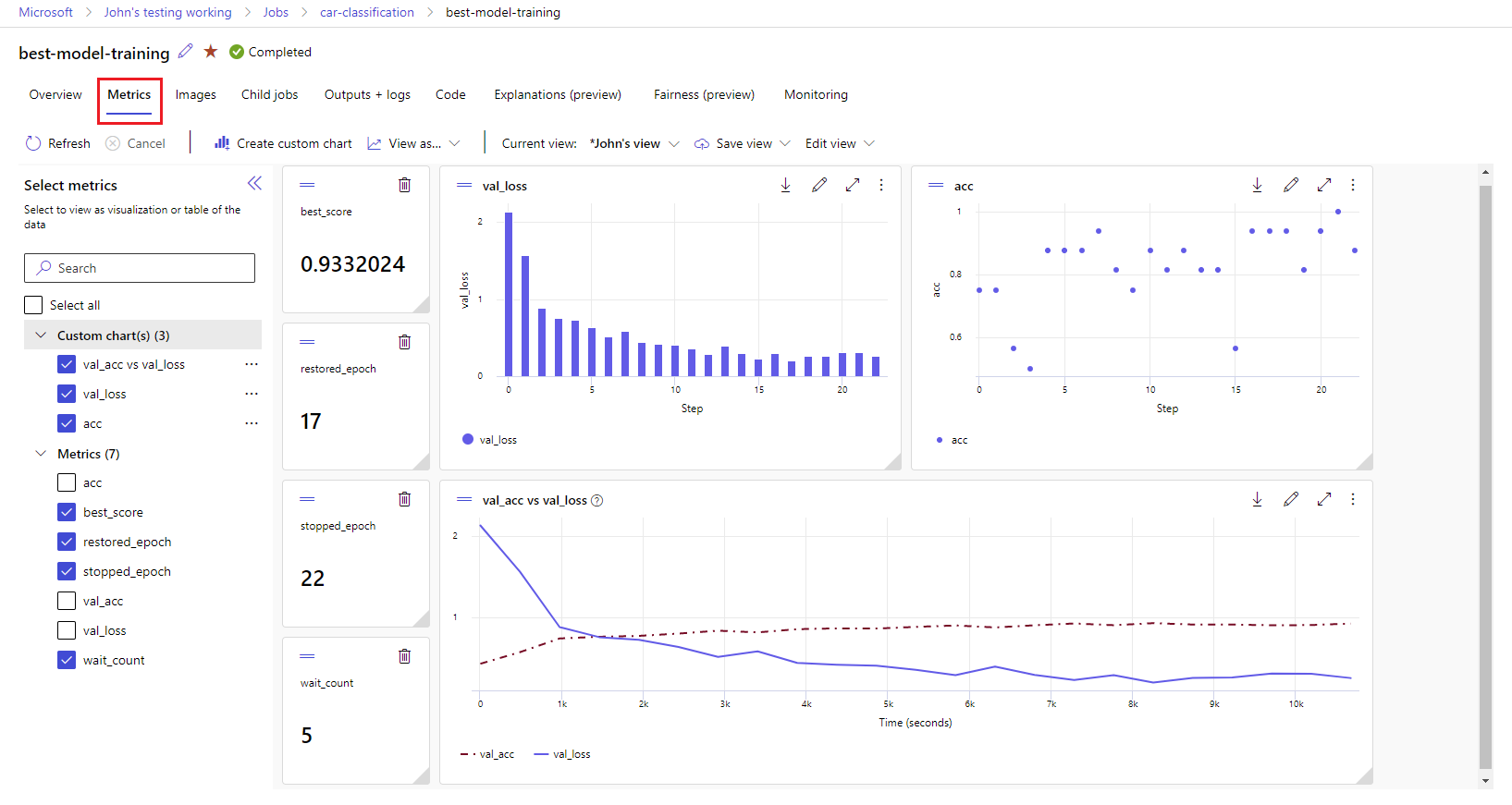
Diseñador de Azure Machine Learning: use el diseñador para entrenar e implementar modelos de Machine Learning sin necesidad de escribir código. Arrastre y coloque conjuntos de datos y componentes para crear canalizaciones de Machine Learning.
Interfaz de usuario de aprendizaje automático automatizado: aprenda a crear experimentos de aprendizaje automático automatizado con una interfaz fácil de usar.
Etiquetado de datos: use el etiquetado de datos de Azure Machine Learning para coordinar eficazmente los proyectos de etiquetado de imágenes o etiquetado de texto.
Trabajar con LLM e IA generativa
Azure Machine Learning incluye herramientas para ayudarle a crear aplicaciones de IA generativa con tecnología de modelos de lenguaje grandes (LLM). La solución incluye un catálogo de modelos, un flujo de avisos y un conjunto de herramientas para simplificar el ciclo de desarrollo de las aplicaciones de inteligencia artificial.
Tanto Estudio de Azure Machine Learning como Microsoft Foundry le permiten trabajar con LLMs. Use esta guía para determinar qué estudio debe usar.
Catálogo de modelo
El catálogo de modelos de Estudio de Azure Machine Learning es un centro en el que podrá descubrir y usar una amplia gama de modelos que le permitirán crear aplicaciones de inteligencia artificial generativa. El catálogo de modelos incluye cientos de modelos de proveedores de modelos, como Azure OpenAI Service, Mistral, Meta, Cohere, NVIDIA y Hugging Face, incluidos los modelos entrenados por Microsoft. Los modelos de proveedores distintos de Microsoft son Productos que no son de Microsoft, tal como se define en los Términos de producto de Microsoft, y están sujetos a los términos proporcionados con el modelo.
Flujo de avisos
El flujo de mensajes de Azure Machine Learning es una herramienta de desarrollo diseñada para simplificar todo el ciclo de desarrollo de aplicaciones de inteligencia artificial con tecnología de modelos de lenguaje grandes (LLM). El flujo de avisos proporciona una solución completa que simplifica el proceso de creación de prototipos, experimentación, iteración e implementación de las aplicaciones de inteligencia artificial.
Preparación y seguridad de la empresa
Machine Learning se integra con la plataforma en la nube de Azure para agregar seguridad a los proyectos de ML.
Las integraciones de seguridad incluyen:
- Redes virtuales de Azure con grupos de seguridad de red
- Azure Key Vault, donde puede guardar secretos de seguridad, como la información de acceso para las cuentas de almacenamiento
- Configuración de Azure Container Registry detrás de una red virtual
Para más información, vea Tutorial: Configuración de un área de trabajo seguro.
Integraciones de Azure para soluciones completas
Otras integraciones con los servicios de Azure admiten un proyecto de ML integral. Incluyen:
- Azure Synapse Analytics, para procesar y transmitir datos con Spark
- Azure Arc, donde puede ejecutar servicios de Azure en un entorno de Kubernetes
- Opciones de almacenamiento y base de datos, como Azure SQL Database y Azure Blob Storage
- Azure App Service, para implementar y administrar aplicaciones con tecnología de aprendizaje automático
- Microsoft Purview, para detectar y catalogar recursos de datos en toda la organización
Importante
Azure Machine Learning no almacena ni procesa los datos fuera de la región donde se realiza la implementación.
Flujo de trabajo del proyecto de aprendizaje automático
Normalmente, los modelos se desarrollan como parte de un proyecto con varios objetivos. Los proyectos suelen implicar a más de una persona. Al experimentar con datos, algoritmos y modelos, el desarrollo es iterativo.
Ciclo de vida del proyecto
El ciclo de vida del proyecto puede variar según el proyecto, pero a menudo es similar a este diagrama.
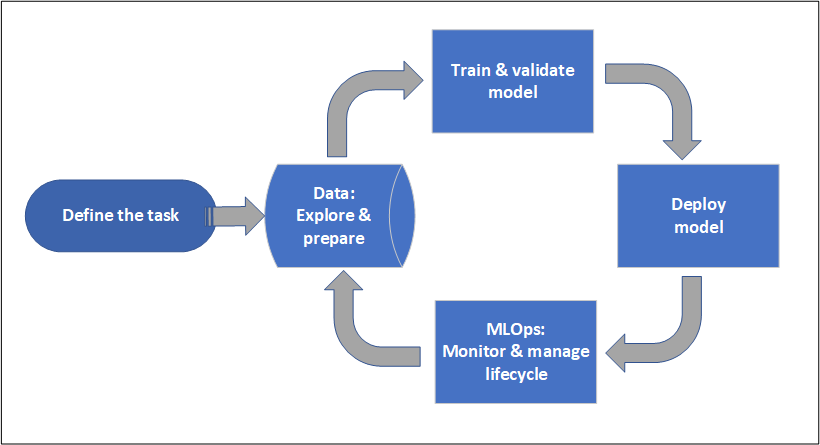
Un área de trabajo organiza un proyecto y permite la colaboración para muchos usuarios que trabajan con un objetivo común. Los usuarios de un área de trabajo pueden compartir fácilmente los resultados de sus ejecuciones de experimentación en la interfaz de usuario de Estudio. O bien, pueden usar recursos con versiones para trabajos como entornos y referencias de almacenamiento.
Para obtener más información, consulte Administrar áreas de trabajo de Azure Machine Learning.
Cuando un proyecto está listo para ponerse en marcha, el trabajo de los usuarios se puede automatizar en una canalización de ML y desencadenarse según una programación o una solicitud HTTPS.
Puede implementar los modelos en la solución de inferencia administrada, tanto en tiempo real como por lotes, lo que simplifica la administración de la infraestructura que suele ser necesaria para implementar los modelos.
Entrenamiento de modelos
En Azure Machine Learning, puede ejecutar el script de entrenamiento en la nube o crear un modelo desde cero. A menudo, los clientes incorporan modelos que han creado y entrenado en marcos de código abierto, a fin de ponerlos en marcha en la nube.
Abierto e interoperable
Los científicos de datos pueden usar modelos en Azure Machine Learning que han creado en marcos comunes de Python, como:
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- LightGBM
También se admiten otros lenguajes y marcos:
- R
- .NET
Para más información, vea Integración de código abierto con Azure Machine Learning.
Caracterización automatizada y selección de algoritmos
En el aprendizaje automático clásico, los científicos de datos usan experiencia previa e intuición para seleccionar la caracterización y el algoritmo de datos adecuados para el entrenamiento en un proceso repetitivo y lento. El aprendizaje automático automatizado (AutoML) acelera este proceso. Puede usarlo desde la interfaz de usuario de Estudio de Azure Machine Learning o el SDK de Python.
Para más información, vea ¿Qué es el aprendizaje automático automatizado?
Optimización de hiperparámetros
La optimización de los hiperparámetros, o el ajuste de los hiperparámetros, puede ser una tarea tediosa. Machine Learning puede automatizar esta tarea para comandos con parámetros arbitrarios con poca modificación en la definición del trabajo. Los resultados se visualizan en el Estudio.
Para más información, vea Ajuste de hiperparámetros.
Entrenamiento distribuido de varios nodos
La eficacia del entrenamiento para el aprendizaje profundo y, a veces, los trabajos de aprendizaje automático clásicos se pueden mejorar drásticamente a través del entrenamiento distribuido con varios nodos. Los clústeres de proceso de Azure Machine Learning y los procesos sin servidor ofrecen las opciones de GPU más recientes.
Se admite mediante Kubernetes de Azure Machine Learning, clústeres de proceso de Azure Machine Learning y procesos sin servidor:
- PyTorch
- TensorFlow
- MPI
Puede usar la distribución de MPI para Horovod o lógica personalizada de varios nodos. Apache Spark se admite mediante el proceso de Spark sin servidor y el grupo de Spark de Synapse conectado que usan los clústeres de Spark de Azure Synapse Analytics.
Para más información, vea Entrenamiento distribuido con Azure Machine Learning.
Entrenamiento perfectamente paralelo
Es posible que para el escalado de un proyecto de ML sea necesario escalar el entrenamiento de modelos perfectamente paralelos. Este patrón es común en escenarios como los de previsión de la demanda, donde se puede entrenar un modelo para muchos almacenes.
Implementación de modelos
Para incorporar un modelo a producción, se debe implementar el modelo. Los puntos de conexión administrados de Azure Machine Learning abstraen la infraestructura necesaria para la puntuación de modelos (inferencia) por lotes o en tiempo real (en línea).
Puntuación por lotes y en tiempo real (inferencia)
La puntuación por lotes o la inferencia por lotes implica invocar un punto de conexión con una referencia a los datos. El punto de conexión por lotes ejecuta trabajos de forma asincrónica para procesar datos en paralelo en clústeres de proceso y almacenarlos para su posterior análisis.
La puntuación en tiempo real, o la inferencia en línea, consiste en invocar un punto de conexión con una o más implementaciones de modelos y recibir una respuesta en tiempo casi real mediante HTTPS. El tráfico se puede dividir en varias implementaciones, lo que permite probar nuevas versiones del modelo, desviar inicialmente cierta cantidad de tráfico y aumentarlo después de establecer la confianza en el nuevo modelo.
Para más información, consulte:
- Implementación de un modelo con un punto de conexión administrado en tiempo real
- Uso de puntos de conexión por lotes para la puntuación
MLOps: DevOps para aprendizaje automático
DevOps para modelos de ML, a menudo denominado MLOps, es un proceso para desarrollar modelos para la fase de producción. El ciclo de vida de un modelo desde el entrenamiento hasta la implementación debe ser auditable si no se puede reproducir.
Ciclo de vida del modelo de ML
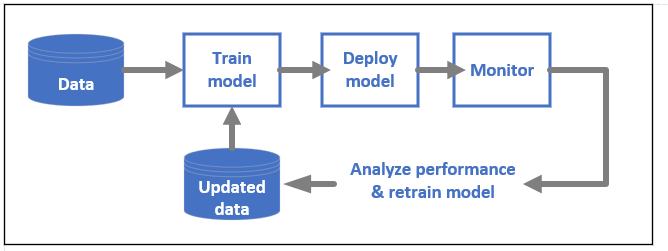
Obtenga más información sobre MLOps en Azure Machine Learning.
Integraciones que habilitan MLOps
Machine Learning se ha creado teniendo en cuenta el ciclo de vida de los modelos. Incluso puede auditar una confirmación y un entorno específicos del ciclo de vida de los modelos.
Algunas características clave que habilitan MLOps incluyen:
- Integración de Git
- Integración de MLflow
- Programación de la canalización de aprendizaje automático
- Integración de Azure Event Grid para desencadenadores personalizados
- Facilidad de uso con herramientas de CI/CD como Acciones de GitHub o Azure DevOps
Además, Machine Learning incluye características para supervisión y auditoría:
- Artefactos de trabajo, como instantáneas de código, registros y otras salidas
- Linaje entre trabajos y recursos, como contenedores, datos y recursos de proceso
Si usa Apache Airflow, el paquete airflow-provider-azure-machinelearning es un proveedor que le permite enviar flujos de trabajo a Azure Machine Learning desde Apache Airflow.
Contenido relacionado
Empiece a usar Azure Machine Learning: