Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica cómo usar el componente Entrenamiento del modelo de PyTorch del diseñador de Azure Machine Learning para entrenar modelos de PyTorch como DenseNet. El entrenamiento tiene lugar después de definir un modelo y establecer sus parámetros y requiere datos etiquetados.
Actualmente el componente Entrenamiento del modelo de PyTorch admite el entrenamiento distribuido y de nodo único.
Cómo usar Entrenamiento del modelo de PyTorch
Agregue los componentes DenseNet o ResNet al borrador de canalización del diseñador.
Agregue el componente Entrenamiento del modelo de PyTorch a la canalización. Puede encontrar este componente en la categoría Entrenamiento del modelo. Expanda Entrenar y luego arrastre el componente Entrenamiento del modelo de PyTorch a la canalización.
Nota:
El componente Entrenamiento del modelo de PyTorch se ejecuta mejor en un proceso de tipo GPU para conjuntos de datos grandes; de lo contrario, se genera un error en la canalización. Puede seleccionar el proceso para un componente determinado en el panel derecho del componente si establece Usar otro destino de proceso.
En la entrada izquierda, adjunte un modo no entrenado. Conecte el conjunto de datos de entrenamiento y el conjunto de datos de validación a la entrada de la parte central y derecha de Entrenamiento del modelo de PyTorch.
En el caso de un modelo no entrenado, debe ser un modelo de PyTorch como DenseNet; de lo contrario, se producirá un error "InvalidModelDirectoryError".
En el caso de un conjunto de datos, el conjunto de datos de entrenamiento debe ser un directorio de imagen con etiquetas. Para más información sobre cómo obtener un directorio de imagen con etiquetas, consulte Conversión a directorio de imagen. Si no está etiquetado, se producirá una un error "NotLabeledDatasetError".
El conjunto de datos de entrenamiento y el conjunto de datos de validación deben tener las mismas categorías de etiqueta; de lo contrario, se producirá un error InvalidDatasetError.
En Epochs (Épocas), especifique el número de épocas que le gustaría entrenar. Se iterará todo el conjunto de valores cada época, de forma predeterminada 5.
Para Tamaño del lote, especifique el número de instancias que se van a entrenar en un lote, de forma predeterminada 16.
En Warmup step number (número de paso de preparación), especifique durante cuántas épocas quiere preparar el entrenamiento, en caso de que la velocidad de aprendizaje inicial sea un poco mayor para empezar a converger, de manera predeterminada es 0.
En Velocidad de aprendizaje, especifique un valor para la velocidad de aprendizaje; el valor predeterminado es 0,001. La velocidad de aprendizaje controla el tamaño del paso que se usa en el optimizador, como sgd, cada vez que se prueba y se corrige el modelo.
Al establecer una velocidad menor, se prueba el modelo más a menudo, con el riesgo de que pueda quedarse atascado en un nivel local. Al establecer una velocidad mayor, puede convergir con mayor rapidez, con el riesgo de superar los mínimos verdaderos.
Nota:
Si la pérdida de entrenamiento se convierte en NaN durante el entrenamiento, lo que puede deberse a una velocidad de aprendizaje demasiado alta, disminuir la velocidad de aprendizaje puede ayudar. En el entrenamiento distribuido, para mantener estable el descenso de gradiente, se calcula la velocidad de aprendizaje real mediante
lr * torch.distributed.get_world_size(), ya que el tamaño de lote del grupo de procesos es igual al de la muestra completa multiplicado por ese único proceso. Se aplica la decadencia polinómica de la velocidad de aprendizaje y puede ayudar a mejorar el rendimiento del modelo.En Random seed (Inicialización aleatoria), escriba opcionalmente un valor de entero que se usará como inicialización. Se recomienda usar una inicialización si quiere garantizar la reproducibilidad del experimento a través de los trabajos.
Por Patience (Paciencia), especifique para cuántas épocas quiere detener el entrenamiento con antelación si la pérdida de validación no se reduce consecutivamente. De forma predeterminada 3.
En Frecuencia de impresión, especifique la frecuencia de impresión del registro de entrenamiento en iteraciones por cada época; de manera predeterminada es 10.
Envíe la canalización. Si el conjunto de datos tiene un tamaño mayor, tardará un tiempo, por lo que se recomienda un proceso de GPU.
Entrenamiento distribuido
En el entrenamiento distribuido, la carga de trabajo para entrenar un modelo se divide y se comparte entre varios procesadores pequeños, denominados nodos de trabajo. Estos nodos de trabajo trabajan en paralelo para acelerar el entrenamiento del modelo. Actualmente el diseñador admite el entrenamiento distribuido para el componente Entrenamiento del modelo de PyTorch.
Tiempo de entrenamiento
El entrenamiento distribuido permite entrenar en un conjunto de datos de gran tamaño, como ImageNet (1000 clases, 1,2 millones de imágenes) en tan solo algunas horas mediante Entrenamiento del modelo de PyTorch. En la tabla siguiente se muestra el tiempo de entrenamiento y el rendimiento durante el entrenamiento de 50 épocas de Resnet50 en ImageNet desde cero según diferentes dispositivos.
| Dispositivos | Tiempo de entrenamiento | Rendimiento de entrenamiento | Precisión de validación del primer resultado | Precisión de validación de los primeros cinco resultados |
|---|---|---|---|---|
| 16 V100 GPU | 6 h 22 min | ~3200 imágenes/s | 68,83 % | 88,84 % |
| 8 V100 GPU | 12 h 21 min | ~1670 imágenes/s | 68,84 % | 88,74 % |
Haga clic en la pestaña "Métricas" de este componente y vea los grafos de métricas de entrenamiento, como "Train images per second" (Imágenes de entrenamiento por segundo) y "Top-1 accuracy" (Precisión del primer resultado).

Cómo habilitar el entrenamiento distribuido
Para habilitar el entrenamiento distribuido para el componente Entrenamiento del modelo de PyTorch, puede hacerlo en Parámetros de trabajo en el panel derecho del componente. Solo se admite el clúster de proceso de AML para el entrenamiento distribuido.
Nota:
Se necesitan varias GPU para activar el entrenamiento distribuido, ya que el componente Entrenamiento del modelo de PyTorch de back-end de NCCL necesita CUDA.
Seleccione el componente y abra el panel derecho. Expanda la sección Parámetros de trabajo.
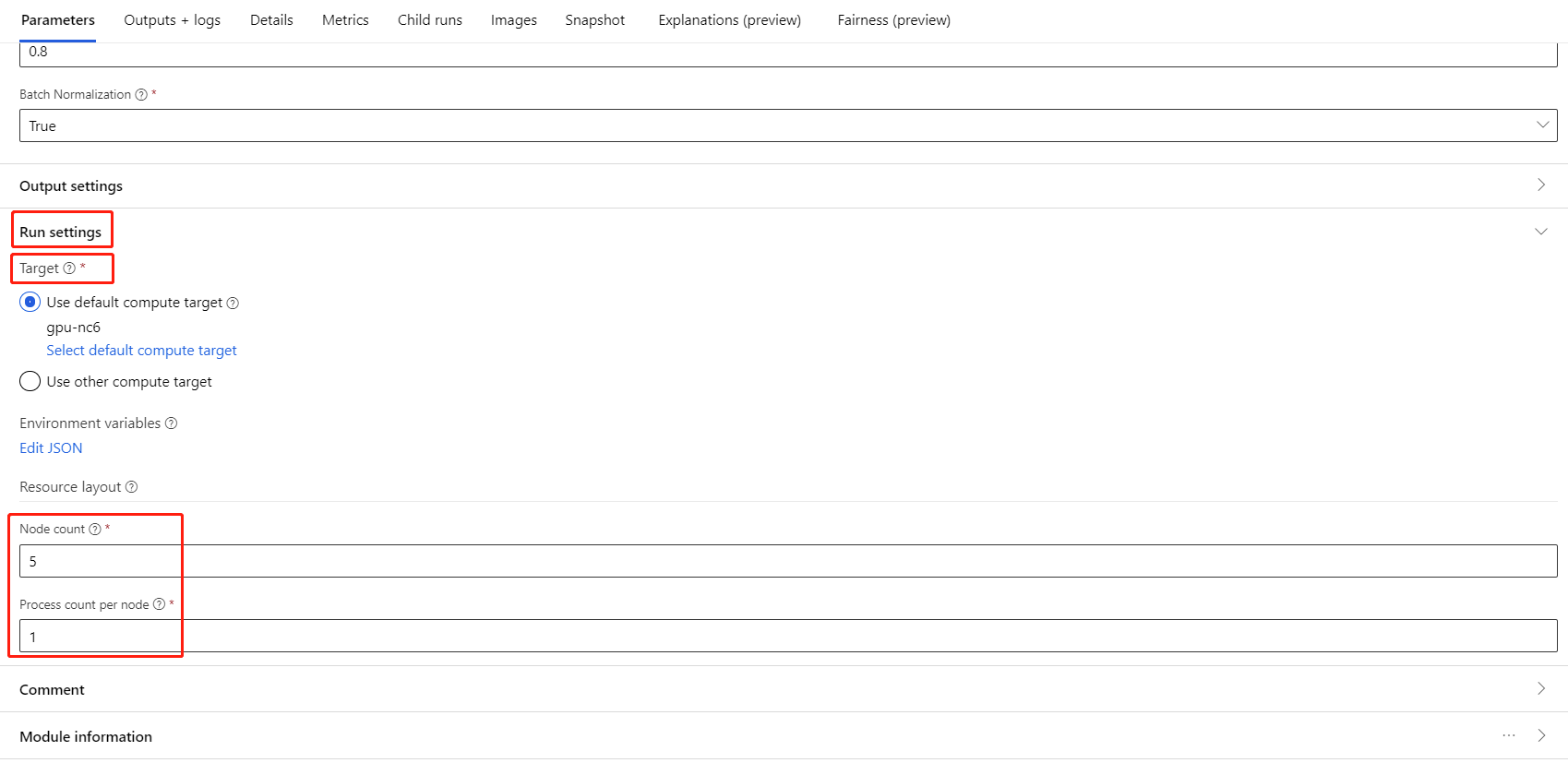
Asegúrese de que ha seleccionado Proceso de AML para el destino de proceso.
En la sección Resource layout (diseño de recursos), debe establecer los valores siguientes:
Recuento de nodos: número de nodos en el destino de proceso usados para el entrenamiento. Debe ser menor o igual que el Número máximo de nodos del clúster de proceso. De manera predeterminada, tiene un valor de 1, lo que significa un único trabajo de nodo.
Process count per node (recuento de procesos por nodo): número de procesos desencadenados por nodo. Debe ser menor o igual que la Unidad de procesamiento del proceso. De manera predeterminada, tiene un valor de 1, lo que significa un único trabajo de proceso.
Haga clic en el nombre del proceso en la página de detalles del proceso correspondiente para comprobar el Número máximo de nodos y la Unidad de procesamiento.
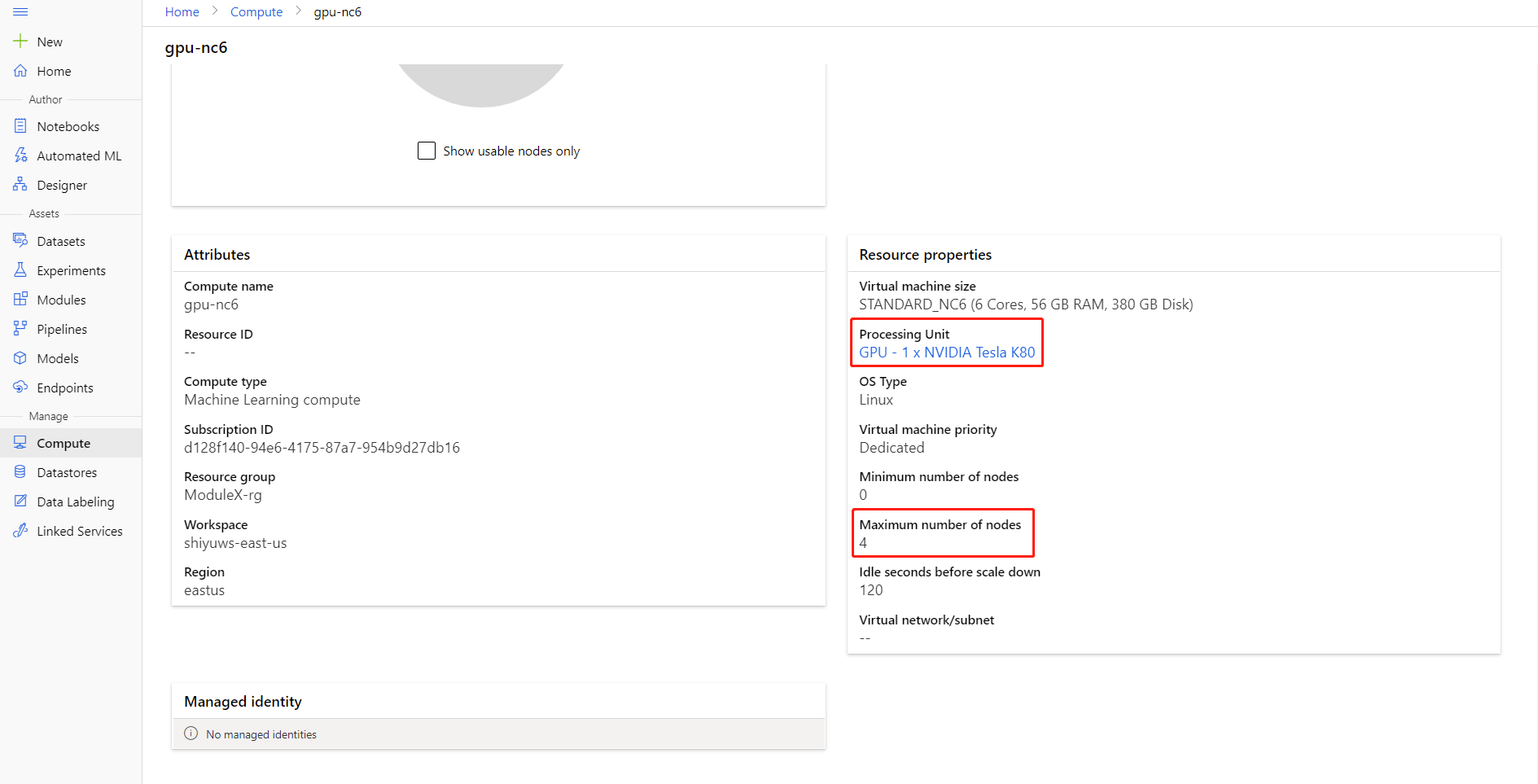


Puede obtener más información acerca del entrenamiento distribuido en Azure Machine Learning aquí.
Solución de problemas de entrenamiento distribuido
Si habilita el entrenamiento distribuido para este componente, va a haber registros de controlador para cada proceso.
70_driver_log_0 es para el proceso maestro. Puede comprobar los registros de controladores para obtener los detalles de errores de cada proceso en la pestaña Resultados y registros del panel derecho.

Si se produce un error en el entrenamiento distribuido habilitado para el componente sin ningún registro 70_driver, puede comprobar 70_mpi_log para ver los detalles del error.
En el ejemplo siguiente se muestra un error común, que implica que el Recuento de procesos por nodo es mayor que la Unidad de procesamiento del proceso.

Puede ver este artículo para obtener más detalles sobre la solución de problemas de los componentes.
Resultados
Una vez completado el trabajo de la canalización, para usar el modelo para la puntuación, conecte Entrenamiento del modelo de PyTorch a Puntuación del modelo de imagen a fin de predecir valores para los nuevos ejemplos de entrada.
Notas técnicas
Entradas esperadas
| Nombre | Escribir | Descripción |
|---|---|---|
| Modelo no entrenado | UntrainedModelDirectory | Modelo no entrenado, requiere PyTorch |
| Conjunto de datos de entrenamiento | ImageDirectory | Conjunto de datos de entrenamiento |
| Conjunto de datos de validación | ImageDirectory | Conjunto de datos de validación para la evaluación cada época |
Parámetros del componente
| Nombre | Intervalo | Escribir | Valor predeterminado | Descripción |
|---|---|---|---|---|
| Épocas | >0 | Entero | 5 | Seleccionar la columna que contiene la columna de etiqueta o resultado |
| Tamaño de lote | >0 | Entero | 16 | Número de instancias que se van a entrenar en un lote |
| Número de paso de preparación | >=0 | Entero | 0 | Número de épocas para preparar el entrenamiento |
| Velocidad de aprendizaje | >=double. Épsilon | Flotar | 0,1 | Velocidad de aprendizaje inicial para el optimizador de descenso de gradiente estocástico. |
| Inicialización aleatoria | Cualquiera | Entero | 1 | La inicialización para el generador de números aleatorios usado por el modelo. |
| Paciencia | >0 | Entero | 3 | Número de épocas para la detención con antelación del entrenamiento |
| Frecuencia de impresión | >0 | Entero | 10 | Frecuencia de impresión del registro de entrenamiento en iteraciones por cada época |
Salidas
| Nombre | Escribir | Descripción |
|---|---|---|
| Modelo entrenado | ModelDirectory | Modelo entrenado |
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.