Configuración de AutoML para entrenar un modelo de previsión de series temporales con el SDK y la CLI
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo, obtendrá información sobre cómo configurar AutoML para la previsión de series temporales con el aprendizaje automático automatizado de Azure Machine Learning en el SDK de Python de Azure Machine Learning.
Para ello, haremos lo siguiente:
- Preparación de los datos para el entrenamiento.
- Configure parámetros de serie temporal específicos en un Trabajo de previsión.
- Organice el entrenamiento, la inferencia y la evaluación del modelo mediante componentes y canalizaciones.
Para una experiencia con poco código, consulte Tutorial: Previsión de la demanda con aprendizaje automático automatizado para ver un ejemplo de previsión de series temporales con AutoML en Estudio de Azure Machine Learning.
AutoML usa modelos de aprendizaje automático estándar junto con modelos de serie temporal conocidos para crear previsiones. Nuestro enfoque incorpora información histórica sobre la variable de destino, las características proporcionadas por el usuario en los datos de entrada y las características diseñadas automáticamente. A continuación, los algoritmos de búsqueda de los modelos trabajan para encontrar un modelo con la mejor precisión predictiva. Para obtener más información, consulte nuestros artículos sobre la metodología de previsión y la búsqueda de modelos.
Requisitos previos
Para realizar este artículo, necesitará lo siguiente
Un área de trabajo de Azure Machine Learning. Para crear el área de trabajo, consulte Creación de recursos del área de trabajo.
La capacidad de iniciar trabajos de entrenamiento de AutoML. Siga la guía paso a paso para configurar AutoML para obtener más información.
Datos de entrenamiento y validación
Los datos de entrada para la previsión de AutoML deben contener series temporales válidas en formato tabular. Cada variable debe tener su propia columna correspondiente en la tabla de datos. AutoML requiere al menos dos columnas: una columna de tiempo que representa el eje de tiempo y la columna de destino, que es la cantidad que se va a predecir. Otras columnas pueden servir como predictores. Para más información, consulte cómo AutoML usa los datos.
Importante
Al entrenar un modelo para la previsión de valores futuros, asegúrese de que todas las características del entrenamiento se pueden usar al ejecutar predicciones para su horizonte previsto.
Por ejemplo, una característica para el precio de cotización actual podría aumentar la precisión del entrenamiento de manera exponencial. Sin embargo, si quiere una previsión con un horizonte lejano, no es posible predecir con precisión valores de cotización futuros correspondientes a momentos futuros en la serie temporal y la precisión del modelo podría verse afectada.
Los trabajos de previsión de AutoML requieren que los datos de entrenamiento se representen como un objeto MLTable. Una instancia de MLTable especifica un origen de datos y pasos para cargar los datos. Para más información y casos de uso, consulte la Guía paso a paso de MLTable. Como ejemplo sencillo, supongamos que los datos de entrenamiento están contenidos en un archivo CSV en un directorio local, ./train_data/timeseries_train.csv.
Puede crear una instancia de MLTable mediante el SDK de Python de mltable como en el ejemplo siguiente:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Este código crea un nuevo archivo, ./train_data/MLTable, que contiene el formato de archivo y las instrucciones de carga.
Ahora define un objeto de datos de entrada, que es necesario para iniciar un trabajo de entrenamiento, mediante el SDK de Python de Azure Machine Learning, como se indica a continuación:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Especifique datos de validación de una manera similar mediante la creación de una MLTable y especificando una entrada de datos de validación. Como alternativa, si no proporciona datos de validación, AutoML crea automáticamente divisiones de validación cruzada de los datos de entrenamiento que se usarán para la selección del modelo. Consulte nuestro artículo sobre la selección de modelos de previsión para obtener más detalles. Consulte también los requisitos de longitud de datos de entrenamiento para obtener más información sobre la cantidad de datos de entrenamiento que necesita para entrenar correctamente un modelo de previsión.
Obtenga más información sobre cómo AutoML aplica la validación cruzada para evitar un sobreajuste.
Proceso para ejecutar el experimento
AutoML usa Proceso de Azure Machine Learning, que es un recurso de proceso totalmente administrado, para ejecutar el trabajo de entrenamiento. En el ejemplo siguiente, se crea un clúster de proceso denominado cpu-compute:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Configuración del experimento
Las funciones de fábrica de automl se usan para configurar trabajos de previsión en el SDK de Python. En el ejemplo siguiente se muestra cómo crear un trabajo de previsión estableciendo la métrica principal y estableciendo límites en la ejecución del entrenamiento:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Configuración del trabajo de previsión
Las tareas de previsión tienen muchas configuraciones específicas de la previsión. Los valores más básicos de esta configuración son el nombre de la columna de tiempo en los datos de entrenamiento y el horizonte de previsión.
Use los métodos ForecastingJob para configurar estas opciones:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
El nombre de la columna de hora es una configuración necesaria y, por lo general, debe establecer el horizonte de previsión según el escenario de predicción. Si los datos contienen varias series temporales, puede especificar los nombres de las columnas de identificador de serie temporal. Estas columnas, cuando se agrupan, definen la serie individual. Por ejemplo, supongamos que tiene datos que constan de ventas por hora de diferentes tiendas y marcas. En el ejemplo siguiente se muestra cómo establecer las columnas de identificador de serie temporal suponiendo que los datos contienen columnas denominadas "tienda" y "marca":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML intenta detectar automáticamente columnas de identificador de serie temporal en los datos si no se especifica ninguna.
Otros ajustes de configuración son opcionales y se revisan en la sección siguiente.
Configuración opcional del trabajo de previsión
Hay configuraciones opcionales disponibles para las tareas de previsión, como la habilitación del aprendizaje profundo y la especificación de una agregación de ventana con desplazamiento de objetivo. Hay disponible una lista completa de parámetros en la documentación de referencia de previsión.
Configuración de búsqueda de modelos
Hay dos ajustes opcionales que controlan el espacio del modelo donde AutoML busca el mejor modelo allowed_training_algorithms y blocked_training_algorithms. Para restringir el espacio de búsqueda a un conjunto determinado de clases de modelo, use el parámetro allowed_training_algorithms como en el ejemplo siguiente:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
En este caso, el trabajo de previsión solo busca en las clases de modelo de Exponential Smoothing y Elastic Net. Para quitar un conjunto determinado de clases de modelo del espacio de búsqueda, use el blocked_training_algorithms como en el ejemplo siguiente:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Ahora, el trabajo busca en todas las clases de modelo excepto Prophet. Para obtener una lista de los nombres del modelo de previsión que se aceptan en allowed_training_algorithms y blocked_training_algorithms, consulte la documentación de referencia de las propiedades de entrenamiento. O bien, allowed_training_algorithms y blocked_training_algorithms, pero no ambos, se pueden aplicar a una ejecución de entrenamiento.
Habilitar el aprendizaje profundo.
AutoML se incluye con un modelo de red neuronal profunda (DNN) personalizado denominado TCNForecaster. Este modelo es una red convolucional temporal o TCN, que aplica métodos comunes de tareas de creación de imágenes al modelado de series temporales. Es decir, las convoluciones unidimensionales "causales" forman la red troncal de la red y permiten que el modelo aprenda patrones complejos durante largas duraciones en el historial de entrenamiento. Para obtener más información, consulte el artículo sobre TCNForecaster.
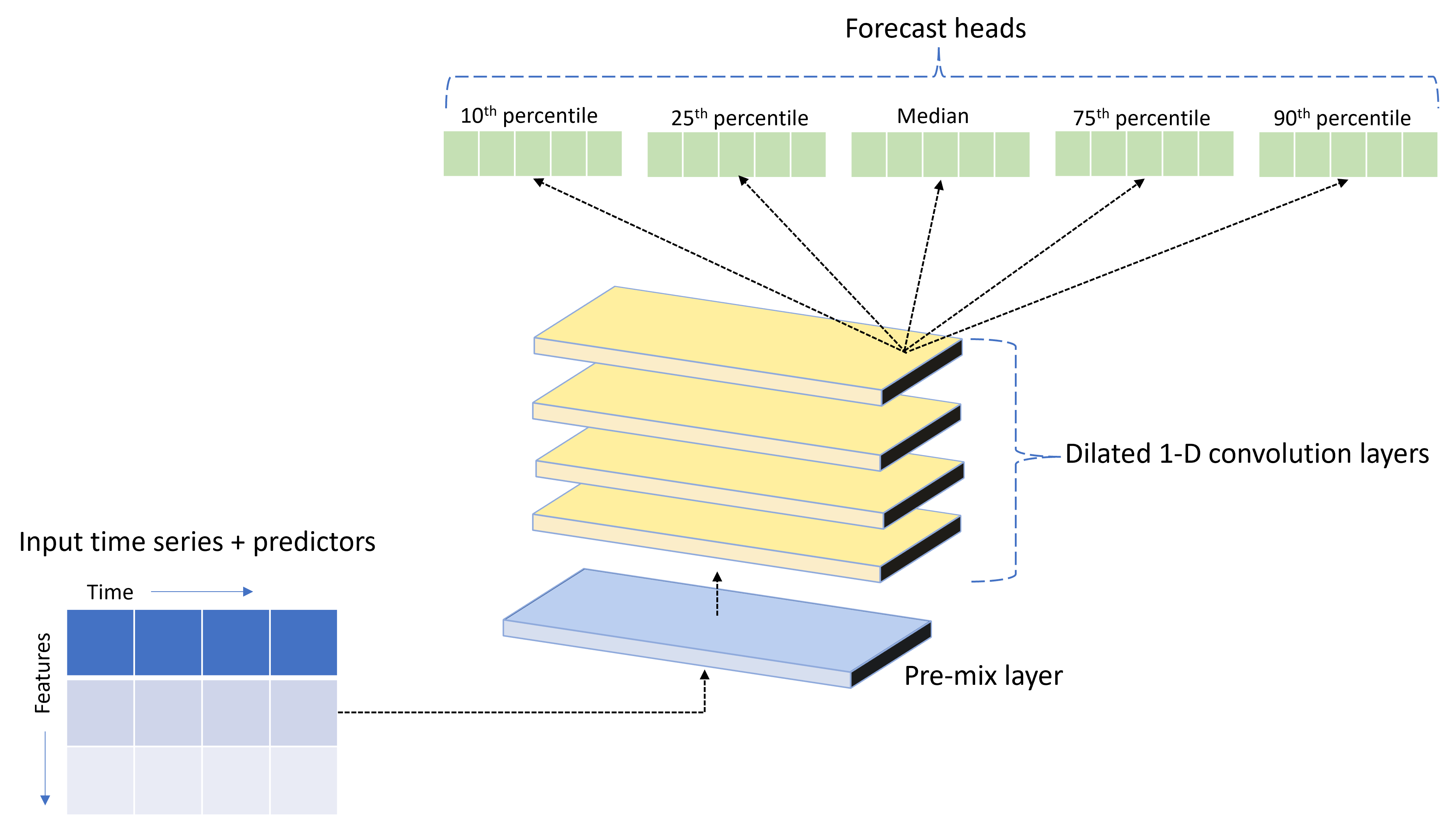
TCNForecaster suele lograr una mayor precisión que los modelos de series temporales estándar cuando hay miles de observaciones o más en el historial de entrenamiento. Sin embargo, también se tarda más tiempo en entrenar y hacer el barrido de los modelos de TCNForecaster debido a su mayor capacidad.
Para habilitar TCNForecaster en AutoML, establezca la marca enable_dnn_training en la configuración de entrenamiento de la siguiente manera:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
De manera predeterminada, el entrenamiento TCNForecaster se limita a un único nodo de proceso y una única GPU, si está disponible, por prueba de modelo. Para escenarios de datos de gran tamaño, se recomienda distribuir cada prueba TCNForecaster a través de varios núcleos/GPU y nodos. Consulte la sección del artículo de entrenamiento distribuido para obtener más información y ejemplos de código.
Para habilitar DNN para un experimento de AutoML creado en Azure Machine Learning Studio, consulte los procedimientos en la interfaz de usuario de Studio para la configuración del tipo de tarea.
Nota
- Al habilitar DNN para los experimentos creados con el SDK, las mejores explicaciones del modelo se deshabilitan.
- La compatibilidad con DNN para la previsión en el aprendizaje automático automatizado no es compatible con las ejecuciones iniciadas en Databricks.
- Se recomiendan los tipos de proceso de GPU cuando se habilita el entrenamiento de DNN
Características de ventana graduales y de retraso
Los valores recientes del destino suelen ser características impactantes en un modelo de previsión. En consecuencia, AutoML puede crear características de agregación de ventana graduales y de retraso en el tiempo para mejorar potencialmente la precisión del modelo.
Considere un escenario de previsión de la demanda energética en el que están disponibles los datos meteorológicos y la demanda histórica. En la tabla se muestra la ingeniería de características resultante que se produce cuando se aplica la agregación de ventanas en las tres horas más recientes. Las columnas para los valores mínimo, máximo y suma se generan en una ventana deslizante de tres horas según la configuración definida. Por ejemplo, para la observación válida del 8 de septiembre de 2017 4:00 a. m., los valores máximo, mínimo y suma se calculan con los valores de la demanda del 8 de septiembre de 2017, de la 1:00 a. m. a las 3:00 a. m. Esta ventana tiene tres turnos de horas juntos para rellenar los datos de las filas restantes. Para obtener más información y ejemplos, consulte el artículo sobre la característica de retraso.

Puede habilitar las características de agregación de ventanas de retraso y graduales para el destino estableciendo el tamaño de la ventana gradual, que era tres en el ejemplo anterior, y los pedidos de retraso que desea crear. También puede habilitar los retrasos para las características con la configuración feature_lags. En el ejemplo siguiente, se establecen todos los valores de configuración en auto para que AutoML determine automáticamente la configuración mediante el análisis de la estructura de correlación de los datos:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Control de series breves
El ML automatizado considera una serie temporal como serie breve si no hay suficientes puntos de datos para llevar a cabo las fases de entrenamiento y validación del desarrollo del modelo. Consulte requisitos de longitud de datos de entrenamiento para obtener más información sobre los requisitos de longitud.
AutoML tiene varias acciones que puede realizar para series cortas. Estas acciones se pueden configurar con short_series_handling_config. El valor predeterminado es "auto". En la tabla siguiente se describen las opciones de configuración:
| Configuración | Descripción |
|---|---|
auto |
Valor predeterminado para el control de series cortas. - Si todas las series son cortas, se rellenan los datos. - Si no todas las series son cortas, se anulan las series cortas. |
pad |
Si short_series_handling_config = pad, el aprendizaje automático automatizado agrega valores aleatorios a cada serie breve que se encuentra. A continuación se enumeran los tipos de columna y con qué se rellenan: - Columnas de objetos con NaN - Columnas numéricas con 0 - Columnas booleanas o lógicas con False - La columna de destino se rellena con ruido blanco. |
drop |
Si short_series_handling_config = drop, el aprendizaje automático automatizado quita las series breves, y no se usarán para el entrenamiento ni la predicción. Las predicciones para estas series devolverán NaN. |
None |
No se rellena ni anula ninguna serie |
En el ejemplo siguiente, se establece el control de series cortas para que todas las series cortas se rellenen con la longitud mínima:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Advertencia
El relleno puede afectar a la precisión del modelo resultante, ya que estamos introduciendo datos artificiales para evitar los errores en el entrenamiento. Si muchas de las series son breves, puede que también vea algún impacto en los resultados de la capacidad de explicación.
Frecuencia y agregación de datos de destino
Use las opciones de agregación de datos y frecuencia para evitar errores causados por datos irregulares. Los datos son irregulares si no siguen una cadencia establecida en el tiempo, como cada hora o diariamente. Los datos de punto de venta son un buen ejemplo de datos irregulares. En estos casos, AutoML puede agregar los datos a una frecuencia deseada y, a continuación, crear un modelo de previsión a partir de los agregados.
Debe establecer la configuración frequency y target_aggregate_function para controlar datos irregulares. La configuración de frecuencia acepta Cadenas DateOffset de Pandas como entrada. Los valores admitidos para la función de agregación son:
| Función | Descripción |
|---|---|
sum |
La suma de los valores de destino |
mean |
La media o promedio de los valores de destino |
min |
El valor mínimo de un destino |
max |
El valor máximo de un destino |
- Los valores de la columna de destino se agregan de acuerdo a la operación especificada. Normalmente, es adecuado para la mayoría de los escenarios.
- Las columnas de predicción numéricas de los datos se agregan en función de la suma, la media, el valor mínimo y el valor máximo. Como resultado, los ML automatizados generan nuevas columnas con el sufijo del nombre de la función de agregación y aplican la operación de agregado seleccionada.
- En el caso de las columnas de predicción de categorías, los datos se agregan en función del modo, que es la categoría más destacada en la ventana.
- Las columnas de predicción de fecha se agregan en función del valor mínimo, el valor máximo y el modo.
En el ejemplo siguiente se establece la frecuencia en cada hora y la función de agregación en suma:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Configuración personalizada de validación cruzada
Hay dos configuraciones personalizables que controlan la validación cruzada para los trabajos de previsión: el número de plegamientos, n_cross_validations, y el tamaño del paso que define el desplazamiento de tiempo entre plegados, cv_step_size. Consulte la selección del modelo de previsión para obtener más información sobre el significado de estos parámetros. De forma predeterminada, AutoML establece ambas opciones automáticamente en función de las características de los datos, pero es posible que los usuarios avanzados quieran establecerlos manualmente. Por ejemplo, supongamos que tiene datos de ventas diarios y desea que la configuración de validación conste de cinco plegamientos con un desplazamiento de siete días entre plegados adyacentes. El siguiente ejemplo de código muestra cómo establecer esta configuración:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Caracterización personalizada
De forma predeterminada, AutoML aumenta los datos de entrenamiento con características diseñadas para aumentar la precisión de los modelos. Consulte ingeniería de características automatizada para obtener más información. Algunos de los pasos de preprocesamiento se pueden personalizar mediante la configuración de caracterización del trabajo de previsión.
Las personalizaciones admitidas para la previsión se encuentran en la tabla siguiente:
| Personalización | Descripción | Opciones |
|---|---|---|
| Actualización del propósito de la columna | Invalida el tipo de característica detectado automáticamente para la columna especificada. | "Categorical", "DateTime", "Numeric" |
| Actualización de parámetros del transformador | Actualice los parámetros del equipo de imputer especificado. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Por ejemplo, supongamos que tiene un escenario de demanda comercial en el que los datos incluyen los precios, una marca "en venta" y un tipo de producto. En el ejemplo siguiente se muestra cómo puede establecer tipos personalizados e imputers para estas características:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Si usa Azure Machine Learning Studio para el experimento, consulte Personalización de la caracterización en Studio.
Envío de un trabajo de previsión
Una vez configuradas todas las opciones, inicie el trabajo de previsión de la siguiente manera:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Una vez enviado el trabajo, AutoML aprovisionará los recursos de proceso, aplicará la caracterización y otros pasos de preparación a los datos de entrada y, a continuación, comenzará a analizar los modelos de previsión. Para obtener más información, consulte nuestros artículos sobre la metodología de previsión y la búsqueda de modelos.
Orquestación del entrenamiento, la inferencia y la evaluación con componentes y canalizaciones
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Es probable que el flujo de trabajo de ML requiera algo más que solo entrenamiento. La inferencia o la recuperación de predicciones del modelo en datos más recientes, y la evaluación de la precisión del modelo en un conjunto de pruebas con valores de destino conocidos son otras tareas comunes que puede orquestar en AzureML junto con trabajos de entrenamiento. Para admitir tareas de inferencia y evaluación, AzureML proporciona componentes, que son fragmentos independientes de código que realizan un paso en una canalización de AzureML.
En el ejemplo siguiente, recuperamos el código de componente de un registro de cliente:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
A continuación, definimos una función de fábrica que crea canalizaciones que orquestan el entrenamiento, la inferencia y el cálculo de métricas. Consulte la sección configuración de entrenamiento para obtener más información sobre la configuración de entrenamiento.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Ahora, definimos entradas de datos de entrenamiento y prueba, suponiendo que están contenidas en las carpetas locales, ./train_data y ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Por último, se crea la canalización, se establece su proceso predeterminado y se envía el trabajo:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Una vez enviada, la canalización ejecuta el entrenamiento de AutoML, la inferencia de evaluación gradual y el cálculo de métricas en secuencia. Puede supervisar e inspeccionar la ejecución en la interfaz de usuario de Studio. Una vez finalizada la ejecución, se pueden descargar las previsiones graduales y las métricas de evaluación en el directorio de trabajo local:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
A continuación, puede encontrar los resultados de las métricas en ./named-outputs/metrics_results/evaluationResult/metrics.json y las previsiones, en formato de líneas JSON, en ./named-outputs/rolling_fcst_result/inference_output_file.
Para obtener más información sobre la evaluación gradual, consulte nuestro artículo de evaluación del modelo de previsión.
Previsión a gran escala: muchos modelos
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Los componentes de muchos modelos de AutoML permiten entrenar y administrar millones de modelos en paralelo. Para obtener más información sobre los conceptos de muchos modelos, consulte la sección del artículo sobre muchos modelos.
Configuración del entrenamiento de muchos modelos
El componente de entrenamiento de muchos modelos acepta un archivo de configuración en formato YAML de la configuración de entrenamiento de AutoML. El componente aplica esta configuración a cada instancia de AutoML que se inicia. Este archivo YAML tiene la misma especificación que el trabajo de previsión más los parámetros adicionales partition_column_names y allow_multi_partitions.
| Parámetro | Descripción |
|---|---|
| partition_column_names | Nombres de columna en los datos que, cuando se agrupan, definen las particiones de datos. El componente de entrenamiento de muchos modelos inicia un trabajo de entrenamiento independiente en cada partición. |
| allow_multi_partitions | Marca opcional que permite entrenar un modelo por partición cuando cada partición contiene más de una serie temporal única. El valor predeterminado es False. |
En el ejemplo siguiente se proporciona una plantilla de configuración:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
En ejemplos posteriores, se supone que la configuración se almacena en la ruta de acceso, ./automl_settings_mm.yml.
Canalización de muchos modelos
A continuación, definimos una función de fábrica que crea canalizaciones para la orquestación del entrenamiento, inferencia y cálculo de métricas de muchos modelos. Los parámetros de esta función de fábrica se detallan en la tabla siguiente:
| Parámetro | Descripción |
|---|---|
| max_nodes | Número de nodos de proceso que se van a usar en el trabajo de entrenamiento |
| max_concurrency_per_node | Número de procesos de AutoML que se ejecutarán en cada nodo. Por lo tanto, la simultaneidad total de los trabajos de muchos modelos es max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Se ha agotado el tiempo de espera del componente de muchos modelos en cantidad de segundos. |
| retrain_failed_models | Marca para habilitar el nuevo entrenamiento para los modelos con errores. Esto es útil si ha realizado ejecuciones de muchos modelos anteriores que provocaron errores en los trabajos de AutoML en algunas particiones de datos. Cuando esta marca está habilitada, muchos modelos solo iniciarán trabajos de entrenamiento para particiones con errores anteriores. |
| forecast_mode | Modo de inferencia para la evaluación del modelo. Los valores válidos son "recursive" y "rolling". Consulte el artículo sobre la evaluación del modelo para obtener más información. |
| forecast_step | Tamaño del paso para la previsión gradual. Consulte el artículo sobre la evaluación del modelo para obtener más información. |
En el ejemplo siguiente se muestra un método de fábrica para construir canalizaciones de entrenamiento y evaluación de modelos de muchos modelos:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Ahora, creamos la canalización a través de la función de fábrica, suponiendo que los datos de entrenamiento y prueba están en las carpetas locales, ./data/train y ./data/test respectivamente. Por último, se establece el proceso predeterminado y se envía el trabajo como en el ejemplo siguiente:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Una vez finalizado el trabajo, las métricas de evaluación se pueden descargar localmente mediante el mismo procedimiento que en la canalización de ejecución de entrenamiento única.
Consulte también la previsión de la demanda con cuadernos de muchos modelos para obtener un ejemplo más detallado.
Nota
Los componentes del entrenamiento de muchos modelos y la inferencia crean condicionalmente particiones de los datos según la configuración partition_column_names para que cada partición esté en su propio archivo. Este proceso puede ser muy lento o producir errores cuando los datos son muy grandes. En este caso, se recomienda crear particiones de los datos manualmente antes de ejecutar el entrenamiento o inferencia de muchos modelos.
Previsión a gran escala: serie temporal jerárquica
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Los componentes de la serie temporal jerárquica (HTS) de AutoML permiten entrenar un gran número de modelos en datos con estructura jerárquica. Para obtener más información, consulte la sección del artículo sobre HTS.
Configuración del entrenamiento de HTS
El componente de entrenamiento de HTS acepta un archivo de configuración en formato YAML de la configuración de entrenamiento de AutoML. El componente aplica esta configuración a cada instancia de AutoML que se inicia. Este archivo YAML tiene la misma especificación que el trabajo de previsión más parámetros adicionales relacionados con la información de jerarquía:
| Parámetro | Descripción |
|---|---|
| hierarchy_column_names | Lista de nombres de columna en los datos que definen la estructura jerárquica de los datos. El orden de las columnas de esta lista determina los niveles de jerarquía; el grado de agregación disminuye con el índice de la lista. Es decir, la última columna de la lista define el nivel de hoja (más desagregado) de la jerarquía. |
| hierarchy_training_level | Nivel de jerarquía que se va a usar para el entrenamiento del modelo de previsión. |
A continuación se muestra una configuración de ejemplo:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
En ejemplos posteriores, se supone que la configuración se almacena en la ruta de acceso, ./automl_settings_hts.yml.
Canalización de HTS
A continuación, definimos una función de fábrica que crea canalizaciones para la orquestación del entrenamiento, inferencia y cálculo de métricas de HTS. Los parámetros de esta función de fábrica se detallan en la tabla siguiente:
| Parámetro | Descripción |
|---|---|
| forecast_level | Nivel de la jerarquía para el que se van a recuperar las previsiones |
| allocation_method | Método de asignación que se va a usar cuando se desagreguen las previsiones. Los valores válidos son "proportions_of_historical_average" y "average_historical_proportions". |
| max_nodes | Número de nodos de proceso que se van a usar en el trabajo de entrenamiento |
| max_concurrency_per_node | Número de procesos de AutoML que se ejecutarán en cada nodo. Por lo tanto, la simultaneidad total de un trabajo HTS es max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Se ha agotado el tiempo de espera del componente de muchos modelos en cantidad de segundos. |
| forecast_mode | Modo de inferencia para la evaluación del modelo. Los valores válidos son "recursive" y "rolling". Consulte el artículo sobre la evaluación del modelo para obtener más información. |
| forecast_step | Tamaño del paso para la previsión gradual. Consulte el artículo sobre la evaluación del modelo para obtener más información. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Ahora, creamos la canalización a través de la función de fábrica, suponiendo que los datos de entrenamiento y prueba están en las carpetas locales, ./data/train y ./data/test respectivamente. Por último, se establece el proceso predeterminado y se envía el trabajo como en el ejemplo siguiente:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Una vez finalizado el trabajo, las métricas de evaluación se pueden descargar localmente mediante el mismo procedimiento que en la canalización de ejecución de entrenamiento única.
Consulte también la previsión de la demanda con el cuaderno de series temporales jerárquicas para obtener un ejemplo más detallado.
Nota
Los componentes e inferencia del entrenamiento HTS crean condicionalmente particiones de los datos según la configuración hierarchy_column_names para que cada partición esté en su propio archivo. Este proceso puede ser muy lento o producir errores cuando los datos son muy grandes. En este caso, se recomienda crear particiones de los datos manualmente antes de ejecutar el entrenamiento o inferencia de HTS.
Previsión a gran escala: entrenamiento de DNN distribuido
- Para obtener información sobre cómo funciona el entrenamiento distribuido para las tareas de previsión, consulte nuestro artículo de previsión a gran escala.
- Consulte nuestra sección en el artículo sobre configuración del entrenamiento distribuido para datos tabulares para obtener ejemplos de código.
Cuadernos de ejemplo
Consulte los cuadernos de ejemplo de previsión para ejemplos de código detallados de la configuración de predicciones avanzada, que incluye:
- Ejemplos de canalización de previsión de demanda
- Modelos de aprendizaje profundo
- Detección y caracterización de festividades
- Configuración manual para las características de agregación de ventanas graduales y de retraso
Pasos siguientes
- Obtenga más información sobre la Implementación de un modelo de AutoML en un punto de conexión en línea.
- Obtenga más información sobre la Capacidad de interpretación: explicaciones de los modelos en el aprendizaje automático automatizado (versión preliminar).
- Obtenga información sobre cómo AutoML crea modelos de previsión.
- Obtenga información sobre la previsión a gran escala.
- Aprenda a configurar AutoML para varios escenarios de previsión.
- Obtenga información sobre la inferencia y la evaluación de los modelos de previsión.