Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Machine Learning Studio (clásico)
Machine Learning Studio (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning en esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte información sobre cómo mover proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información sobre Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
Para usar sus propios datos en Machine Learning Studio (clásico) para desarrollar y entrenar una solución de análisis predictivo, puede usar los datos de:
- Archivo local : cargue los datos locales con antelación desde el disco duro para crear un módulo de conjunto de datos en el área de trabajo.
- Orígenes de datos en línea: use el módulo Importar datos para acceder a datos de uno de varios orígenes en línea mientras se ejecuta el experimento.
- Experimento de Machine Learning Studio (clásico): uso de datos guardados como un conjunto de datos en Machine Learning Studio (clásico)
- Base de datos de SQL Server : uso de datos de una base de datos de SQL Server sin tener que copiar datos manualmente
Nota:
Existe una gran variedad de conjuntos de datos de ejemplo disponibles en Machine Learning Studio (clásico) que puede usar como datos de aprendizaje. Para obtener información sobre ellos, consulte Uso de los conjuntos de datos de ejemplo en Machine Learning Studio (clásico).
Preparación de los datos
Machine Learning Studio (clásico) está diseñado para trabajar con datos rectangulares o tabulares, como datos de texto delimitados o datos estructurados de una base de datos, aunque en algunas circunstancias, es posible usar datos no rectangulares.
Es mejor si los datos están relativamente limpios antes de importarlos a Studio (clásico). Por ejemplo, conviene tener cuidado de cuestiones como cadenas sin comillas.
Sin embargo, hay módulos disponibles en Studio (clásico) que le permitirán manipular levemente los datos en el experimento después de importar los datos. Dependiendo de los algoritmos de aprendizaje automático que usará, es posible que deba decidir cómo controlar los problemas estructurales de los datos, como valores que faltan y datos esparcidos y existen módulos que pueden ayudar en esto. Busque en la sección Transformación de datos de la paleta de módulos para los módulos que realizan estas funciones.
En cualquier momento del experimento, puede ver o descargar los datos que genera un módulo con un clic en el puerto de salida. Dependiendo del módulo, es posible que haya distintas opciones de descarga disponibles, o bien que se puedan visualizar los datos dentro del explorador web en Studio (clásico).
Formatos y tipos de datos admitidos
Puede importar diversos tipos de datos al experimento, dependiendo del mecanismo que usa para importar los datos y de dónde provienen estos:
- Texto sin formato (.txt)
- Valores separados por coma (CSV) con un encabezado (.csv) o sin encabezado (.nh.csv)
- Valores separados con tabulaciones (TSV) con un encabezado (.tsv) o sin encabezado (.nh.tsv)
- Archivo de Excel
- Tabla de Azure
- Tabla de Hive
- Tabla de Base de datos SQL
- Valores de OData
- Datos de SVMLight (.svmlight) (consulte la definición de SVMLight para obtener información de formato)
- Datos de formato de archivo de relación de atributos (ARFF) (.arff) (vea la definición ARFF para obtener información de formato)
- Archivo ZIP (.zip)
- Archivo de área de trabajo u objeto de R (.RData)
Si importa datos en un formato como ARFF que incluyan metadatos, Studio (clásico) usa estos metadatos para definir el tipo de datos y encabezado de cada columna.
Si importa datos en formato TSV o CSV que no incluyan estos metadatos, Studio (clásico) infiere el tipo de datos de cada columna tomando una muestra de estos. Si los datos tampoco tienen encabezados de columna, Studio (clásico) proporciona nombres predeterminados.
Puede especificar o cambiar explícitamente los encabezados y los tipos de datos de las columnas mediante el módulo Editar metadatos .
Studio (clásico) reconoce los siguientes tipos de datos:
- Cadena
- Entero
- Doble
- Booleano
- Fecha y hora
- TimeSpan
Studio usa un tipo de datos interno denominado tabla de datos para pasar datos entre módulos. Puede convertir explícitamente los datos en formato de tabla de datos mediante el módulo Convertir en conjunto de datos .
Todo módulo que acepta formatos distintos de tabla de datos convertirá los datos a tabla de datos de manera silenciosa antes de pasarlos al módulo siguiente.
En caso de ser necesario, puede convertir el formato tabla de datos de vuelta al formato CSV, TSV, ARFF o SVMLight mediante otros módulos de conversión. Busque en la sección Conversiones de formato de datos de la paleta de módulos para los módulos que realizan estas funciones.
Capacidades de datos
Los módulos en Machine Learning Studio (clásico) admiten conjuntos de datos de hasta 10 GB de datos numéricos densos para casos de uso comunes. Si un módulo ocupa más de una entrada, el valor de 10 GB es el total de todos los tamaños de entrada. Puede realizar el muestreo de conjuntos de datos grandes mediante consultas de Hive o Azure SQL Database, o bien usar el procesamiento previo de aprendizaje por recuentos antes de la importación de los datos.
Los siguientes tipos de datos se pueden expandir en conjuntos de datos grandes durante la normalización de características y están limitados a menos de 10 GB:
- Disperso
- Categorías
- Cadenas
- Datos binarios
Los siguientes módulos están limitados a conjuntos de datos de menos de 10 GB:
- Módulos de recomendación.
- Módulo Synthetic Minority Oversampling Technique (SMOTE)
- Módulos de script: R, Python y SQL
- Módulos donde el tamaño de los datos de salida puede ser mayor que el tamaño de los datos de entrada, como en la aplicación de hash de característica o unión.
- Validación cruzada, ajuste de los hiperparámetros del modelo, regresión ordinal y multiclase uno contra todos, cuando el número de iteraciones sea muy grande.
En el caso de conjuntos de datos que tengan más de 2 GB, cargue los datos en Azure Storage o Azure SQL Database, o use Azure HDInsight, en lugar de cargarlos directamente desde el archivo local.
Puede encontrar información sobre los datos de imagen en la referencia del módulo Importar imágenes .
Importación desde un archivo local
Puede cargar un archivo de datos desde la unidad de disco duro para usar como datos de entrenamiento en Studio (clásico). Al importar un archivo de datos, crea un módulo de conjunto de datos listo para usar en los experimentos del área de trabajo.
Para importar datos desde una unidad de disco duro local, siga estos pasos:
- Haga clic en +NUEVO en la parte inferior de la ventana de Studio (clásico).
- Seleccione DATASET y FROM LOCAL FILE.
- En el cuadro de diálogo Cargar un nuevo conjunto de datos , vaya al archivo que desea cargar.
- Escriba un nombre, identifique el tipo de datos y, si lo desea, escriba una descripción. Se recomienda incluir una descripción: le permite registrar cualquier característica acerca de los datos que quiera recordar cuando use los datos en el futuro.
- La casilla Esta es la nueva versión de un conjunto de datos existente que permite actualizar un conjunto de datos existente con nuevos datos. Para ello, haga clic en esta casilla y, luego, escriba el nombre de un conjunto de datos existente.
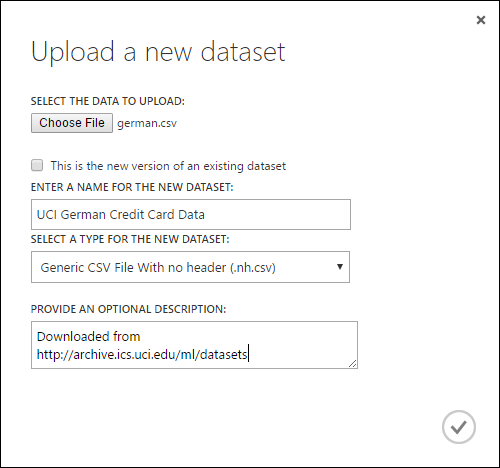
El tiempo de la carga dependerá del tamaño de los datos y de la velocidad de conexión con el servicio. Si sabe que el archivo tardará mucho tiempo en cargarse, puede realizar otras operaciones en Studio(clásico) mientras espera. Sin embargo, si cierra el explorador antes de que se complete la carga de datos, la carga genera un error.
Una vez que los datos estén cargados, se almacenan en un módulo de conjunto de datos y se encontrarán disponibles para cualquier experimento que se realice en su área de trabajo.
Al editar un experimento, puede encontrar los conjuntos de datos que ha cargado en la lista Mis conjuntos de datos en la lista Conjuntos de datos guardados de la paleta de módulos. Puede arrastrar y colocar el conjunto de datos en el lienzo de experimento cuando desee usarlo para profundizar en su análisis o para Machine Learning.
Importación desde orígenes de datos en línea
Con el módulo Importar datos , el experimento puede importar datos de varios orígenes de datos en línea mientras se ejecuta el experimento.
Nota:
En este artículo se proporciona información general sobre el módulo Importar datos . Para obtener información más detallada sobre los tipos de datos a los que puede acceder, dar formatos, parámetros y respuestas a preguntas comunes, consulte el tema de referencia del módulo para el módulo Importar datos .
Mediante el módulo Importar datos , puede acceder a datos desde uno de varios orígenes de datos en línea mientras se ejecuta el experimento:
- Una dirección URL web con HTTP
- Hadoop con HiveQL
- Almacenamiento de blobs de Azure
- Tabla de Azure
- Azure SQL Database. SQL Managed Instance o SQL Server
- Un proveedor de fuentes de datos, actualmente OData
- Azure Cosmos DB (la base de datos de Azure Cosmos)
Dado que se tiene acceso a estos datos de entrenamiento mientras se está ejecutando el experimento, solo están disponibles en ese experimento. En comparación, los datos que estén almacenados en módulos de conjunto de datos se encontrarán disponibles para cualquier experimento que se haga en su área de trabajo.
Para acceder a orígenes de datos en línea en el experimento de Studio (clásico), agregue el módulo Importar datos al experimento. A continuación, seleccione Iniciar asistente para importar datos en Propiedades para obtener instrucciones guiadas paso a paso para seleccionar y configurar el origen de datos. Como alternativa, puede seleccionar manualmente Origen de datos en Propiedades y proporcionar los parámetros necesarios para acceder a los datos.
Los orígenes de datos en línea admitidos se muestran en la tabla siguiente. Esta tabla también resume los formatos de archivo admitidos y los parámetros usados para tener acceso a los datos.
Importante
Actualmente, los módulos Importar datos y Exportar datos solo pueden leer y escribir datos de Azure Storage creados mediante el modelo de implementación clásica. Es decir, todavía no se admite el nuevo tipo de cuenta de Azure Blob Storage que ofrece un nivel de acceso frecuente o esporádico al almacenamiento.
Por lo general, las cuentas de almacenamiento de Azure que podría haber creado antes de que esta opción de servicio estuviera disponible no deberían verse afectadas. Si necesita crear una cuenta, seleccione Clásico para el modelo de implementación o use Resource Manager y seleccione Uso general en lugar de Almacenamiento de blobs para Tipo de cuenta.
Para más información, consulte Azure Blob Storage: Niveles de almacenamiento caliente y frío.
Orígenes de datos en línea admitidos
El módulo Importar datos de Machine Learning Studio (clásico) admite los siguientes orígenes de datos:
| Origen de datos | Descripción | Parámetros |
|---|---|---|
| Dirección URL web a través de HTTP | Lee datos en valores separados por comas (CSV), valores separados por tabulaciones (TSV), formato de archivo de atributo-relación (ARFF) y formatos de máquinas de vectores de soporte (SVM-light), desde cualquier dirección URL web que use HTTP |
DIRECCIÓN URL: especifica el nombre completo del archivo, incluida la dirección URL del sitio y el nombre de archivo, con cualquier extensión. Formato de datos: especifica uno de los formatos de datos admitidos: CSV, TSV, ARFF o SVM-light. Si los datos tienen una fila de encabezado, esta se usa para asignar nombres de columna. |
| Hadoop/HDFS | Lee datos de almacenamiento distribuido de Hadoop. Especifique los datos que desee mediante HiveQL, un lenguaje de consulta similar a SQL. HiveQL también se puede usar para agregar datos y realizar un filtrado de datos antes de agregarlos a Studio (clásico). |
Consulta de base de datos de Hive: especifica la consulta de Hive que se usa para generar los datos. URI del servidor HCatalog : Especifique el nombre de su clúster usando el formato <su nombre de clúster>.azurehdinsight.net. Nombre de cuenta de usuario de Hadoop: especifica el nombre de la cuenta de usuario de Hadoop que se usa para aprovisionar el clúster. Contraseña de la cuenta de usuario de Hadoop : especifica las credenciales que se usan al aprovisionar el clúster. Para más información, consulte Creación de clústeres de Hadoop en HDInsight. Ubicación de los datos de salida: especifica si los datos se almacenan en un sistema de archivos distribuido de Hadoop (HDFS) o en Azure.
Si almacena los datos de salida en Azure, debe especificar el nombre de cuenta de Azure Storage, la clave de acceso a Storage y el nombre del contenedor de Storage. |
| Base de datos SQL | Lee los datos almacenados en una base de datos de Azure SQL Database, SQL Managed Instance o SQL Server que se ejecuta en una máquina virtual de Azure. |
Nombre del servidor de base de datos: especifica el nombre del servidor en el que se ejecuta la base de datos.
En el caso de un servidor SQL server hospedado en una máquina virtual de Azure , escriba tcp:<Nombre DNS> de máquina virtual, 1433 Nombre de la base de datos : especifica el nombre de la base de datos en el servidor. Nombre de cuenta de usuario del servidor: especifica un nombre de usuario para una cuenta que tiene permisos de acceso para la base de datos. Contraseña de la cuenta de usuario del servidor: especifica la contraseña de la cuenta de usuario. Consulta de base de datos: escriba una instrucción SQL que describa los datos que desea leer. |
| SQL Database local | Lee los datos almacenados en una bases de datos SQL. |
Puerta de enlace de datos: especifica el nombre de la Puerta de enlace de gestión de datos instalada en un equipo en el que puede acceder a la base de datos de SQL Server. Para obtener información sobre cómo configurar la puerta de enlace, consulte Realización de análisis avanzados con Machine Learning Studio (clásico) mediante datos de un servidor SQL Server. Nombre del servidor de base de datos: especifica el nombre del servidor en el que se ejecuta la base de datos. Nombre de la base de datos : especifica el nombre de la base de datos en el servidor. Nombre de cuenta de usuario del servidor: especifica un nombre de usuario para una cuenta que tiene permisos de acceso para la base de datos. Nombre de usuario y contraseña: haga clic en Escribir valores para escribir las credenciales de la base de datos. Puede usar la autenticación integrada de Windows o la autenticación de SQL Server según la configuración de SQL Server. Consulta de base de datos: escriba una instrucción SQL que describa los datos que desea leer. |
| tabla de Azure | Lee los datos de Table service en Azure Storage. Si se leen grandes cantidades de datos con poca frecuencia, use el servicio Tabla de Azure. Proporciona una solución de almacenamiento flexible, no relacional (No SQL), escalable a gran escala, económica y de alta disponibilidad. |
Las opciones de Importación de datos cambian en función de si tiene acceso a información pública o a una cuenta de almacenamiento privada que requiere credenciales de inicio de sesión. Esto viene determinado por el tipo de autenticación que puede tener el valor "PublicOrSAS" o "Account", cada uno de los cuales tiene su propio conjunto de parámetros. URI de firma de acceso público o compartido (SAS): los parámetros son:
Especifica las filas que se van a escanear para nombres de propiedad: los valores son TopN para examinar el número especificado de filas o ScanAll para obtener todas las filas de la tabla. Si los datos son homogéneos y predecibles, se recomienda seleccionar TopN y escribir un número para N. En el caso de las tablas grandes, esto puede dar lugar a tiempos de lectura más rápidos. Si los datos están estructurados con conjuntos de propiedades que varían en función de la profundidad y la posición de la tabla, elija la opción ScanAll para examinar todas las filas. Esto garantiza la integridad de la propiedad resultante y la conversión de metadatos.
Clave de cuenta: especifica la clave de almacenamiento asociada a la cuenta. Nombre de tabla : especifica el nombre de la tabla que contiene los datos que se van a leer. Filas a escanear para nombres de propiedad: los valores son TopN para examinar el número especificado de filas, o ScanAll para obtener todas las filas de la tabla. Si los datos son homogéneos y predecibles, se recomienda seleccionar TopN y escribir un número para N. En el caso de las tablas grandes, esto puede dar lugar a tiempos de lectura más rápidos. Si los datos están estructurados con conjuntos de propiedades que varían en función de la profundidad y la posición de la tabla, elija la opción ScanAll para examinar todas las filas. Esto garantiza la integridad de la propiedad resultante y la conversión de metadatos. |
| Azure Blob Storage (Servicio de almacenamiento de blobs de Azure) | Lee los datos almacenados en Blob service en Azure Storage, incluidos imágenes, texto no estructurado o datos binarios. Puede usar Blob service para exponer datos públicamente o para almacenar datos de aplicación de forma privada. Puede tener acceso a los datos desde cualquier lugar a través de conexiones HTTP o HTTPS. |
Las opciones del módulo Importar datos cambian en función de si está accediendo a la información pública o a una cuenta de almacenamiento privada que requiere credenciales de inicio de sesión. Esto viene determinado por el tipo de autenticación que puede tener un valor de "PublicOrSAS" o de "Account". URI de firma de acceso público o compartido (SAS): los parámetros son:
Formato de archivo: especifica el formato de los datos en Blob service. Los formatos compatibles son CSV, TSV y ARFF.
Clave de cuenta: especifica la clave de almacenamiento asociada a la cuenta. Ruta de acceso al contenedor, directorio o blob : especifica el nombre del blob que contiene los datos que se van a leer. Formato de archivo de blob: especifica el formato de los datos en blob service. Los formatos de datos admitidos son CSV, TSV, ARFF, CSV con una codificación especificada y Excel.
Puede usar la opción Excel para leer datos de libros de Excel. En la opción formato de datos de Excel , indique si los datos están en un intervalo de hojas de cálculo de Excel o en una tabla de Excel. En la opción Hoja de Excel o tabla incrustada , especifique el nombre de la hoja o tabla desde la que desea leer. |
| Proveedor de fuente de distribución de datos | Lee datos de un proveedor de fuente admitido. Actualmente se admite únicamente el formato Open Data Protocol (OData). |
Tipo de contenido de datos: especifica el formato OData. Dirección URL de origen: especifica la dirección URL completa de la fuente de distribución de datos. Por ejemplo, la siguiente dirección URL lee de la base de datos de ejemplo de Northwind: https://services.odata.org/northwind/northwind.svc/ |
Importación desde otro experimento
Habrá ocasiones en las que querrá tomar un resultado intermedio de un experimento y usarlo como parte de otro experimento. Para ello, guarde el módulo como un conjunto de datos:
- Haga clic en la salida del módulo que desea guardar como conjunto de datos.
- Haga clic en Guardar como conjunto de datos.
- Cuando se le solicite, escriba un nombre y una descripción que le permitan identificar fácilmente el conjunto de datos.
- Haga clic en la marca de verificación Aceptar .
Cuando termine de guardar, el conjunto de datos estará disponible para usarlo dentro de cualquier experimento de su área de trabajo. Puede encontrarlo en la lista Conjuntos de datos guardados de la paleta de módulos.