Configuración de un entorno de desarrollo de Python para Azure Machine Learning (v1)
Descubra cómo configurar un entorno de desarrollo de Python para Azure Machine Learning.
En la tabla siguiente se muestra cada entorno de desarrollo que se trata en este artículo, junto con las ventajas y desventajas.
| Entorno | Ventajas | Desventajas |
|---|---|---|
| Entorno local | Control total del entorno de desarrollo y las dependencias. Funciona con cualquier herramienta de compilación, entorno o IDE de su elección. | Tarda más tiempo en comenzar. Se deben instalar los paquetes de SDK necesarios y también debe instalarse un entorno si aún no tiene uno. |
| Data Science Virtual Machine (DSVM) | De forma parecida a la instancia de proceso basada en la nube (con Python y el SDK preinstalados), pero con otras herramientas de ciencia de datos y aprendizaje automático conocidas instaladas previamente. Fácil de escalar y combinar con otras herramientas y flujos de trabajo personalizados. | Una experiencia de inicio más lenta en comparación con la instancia de proceso basada en la nube. |
| Instancia de proceso de Azure Machine Learning | Manera más fácil de empezar. El SDK completo ya está instalado en la máquina virtual del área de trabajo y los tutoriales de cuaderno están clonados previamente y listos para ejecutarse. | Falta de control sobre el entorno de desarrollo y las dependencias. Coste adicional por la máquina virtual Linux (la máquina virtual se puede detener cuando no se use para evitar cargos). Consulte los detalles de los precios. |
| Azure Databricks | Perfecto para ejecutar flujos de trabajo de aprendizaje automático intensivos y a gran escala en la plataforma escalable de Apache Spark. | Excesivo para aprendizaje automático experimental o experimentos y flujos de trabajo a pequeña escala. Coste adicional por Azure Databricks. Consulte los detalles de los precios. |
En este artículo, también se proporcionan sugerencias de uso para las siguientes herramientas:
Jupyter Notebook: si ya usa instancias de Jupyter Notebook, el SDK incluye algunos elementos adicionales que debe instalar.
Visual Studio Code: si usa Visual Studio Code, la extensión de Azure Machine Learning incluye compatibilidad de lenguaje con Python, así como características que harán que trabajar con Azure Machine Learning sea mucho más cómodo y productivo.
Requisitos previos
- Área de trabajo de Azure Machine Learning. Si no tiene ninguna, puede crear un área de trabajo de Azure Machine Learning a través de Azure Portal, la CLI de Azure y las plantillas de Azure Resource Manager.
Solo en el entorno local y DSVM: Crear un archivo de configuración del área de trabajo
El archivo de configuración del área de trabajo es un archivo JSON que le indica al SDK cómo comunicarse con el área de trabajo de Azure Machine Learning. El archivo se denomina config.json y tiene el formato siguiente:
{
"subscription_id": "<subscription-id>",
"resource_group": "<resource-group>",
"workspace_name": "<workspace-name>"
}
Este archivo JSON debe estar en la estructura de directorios que contiene los scripts de Python o las instancias de Jupyter Notebook. Puede estar en el mismo directorio, en un subdirectorio denominado .azureml o en un directorio principal.
Para utilizar este archivo desde el código, utilice el método Workspace.from_config. Este código carga la información del archivo y se conecta a su área de trabajo.
Cree un archivo de configuración del área de trabajo con uno de los métodos siguientes:
Azure portal
Descargar el archivo: en Azure Portal, seleccione Descargar config.json desde la sección Información general del área de trabajo.
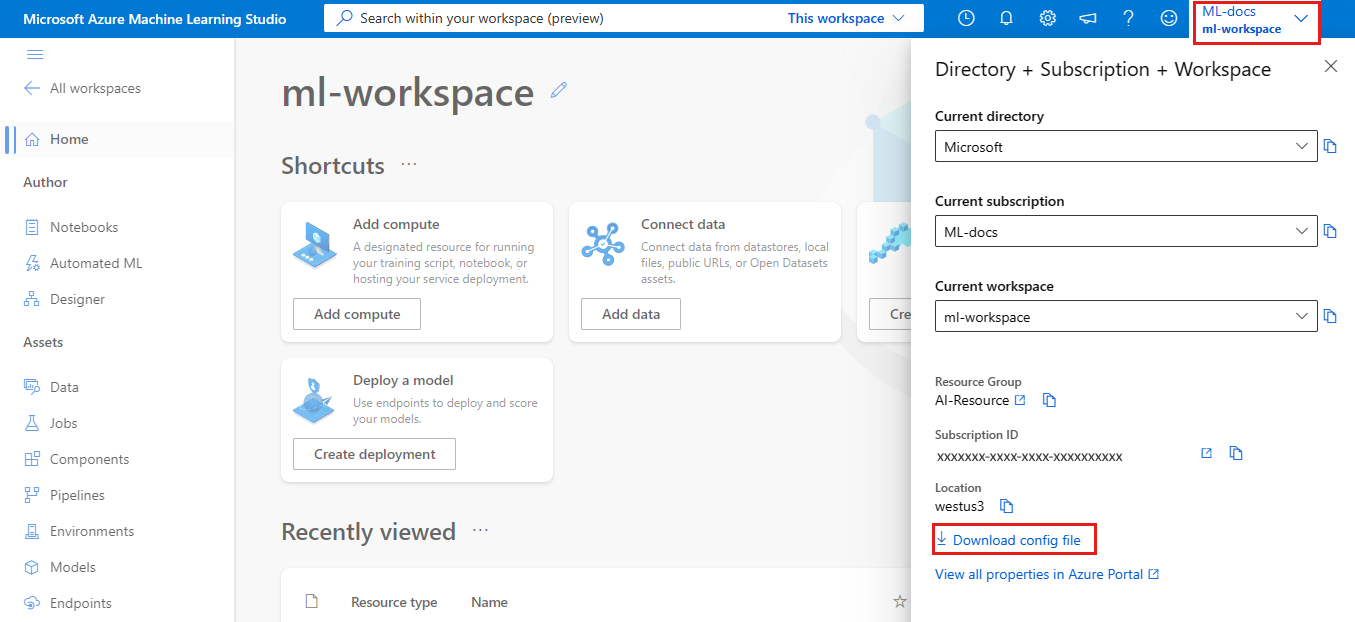
SDK de Python de Azure Machine Learning
Cree un script para conectarse a su área de trabajo de Azure Machine Learning y use el método
write_configa fin de generar el archivo y guárdelo como .azureml/config.json. Asegúrese de reemplazarsubscription_id,resource_groupyworkspace_namepor sus propios valores.SE APLICA A:
 Azure ML del SDK de Python v1
Azure ML del SDK de Python v1from azureml.core import Workspace subscription_id = '<subscription-id>' resource_group = '<resource-group>' workspace_name = '<workspace-name>' try: ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name) ws.write_config() print('Library configuration succeeded') except: print('Workspace not found')
Equipo local o entorno de máquina virtual remoto
Puede configurar un entorno en un equipo local o una máquina virtual remota, como una instancia de proceso de Azure Machine Learning o Data Science VM.
Para configurar un entorno de desarrollo local o una máquina virtual remota:
Cree un entorno virtual de Python (virtualenv, conda).
Nota
Aunque no es necesario, se recomienda usar Anaconda o Miniconda para administrar entornos virtuales de Python e instalar paquetes.
Importante
Si usa Linux o Mac OS y un shell distinto de bash (por ejemplo, zsh), es posible que reciba errores al ejecutar algunos comandos. Para solucionar este problema, use el comando
bashpara iniciar un nuevo shell de bash y ejecutar sus comandos.Active el entorno virtual de Python recién creado.
Instale el SDK de Azure Machine Learning para Python.
Con el fin de configurar el entorno local para usar el área de trabajo de Azure Machine Learning, cree un archivo de configuración de área de trabajo o use uno que ya tenga.
Ahora que ha configurado el entorno local, ya podrá empezar a trabajar con Azure Machine Learning. Consulte la guía de introducción de Azure Machine Learning para Python para comenzar.
Cuadernos de Jupyter Notebook
Al ejecutar un servidor de Jupyter Notebook local, se recomienda crear un kernel de IPython para el entorno virtual de Python. Esto ayuda a garantizar el comportamiento esperado de la importación del paquete y el kernel.
Habilitación de los kernels de IPython específicos del entorno
conda install notebook ipykernelCree un kernel para el entorno virtual de Python. Asegúrese de reemplazar
<myenv>por el nombre de su entorno virtual de Python.ipython kernel install --user --name <myenv> --display-name "Python (myenv)"Inicio del servidor de Jupyter Notebook
Consulte el repositorio de cuadernos de Azure Machine Learning para empezar a trabajar con Azure Machine Learning y Jupyter Notebook. Consulte también el repositorio controlado por la comunidad, AzureML-Examples.
Visual Studio Code
Para usar Visual Studio Code para el desarrollo:
Instale Visual Studio Code.
Instale la extensión Azure Machine Learning para Visual Studio Code (versión preliminar).
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Una vez que tenga instalada la extensión de Visual Studio Code, úsela para:
- Administrar los recursos de Azure Machine Learning
- Inicio de Visual Studio Code conectado de forma remota a una instancia de proceso (versión preliminar)
- Ejecutar y depurar experimentos
- Implementar modelos entrenados (CLI v2).
Instancia de proceso de Azure Machine Learning
La instancia de proceso de Azure Machine Learning es una estación de trabajo de Azure segura y basada en la nube que proporciona a los científicos de datos un servidor de Jupyter Notebook, JupyterLab y un entorno de aprendizaje automático totalmente administrado.
No hay nada que instalar o configurar para una instancia de proceso.
Cree una en cualquier momento desde el área de trabajo de Azure Machine Learning. Basta con que proporcione un nombre y especifique un tipo de máquina virtual de Azure. Pruébela ahora mediante Creación de recursos para empezar.
Para obtener más información acerca de las instancias de proceso, incluyendo cómo instalar paquetes, consulte Creación y administración de una instancia de proceso de Azure Machine Learning.
Sugerencia
Para evitar incurrir en cargos por una instancia de proceso no usada, detenga la instancia de proceso. O habilite el apagado inactivo para la instancia de proceso.
Además de un servidor de Jupyter Notebook y JupyterLab, puede usar instancias de proceso en la característica de cuadernos integrada en Estudio de Azure Machine Learning.
También puede usar la extensión de Visual Studio Code para Azure Machine Learning para conectarse a una instancia de proceso remota mediante VS Code.
Máquina virtual de ciencia de datos
Data Science VM es una imagen de máquina virtual personalizada que puede usar como entorno de desarrollo. Está diseñada para realizar trabajos de ciencia de datos que estén preconfigurados con herramientas y software como:
- Paquetes, como TensorFlow, PyTorch, Scikit-learn, XGBoost y el SDK de Azure Machine Learning
- Herramientas de ciencia de datos populares, como Spark Standalone o Drill
- Herramientas de Azure, como la CLI de Azure, AzCopy y el Explorador de Storage
- Entornos de desarrollo integrado (IDE), como Visual Studio Code y PyCharm
- Servidor de Jupyter Notebook
Para ver una lista más completa de las herramientas, consulte la guía de herramientas de Data Science VM.
Importante
Si planea usar la instancia de Data Science VM como destino de proceso para sus trabajos de entrenamiento o inferencia, solo se admite Ubuntu.
Para usar la instancia de Data Science VM como entorno de desarrollo, haga lo siguiente:
Cree una instancia de Data Science VM con uno de los métodos siguientes:
Use Azure Portal para crear una instancia de DSVM de Ubuntu o Windows.
Cree una instancia de Data Science VM con plantillas de Resource Manager.
Uso de la CLI de Azure
Para crear una instancia de Data Science VM de Ubuntu, use el siguiente comando:
# create a Ubuntu Data Science VM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully # If you need to create a new resource group use: "az group create --name YOUR-RESOURCE-GROUP-NAME --location YOUR-REGION (For example: westus2)" az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --generate-ssh-keys --authentication-type passwordPara crear una instancia de DSVM de Windows, use el siguiente comando:
# create a Windows Server 2016 DSVM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:dsvm-windows:server-2016:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --authentication-type password
Active el entorno de conda que contiene el SDK de Azure Machine Learning.
Para una instancia de Data Science VM de Ubuntu:
conda activate py36Para una instancia de Data Science VM de Windows:
conda activate AzureML
Para configurar la instancia de Data Science VM que usará el área de trabajo de Azure Machine Learning, cree un archivo de configuración del área de trabajo o use uno que ya tenga.
De forma similar a los entornos locales, puede usar Visual Studio Code y la extensión de Azure Machine Learning para Visual Studio Code con el fin de interactuar con Azure Machine Learning.
Consulte Data Science Virtual Machine para obtener más información.
Pasos siguientes
- Entrenar e implementar un modelo en Azure Machine Learning con el conjunto de datos de MNIST.
- Consultar la referencia del SDK de Azure Machine Learning para Python.